理解 HTTP/2
如果你正在阅读本书,我假设你已经熟悉 HTTP/1.1,或者至少对如何通过网络发起传统的 HTTP API 调用有所了解。我这么认为是因为,作为开发者,我们与之交互的大多数 API 都是由这一协议引入的概念构成的。我说的概念包括头部(headers),它可以提供调用的元数据;正文(body),它包含了主要数据;以及诸如 GET、POST、UPDATE 等动作,它们定义了你打算如何处理正文中的数据。
HTTP/2 保留了这些概念,但在效率、安全性和可用性方面做了一些改进。
HTTP/2 相较于传统的 HTTP/1.1 有两个主要优势:
第一个优势是压缩为二进制。在 HTTP/2 之前,网络上传输的所有内容都是纯文本,是否压缩完全由用户决定。而在 HTTP/2 中,HTTP 的每个语义部分都被转换为二进制格式,这使得计算机在调用之间序列化和反序列化数据时更加高效,从而减少了请求/响应的有效载荷大小。
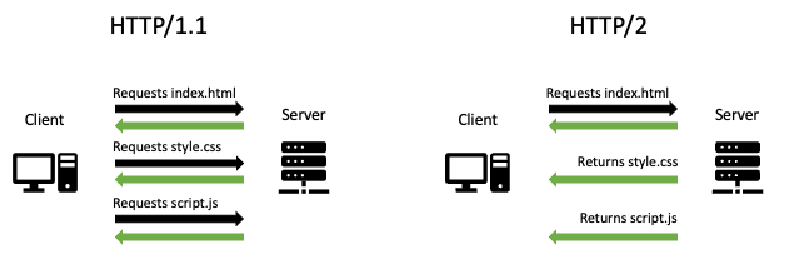
第二个优势是 HTTP/2 提供了一个叫做 “服务器推送”(server push)的功能。这是一个允许服务器在客户端发起一个调用时,返回多个响应的功能。其总体目标是减少服务器和客户端之间的通信,从而减少总的有效载荷,以达到相同的最终结果。如果没有这个功能,当客户端想要请求一个网页及其所有资源时,它必须为每个资源发起一个请求。然而,借助服务器推送功能,客户端只需要发送一次请求来获取网页,服务器会返回该网页,并且还可以返回 CSS 和可能的 JavaScript 脚本。这意味着客户端只需要发起一次请求,而不是三次。
另一个重要的效率提升是通过创建一个长期存在的 TCP 连接,而不是每个请求都创建一个独立的连接。在 HTTP/0.9 中,每次调用都需要先建立一个 TCP 连接,然后在请求完成后关闭该连接。这对于今天互联网的使用来说非常低效。
随后,HTTP/1.1 引入了 KeepAlive 的概念,允许重用单个 TCP 连接。然而,这并不意味着我们可以通过交错的数据包来并发处理多个请求;而是说在完成一个请求后,可以重用相同的连接进行下一个请求。
1997 年该协议发布时,这种做法可能是可以接受的,但如今我们发起的请求越来越多,而且请求的体积也越来越大,等待一个请求完成后再开始下一个请求已经不再可行。HTTP/2 通过创建一个单一的长期连接来解决这个问题,这个连接能够处理多个请求和响应,并以交错的数据包形式进行传输。
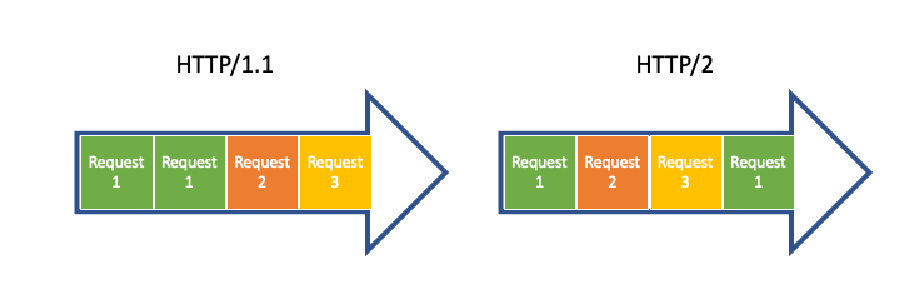
这里展示的显然是 HTTP/2 协议的简化版本。要解释协议的所有实现细节,可能需要一本书。我们在讨论 gRPC 时,主要需要理解的是,在 HTTP/2 中,我们可以通过网络发送结构化的二进制消息,而不是文本;我们可以使用流的方式,让服务器为一个请求发送多个响应;最后,我们能够以高效的方式进行通信,因为我们只需要建立一个 TCP 连接,它可以处理多个请求和响应。
然而,同样重要的是要理解,gRPC 在 HTTP/2 之上有自己的通信协议。这意味着,所有这些 HTTP 协议的改进,都是为了促进通信。gRPC 将这些改进与四种 RPC 操作结合使用。