识别糟糕的代码
承认我们的代码难以处理是一回事,但要超越这一点并编写优质的代码,我们需要理解为什么代码是糟糕的。让我们来识别这些技术问题。
糟糕的变量命名
优质代码是自描述的且易于更改的,而糟糕的代码则不然。
命名是决定代码是否易于处理的最关键因素。好的名称清楚地告诉读者他们可以期待什么,而糟糕的名称则不能。变量应根据其包含的内容命名。它们应该回答 “我为什么要使用这些数据?它会告诉我什么?”
一个名为 string 的字符串变量命名得很糟糕。我们只知道它是一个字符串,但这并没有告诉我们变量中存储了什么内容,或者我们为什么要使用它。如果这个字符串代表姓氏,那么简单地将其命名为 surname,我们将帮助未来的代码读者更好地理解我们的意图。他们将能够轻松地看到这个变量存储的是姓氏,而不应用于其他目的。
我们在 图1.1 的代码清单中看到的两个字母的变量名是 BASIC 语言的限制。当时无法做得更好,但正如我们所看到的,这些名称并没有帮助。理解 sn 的含义比理解 surname 要困难得多,尤其是如果变量存储的是姓氏。更进一步,如果我们决定将姓氏存储在名为 x 的变量中,我们就为代码的读者制造了真正的困难。他们现在需要解决两个问题:
-
他们必须通过逆向工程代码来推断
x用于存储姓氏 -
每次使用
x时,他们必须在心理上将其与姓氏的概念映射起来
当我们为所有数据使用描述性名称时,比如局部变量、方法参数和对象字段,事情就变得容易得多。就更一般的指导方针而言,以下的 Google 风格指南是一个很好的参考来源: Google Java Style Guide。
|
变量命名的最佳实践
描述数据的内容,而不是数据的类型。 |
现在我们更好地理解了如何命名变量。接下来,让我们看看如何正确命名函数、方法和类。
糟糕的函数、方法和类命名
函数、方法和类的名称都遵循类似的模式。在优质代码中,函数名称告诉我们为什么应该调用该函数。它们描述了该函数将为我们做什么,作为该函数的用户,重点在于结果——即函数返回时会发生什么。我们不会描述该函数的实现方式。这一点很重要,因为它允许我们在以后改变该函数的实现(如果有必要),而名称仍然能够清楚地描述结果。
一个名为 calculateTotalPrice 的函数很清楚地告诉我们它要做什么。它将计算总价。它不会有任何令人惊讶的副作用。它不会尝试做任何其他事情。它会做它所说的。如果我们将其名称缩写为 ctp,那就不那么清楚了。如果我们叫它 func1,那就完全无法告诉我们任何有用的信息。
不良的命名迫使我们每次阅读代码时都要逆向推理每一个决策。我们必须仔细查阅代码,试图找出它的用途。我们不应该这样做。名称应该是抽象的。一个好的名称能够通过将更大的背景理解浓缩为几个词,来加速我们理解代码的能力。
你可以把函数名称看作一个标题,函数内部的代码则是正文。它的工作原理和你现在正在阅读的文本中的标题 “识别糟糕代码” 一样,给我们一个大致的内容概念。从标题中,我们期望接下来的段落会讨论识别糟糕代码的内容,而不会偏离这个主题。
