使用Spring WebFlux
传统的基于Servlet的Web框架,如Spring MVC,本质上都是阻塞式和多线程的,每个连接都会使用一个线程。在请求处理的时候,会在线程池中拉取一个工作者(worker)线程来对请求进行处理。同时,请求线程是阻塞的,直到工作者线程提示它已经完成。
这样的后果就是阻塞式Web框架面临大量请求时无法有效地扩展。缓慢的工作者线程带来的延迟会使情况变得更糟,因为它需要花费更长的时间才能将工作者线程送回池中,以处理另外的请求。在某些场景中,这种设计完全可以接受。事实上,十多年来,大多数Web应用程序的开发方式基本上都是这样的,但是时代在变化。
以前,这些Web应用程序的客户是偶尔浏览网站的人,而现在这些人会频繁消费内容并使用与HTTP API协作的应用程序。如今,所谓的物联网中有汽车、喷气式发动机和其他非传统的客户端(甚至不需要人类),它们会持续地与Web API交换数据。随着消费Web应用的客户端越来越多,可扩展性比以往任何时候都更加重要。
相比之下,异步Web框架能够以更少的线程获得更高的可扩展性,通常它们只需要与CPU核心数量相同的线程。通过使用所谓的事件轮询(event looping)机制(如图12.1所示),这些框架能够用一个线程处理很多请求,使得每次连接的成本更低。
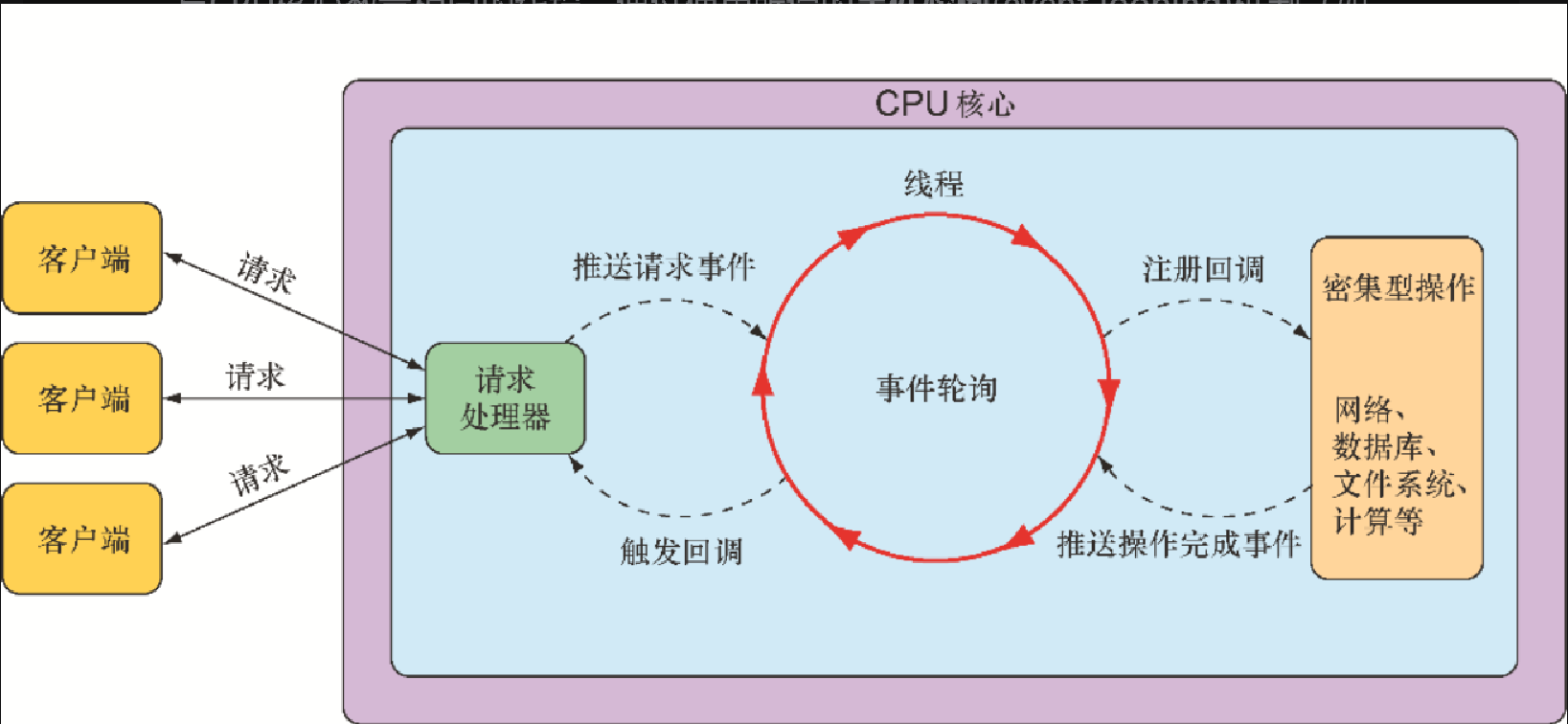
在事件轮询中,所有事情都是以事件的方式来处理的,包括请求以及密集型操作(如数据库和网络操作)的回调。当需要执行成本高昂的操作时,事件轮询会为该操作注册一个回调,这样一来,操作可以被并行执行,而事件轮询则会继续处理其他的事件。
当操作完成时,事件轮询机制会将其作为一个事件,这与请求是类似的。这样的效果是,在面临大量请求负载时,异步Web框架能够以更少的线程实现更好的可扩展性,从而减少线程管理的开销。
Spring提供了一个主要基于Reactor项目的非阻塞、异步Web框架,以解决Web应用和API中更多的可扩展性需求。接下来我们看一下Spring WebFlux,一种面向Spring的反应式Web框架。
Spring WebFlux简介
当Spring团队在思考如何向Web层添加反应式编程模型时,很快就发现如果不在Spring MVC中做大量工作,就很难实现这一点。这涉及在代码中产生分支以决定是否要以反应式的方式来处理请求。本质上,这样做会将两个Web框架打包成一个,并用if语句来区分反应式和非反应式。
与其将反应式编程模型硬塞进Spring MVC中,还不如创建一个单独的反应式Web框架,并尽可能多地借鉴Spring MVC。Spring WebFlux应运而生。Spring定义的完整Web开发技术栈如图12.2所示。
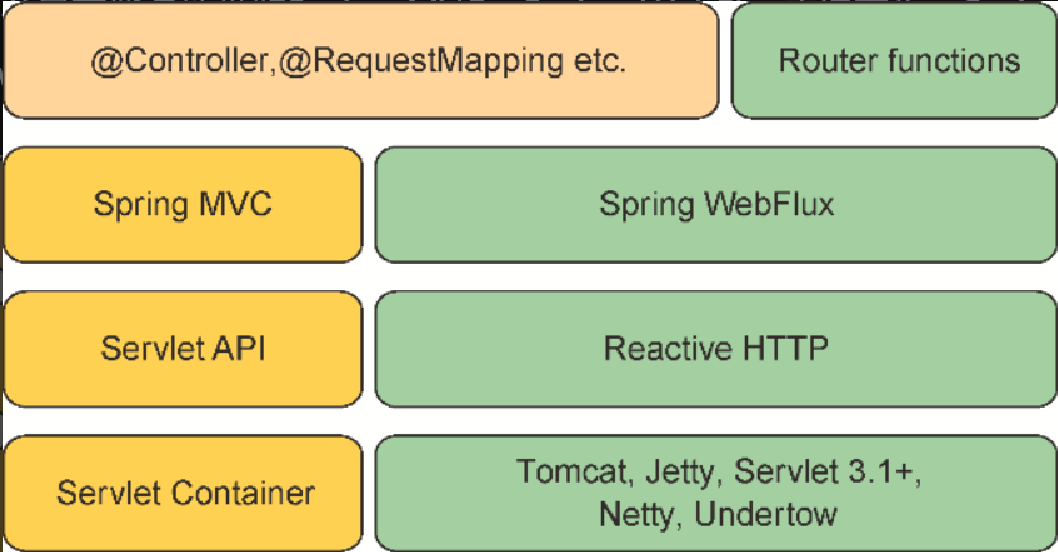
在图12.2的左侧,我们会看到Spring MVC技术栈,这是Spring框架2.5版本就引入的。Spring MVC(在第2章和第7章已经讨论过)建立在Java Servlet API之上,因此需要Servlet容器(比如Tomcat)才能执行。
