使用Spring Data JPA持久化数据
尽管 Spring Data JDBC 使持久化数据的工作变得很简单,但 Java Persistence API(JPA) 是另一个处理关系型数据库中数据的流行方案。Spring Data JPA 提供了一种与 Spring Data JDBC 类似的 JPA 持久化方式。
要了解 Spring Data 是如何运行的,我们需要重新开始,将本章前文基于 JDBC 的存储库替换为使用 Spring Data JPA 的存储库。首先,我们需要将 Spring Data JPA 添加到项目的构建文件中。
添加Spring Data JPA到项目中
Spring Boot 应用可以通过 JPA starter 来添加 Spring Data JPA。这个 starter 依赖不仅会引入 Spring Data JPA,还会传递性地将 Hibernate 作为 JPA 实现引入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>如果想要使用不同的 JPA 实现,那么至少需要将 Hibernate 依赖排除出去,并将所选择的 JPA 库包含进来。举例来说,如果想要使用 EclipseLink 来替代 Hibernate,需要像这样修改构建文件:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<exclusions>
<exclusion>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>org.eclipse.persistence.jpa</artifactId>
<version>2.7.6</version>
</dependency>需要注意,根据所选择的 JPA 实现,这里可能还需要其他的变更。请参阅你所选择的 JPA 实现的文档以了解更多细节。现在,我们重新看一下领域对象,并为它们添加注解使其支持 JPA 持久化。
将领域对象标注为实体
在介绍 Spring Data JDBC 时,我们已经看到,Spring Data 做了很多非常棒的事情来帮助我们创建存储库。但是,在使用 JPA 映射注解标注领域对象方面,它却没有提供太多的帮助。我们需要打开 Ingredient、Taco 和 TacoOrder 类,并为其添加一些注解。首先我们看一下 Ingredient 类,如程序清单3.18所示。
package tacos;
import javax.persistence.Entity;
import javax.persistence.Id;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Entity
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
public class Ingredient {
@Id
private String id;
private String name;
private Type type;
public enum Type {
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}为了将 Ingredient 声明为 JPA 实体,它必须添加 @Entity 注解。它的 id 属性需要使用 @Id 注解,以便于将其指定为数据库中唯一标识该实体的属性。注意,这个 @Id 注解来自 javax.persistence 包,不是 Spring Data 在 org.springframework.data.annotation 包中所提供的 @Id 注解。
除此之外,我们不再需要 @Table 注解,也不需要实现 Persistable。尽管我们依然可以使用 @Table 注解,但是在与 JPA 协作的时候,这并不是必需的,它的默认值为类的名称(在本例中,也就是 “Ingredient”)。至于 Persistable 接口,只有在 Spring Data JDBC 中才需要,它用来确定要创建一个新的实体,还是要更新现有的实体,而 JPA 会自动帮助我们处理这一切。