我们希望能够通过软件的标题——函数、方法、类和变量的名称——快速浏览,从而专注于我们现在想做的事情,而不是重新学习过去做了什么。
方法名称与函数名称的处理方式相同。它们都描述了要采取的动作。同样,你可以将函数名称的相同规则应用于方法名称。
|
方法和函数名称的最佳实践
描述结果,而不是实现。 |
同样,类名也遵循描述性规则。一个类通常表示一个单一的概念,因此它的名称应该描述这个概念。如果一个类表示我们系统中的用户档案数据,那么类名 UserProfile 将帮助代码的读者理解这一点。
名称的长度取决于命名空间
关于名称长度的一个额外提示适用于所有命名。名称应具有完整的描述性,但其长度取决于几个因素。当以下情况之一适用时,我们可以选择较短的名称:
-
命名的变量作用域很小,只有几行代码
-
类名本身提供了大部分描述
-
名称存在于某些其他命名空间中,例如类名
让我们通过代码示例来明确每种情况。
以下代码计算一组值的总和,使用了一个简短的变量名 total:
int calculateTotal(List<Integer> values) {
int total = 0;
for (Integer v : values) {
total += v;
}
return total;
}这段代码运行良好,因为很明显 total 表示所有值的总和。在代码的上下文中,我们不需要更长的名称。也许更好的例子是循环变量 v。它的作用域只有一行,在该作用域内,v 表示循环中的当前值。我们可以使用更长的名称,例如 currentValue,但这真的增加了清晰度吗?并没有。
在以下方法中,我们有一个短名称的参数 gc:
private void draw(GraphicsContext gc) {
// 使用gc的代码省略
}我们可以选择如此短名称的原因是 GraphicsContext 类已经承载了大部分描述。如果这是一个更通用的类,例如 String,那么这种短名称技术就没有帮助了。
在最后的代码示例中,我们使用了短方法名 draw():
public class ProfileImage {
public void draw(WebResponse wr) {
// 代码省略
}
}这里的类名具有高度描述性。我们在系统中使用的 ProfileImage 类名通常用于描述用户个人资料页面上显示的头像或照片。draw() 方法负责将图像数据写入 WebResponse 对象。我们可以选择更长的方法名,例如 drawProfileImage(),但这只是重复了类名已经明确的信息。这样的细节使 Java 因其冗长而闻名,我认为这是不公平的;通常是我们 Java 程序员冗长,而不是 Java 本身。
我们已经看到了如何通过正确命名使代码更易于理解。接下来,让我们看看糟糕代码中的另一个大问题——使用容易导致逻辑错误的代码结构。
