部署到应用服务器
到目前为止,阅读列表应用程序每次运行,Web应用程序都通过内嵌在应用里的Tomcat提供服务。情况和传统Java Web应用程序正好相反。不是应用程序部署在Tomcat里,而是Tomcat部署在了应用程序里。
归功于Spring Boot的自动配置功能,我们不需要创建web.xml文件或者Servlet初始化类来声明Spring MVC的DispatcherServlet。但如果要将应用程序部署到Java应用服务器里,我们就需要构建WAR文件了。这样应用服务器才能知道如何运行应用程序。那个WAR文件里还需要一个对Servlet进行初始化的东西。
构建WAR文件
实际上,构建WAR文件并不困难。如果你使用Gradle来构建应用程序,只需应用WAR插件即可:
apply plugin: 'war'随后,在build.gradle里用以下war配置替换原来的jar配置:
war {
baseName='readinglist'
version='0.0.1-SNAPSHOT'
}两者的唯一区别就是 j 换成了 w。
如果使用Maven构建项目,获取WAR文件会更容易。只需把<packaging>元素的值从jar改为war。
<packaging>war</packaging>这样就能生成WAR文件了。但如果WAR文件里没有启用Spring MVC DispatcherServlet的web.xml文件或者Servlet初始化类,这个WAR文件就一无是处。
此时就该Spring Boot出马了。它提供的SpringBootServletInitializer是一个支持Spring Boot的Spring WebApplicationInitializer实现。除了配置Spring的Dispatcher-Servlet, SpringBootServletInitializer还会在Spring应用程序上下文里查找Filter、Servlet或ServletContextInitializer类型的Bean,把它们绑定到Servlet容器里。
要使用SpringBootServletInitializer,只需创建一个子类,覆盖configure()方法来指定Spring配置类。代码清单8-1是ReadingListServletInitializer,也就是我们为阅读列表应用程序写的SpringBootServletInitializer的子类。
如你所见,configure()方法传入了一个SpringApplicationBuilder参数,并将其作为结果返回。期间它调用sources()方法注册了一个Spring配置类。本例只注册了一个Application类。回想一下,这个类既是启动类(带有main()方法),也是一个Spring配置类。
虽然阅读列表应用程序里还有其他Spring配置类,但没有必要在这里把它们全部注册进来。Application类上添加了@SpringBootApplication注解。这会隐性开启组件扫描,而组件扫描则会发现并应用其他配置类。
现在我们可以构建应用程序了。如果使用Gradle,你只需调用build任务即可:
$ gradle build没问题的话,你可以在 build/libs 里看到一个名为 readinglist-0.0.1-SNAPSHOT.war 的文件。
对于基于 Maven 的项目,可以使用 package:
$ mvn package成功构建之后,你可以在target目录里找到WAR文件。
剩下的工作就是部署应用程序了。应用服务器不同,部署过程会有所区别,因此请参考应用服务器的部署说明文档。
对于Tomcat而言,可以把WAR文件复制到Tomcat的webapps目录里。如果Tomcat正在运行(要是没有运行,则在下次启动时检测),则会检测到WAR文件,解压并进行安装。
假设你没有在部署前重命名WAR文件,Servlet上下文路径会与WAR文件的主文件名相同,在本例中是/readinglist-0.0.1-SNAPSHOT。用你的浏览器打开http://server:port/readinglist-0.0.1-SNAPSHOT就能访问应用程序了。
还有一点值得注意:就算我们在构建的是WAR文件,这个文件仍旧可以脱离应用服务器直接运行。如果你没有删除Application里的main()方法,构建过程生成的WAR文件仍可直接运行,一如可执行的JAR文件:
$ java -jar readinglist-0.0.1-SNAPSHOT.war这样一来,同一个部署产物就能有两种部署方式了!
