依赖管理的快速概述
几乎所有基于 JVM 的软件项目都依赖外部库来重用现有功能。 例如,如果您正在开发一个基于 Web 的项目,那么您很可能依赖 Spring MVC 或 Play 等流行的开源框架之一来提高开发人员的工作效率。 Java 中的库以 JAR 文件的形式分发。 JAR 文件规范不要求您指示库的版本。 但是,通常的做法是将版本号附加到 JAR 文件名以标识特定版本(例如 spring-web-3.1.3.RELEASE.jar)。 您已经看到小型项目非常快速地发展壮大,以及您的项目所依赖的第三方库和模块的数量。 组织和管理 JAR 文件至关重要。
不完善的依赖管理技术
由于 Java 语言没有提供或提出任何用于管理版本依赖项的工具,因此团队必须制定自己的策略来存储和检索它们。 您可能遇到过以下常见做法:
-
手动将 JAR 文件复制到开发人员计算机。 这是处理依赖关系的最原始、非自动化且容易出错的方法。
-
使用 JAR 文件的共享存储(例如,共享网络驱动器上的文件夹),将其安装在开发人员的计算机上,或通过 FTP 检索二进制文件。 这种方法要求开发人员首先建立与二进制存储库的连接。 新的依赖项需要手动添加,这可能需要写入权限或访问凭据。
-
检查与项目源代码一起下载到 VCS 中的 JAR 文件。 这种方法不需要任何额外的设置,并将源代码和所有依赖项捆绑为一个一致的单元。 您的团队可以在更新存储库的本地副本时检索更改。 不利的一面是,二进制文件不必要地占用存储库中的空间。 每当源代码发生更改时,更改库的工作副本都需要频繁签入。 如果您正在处理相互依赖的项目,则尤其如此。
自动化依赖管理的重要性
