构建工具
当然,您可能会问自己为什么需要另一个工具来为您的项目实现自动化。 您可以将逻辑编写为可执行脚本,例如 shell 脚本。 回想一下我们之前讨论的项目自动化的目标。 您需要一个工具,让您无需手动干预即可创建可重复、可靠且可移植的构建。 shell 脚本不容易从基于 UNIX 的系统移植到基于 Windows 的系统,因此它不符合您的标准。
什么是构建工具?
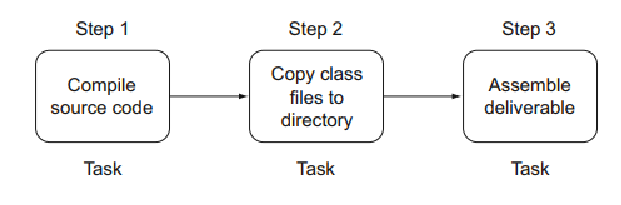
您需要的是一个编程实用程序,它可以让您将自动化需求表达为可执行的有序任务。 假设您想要编译源代码,将生成的类文件复制到一个目录中,并组装包含类文件的可交付成果。 例如,可交付成果可以是 ZIP 文件,可以分发到运行时环境。 图 1.4 显示了所描述场景的任务及其执行顺序。
这些任务中的每一个都代表一个工作单元,例如源代码的编译。 顺序很重要。 如果所需的类文件尚未编译,则无法创建 ZIP 存档。 因此,需要先执行编译任务。
有向无环图
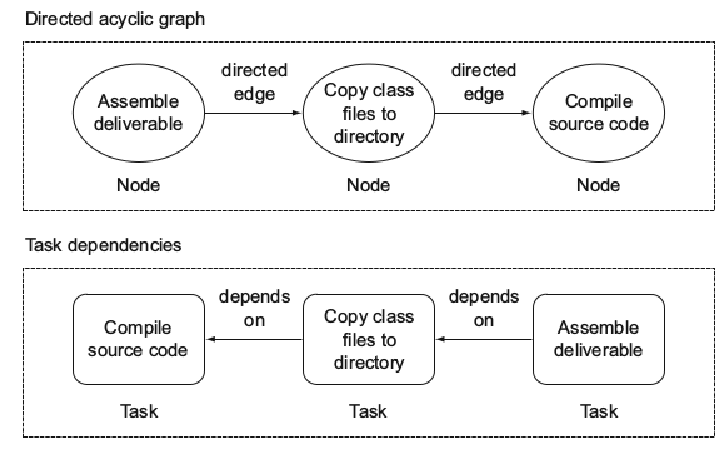
在内部,任务及其相互依赖关系被建模为有向无环图 (DAG)。 DAG 是计算机科学中的一种数据结构,包含以下两个元素:
-
节点(node):一个工作单元,在这里就是一个任务,比如编译源代码
-
边(edge): 有向边,也称为箭头,表示节点之间的关系。 在我们的情况下,箭头的含义取决于。 如果任务定义了依赖任务,则它们需要在任务本身执行之前执行。 通常会出现这种情况,因为该任务依赖于另一个任务产生的输出。 这是一个示例:要执行任务 “组装可交付成果”,您需要运行其依赖任务 “将类文件复制到目录” 和 “编译源代码”。