现在,应用程序应该已经在Tomcat里顺利地运行起来了。但是它还在使用内嵌的H2数据库。开发应用程序时,嵌入式数据库很好用,但对生产环境而言这不是一个明智的选择。让我们来看看如何在部署到生产环境时选择不同的数据源。
创建生产Profile
多亏了自动配置,我们有了一个指向嵌入式H2数据库的DataSource Bean。更确切地说,DataSource Bean是一个数据库连接池,通常是org.apache.tomcat.jdbc.pool.DataSource。因此,很明显,要使用嵌入式H2之外的数据库,我们只需声明自己的DataSource Bean,指向我们选择的生产数据库,用它覆盖自动配置的DataSource Bean。
例如,假设我们想使用运行localhost上的PostgreSQL数据库,数据库名字是readingList。下面的@Bean方法就能声明我们的DataSource Bean:
@Bean
@Profile("production")
public DataSource dataSource() {
DataSource ds=new DataSource();
ds.setDriverClassName("org.postgresql.Driver");
ds.setUrl("jdbc:postgresql://localhost:5432/readinglist");
ds.setUsername("habuma");
ds.setPassword("password");
return ds;
}这里DataSource的类型是Tomcat的org.apache.tomcat.jdbc.pool.DataSource,不要和javax.sql.DataSource搞混了。前者是后者的实现。连接数据库所需的细节(包括JDBC驱动类名、数据库URL、用户名和密码)提供给了DataSourse实例。声明了这个Bean之后,默认自动配置的DataSource Bean就会忽略。
这个@Bean方法最关键的一点是,它还添加了@Profile注解,说明只有在production Profile被激活时才会创建该Bean。所以,在开发时我们还能继续使用嵌入式的H2数据库。激活productionProfile后就能使用PostgreSQL数据库了。
虽然这么做能达到目的,但是配置数据库细节的时候,最好还是不要显式地声明自己的DataSource Bean。在不替换自动配置的Datasource Bean的情况下,我们还能通过application.yml或application.properties来配置数据库的细节。表8-2列出了在配置DataSource Bean时用到的全部属性。

表8-2里的大部分属性都是用来微调连接池的。怎么设置这些属性以适应你的需要,这就交给你来解决了。我们现在要设置属性,让DataSource Bean指向PostgreSQL而非内嵌的H2数据库。具体来说,我们要设置的是spring.datasource.url、spring.datasource.username以及spring.datasource.password属性。
在设置这些内容时,我在本地运行了一个PostgreSQL数据库,监听5432端口。用户名和密码分别是habuma和password。因此,application.yml的production Profile里需要如下内容:
---
spring:
profiles: production
datasource:
url: jdbc:postgresql://localhost:5432/readinglist
username: habuma
password: password
jpa:
database-platform: org.hibernate.dialect.PostgreSQLDialect请注意,这个代码片段以---开头,设置的第一个属性是spring.profiles。这说明随后的属性都只在productionProfile激活时才会生效。
随后设置的是spring.datasource.url、spring.datasource.username和spring.datasource.password属性。注意,spring.datasource.driver-class-name属性一般无需设置。Spring Boot可以根据spring.datasource.url属性的值做出相应推断。我还设置了一些JPA的属性。spring.jpa.database-platform属性将底层的JPA引擎设置为Hibernate的PostgreSQL方言。