虽然所有这些方法都有效,但它们还远远不是足够的解决方案,因为它们没有提供命名和组织 JAR 文件的标准化方法。 至少,您需要知道库的确切版本及其所依赖的依赖项(传递依赖项)。 为什么这个这么重要?
了解依赖项的确切版本
处理一个没有明确说明其依赖项版本的项目很快就会成为维护的噩梦。 如果没有仔细记录,您永远无法确定项目中的库版本实际上支持哪些功能。 将库升级到新版本变成了一场猜谜游戏,因为您不确切知道要从哪个版本升级。 事实上,您可能在不知情的情况下实际上正在降级。
管理传递依赖
即使在开发的早期阶段,传递依赖性也是值得关注的。 这些是您的第一级依赖项正常工作所需的库。 流行的 Java 开发堆栈(例如 Spring 和 Hibernate 的组合)从一开始就可以轻松引入 20 多个附加库。 单个库可能需要许多其他库才能正常工作。 图 5.1 显示了 Hibernate 核心库的依赖关系图。
尝试手动确定特定库的所有传递依赖项可能会耗费大量时间。 很多时候,这些信息在库的文档中找不到,你最终会徒劳地寻找正确的依赖项。
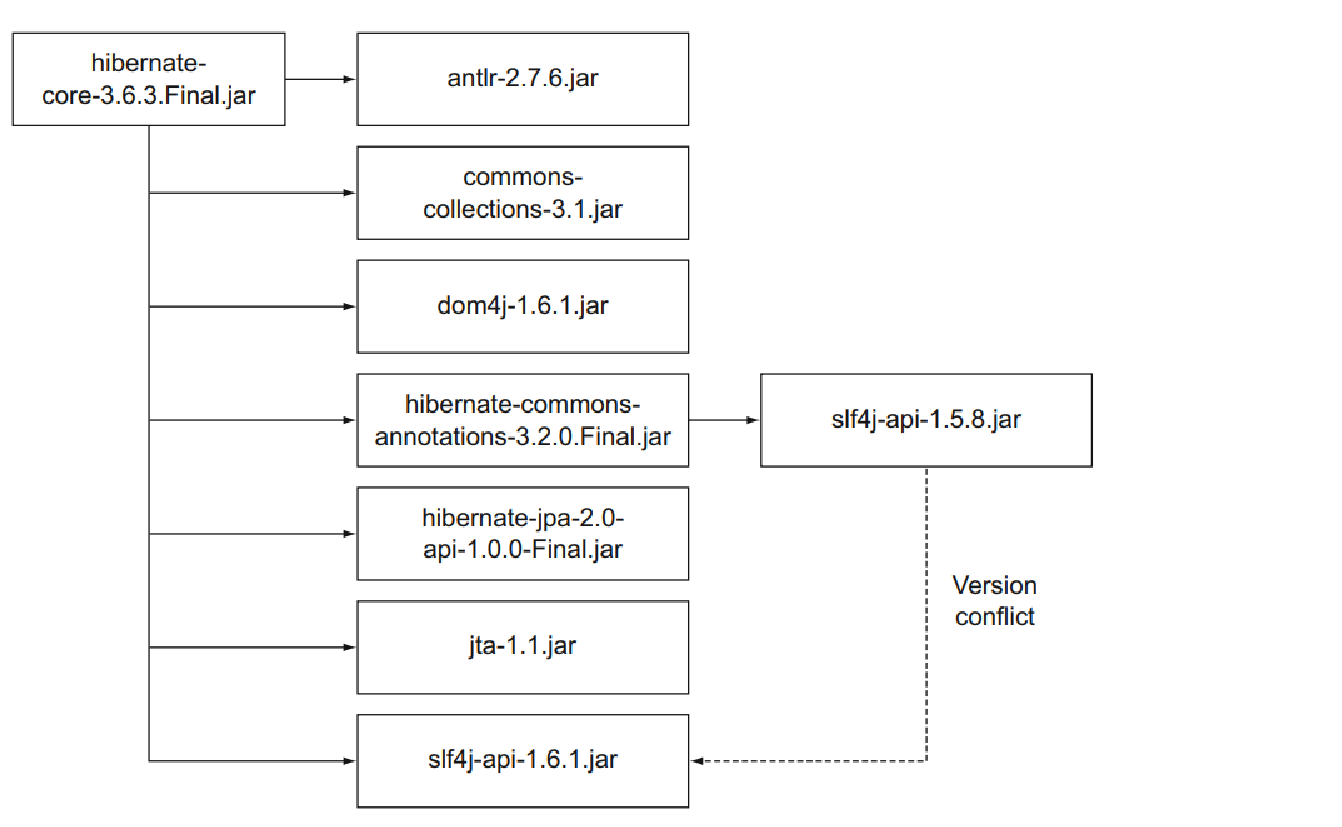
因此,您可能会遇到意外行为,例如编译错误和运行时类加载问题。
我认为我们可以同意需要一个更复杂的解决方案来管理依赖项。 最理想的情况是,您希望能够将依赖项及其各自的版本声明为项目元数据。 作为自动化流程的一部分,可以从中心位置检索它们并为您的项目安装。 让我们看看支持这些功能的现有开源解决方案。
使用自动化依赖管理
Java 领域主要由两个支持声明式和自动化依赖项管理的项目主导:Apache Ivy,一个主要与 Ant 项目一起使用的纯粹依赖项管理器,以及 Maven,它包含一个依赖项管理器作为其构建基础设施的一部分。 我不会深入讨论这些解决方案的细节。 相反,本节的目的是解释自动依赖关系管理的概念和机制。