除了 JPA 特定的注解,你可能还会发现,程序3.18在类级别添加了 @NoArgsConstructor 注解。JPA 需要实体带有无参的构造器,Lombok 的 @NoArgsConstructor 注解能够帮助我们实现这一点。但是,我们不想直接使用它,因此将 access 属性设置为 AccessLevel.PRIVATE,从而使其变成 private。因为我们必须要设置 final 属性,所以将 force 设置为 true,这样一来,Lombok 生成的构造器会将属性设置为默认值,即 null、0 或者 false,具体取决于属性的类型。
我们还添加了一个 @AllArgsConstructor 注解,以便创建一个所有属性都完成初始化的 Ingredient 对象。
接下来,我们看一下 Taco 类,看看它是如何标注为 JPA 实体的,如程序清单3.19所示。
package tacos;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.ManyToMany;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Size;
import lombok.Data;
@Data
@Entity
public class Taco {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@NotNull
@Size(min = 5, message = "Name must be at least 5 characters long")
private String name;
private Date createdAt = new Date();
@Size(min = 1, message = "You must choose at least 1 ingredient")
@ManyToMany()
private List<Ingredient> ingredients = new ArrayList<>();
public void addIngredient(Ingredient ingredient) {
this.ingredients.add(ingredient);
}
}与 Ingredient 类似,我们为 Taco 类添加了 @Entity 注解,并为其 id 属性添加了 @Id 注解。我们要依赖数据库自动生成 ID 值,所以在这里还为 id 属性设置了 @GeneratedValue,将它的 strategy 设置为 AUTO。
为了声明 Taco 与其关联的 Ingredient 列表之间的关系,我们为 ingredients 添加了 @ManyToMany 注解。每个 Taco 可以有多个 Ingredient,而每个 Ingredient 可以是多个 Taco 的组成部分。
最后,我们要将 TacoOrder 对象标注为实体。程序清单3.20展示了新的 TacoOrder 类。
package tacos;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import javax.persistence.CascadeType;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.OneToMany;
import javax.validation.constraints.Digits;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.Pattern;
import org.hibernate.validator.constraints.CreditCardNumber;
import lombok.Data;
@Data
@Entity
public class TacoOrder implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private Date placedAt = new Date();
...
@OneToMany(cascade = CascadeType.ALL)
private List<Taco> tacos = new ArrayList<>();
public void addTaco(Taco taco) {
this.tacos.add(taco);
}
}可以看到,TacoOrder 所需的变更与 Taco 几乎如出一辙。但是,有一件事情需要特别注意,那就是我们在它与 Taco 对象列表的关系上使用了 @OneToMany 注解,表明这些 taco 都属于这一个订单。除此之外,cascade 属性设置成了 CascadeType.ALL,因此在删除订单的时候,所有关联的 taco 也都会被删除。