要开启这个Profile,我们需要把spring.profiles.active属性设置为production。实现方式有很多,但最方便的还是在运行应用服务器的机器上设置一个系统环境变量。在启动Tomcat前开启productionProfile,我需要像这样设置SPRING_PROFILES_ACTIVE环境变量:
$ export SPRING_PROFILES_ACTIVE=production你也许已经注意到了,SPRING_PROFILES_ACTIVE不同于spring.profiles.active。因为无法在环境变量名里使用句点,所以变量名需要稍作修改。站在Spring的角度看,这两个名字是等价的。
我们基本已经可以在应用服务器上部署并运行应用程序了。实际上,如果你喜欢冒险,也可以直接尝试一下。不过你会遇到一点小问题。
默认情况下,在使用内嵌的H2数据库时,Spring Boot会配置Hibernate来自动创建Schema。更确切地说,这是将Hibernate的hibernate.hbm2ddl.auto设置为create-drop,说明在Hibernate的SessionFactory创建时会创建Schema,SessionFactory关闭时删除Schema。
但如果没使用内嵌的H2数据库,那么它什么都不会做。也就是,说应用程序的数据表尚不存在,在查询那些不存在的表时会报错。
开启数据库迁移
一种途径是通过Spring Boot的spring.jpa.hibernate.ddl-auto属性将hibernate.hbm2ddl.auto属性设置为create、create-drop或update。例如,要把hibernate.hbm2ddl.auto设置为create-drop,我们可以在application.yml里加入如下内容:
spring:
jpa:
hibernate:
ddl-auto: create-drop然而,这对生产环境来说并不理想,因为应用程序每次重启数据库,Schema就会被清空,从头开始重建。它可以设置为update,但就算这样,我们也不建议将其用于生产环境。
还有一个途径。我们可以在schema.sql里定义Schema。在第一次运行时,这么做没有问题,但随后每次启动应用程序时,这个初始化脚本都会失败,因为数据表已经存在了。这就要求在书写初始化脚本时格外注意,不要重复执行那些已经做过的工作。
一个比较好的选择是使用数据库迁移库(database migration library)。它使用一系列数据库脚本,而且会记录哪些已经用过了,不会多次运用同一个脚本。应用程序的每个部署包里都包含了这些脚本,数据库可以和应用程序保持一致。
Spring Boot为两款流行的数据库迁移库提供了自动配置支持。
-
Flyway(http://flywaydb.org)
-
Liquibase(http://www.liquibase.org)
当你想要在Spring Boot里使用其中某一个库时,只需在项目里加入对应的依赖,然后编写脚本就可以了。让我们先从Flyway开始了解吧。
用FIyway定义数据库迁移过程
Flyway是一个非常简单的开源数据库迁移库,使用SQL来定义迁移脚本。它的理念是,每个脚本都有一个版本号,Flyway会顺序执行这些脚本,让数据库达到期望的状态。它也会记录已执行的脚本状态,不会重复执行。
在阅读列表应用程序这里,我们先从一个没有数据表和数据的空数据库开始。因此,这个脚本里需要先创建Reader和Book表,包含外键约束和初始化数据。代码清单8-2就是从空数据库到可用状态的Flyway脚本。
如你所见,Flyway脚本就是SQL。让其发挥作用的是其在Classpath里的位置和文件名。Flyway脚本都遵循一个命名规范,含有版本号,具体如图8-1所示。
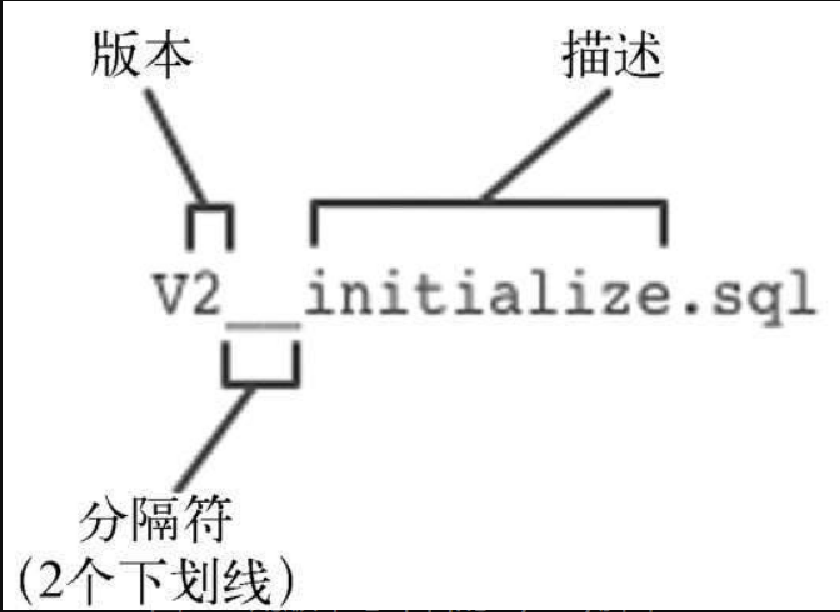
所有Flyway脚本的名字都以大写字母V开头,随后是脚本的版本号。后面跟着两个下划线和对脚本的描述。因为这是整个迁移过程中的第一个脚本,所以它的版本是1。描述可以很灵活,主要用来帮助理解脚本的用途。稍后我们需要向数据库添加新表,或者向已有数据表添加新字段。可以再创建一个脚本,标明版本号为2。
Flyway脚本需要放在相对于应用程序Classpath根路径的/db/migration路径下。因此,项目中,脚本需要放在src/main/resources/db/migration里。
