Flask-SQLAlchemy的基本使用
连接MySQL
在使用 Flask-SQLAlchemy 操作数据库之前,要先创建一个由 Flask-SQLAlchemy 提供的 SQLAlchemy 类的对象。在创建这个类时,要传入当前的 app,然后还需要在 app.config 中设置 SQLALCHEMY_DATABASE_URI,来配置数据库的连接,示例代码如下。
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# MySQL所在的主机名
HOSTNAME = "127.0.0.1"
# MySQL监听的端口号,默认3306
PORT = 3306
# 连接MySQL的用户名,读者用自己设置的
USERNAME = "root"
# 连接MySQL的密码,读者用自己的
PASSWORD = "root"
# MySQL上创建的数据库名称
DATABASE = "database_learn"
app.config['SQLALCHEMY_DATABASE_URI'] = f"mysql+pymysql://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}?charset=utf8"
db = SQLAlchemy(app)
# 测试是否连接成功
with db.engine.connect() as conn:
rs = conn.execute("select 1")
print(rs.fetchone())Flask-SQLAlchemy 在连接数据库时,会从 app.config 中读取 SQLALCHEMY_DATABASE_URI 参数,以上代码分别设置了 MySQL 主机名、端口号、用户名、密码及数据库名称,数据库应该提前在 MySQL 中创建好。SQLALCHEMY_DATABASE_URI 根据不同的数据库有不同的连接方式,MySQL 的连接方式如下。
mysql+[driver]://[username]:[password]@[host]:[port]/[database]?charset=utf8其中 [] 中是变量,需要配置时填充进去即可。如果单击运行后,在 PyCharm 的控制台中打印了 (1,),则说明已经连接成功。
ORM模型
对象关系映射(object relationship mapping,简称 ORM)是一种可以用 Python 面向对象的方式来操作关系型数据库的技术,具有可以映射到数据库表能力的 Python 类我们称之为 ORM 模型。一个 ORM 模型与数据库中的一个表相对应,ORM 模型中的每个类属性分别对应表的每个字段;ORM 模型的每个实例对象对应表中的每条记录。ORM 技术提供了面向对象与 SQL 交互的桥梁,让开发者用面向对象的方式操作数据库,使用 ORM 模型具有以下优势。