在 Ivy 和 Maven 中,依赖配置是通过 XML 描述符文件来表达的。 配置由两部分组成:依赖项标识符及其各自的版本,以及二进制存储库的位置(例如,您要从中检索它们的 HTTP 地址)。 依赖项管理器评估此信息并自动定位这些存储库以将依赖项下载到本地计算机上。 库可以将传递依赖定义为其元数据的一部分。 依赖关系管理器足够智能,可以分析这些信息并在检索过程中解决这些依赖关系。 如果识别出依赖项版本冲突(如 Hibernate 核心示例所示),依赖项管理器将尝试解决它。 下载后,库将存储在本地缓存中。 现在,配置的库在您的开发人员计算机上可用,它们可以用于您的构建。 后续构建将首先检查本地缓存中的库,以避免对存储库发出不必要的请求。 图 5.2 说明了自动化依赖管理的关键要素。
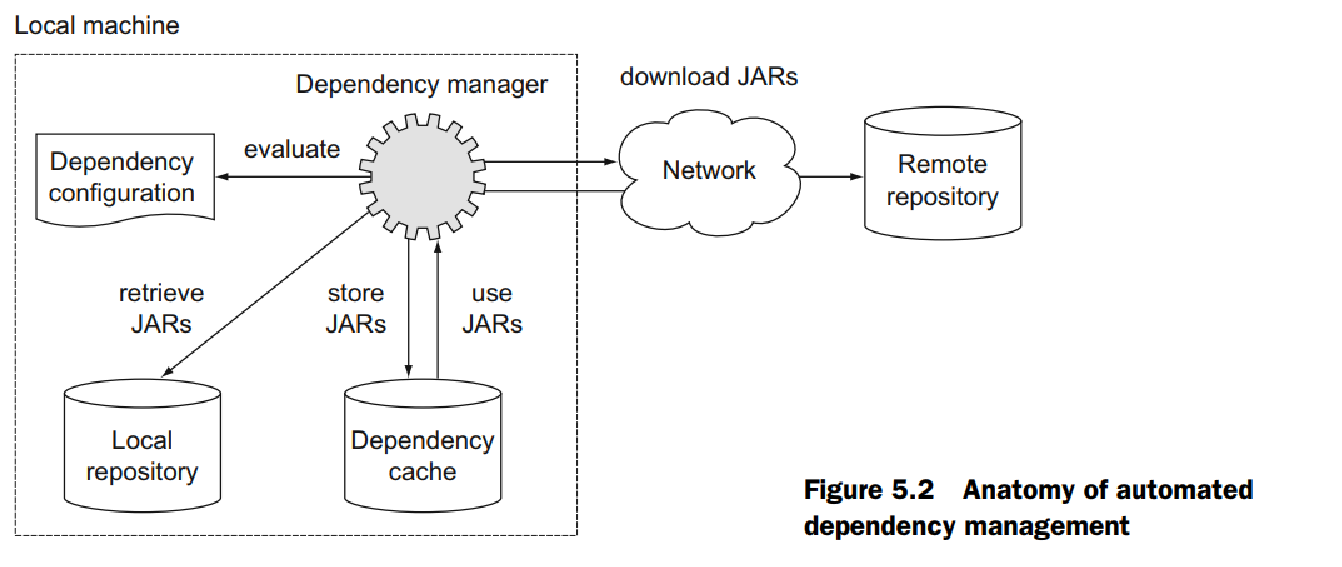
使用依赖项管理器可以使您摆脱手动复制或组织 JAR 文件的负担。 Gradle 提供了一个强大的开箱即用的依赖管理实现,适合刚刚描述的架构。 它将依赖配置描述为 Gradle 富有表现力的 DSL 的一部分,支持传递依赖管理,并且可以与现有存储库基础设施很好地配合。 在深入讨论细节之前,让我们先看看依赖管理可能面临的一些挑战以及如何应对这些挑战。
自动化依赖管理的挑战
尽管依赖管理显着简化了外部库的处理,但在某些时候您会发现自己正在处理某些可能会损害构建的可靠性和可重复性的缺点。
中央托管存储库可能不可用
企业软件依赖开源库的情况并不罕见。 其中许多项目将其版本发布到集中托管的存储库。 使用最广泛的存储库之一是 Maven Central。 如果 Maven Central 是您的构建所依赖的唯一存储库,那么您就自动为系统创建了单点故障。 如果存储库关闭,如果需要本地缓存中不可用的依赖项,您就失去了构建项目的能力。