你还需要将spring.jpa.hibernate.ddl-auto设置为none,由此告知Hibernate不要创建数据表。这关系到application.yml中的如下内容:
spring:
jpa:
hibernate:
ddl-auto: none剩下的就是将Flyway添加为项目依赖。在Gradle里,此依赖是这样的:
compile("org.flywaydb:flyway-core")在Maven项目里,<dependency>是这样的:
<dependency>
<groupId>org.flywayfb</groupId>
<artifactId>flyway-core</artifactId>
</dependency>在应用程序部署并运行起来后,Spring Boot 会检测到Classpath里的Flyway,自动配置所需的Bean。Flyway会依次查看/db/migration里的脚本,如果没有执行过就运行这些脚本。每个脚本都执行过后,向schema_version表里写一条记录。应用程序下次启动时,Flyway会先看schema_version里的记录,跳过那些脚本。
用Liquibase定义数据库迁移过程
Flyway用起来很简便,在Spring Boot自动配置的帮助下尤其如此。但是,使用SQL来定义迁移脚本是一把双刃剑。SQL用起来便捷顺手,却要冒着只能在一个数据库平台上使用的风险。
Liquibase并不局限于特定平台的SQL,可以用多种格式书写迁移脚本,不用关心底层平台(其中包括XML、YAML和JSON)。如果你有这个期望的话,Liquibase当然也支持SQL脚本。
要在Spring Boot里使用Liquibase,第一步是添加依赖。Gradle里的依赖是这样的:
compile("org.liquibase:liquibase-core")对于Maven项目,你需要添加如下<dependency>:
<dependency>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-core</artifactId>
</dependency>有了这个依赖,Spring Boot自动配置就能接手,配置好用于支持Liquibase的Bean。默认情况下,那些Bean会在/db/changelog(相对于Classpath根目录)里查找db.changelog-master.yaml文件。这个文件里都是迁移脚本。代码清单8-3的初始化脚本为阅读列表应用程序进行了数据库初始化。
如你所见,比起等效的Flyway SQL脚本,YAML格式略显繁琐,但看起来还是很清晰的,而且这个脚本不与任何特定的数据库平台绑定。
与Flyway不同,Flyway有多个脚本,每个脚本对应一个变更集。Liquibase变更集都集中在一个文件里。请注意,changeset命令后的那行有一个id属性,要对数据库进行后续变更。可以添加一个新的changeset,只要id不一样就行。此外,id属性也不一定是数字,可以包含任意内容。
应用程序启动时,Liquibase会读取db.changelog-master.yaml里的变更集指令集,与之前写入databaseChangeLog表里的内容做对比,随后执行未运行过的变更集。
虽然这里的例子使用的是YAML格式,但你也可以任意选择Liquibase所支持的其他格式,比如XML或JSON。只需简单地设置liquibase.change-log属性(在application.properties或application.yml里),标明希望Liquibase加载的文件即可。举个例子,要使用XML变更集,可以这样设置liquibase.change-log:
liquibase:
change-log: classpath:/db/changelog/db.changelog-master.xmlSpring Boot的自动配置让Liquibase和Flyway的使用变得轻而易举。但实际上所有数据库迁移库都有更多功能,这里不便一一列举。建议大家参考官方文档,了解更多详细内容。
我们已经了解了如何将Spring Boot应用程序部署到传统的Java应用服务器上,基本就是创建一个SpringBootServletInitializer的子类,调整构建说明来生成一个WAR文件,而非JAR文件。接下来我们会看到,Spring Boot应用程序在云端使用更方便。