依赖倒置来拯救
在本节中,我们将回顾一种称为六边形架构的设计方法,基于我们已经知道的 SOLID 原则。使用这种方法使我们能够更有效地在更多代码库中使用 TDD。
我们之前在这本书中学习了依赖倒置原则。我们看到它帮助我们隔离了一些我们想要测试的代码与其协作者的细节。我们注意到这对于测试连接到我们无法控制的外部系统的东西很有用。我们看到了单一职责原则如何指导我们将软件分解为更小、更专注的任务。
将这些想法应用到我们之前的销售报告示例中,我们将得到一个改进的设计,如下图所示:
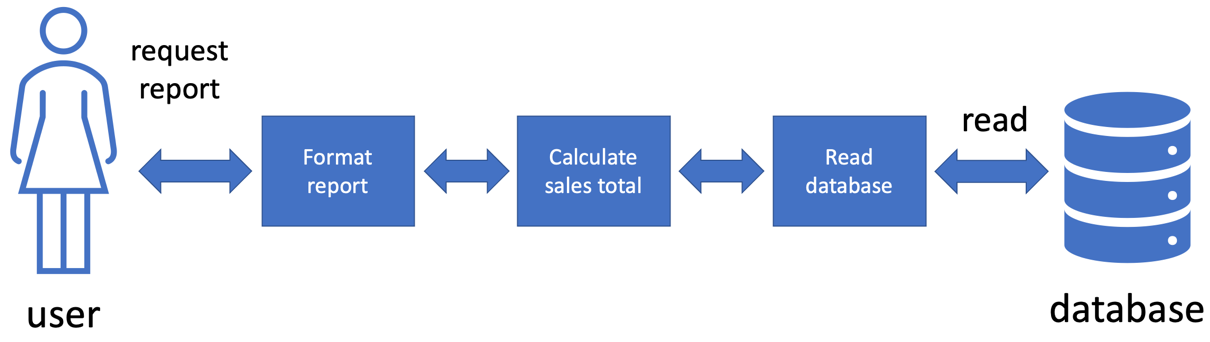
前面的图表显示了我们如何应用 SOLID 原则来拆分我们的销售报告代码。我们使用了单一职责原则将整体任务分解为三个独立的任务:
-
格式化报告
-
计算销售总额
-
从数据库中读取销售数据
这已经使应用程序更容易使用。更重要的是,我们已经将计算销售总额的代码与用户和数据库隔离。这个计算不再直接访问数据库。它通过另一段只负责此操作的代码进行。同样,计算结果也不会直接格式化并发送给用户。另一段代码负责这一点。
我们也可以在这里应用依赖倒置原则。通过倒置对格式化和数据库访问代码的依赖,我们的计算销售总额现在不再需要知道它们的任何细节。我们已经取得了重大突破:
-
计算代码现在完全与数据库和格式化隔离
-
我们可以插入任何可以访问任何数据库的代码
-
我们可以插入任何可以格式化报告的代码
-
我们可以使用测试替身代替格式化和数据库访问代码
最大的好处是我们可以插入任何可以访问任何数据库的代码,而无需更改计算代码。例如,我们可以从 Postgres SQL 数据库更改为 Mongo NoSQL 数据库,而无需更改计算代码。我们可以使用测试替身作为数据库,以便我们可以将计算代码作为 FIRST 单元测试进行测试。这些是非常显著的优势,不仅在 TDD 和测试方面,而且在代码组织方面也是如此。考虑到这个单一销售报告解决方案,我们已经从纯粹的编写代码转向了软件工程。我们不仅考虑让代码工作,还专注于使代码易于使用。接下来的几节将探讨我们如何概括这种方法,从而形成六边形架构。我们将了解这种方法如何提供一种逻辑代码组织,帮助我们更有效地应用 TDD。
将此方法推广到六边形架构