容易出错的代码结构
糟糕代码的另一个明显特征是使用了容易出错的代码结构和设计。在代码中,总是有多种方式可以实现相同的功能。其中一些方式比其他方式更容易引入错误。因此,选择能够主动避免错误的编码方式是明智的。
让我们比较两个不同版本的计算总和的函数,并分析错误可能存在的地方:
int calculateTotal(List<Integer> values) {
int total = 0;
for (int i = 0; i < values.size(); i++) {
total += values.get(i);
}
return total;
}前面的代码是一个简单的方法,它接收一个整数列表并返回它们的总和。这是自 Java 1.0.2 以来就存在的代码类型。它确实有效,但容易出错。为了使这段代码正确,我们需要确保以下几点:
-
确保
total初始化为 0,而不是其他值 -
确保循环索引
i初始化为 0 -
确保在循环比较中使用
<,而不是<=或== -
确保循环索引
i每次递增 1 -
确保将列表中当前索引的值加到
total上
有经验的程序员通常能一次性正确完成这些操作。但我的观点是,存在可能在这些地方出错的风险。我曾见过使用 <= 而不是 < 的错误,结果代码因 ArrayIndexOutOfBounds 异常而失败。另一个容易犯的错误是在累加时使用 = 而不是 +=,这会导致只返回最后一个值,而不是总和。我甚至曾因为纯粹的拼写错误而犯过这个错误——我确实以为自己输入了正确的内容,但当时打字太快,结果出错了。
显然,完全避免这些错误是更好的选择。如果错误不可能发生,那么它就不会发生。我将这一过程称为 设计消除错误。这是一种基本的干净代码实践。为了了解如何在前面的示例中实现这一点,让我们看看以下代码:
int calculateTotal(List<Integer> values) {
return values.stream().mapToInt(v -> v).sum();
}这段代码实现了相同的功能,但它本质上更安全。我们没有 total 变量,因此无法错误地初始化它,也不会忘记将值添加到它上面。我们没有循环,因此也没有循环索引变量。我们无法在循环结束时使用错误的比较,因此不会出现 ArrayIndexOutOfBounds 异常。这段代码的实现中,出错的可能性要小得多。它通常也使代码更清晰易读。这反过来有助于新开发者的入职、代码审查、添加新功能以及结对编程。
每当我们有机会选择使用出错可能性更小的代码时,我们应该选择这种方式。通过尽可能保持代码无错误和简单,我们可以为自己和同事减轻负担。我们可以使用更健壮的代码结构,减少错误的藏身之处。
值得一提的是,这两个版本的代码都存在 整数溢出错误。如果我们相加的整数总和超出了允许的范围(-2147483648 到 2147483647),代码将产生错误的结果。然而,关键点仍然成立:后一个版本出错的地方更少。从结构上看,它是更简单的代码。