-
开发效率高:几乎不需要写原生 SQL 语句,使用纯 Python 的方式操作数据库,大大地提高了开发效率。
-
安全性高:ORM 模型底层代码对一些常见的安全问题,如 SQL 注入做了防护,比直接使用 SQL 语句更加安全。
-
灵活性强:Flask-SQLAlchemy 底层支持 SQLite、MySQL、Oracle、PostgreSQL 等关系型数据库,但针对不同的数据库,ORM 模型的代码几乎一模一样,只需修改少量代码,即可完成底层数据库的更换。
下面用 Flask-SQLAlchemy 来创建一个 User 模型,示例代码如下。
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
username = db.Column(db.String(100))
password = db.Column(db.String(100))
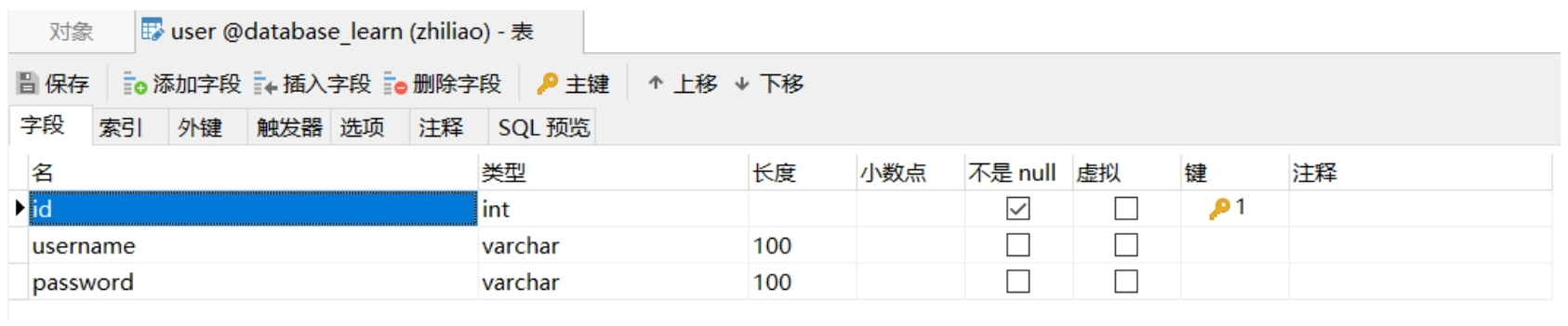
db.create_all()以上代码中,首先创建了一个 User 类,并使它继承自 db.Model 类,所有 ORM 模型必须是 db.Model 的直接或者间接子类。然后通过 __tablename__ 属性,指定 User 模型映射到数据库中表的名称。接着定义了 3 个 db.Column 类型的类属性,分别是 id、username、password,只有使用 db.Column 定义的类属性,才会被映射到数据库表中成为字段。在这个 User 模型中,id 是 db.Integer 类型,在数据库中将表现为整型,并且传递 primary_key=True 参数指定 id 作为主键,传递 autoincrement=True 参数设置 id 为自增长。username 和 password 属性分别指定其类型为 db.String 类型,在数据库中将表现为 varchar 类型,并且指定其最大长度为 100。
最后通过 db.create_all() 把 User 模型映射成数据库中的表。我们可以通过 navicat 软件来查看数据库中的表,如图 5-1 所示。
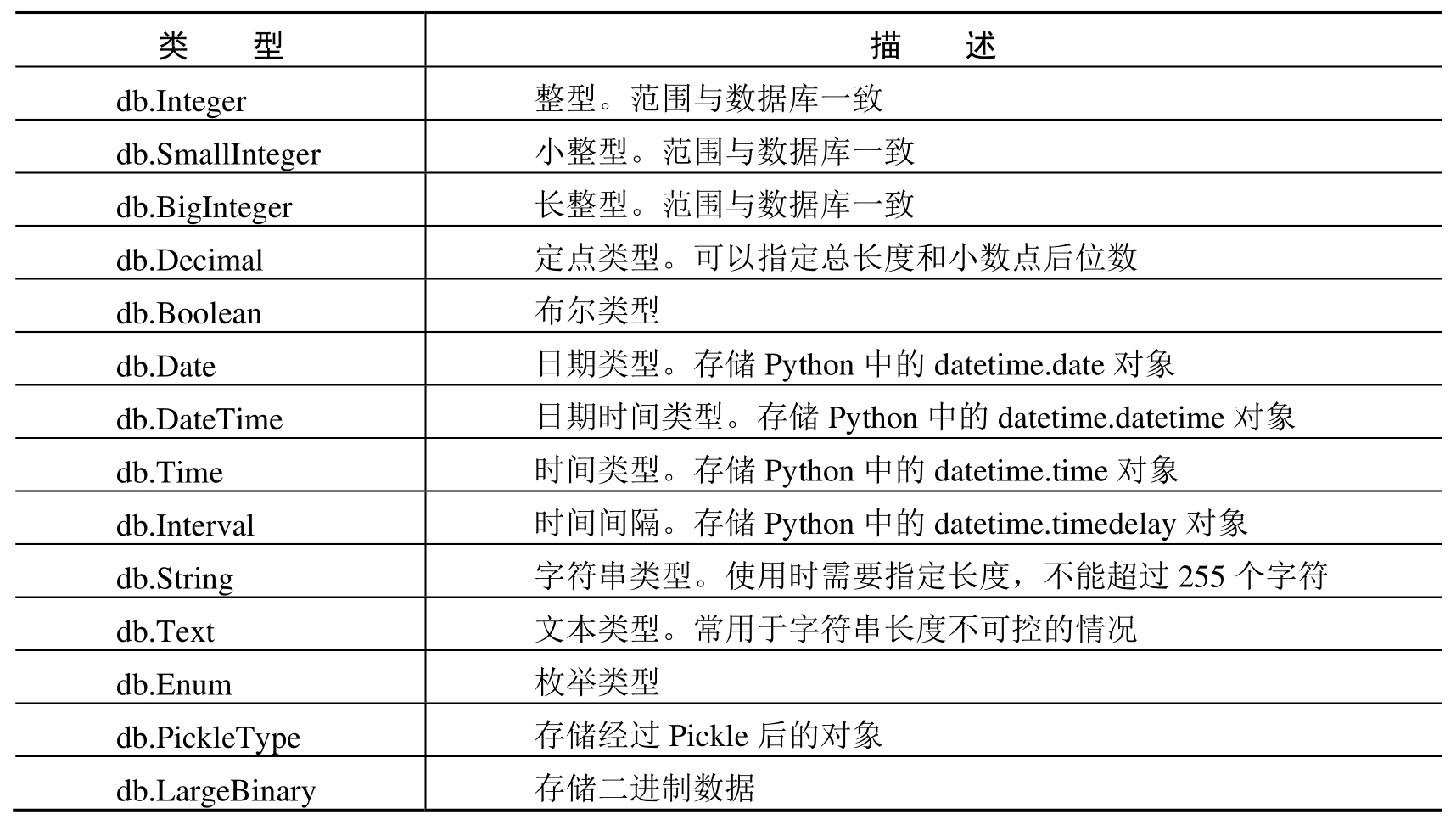
创建数据库的字段类型,除了以上的 db.Integer 和 db.String,还有以下字段类型,如表 5-1 所示。
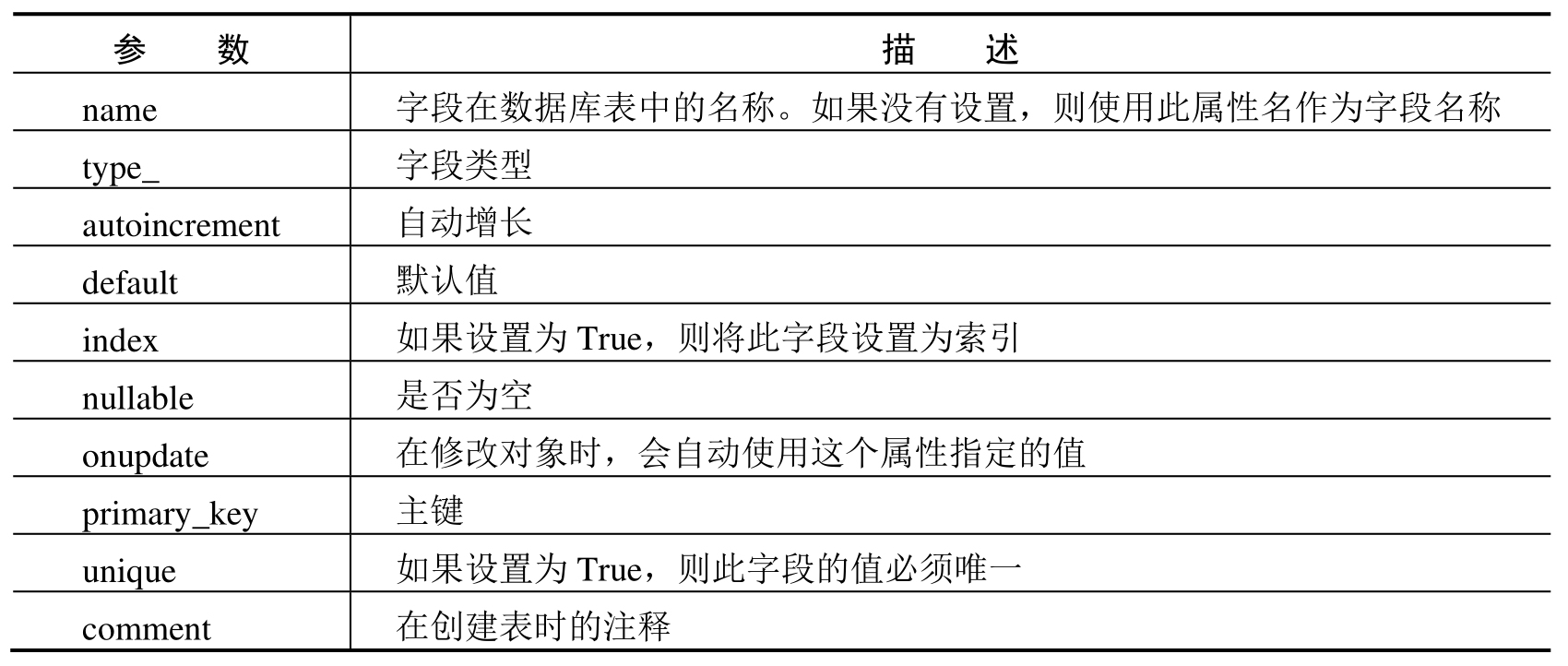
