学习新的数组和字符串处理技术
PHP 8 对数组和字符串处理技术进行了许多改进。虽然本书没有足够的篇幅来介绍每一项改进,但我们将在本节中考察比较重要的改进。
使用 array_splice()
array_splice() 函数介于 substr() 和 str_replace() 之间:它可以将一个数组的子集替换为另一个数组的子集。然而,当您只需将数组的最后一部分替换为不同的内容时,该函数的使用就会变得尴尬。快速查看一下语法,就会发现它开始变得不方便的地方—替换参数的前面是 length 参数,如图所示:
array_splice(&$input,$offset[,$length[,$replacement]]):array传统上,开发人员首先在原始数组上运行 count(),然后使用它作为长度参数,如图所示:
array_splice($arr, 3, count($arr), $repl);在 PHP 8 中,第三个参数可以是 NULL,从而节省了对 count() 的额外调用。如果利用 PHP 8 的 命名参数 功能,代码会变得更加简洁。下面是为 PHP 8 编写的相同代码片段:
array_splice($arr, 3, replacement: $repl);下面还有一个例子可以清楚地说明 PHP 7 和 PHP 8 之间的区别:
// /repo/ch02/php7_array_splice.php
$arr = ['Person', 'Camera', 'TV', 'Woman', 'Man'];
$repl = ['Female', 'Male'];
$tmp = $arr;
$out = array_splice($arr, 3, count($arr), $repl);
var_dump($arr);
$arr = $tmp;
$out = array_splice($arr, 3, NULL, $repl);
var_dump($arr);如果在 PHP 7 中运行该代码,请注意最后一个 var_dump() 实例的结果,如图所示:
repo/ch02/php7_array_splice.php:11:
array(7) {
[0] => string(6) "Person"
[1] => string(6) "Camera"
[2] => string(2) "TV"
[3] => string(6) "Female"
[4] => string(4) "Male"
[5] => string(5) "Woman"
[6] => string(3) "Man"
}在 PHP 7 中,为 array_splice() 的第三个参数提供一个 NULL 值会导致两个数组被简单地合并,这不是我们想要的结果!
现在来看看最后一次 var_dump() 的输出结果,不过这次是在 PHP 8 下运行的:
root@php8_tips_php8 [ /repo/ch02 ]# php php8_array_splice.php
// some output omitted
array(5) {
[0]=> string(6) "Person"
[1]=> string(6) "Camera"
[2]=> string(2) "TV"
[3]=> string(6) "Female"
[4]=> string(4) "Male"
}如您所见,将第三个参数设置为 NULL 与在 PHP 8 下运行时为 array_splice() 的第三个参数提供一个数组 count() 的功能是一样的。您还会注意到,在 PHP 8 中,数组元素的总数是 5,而在 PHP 7 中运行的相同代码的总数是 7。
使用 array_slice()
array_slice() 函数对数组的操作就像 substr() 对字符串的操作一样。早期版本 PHP 的最大问题是,在内部,PHP 引擎会依次遍历整个数组,直到达到所需的偏移量。如果偏移量很大,性能就会受到影响,这与数组的大小直接相关。
在 PHP 8 中,使用了一种不同的算法,不需要按顺序迭代数组。随着数组大小的增加,性能的提高也越来越明显。
-
在这里显示的示例中,我们首先构建一个包含大约 600 万个条目的大型数组:
// /repo/ch02/php8_array_slice.php ini_set('memory_limit', '1G'); $start = microtime(TRUE); $arr = []; $alpha = range('A', 'Z'); $beta = $alpha; $loops = 10000; // size of outer array $iters = 500; // total iterations $drip = 10; // output every $drip times $cols = 4; for ($x = 0; $x < $loops; $x++) foreach ($alpha as $left) foreach ($beta as $right) $arr[] = $left . $right . rand(111,999); -
接下来,我们遍历数组,随机抽取大于 999,999 的偏移量。这将迫使
array_slice()努力工作,并显示出 PHP 7 和 PHP 8 之间显著的性能差异,如下面的代码片段所示:$max = count($arr); for ($x = 0; $x < $iters; $x++ ) { $offset = rand(999999, $max); $slice = array_slice($arr, $offset, 4); // not all display logic is shown } $time = (microtime(TRUE) - $start); echo "\nElapsed Time: $time seconds\n";
以下是在 PHP 7 下运行代码时的输出:
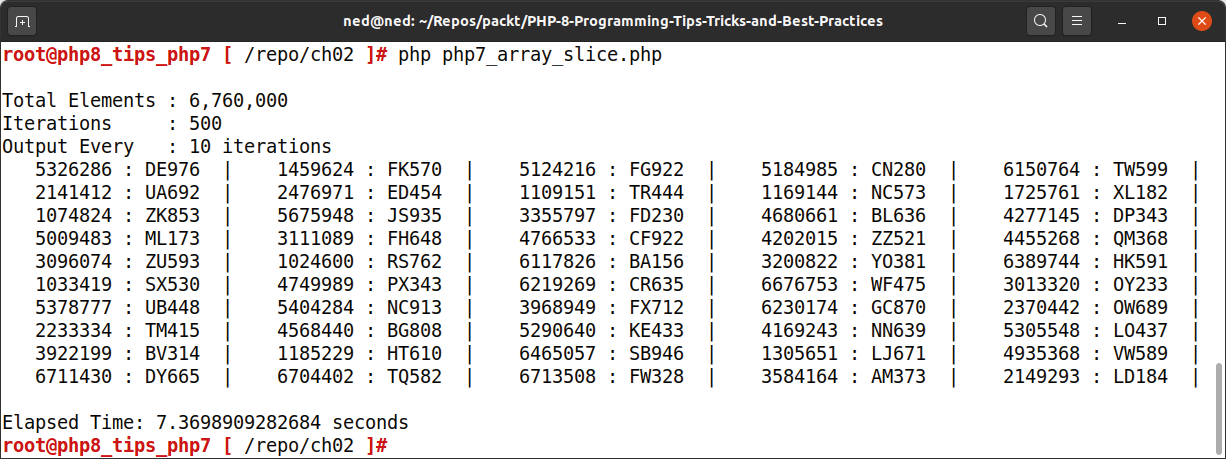
请注意在 PHP 8 下运行相同代码时的巨大性能差异:
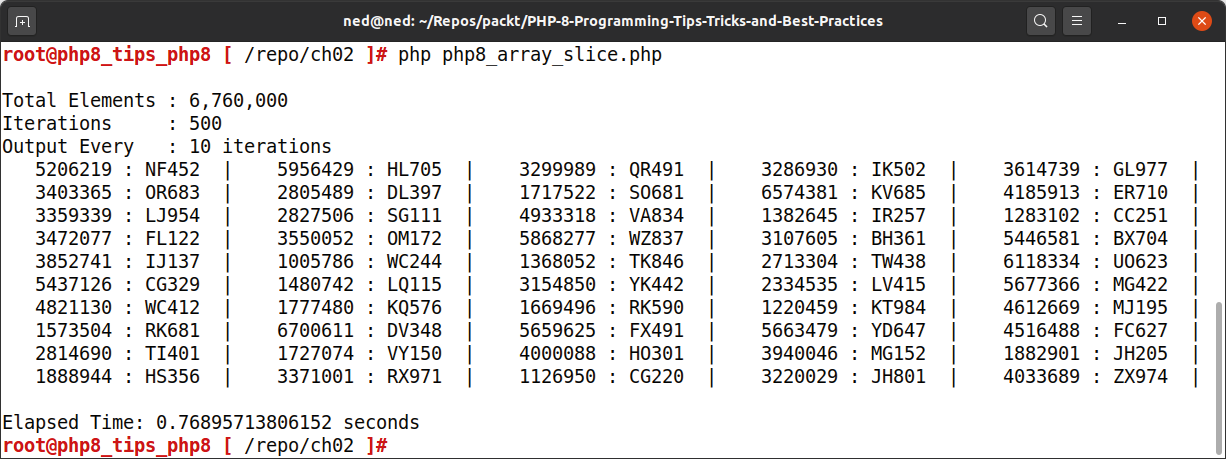
|
新算法只有在数组不包含 |
现在让我们把注意力转向一些优秀的新字符串函数。
检测字符串的开头、中间和结尾
PHP 开发人员经常要处理的问题是,必须检查字符串开头、中间或结尾的字符集。当前字符串函数集的问题在于,它们不是为了处理是否存在子串而设计的。相反,当前的函数集旨在确定子串的位置。这反过来又可以用布尔方式进行插值,以确定是否存在子字符串。
温斯顿-丘吉尔爵士的一句名言概括了这种方法的问题:
"高尔夫球运动的目的是将一个非常小的球打进一个越来越小的洞里,而使用的武器却完全不是为此目的而设计的"。
现在让我们来看看解决这个问题的三个非常有用的新字符串函数。
str_starts_with()
我们要检查的第一个函数是 str_starts_with()。为了说明它的用途,请看一个代码示例,我们在开头查找 https,在结尾查找 login,如下代码片段所示:
// /repo/ch02/php7_starts_ends_with.php
$start = 'https';
if (substr($url, 0, strlen($start)) !== $start)
$msg .= "URL does not start with $start\n";
// not all code is shown正如我们在本节导言中提到的,为了确定一个字符串是否以 https 开头,我们需要同时调用 substr() 和 strlen()。这两个函数都无法给出我们想要的答案。此外,必须同时使用这两个函数会降低代码的效率,导致不必要的资源使用率增加。
同样的代码可以用 PHP 8 来编写,如下所示:
// /repo/ch02/php8_starts_ends_with.php
$start = 'https';
if (!str_starts_with($url, $start))
$msg .= "URL does not start with $start\n";
// not all code is shownstr_ends_with()
类似于 str_starts_with(),PHP 8 引入了一个新函数 str_ends_with(),用于确定字符串的末尾是否与某个值相匹配。为了说明这个新函数的作用,请看使用 strrev() 和 strpos() 的旧 PHP 代码,可能如下所示:
$end = 'login';