现在我们已经看到了如何避免糟糕代码中典型的错误,接下来让我们转向其他问题领域:耦合性与内聚性。
耦合性与内聚性
如果我们有多个 Java 类,耦合性 描述的是这些类之间的关系,而 内聚性 描述的是每个类内部方法之间的关系。
一旦我们正确掌握了耦合性和内聚性的程度,我们的软件设计就会变得更易于处理。我们将在 第 7 章:驱动设计——TDD 与 SOLID 中学习相关的技术。现在,让我们先了解如果处理不当会面临的问题,从低内聚性的问题开始。
类内部的低内聚性
低内聚性 描述的是代码中将许多不同的功能混杂在一个地方的情况。以下 UML 类图展示了一个方法之间低内聚的类的示例:

这个类中的代码试图结合过多的职责。这些职责并不明显相关——我们正在写入数据库、发送欢迎邮件以及渲染网页。这种多样化的职责使我们的类更难以理解和更改。考虑我们可能需要更改这个类的不同原因:
-
数据库技术的更改
-
网页布局的更改
-
网页模板引擎技术的更改
-
邮件模板引擎技术的更改
-
新闻生成算法的更改
有许多原因可能导致我们需要更改这个类中的代码。最好给类一个更精确的焦点,这样更改它们的理由就会更少。理想情况下,任何一段代码应该只有一个更改的理由。
理解低内聚性的代码很困难。我们被迫同时理解许多不同的功能。在内部,代码之间相互关联。更改一个方法通常会导致其他方法的更改。使用这个类也很困难,因为我们需要构建它的所有依赖项。在我们的示例中,我们混合了模板引擎、数据库和创建网页的代码。这也使得这个类非常难以测试。我们需要在运行测试方法之前设置所有这些内容。像这样的类,其可重用性也很有限。这个类与其内部混合的功能紧密绑定。
类之间的高耦合性
高耦合性描述的是一个类在使用之前需要连接到多个其他类的情况。这使得它难以单独使用。我们需要在可以使用这个类之前,设置并正确运行那些支持类。出于同样的原因,如果不理解它与许多其他类的交互,我们也无法完全理解这个类。例如,以下 UML 类图展示了彼此之间高度耦合的类:
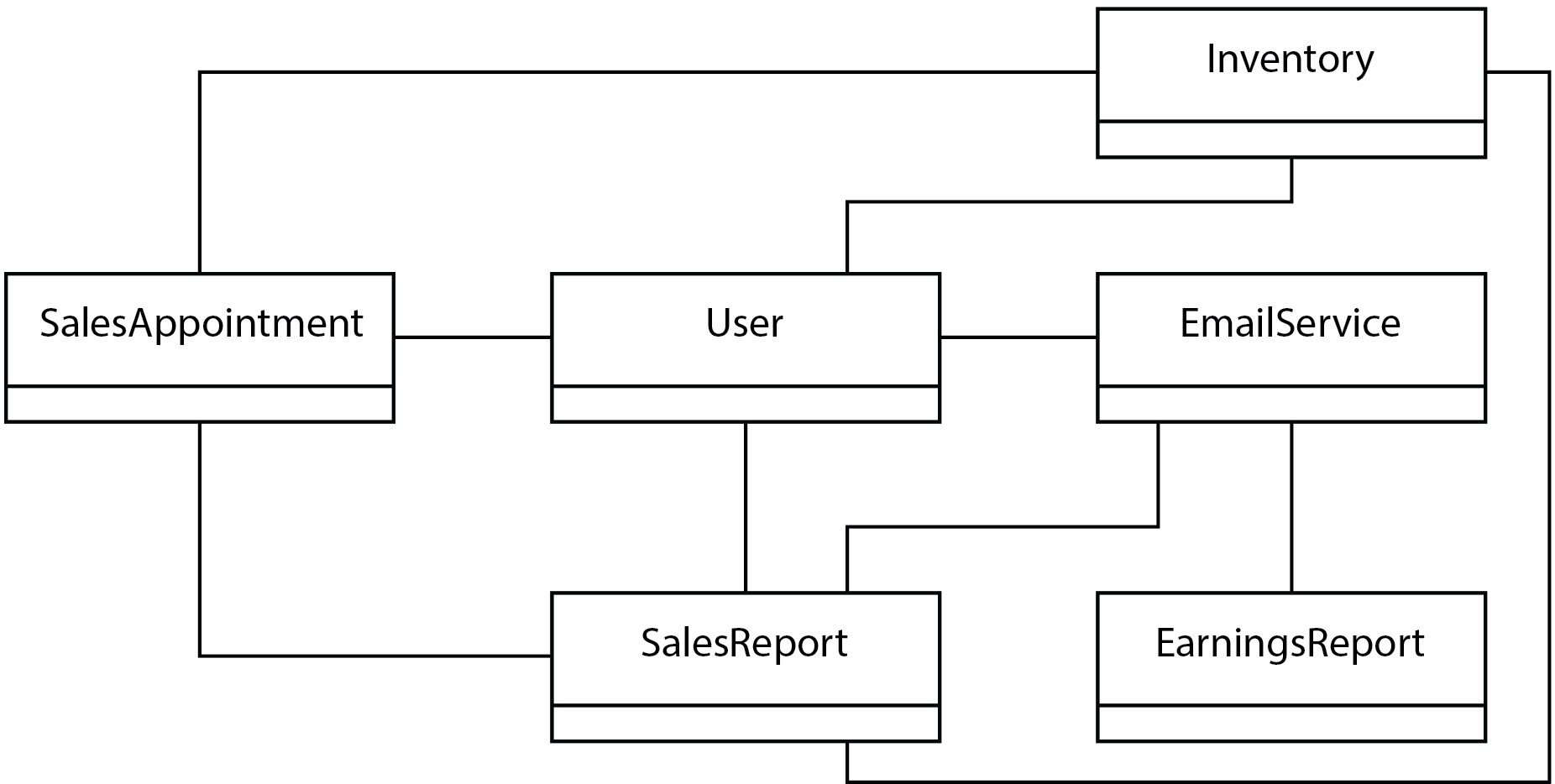
在这个虚构的销售跟踪系统示例中,多个类需要相互交互。中间的 User 类与四个其他类耦合:Inventory、EmailService、SalesAppointment 和 SalesReport。这使得它比耦合较少其他类的类更难使用和测试。这里的耦合性是否过高?也许不是,但我们可以想象其他设计可以减少这种耦合。关键是要意识到设计中类之间的耦合程度。一旦我们发现类与其他类有许多连接,我们就知道在理解、维护和测试它们时会遇到问题。
我们已经看到了 高耦合性 和 低内聚性 的技术元素如何使我们的代码难以处理,但糟糕代码还有一个社会层面的影响。让我们考虑糟糕代码对开发团队的影响。