字段在数据库中的表现,都是通过 db.Column 上的参数实现的。db.Column 常用参数如表 5-2 所示。
CRUD操作
使用 ORM 进行 CRUD(create、read、update、delete)操作,需要先把操作添加到会话中,通过 db.session 可以获取到会话对象。会话对象存在内存中,如果要把会话中的操作提取到数据库中,需要调用 db.session.commit() 操作;如果要把会话中的操作回滚,则需要调用 db.session.rollback() 实现。下面分别对 CRUD 操作进行讲解。
Create操作
使用 ORM 创建一条数据非常简单,先使用 ORM 模型创建一个对象,然后添加到会话中,再进行 commit 操作即可,示例代码如下。
@app.route('/user/add')
def user_add():
user1 = User(username="张三", password="111111")
user2 = User(username="李四", password="222222")
user3 = User(username="王五", password="333333")
db.session.add(user1)
db.session.add(user2)
db.session.add(user3)
db.session.commit()
return "用户添加成功!"在以上代码中,首先用 User 类创建了 3 个对象,在创建对象时,必须通过关键字参数给字段赋值,否则 SQLAlchemy 将不知道是给哪个字段赋值,从而报错。由于 id 是作为一个自增长的主键,因此可以不需要赋值。然后再把 3 个对象添加到 session 中,最后再统一进行 commit 操作,即可把数据添加到数据库中。
Read操作
Read 就是查询操作。ORM 模型都是继承自 db.Model,db.Model 内置的 query 属性上有许多方法,可以实现对 ORM 模型的查询操作。query 上的方法可以分为两大类,分别是提取方法和过滤方法。首先来看提取方法,示例代码如下。
@app.route('/user/fetch')
def user_fetch():
# 1. 获取User中所有数据
users = User.query.all()
# 2. 获取主键为1的User对象
user = User.query.get(1)
# 3. 获取第一条数据
user = User.query.first()
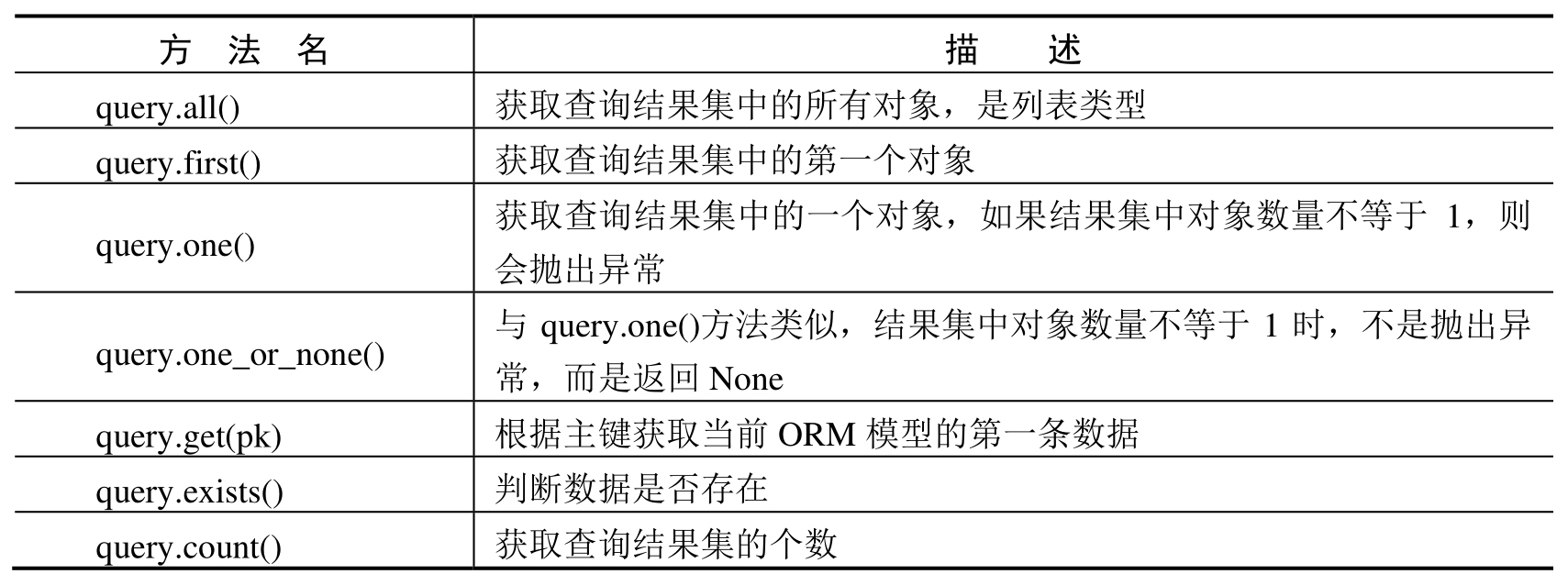