if (strpos(strrev($url), strrev($end)) !== 0)
$msg .= "URL does not end with $end\n";在操作中,$url 和 $end 都需要反转,这个过程的代价会随着字符串长度的增加而增加。另外,如前所述,strpos() 的目的是返回子字符串的位置,而不是确定它是否存在。
在 PHP 8 中,实现相同功能的方法如下:
if (!str_ends_with($url, $end))
$msg .= "URL does not end with $end\n";str_contains()
最后一个函数是 str_contains()。正如我们已经讨论过的,在 PHP 7 和更早的版本中,除了 preg_match() 之外,没有其他特定的 PHP 函数可以告诉我们字符串中是否存在子串。
使用 preg_match() 的问题,正如我们一再被警告的那样,是性能下降。为了处理正则表达式,preg_match() 需要首先分析模式。然后,它还需要执行第二次处理,以确定字符串的哪一部分与模式匹配。就时间和资源利用率而言,这是一个非常昂贵的操作。
|
当我们提到某个操作在时间和资源方面比较昂贵时,请记住,如果您的脚本只有几十行代码,并且/或者您没有在循环中重复操作数千次,那么使用本节中介绍的新函数和新技术很可能不会带来任何显著的性能提升。 |
在下面的示例中,PHP 脚本使用 preg_match(),在地名项目数据库中搜索人口超过 15000 的城市,查找是否有包含伦敦的列表:
// /repo/ch02/php7_str_contains.php
$start = microtime(TRUE);
$target = '/ London /';
$data_src = __DIR__ . '/../sample_data/cities15000_min.txt';
$fileObj = new SplFileObject($data_src, 'r');
while ($line = $fileObj->fgetcsv("\t")) {
$tz = $line[17] ?? '';
if ($tz) unset($line[17]);
$str = implode(' ', $line);
$city = $line[1] ?? 'Unknown';
$local1 = $line[10] ?? 'Unknown';
$iso = $line[8] ?? '??';
if (preg_match($target, $str))
printf("%25s : %12s : %4s\n", $city, $local1, $iso);
}
echo "Elapsed Time: " . (microtime(TRUE) - $start) . "\n";以下是在 PHP 7 中运行时的输出:
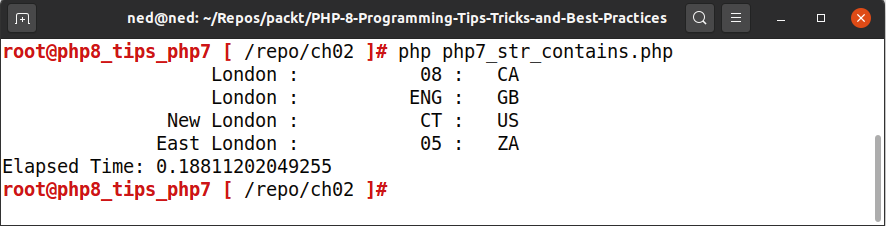
在 PHP 8 中,将 if 语句替换为下面的代码,可以获得相同的输出结果:
// /repo/ch02/php8_str_contains.php
// not all code is shown
if (str_contains($str, $target))
printf("%25s : %12s : %4s\n", $city, $local1, $iso);下面是 PHP 8 的输出结果:
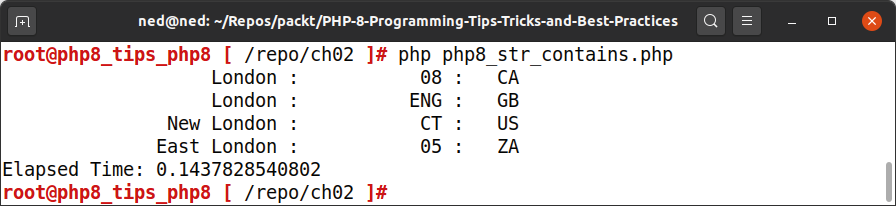
从两个不同的输出屏幕上可以看到,PHP 8 代码的运行时间约为 0.14 微秒,而 PHP 7 为 0.19 微秒。这本身并不是一个巨大的性能提升,但正如本节前面提到的,更多的数据、更长的字符串和更多的迭代会放大任何微小的性能提升。
|
最佳实践:实现小幅性能提升的小代码修改最终会带来巨大的整体性能提升! 有关 GeoNames 开源项目的更多信息,请访问其网站: https://www.geonames.org/ 。 |
现在,您已经知道如何以及在何处使用三个新的字符串函数。您还可以使用专门用于检测目标字符串开头、中间或结尾是否存在子串的函数来编写更高效的代码。
最后,在本章的结尾,我们将带着一点乐趣来看看新的 SQLite3 授权器。