与之不同,Spring WebFlux(在图12.2右侧)并不会绑定Servlet API,所以它构建在Reactive HTTP API之上,这个API与Servlet API具有相同的功能,只不过是采用了反应式的方式。因为Spring WebFlux没有与Servlet API耦合,所以它的运行并不需要Servlet容器。它可以运行在任意非阻塞Web容器中,包括Netty、Undertow、Tomcat、Jetty或任意Servlet 3.1及以上的容器。
在图12.2中,最值得注意的是左上角,它代表了Spring MVC和Spring WebFlux公用的组件,主要用来定义控制器的注解。因为Spring MVC和Spring WebFlux会使用相同的注解,所以Spring WebFlux与Spring MVC在很多方面并没有区别。
右上角的方框表示另一种编程模型,它使用函数式编程范式来定义控制器,而不是使用注解。在12.2节中,我们会详细地讨论Spring的函数式Web编程模型。
Spring MVC和Spring WebFlux最显著的区别在于需要添加到构建文件中的依赖项不同。在使用Spring WebFlux时,我们需要添加Spring Boot WebFlux starter依赖项,而不是标准的Web starter(例如,spring-boot-starter-web)。在项目的pom.xml文件中,如下所示:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>|
注意:与Spring Boot的大多数starter依赖类似,这个starter也可以在Initializr中通过选中Reactive Web复选框添加到项目中。 |
使用WebFlux有一个很有意思的副作用,即WebFlux的默认嵌入式服务器是Netty而不是Tomcat。Netty是一个异步、事件驱动的服务器,非常适合Spring WebFlux这样的反应式Web框架。
除了使用不同的starter依赖,Spring WebFlux的控制器方法通常要接受和返回反应式类型,如Mono和Flux,而不是领域类型和集合。Spring WebFlux控制器也能处理RxJava类型,如Observable、Single和Completable。
编写反应式控制器
你可能还记得在第7章中我们为Taco Cloud的REST API创建了一些控制器,这些控制器中包含请求处理方法,这些方法会以领域类型(如TacoOrder和Taco)或领域类型集合的方式处理输入和输出。作为提醒,我们看一下第7章中的TacoController片段:
@RestController
@RequestMapping(path = "/api/tacos",
produces = "application/json")
@CrossOrigin(origins = "*")
public class TacoController {
...
@GetMapping(params = "recent")
public Iterable<Taco> recentTacos() {
PageRequest page = PageRequest.of(
0, 12, Sort.by("createdAt").descending());
return tacoRepo.findAll(page).getContent();
}
...