return "数据提取成功!"在以上代码中,通过 all() 方法获取所有 User 对象,通过 get 方法获取指定主键的 User 对象,通过 first() 方法获取第一个 User 对象。提取数据的常用方法如表 5-3 所示。
在查询数据时,经常需要做过滤操作。过滤最常用的两个方法是 filter 和 filter_by,filter 方法传递查询条件,filter_by 方法传递关键字参数,示例代码如下。
@app.route('/user/filter')
def user_filter():
# 1. filter方法:
users = User.query.filter(User.username == "张三").all()
# 2. filter_by方法:
users = User.query.filter_by(username="张三").all()
return "数据过滤成功!"除了 filter 和 filter_by 方法以外,Flask-SQLAlchemy 还提供了以下过滤方法,如表 5-4 所示。
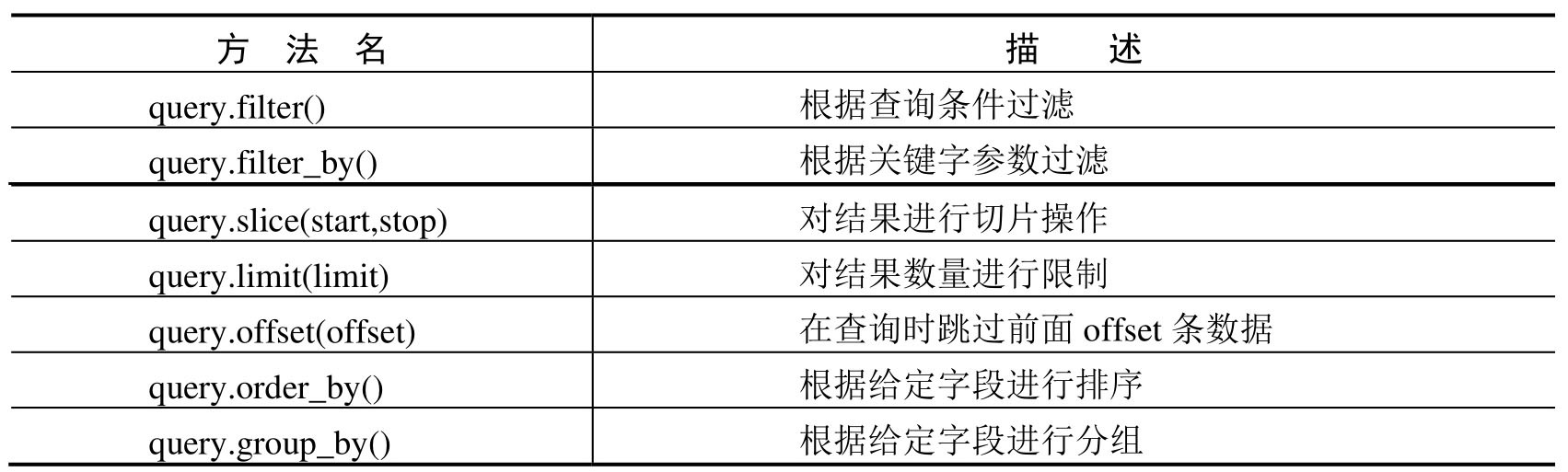
在表 5-4 中,query.slice(start,stop)、query.limit(limit)、query.offset(offset) 方法的使用比较简单,这里不做过多讲解。下面讲解 query.order_by() 和 query.group_by() 的用法。
(1)query.order_by() 的用法如以下代码所示。
from sqlalchemy import desc
@app.route('/user/filter')
def user_filter():
# 正序排序
users = User.query.order_by("id")
users = User.query.order_by(User.id)
# 倒序排序
users = User.query.order_by(db.text("-id"))
users = User.query.order_by(User.id.desc())
# 使用desc函数进行倒序排序
users = User.query.order_by(desc("id"))
for user in users:
print(user.id)
return "数据过滤成功!"以上代码中,以 User 的 id 字段为例(可以换成任何其他的字段),详细地罗列了正序和倒序排序的方法,读者在开发过程中可自行选择合适的方法实现排序。
(2)query.group_by() 方法是根据某个字段进行分组,分组的主要目的是获取分组后的数量、最大值、最小值、平均值、总和等。因为提取的数据不再是某个模型,所以不能通过 <模型>.query 的方式获取,而是通过 db.session.query 来提取,如要获取所有用户名在表中存在的个数,那么可以通过以下代码实现。