声明JPA存储库
在创建 JdbcTemplate 版本的存储库时,我们需要显式声明希望存储库提供的方法。但是,借助 Spring Data JDBC,我们可以省略掉显式的实现类,只需扩展 CrudRepository 接口。实际上,CrudRepository 同样适用于 Spring Data JPA。例如,新的 IngredientRepository 接口如下所示:
package tacos.data;
import org.springframework.data.repository.CrudRepository;
import tacos.Ingredient;
public interface IngredientRepository
extends CrudRepository<Ingredient, String> {
}实际上,我们为 Spring Data JPA 创建的 IngredientRepository 接口与使用 Spring Data JDBC 时定义的接口完全一样。CrudRepository 接口在众多的 Spring Data 项目中广泛使用,我们无须关心底层的持久化机制是什么。同样,我们可以为 Spring Data JPA 定义 OrderRepository,它与 Spring Data JDBC 中的定义完全相同,如下所示:
package tacos.data;
import org.springframework.data.repository.CrudRepository;
import tacos.TacoOrder;
public interface OrderRepository
extends CrudRepository<TacoOrder, Long> {
}CrudRepository 所提供的方法对于实体通用的持久化场景非常有用。但是,如果我们的需求并不局限于基本持久化,那又该怎么办呢?接下来,我们看一下如何自定义存储库来执行领域特有的查询。
自定义JPA存储库
假设除了 CrudRepository 提供的基本 CRUD 操作之外,我们还需要获取投递到指定邮编(ZIP code)的订单。实际上,只需添加如下的方法声明到 OrderRepository 中,这个问题就解决了:
List<TacoOrder> findByDeliveryZip(String deliveryZip);生成存储库实现时,Spring Data 会检查存储库接口的所有方法,解析方法的名称,并基于被持久化的对象(如本例中的 TacoOrder)来试图推测方法的目的。在本质上,Spring Data 定义了一组小型的领域特定语言(Domain-Specific Language, DSL),在这里,持久化的细节都是通过存储库方法的签名来描述的。
Spring Data 能够知道这个方法要查找 TacoOrder,因为我们使用 TacoOrder 对 CrudRepository 进行了参数化。方法名 findByDeliveryZip() 确定该方法需要根据 deliveryZip 属性匹配来查找 TacoOrder,而 deliveryZip 的值是作为参数传递到方法中来的。
findByDeliveryZip() 方法非常简单,而 Spring Data 也能处理更加有意思的方法名称。存储库的方法由一个动词、一个可选的主题(subject)、关键词By,以及一个断言组成。在 findByDeliveryZip() 这个样例中,动词是find,断言是 DeliveryZip,主题并没有指定,暗含的主题是 TacoOrder。
我们考虑另外一个更复杂的样例。假设我们想要查找投递到指定邮编且在一定时间范围内的订单。在这种情况下,可以将如下的方法添加到 OrderRepository 中,以满足我们的要求:
List<TacoOrder> readOrdersByDeliveryZipAndPlacedAtBetween(
String deliveryZip, Date startDate, Date endDate);图3.2展现了 Spring Data 在生成存储库实现时如何解析和理解 readOrdersByDeliveryZipAndPlacedAtBetween() 方法。我们可以看到,在 readOrdersByDeliveryZipAndPlacedAt Between() 中,动词是 read。Spring Data 会将 get、read 和 find 视为同义词,它们都是用来获取一个或多个实体的。另外,我们还可以使用 count 作为动词,它会返回一个 int 值,代表了匹配实体的数量。