每个节点都知道自己的执行状态。 一个节点(以及任务)只能执行一次。 例如,如果两个不同的任务依赖于 “源代码编译” 任务,您只想执行一次。 图 1.5 将这种场景显示为 DAG。
您可能已经注意到,节点的显示顺序与图 1.4 中的任务顺序相反。 这是因为顺序是由节点依赖性决定的。 作为开发人员,您不必直接处理构建的 DAG 表示。 这项工作是由构建工具完成的。 在本章后面,您将看到一些基于 Java 的构建工具如何在实践中使用这些概念。
构建工具剖析
了解构建工具组件之间的交互、构建逻辑的实际定义以及传入和传出的数据非常重要。 让我们讨论每个元素及其特定职责。
构建文件
构建文件包含构建所需的配置,定义外部依赖项(例如第三方库),并包含以任务及其相互依赖关系的形式实现特定目标的指令。 图 1.6 说明了一个构建文件,该文件描述了四个任务以及它们如何相互依赖。
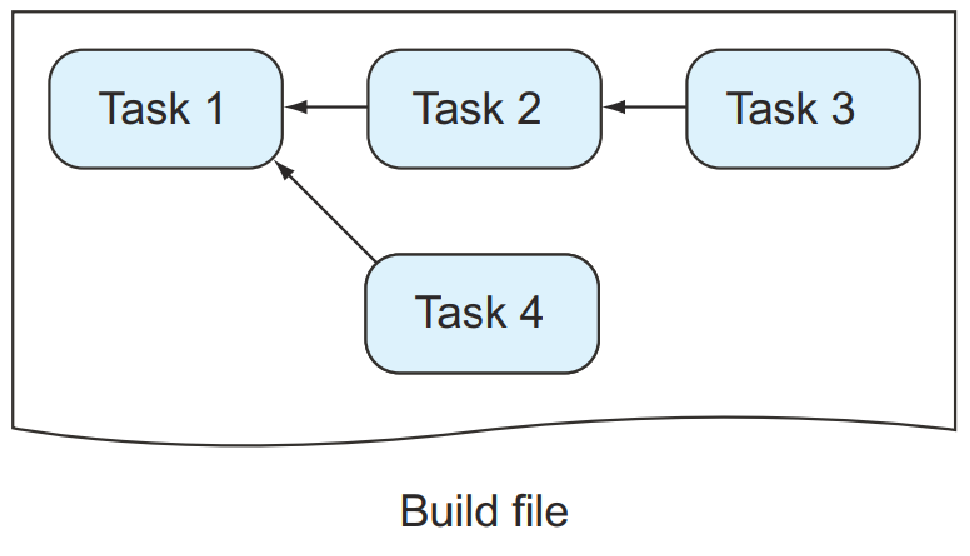
我们在前面的场景中讨论的任务(编译源代码、将文件复制到目录以及组装 ZIP 文件)将在构建文件中定义。 通常,脚本语言用于表达构建逻辑。 这就是为什么构建文件也称为构建脚本。
构建输入和输出
任务接受输入,通过执行一系列步骤对其进行处理,并产生输出。 某些任务可能不需要任何输入即可正常运行,创建输出也不是强制性的。 复杂的任务依赖图可以使用依赖任务的输出作为输入。 图 1.7 演示了任务图中输入的消耗和输出的创建。