from sqlalchemy import func
@app.route('/user/filter')
def user_filter():
# query.group_by方法
users = db.session.query(User.username, func.count(User.id)) \
.group_by("username").all()
return "数据过滤成功!"过滤是数据提取的一个很重要的功能,除了直接使用 == 和 != 关系运算符外,还可以使用以下常用的过滤条件进行过滤,但这些过滤条件只能通过 filter 方法实现。常用的过滤条件如下。
-
like:模糊查询,使用方式与 SQL 语句中的 like 类似,可以在搜索字符左右两边添加 % 来匹配任意字符。contains 方法相当于 like 在搜索字符左右两边都添加 %,例如,contains("张") 与 like("%张%") 是一样的效果。示例代码如下。
users = User.query.filter(User.username.contains("张")) users = User.query.filter(User.username.like("%张%")) -
in:判断值是否在指定数据集中,如果是就提取,否则就不提取。为了不与 Python 中的 in 关键字混淆,在 in 后加下画线,实际的方法名为 in_,示例代码如下。
users = User.query.filter(User.username.in_(["张三","李四","王五"])) -
not in:作用与 in 相反。其使用方式是在 in_ 方法所在代码表达式前添加(
~),示例代码如下。users = User.query.filter(~User.username.in_(['张三'])) -
is null:判断值是否为空,如果为空就提取,否则就不提取。可以通过判断值是否为 none,或通过
is_方法实现,为了不与 Python 中的 in 关键字混淆,同样需要在 is 后加下画线,示例代码如下。users = User.query.filter(User.username==None) users = User.query.filter(User.username.is_(None)) -
is not null:作用与 is null 相反,实际的方法名为 isnot,示例代码如下。
users = User.query.filter(User.username != None) users = User.query.filter(User.username.isnot(None)) -