}按照上述编写形式,recentTacos()控制器会处理对“/api/tacos? recent”的HTTP GET请求,返回最近创建的taco列表。具体来讲,它会返回Taco类型的Iterable对象。这主要是因为存储库的findAll()方法返回的就是该类型,或者更准确地说,这个结果来自findAll()方法所返回的Page对象的getContent()方法。
这样的形式运行起来很顺畅,但Iterable并不是反应式类型。我们不能对它使用任何反应式操作,也不能让框架将它视为反应式类型,从而将工作切分到多个线程中。我们希望recentTacos()方法能够返回Flux<Taco>。
这里有一个简单但效果有限的方案:重写recentTacos(),将Iterable转换为Flux。而且,在重写的时候,我们可以去掉分页代码,将其替换为调用Flux的take():
@GetMapping(params = "recent")
public Flux<Taco> recentTacos() {
return Flux.fromIterable(tacoRepo.findAll()).take(12);
}借助Flux.fromIterable(),我们可以将Iterable<Taco>转换为Flux<Taco>。既然我们可以使用Flux,那么就能使用take操作将Flux返回的值限制为最多12个Taco对象。这样不仅使代码更加简洁,也使我们能够处理反应式的Flux,而不是简单的Iterable。
到目前为止,我们编写反应式代码一切都很顺利。但是,如果存储库一开始就给我们一个Flux那就更好了——这样就没有必要进行转换了。如果是这样,那么recentTacos()将会写成如下形式:
@GetMapping(params = "recent")
public Flux<Taco> recentTacos() {
return tacoRepo.findAll().take(12);
}这样就更好了!在理想情况下,反应式控制器会位于反应式端到端栈的顶部,这个栈包括了控制器、存储库、数据库,以及任何可能介于两者之间的服务。这样的端到端反应式栈如图12.3所示。
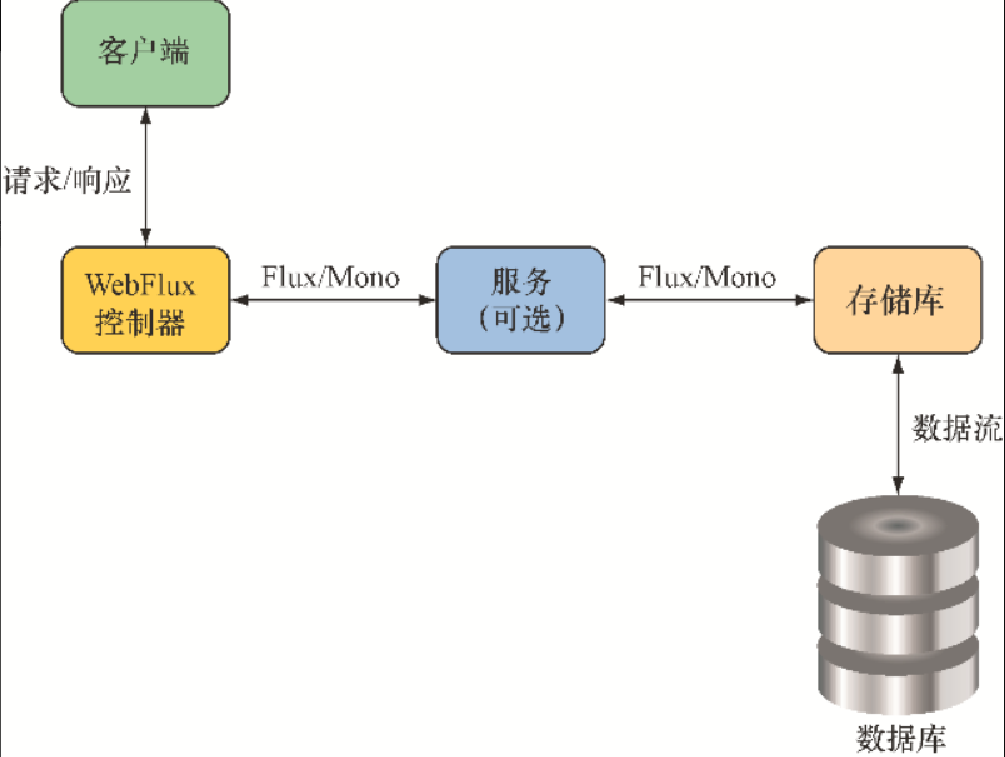
这样的端到端技术栈要求存储库返回Flux,而不是Iterable。在第13章中,我们会详细研究如何编写反应式存储库,这里可以先看一下反应式TacoRepository大致是什么样子的:
package tacos.data;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import tacos.Taco;
public interface TacoRepository
extends ReactiveCrudRepository<Taco, Long> {
}此时,最需要注意的事情在于,除了使用Flux来替换Iterable以及获取Flux的方法外,定义反应式WebFlux控制器的编程模型与非反应式Spring MVC控制器并没有什么差异。它们都使用了@RestController注解以及类级别的@RequestMapping注解。在方法级别,它们都有使用@GetMapping注解的请求处理函数。真正重要的是处理器方法返回了什么类型。