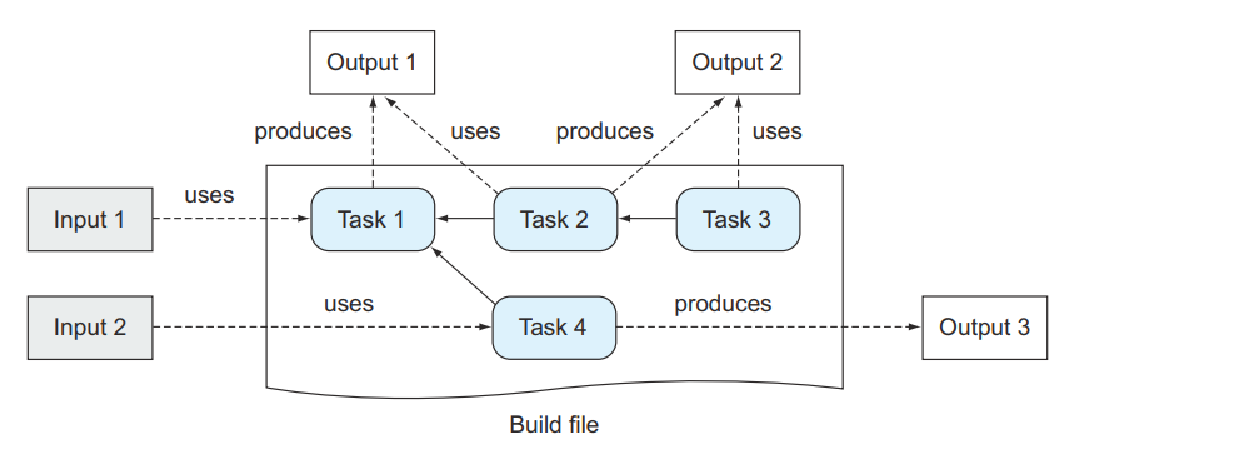
我已经提到了遵循此工作流程的一个示例。 我们将一堆源代码文件作为输入,将它们编译为类,并组装一个可交付成果作为输出。 编译和汇编过程各自代表一项任务。 仅当您首先编译源代码时,可交付成果的汇编才有意义。 因此,这两个任务都需要保留其顺序。
构建引擎
构建文件的分步指令或规则集必须转换为构建工具可以理解的内部模型。 构建引擎在运行时处理构建文件,解决任务之间的依赖关系,并设置命令执行所需的整个配置,如图 1.8 所示。
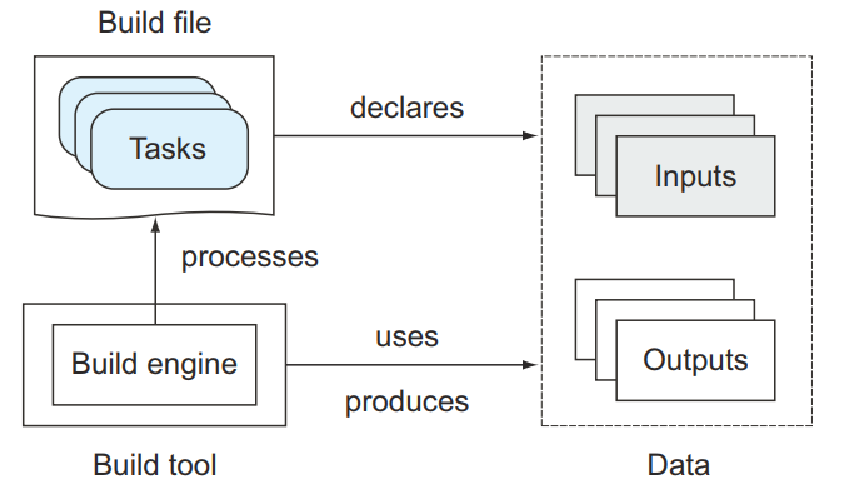
一旦内部模型构建完成,引擎就会按照正确的顺序执行一系列任务。 某些构建工具允许您通过 API 访问此模型,以在运行时查询此信息。
依赖管理器
依赖项管理器用于处理构建文件的声明性依赖项定义,从工件存储库(例如,本地文件系统、FTP 或 HTTP 服务器)解析它们,并使它们可供您的项目使用。 依赖项通常是 JAR 文件形式的外部可重用库(例如,用于日志记录支持的 Log4J)。 存储库充当依赖项的存储,并通过标识符(例如名称和版本)来组织和描述它们。 典型的存储库可以是 HTTP 服务器或本地文件系统。 图 1.9 说明了依赖关系管理器如何适应构建工具的架构。
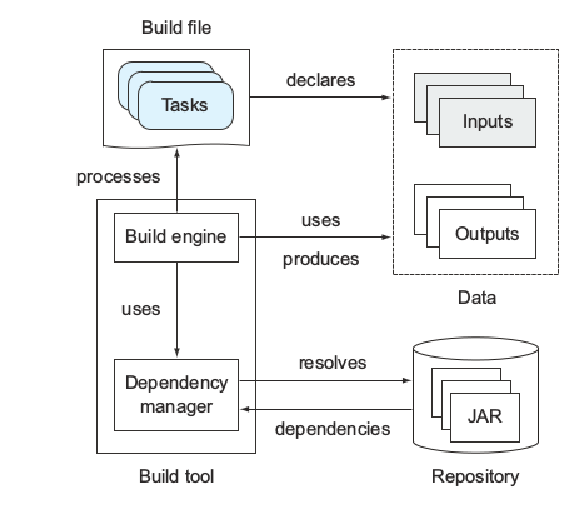
许多库依赖于其他库,称为传递依赖。 依赖关系管理器也可以使用存储在存储库中的元数据来自动解决传递依赖关系。 构建工具不需要提供依赖性管理组件。