单一职责原则和依赖倒置的这种组合似乎给我们带来了一些好处。我们能否将这种方法扩展到整个应用程序并获得相同的好处?我们能否找到一种方法将所有应用程序逻辑和数据表示与外部影响的约束分开?我们当然可以,这种设计的通用形式如下图所示:
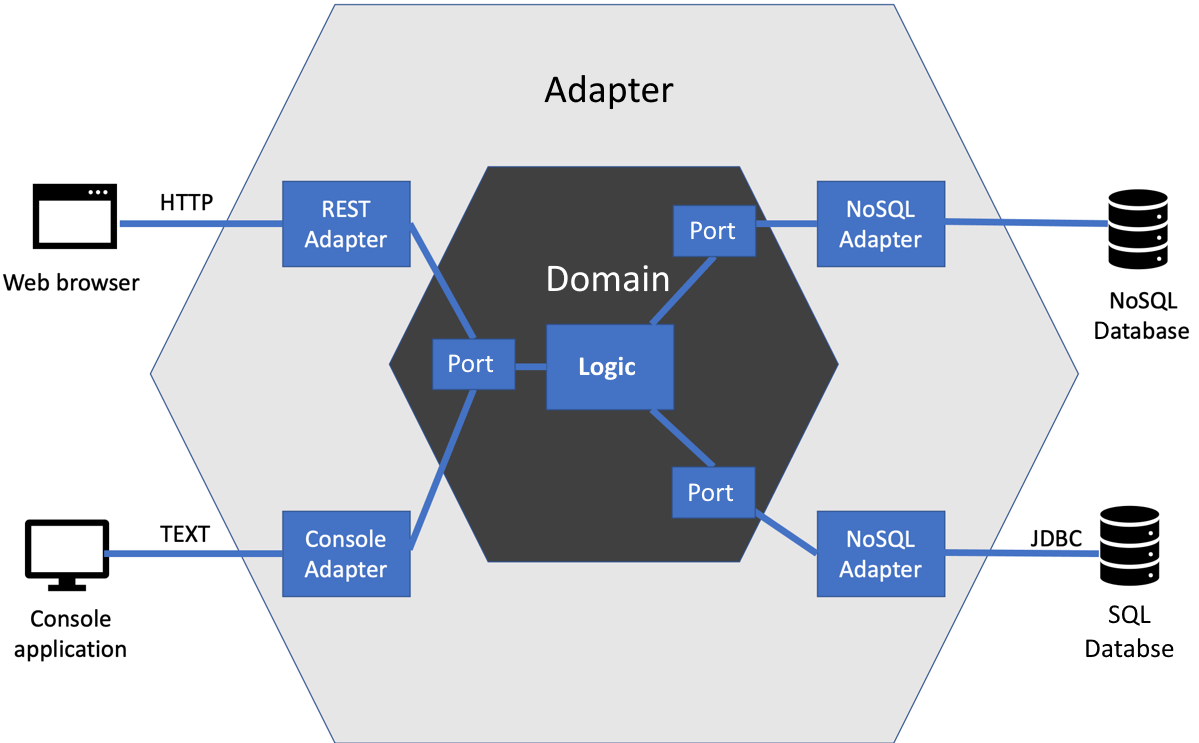
前面的图表显示了当我们将对依赖倒置和单一职责的使用推广到整个应用程序时会发生什么。它被称为六边形架构,也称为端口和适配器,这是 Alastair Cockburn 最初使用的术语,他首次描述了这种方法。好处是它完全将我们应用程序的核心逻辑与外部系统的细节隔离开来。这有助于我们测试该核心逻辑。它还为我们代码的良好工程设计提供了一个合理的模板。
六边形架构组件概览
为了为我们提供这种核心应用程序逻辑的隔离,六边形架构将整个程序分为四个空间:
-
外部系统,包括网络浏览器、数据库和其他计算服务
-
适配器实现外部系统所需的特定 API
-
端口是我们应用程序从外部系统需要的抽象
-
领域模型包含我们的应用程序逻辑,没有外部系统的细节
我们应用程序的核心是领域模型,周围是它从外部系统需要的支持。它间接使用但不被这些外部系统定义。让我们更详细地了解六边形架构中的每个组件,以了解每个组件的职责和不负责的内容。
外部系统连接到适配器
外部系统是存在于我们代码库之外的所有东西。它们包括用户直接交互的东西,例如网络浏览器和前面图表中的控制台应用程序。它们还包括数据存储,例如 SQL 数据库和 NoSQL 数据库。其他常见的外部系统示例包括桌面图形用户界面、文件系统、下游 Web 服务 API 和硬件设备驱动程序。大多数应用程序需要与这些系统交互。
在六边形架构中,我们的应用程序代码的核心不知道如何与外部系统交互的任何细节。与外部系统通信的职责被赋予了一段称为适配器的代码。
例如,下图显示了网络浏览器如何通过 REST 适配器连接到我们的代码:
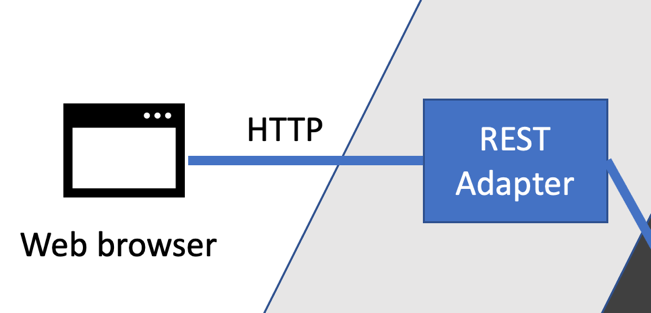
在前面的图表中,我们可以看到网络浏览器连接到 REST 适配器。这个适配器理解 HTTP 请求和响应,这是网络的核心。它还理解 JSON 数据格式,通常使用库将 JSON 数据转换为我们的代码的某种内部表示。这个适配器还将理解我们为应用程序的 REST API 设计的特定协议——我们作为 API 提出的 HTTP 动词、响应、状态代码和 JSON 编码的有效负载数据的精确序列。