您可以通过将构建配置为使用您自己的自定义内部存储库来避免这种情况,这使您可以完全控制服务器的可用性。 如果您渴望了解它,请直接跳到第 14 章,其中讨论了如何设置和使用开源和商业存储库管理器,例如 Sonatype Nexus 和 JFrog 的 Artifactory。
错误的元数据和缺失的依赖项
之前您了解到元数据用于声明库的传递依赖项。 依赖关系管理器分析此信息,从中构建依赖关系图,并为您解决所有嵌套依赖关系。 使用传递依赖管理可以节省大量时间,并且可以跟踪依赖关系图。
不幸的是,元数据和存储库都不能保证元数据中声明的任何工件实际存在、正确定义或者甚至是需要的。 您可能会遇到缺少依赖项等问题,尤其是在不强制执行任何质量控制的存储库上,这是 Maven Central 上的一个已知问题。 图 5.3 演示了 Maven 存储库的工件生产和消费生命周期。
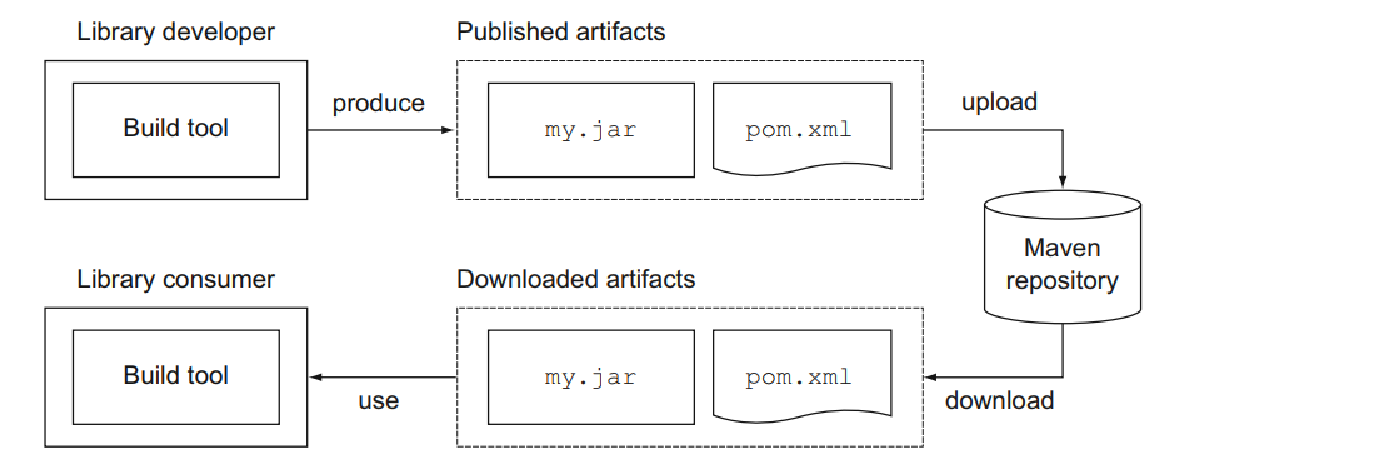
Gradle 允许排除依赖图任何级别上的传递依赖。 或者,您可以省略提供的元数据并设置您自己的传递依赖项定义。
您会发现流行的库会以不同的版本出现在您的传递依赖图中。 对于日志框架等常用功能来说,通常就是这种情况。 依赖管理器试图通过基于某种解决策略选择这些版本之一来找到解决此问题的智能解决方案,以避免版本冲突。 有时您需要调整这些选择。 为此,您首先需要找出哪些依赖项带来了哪个版本的传递依赖项。 Gradle 提供了有意义的依赖关系报告来回答这些问题。 稍后,我们将看到这些报告的实际应用。 现在让我们看看 Gradle 如何借助一个成熟的示例来实现这些想法。