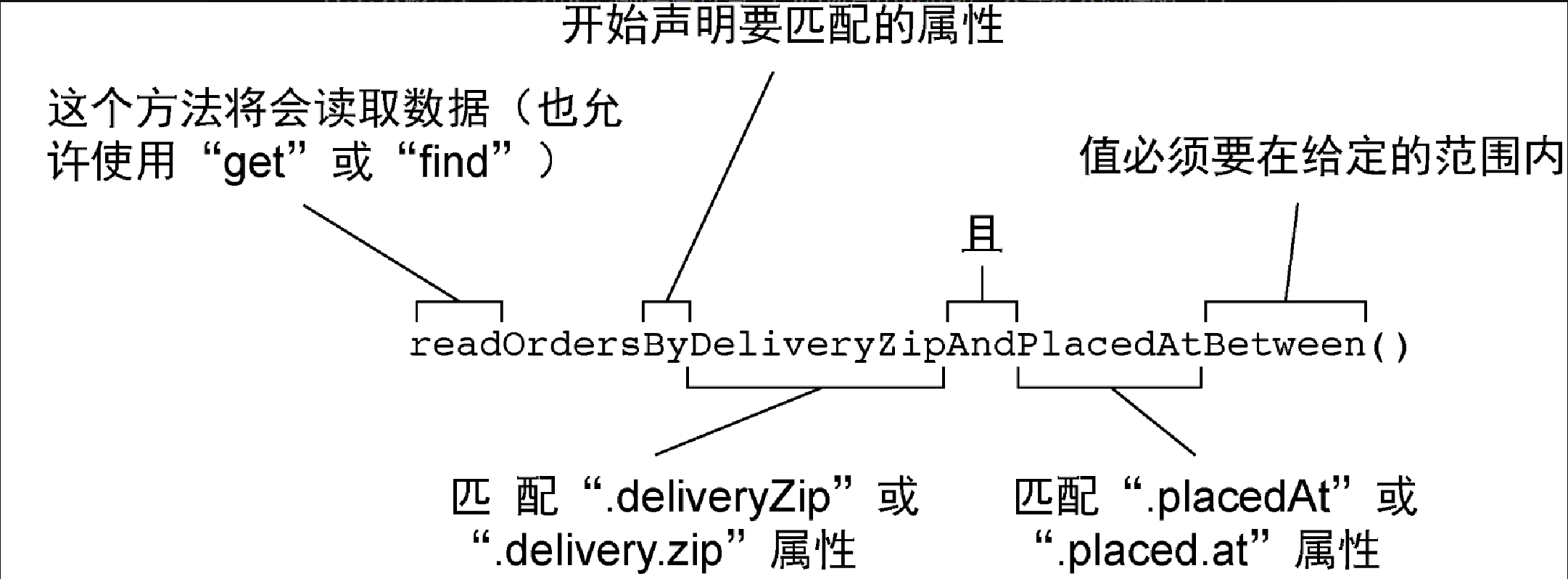
尽管方法的主题是可选的,但是这里要查找的就是 TacoOrder。Spring Data 会忽略主题中大部分的单词,所以你可以将方法命名为 “readPuppiesBy…”,而它依然会去查找 TacoOrder 实体,因为 CrudRepository 是使用 TacoOrder 类进行参数化的。
单词 By 后面的断言是方法签名中最为有意思的一部分。在本例中,断言指定了 TacoOrder 的两个属性:deliveryZip 和 placedAt。deliveryZip 属性的值必须要等于方法第一个参数传入的值。关键字 Between 表明 placedAt 属性的值必须要位于方法最后两个参数的值之间。
除了 Equals 和 Between 操作之外,Spring Data 方法签名还能包括如下的操作符:
-
IsAfter、After、IsGreaterThan、GreaterThan;
-
IsGreaterThanEqual、GreaterThanEqual;
-
IsBefore、Before、 IsLessThan、LessThan;
-
IsLessThanEqual、LessThanEqual;
-
IsBetween、Between ;
-
IsNull、Null;
-
IsNotNull、NotNull;
-
IsIn、In;
-
IsNotIn、NotIn;
-
IsStartingWith、StartingWith、StartsWith;
-
IsEndingWith、EndingWith、EndsWith;
-
IsContaining、Containing、Contains;
-
IsLike、Like;
-
IsNotLike、NotLike;
-
IsTrue、True;
-
IsFalse、False;
-
Is、Equals;
-
IsNot、Not;
-
IgnoringCase、IgnoresCase。
作为 IgnoringCase 或 IgnoresCase 的替代方案,我们还可以在方法上添加 AllIgnoringCase 或 AllIgnoresCase,这样它就会忽略所有 String 对比的大小写。举例来说,请看如下的方法:
List<TacoOrder> findByDeliveryToAndDeliveryCityAllIgnoresCase(
String deliveryTo, String deliveryCity);最后,我们还可以在方法名称的结尾处添加 OrderBy,使结果集根据某个列排序。例如,我们可以按照 deliveryTo 属性排序:
List<TacoOrder> findByDeliveryCityOrderByDeliveryTo(String city);尽管方法名称约定对于相对简单的查询来讲非常有用,但是不难想象,对于更为复杂的查询,方法名可能会面临失控的风险。在这种情况下,可以将方法定义为任何想要的名称,然后为方法添加 @Query 注解,从而明确指明方法调用时要执行的查询,如下所示:
@Query("Order o where o.deliveryCity = 'Seattle'")
List<TacoOrder> readOrdersDeliveredInSeattle();在本例中,通过使用 @Query,我们声明只查询所有投递到 Seattle 的订单。但是,我们可以使用 @Query 执行任何想要的查询,即使有些查询通过方法命名约定很难实现,甚至根本无法实现。
自定义查询方法也可以用于 Spring Data JDBC,但是有如下重要差异。
-
所有的自定义方法都需要使用 @Query。这是因为,与 JPA 不同,我们没有映射元数据帮助 Spring Data JDBC 根据方法名自动推断查询。
-
在 @Query 中声明的必须全部是 SQL 查询,不允许使用 JPA 查询。
在第 4 章,我们会将 Spring Data 的使用扩展至非关系型数据库。到时我们会看到,自定义查询方法以非常相似的方式运行,只不过 @Query 中使用的查询语言是特定地对应底层数据库的。