另外值得注意的是,尽管我们从存储库得到了Flux<Taco>,但是我们直接将它返回了,并没有调用subscribe()。框架将会为我们调用subscribe()。这意味着处理“/api/tacos?recent”请求时,recentTacos()方法会被调用,且在数据真正从数据库取出之前就能立即返回。
返回单个值
作为另外一个样例,我们思考一下在第7章中编写的TacoController的tacoById()方法:
@GetMapping("/{id}")
public Taco tacoById(@PathVariable("id") Long id) {
Optional<Taco> optTaco = tacoRepo.findById(id);
if (optTaco.isPresent()) {
return optTaco.get();
}
return null;
}在这里,该方法处理对 “/tacos/{id}” 的GET请求并返回单个Taco对象。因为存储库的findById()返回的是Optional,所以我们必须编写一些笨拙的代码去处理它。但设想一下,findById()返回的是Mono<Taco>,而不是Optional<Taco>,那么我们可以按照如下的方式重写控制器的tacoById():
@GetMapping("/{id}")
public Mono<Taco> tacoById(@PathVariable("id") Long id) {
return tacoRepo.findById(id);
}这样看上去简单多了。更重要的是,通过返回Mono<Taco>来替代Taco,我们能够让Spring WebFlux以反应式的方式处理响应。这样做的结果就是我们的API在面临高负载的时候可以更灵活。
使用RxJava类型
值得一提的是,在使用Spring WebFlux时,虽然使用Flux和Mono是自然而然的选择,但是我们也可以使用像Observable和Single这样的RxJava类型。例如,假设在TacoController和后端存储库之间有一个服务处理RxJava类型,那么recentTacos()方法可以编写为:
@GetMapping(params = "recent")
public Observable<Taco> recentTacos() {
return tacoService.getRecentTacos();
}类似地,tacoById()方法可以编写成处理RxJava Single类型,而不是Mono类型:
@GetMapping("/{id}")
public Single<Taco> tacoById(@PathVariable("id") Long id) {
return tacoService.lookupTaco(id);
}除此之外,Spring WebFlux控制器方法还可以返回RxJava的Completable,后者等价于Reactor中的Mono<Void>。WebFlux也可以返回RxJava的Flowable,以替换Observable或Reactor的Flux。
实现输入的反应式
到目前为止,我们只关心了控制器方法返回什么样的反应式类型。但是,借助Spring WebFlux,我们还可以接受Mono或Flux以作为处理器方法的输入。为了阐述这一点,我们看一下TacoController中原始的postTaco()实现:
@PostMapping(consumes = "application/json")
@ResponseStatus(HttpStatus.CREATED)
public Taco postTaco(@RequestBody Taco taco) {
return tacoRepo.save(taco);
}按照原始的编写方式,postTaco()不仅会返回一个简单的Taco对象,还会接受一个绑定了请求体中内容的Taco对象。这意味着在请求载荷完成解析并初始化为Taco对象之前postTaco()方法不会被调用,也意味着在对存储库的save()方法的阻塞调用返回之前postTaco()不能返回。简言之,这个请求阻塞了两次,分别在进入postTaco()时和在postTaco()调用的过程中发生。通过为postTaco()添加一些反应式代码,我们能够将它变成完全非阻塞的请求处理方法:
@PostMapping(consumes = "application/json")
@ResponseStatus(HttpStatus.CREATED)
public Mono<Taco> postTaco(@RequestBody Mono<Taco> tacoMono) {
return tacoRepo.saveAll(tacoMono).next();
}在这里,postTaco()接受一个Mono<Taco>并调用了存储库的saveAll()方法,该方法能够接受任意的Reactive Streams Publisher实现,包括Mono或Flux。saveAll()方法返回Flux<Taco>,但由于我们提供的是Mono,我们知道该Flux最多只能发布一个 Taco,所以调用next()方法之后,postTaco()方法返回的就是我们需要的Mono<Taco>。
通过接受Mono<Taco>作为输入,该方法会立即调用,而不再等待Taco从请求体中解析生成。另外,存储库也是反应式的,它接受一个Mono并立即返回Flux<Taco>,所以我们调用Flux的next()来获取最终的Mono<Taco>。方法在请求真正处理之前就能返回。
我们也可以像这样实现postTaco():
@PostMapping(consumes = "application/json")
@ResponseStatus(HttpStatus.CREATED)
public Mono<Taco> postTaco(@RequestBody Mono<Taco> tacoMono) {
return tacoMono.flatMap(tacoRepo::save);
}这种方法颠倒了事情的顺序,使tacoMono成为行动的驱动者。tacoMono中的Taco通过flatMap()方法交给了存储库中的save()方法,并返回一个新的Mono<Taco>作为结果。
上述两种方法都是可行的。可能还有其他方式来实现postTaco()。请自行选择对你来说运行效果最好、最合理的方式。
Spring WebFlux是一个非常棒的Spring MVC替代方案,提供了与Spring MVC相同的开发模型,用于编写反应式Web应用。其实Spring 还有另外一项技巧,下面让我们看看如何使用Spring 的函数式编程风格创建反应式API。