and:用于同时满足多条件的查询,实际的方法名为
and_,示例代码如下。from sqlalchemy import and_ users = User.query.filter(and_(User.username=="张三",User.id < 10)) -
or:用于满足一个或多个条件的查询,实际的方法名为
or_,示例代码如下。from sqlalchemy import or_ users = User.query.filter(or_(User.username=="张三",User.username=="李四"))
update操作
更新操作分为两种,第一种针对一条数据,第二种针对多条数据。针对一条数据,可以直接修改对象的属性,然后执行 commit 操作即可,示例代码如下。
user = User.query.get(1)
user.username = "张三_重新修改的"
db.session.commit()针对修改多条数据的情况,则是通过调用 filter 或者 filter_by 方法获取 BaseQuery 对象,然后再调用 update 方法,实现批量修改的,示例代码如下。
User.query.filter(User.username.like("%张三%")).update({"password":User.password+"_被修改的"},synchronize_session=False)
db.session.commit()以上代码先通过 filter 方法过滤数据,然后再调用 update 方法,在所有的 password 后面都添加 "_被修改的" 字符串,并且因为使用了 like 方法作为过滤条件,所以需要指定 synchronize_session 参数为 False,最后再调用 commit() 方法即可批量完成数据的修改。
delete操作
删除操作也是分成两种。第一种是删除一条数据,第二种是删除多条数据。删除单条数据的操作方式非常简单,直接调用 db.session.delete 方法即可,示例代码如下。
user = User.query.get(1)
db.session.delete(user)
db.session.commit()删除多条数据的操作方式类似更新多条数据,通过 BaseQuery 的 delete 方法即可实现,示例代码如下。
User.query.filter(User.username.contains("张三")).delete(synchronize_session=False)
db.session.commit()