读写流
现在我们已经了解了 Protobuf 和 gRPC,是时候回到第一章中我们展示的读/写流程了。这样做的目的是让这个流程更详细一些,并包括我们所学到的内容。
作为一个简短的回顾,我们看到写和读数据大致有三个层次:用户代码、gRPC 框架和传输层。在这里,对我们来说最有趣的部分主要是用户代码。我们在第一章并没有深入讨论这些细节,但现在有了更多的知识,我们可以更清晰地理解整个过程。
用户代码层 是开发人员编写的代码,并与 gRPC 框架进行交互。对于客户端来说,这就是调用端点,而对于服务器来说,这就是端点的实现。如果我们继续使用我们的 AccountService 服务,我们可以给出一个具体的读/写流程示例。
我们首先可以将用户代码层分为两个部分:实现和生成的代码。此外,在第一章中,我们提供了一个相对通用的架构,描述了整体流程,并画了一个模糊的组件,称为 “其他参与者”。现在我们可以将服务器和客户端分为两个不同的参与者,得到以下系统:
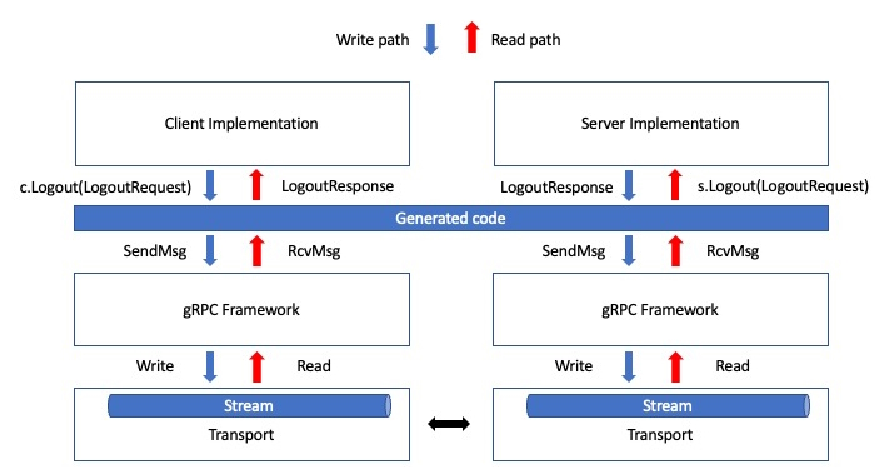
|
在前面的图中,我使用了缩写 “c” 和 “s” 分别表示客户端和服务器。 “c” 是通过调用 |
我们可以在扩展图表后看到几个重要的概念。第一个有趣的概念是生成的代码在不同的通信角色之间共享。我们看到,gRPC Go 插件会生成一个包含服务器和客户端类型的单一文件。这意味着这个文件应该在所有用 Go 编写的角色之间共享。
我们还可以注意到,gRPC 框架和生成的代码为我们抽象化了所有内容。这使我们只需专注于调用带有 Request 对象的端点,并编写处理该 Request 对象并返回 Response 对象的端点。这大大减少了我们需要编写的代码量,从而使我们的代码更具可测试性,因为我们只需要专注于更少的代码。
最后,值得注意的另一点是,我们可以仅通过阅读生成的代码来理解每个端点的参数和返回类型。这非常有帮助,因为生成的代码会被你的 IDE 捕捉并提供自动补全,或者你可以简单地查看一个文件来获取所需的信息。