|
适配器封装了我们系统与外部系统交互所需的所有知识——仅此而已。这些知识由外部系统的规范定义。其中一些可能是我们自己设计的。 |
适配器的单一职责是知道如何与外部系统交互。如果该外部系统更改其公共接口,只有我们的适配器需要更改。
适配器连接到端口
向领域模型移动,适配器连接到端口。端口是领域模型的一部分。它们抽象了适配器对其外部系统的复杂知识的细节。端口回答一个稍微不同的问题:我们需要那个外部系统做什么?端口使用依赖倒置原则将我们的领域代码与适配器的任何细节隔离开来。它们纯粹是根据我们的领域模型编写的:
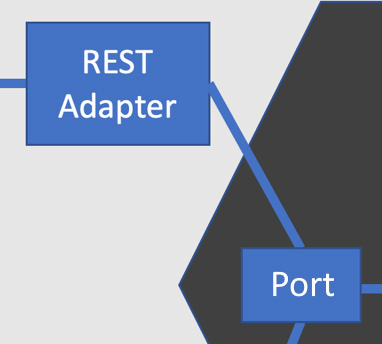
前面描述的 REST 适配器封装了运行 REST API 的细节,使用 HTTP 和 JSON 的知识。它连接到一个命令端口,该端口提供了我们从网络——或任何其他地方——传入的命令的抽象。鉴于我们之前的销售报告示例,命令端口将包括一种技术无关的请求销售报告的方式。在代码中,它可能看起来像这样简单:
package com.sales.domain;
import java.time.LocalDate;
public interface Commands {
SalesReport calculateForPeriod(LocalDate start, LocalDate end);
}这个代码片段具有以下特点:
-
没有对
HttpServletRequest或任何与 HTTP 相关的内容的引用 -
没有对 JSON 格式的引用
-
对我们领域模型的引用——
SalesReport和java.time.LocalDate -
public访问修饰符,因此可以从 REST 适配器调用
这个接口是一个端口。它为我们提供了一种通用方式来从我们的应用程序获取销售报告。参考图9.3,我们可以看到控制台适配器也连接到此端口,为用户提供了我们应用程序的命令行界面。原因是,虽然用户可以使用不同类型的外部系统——网络和命令行——访问我们的应用程序,但我们的应用程序在两种情况下都做同样的事情。它只支持一组命令,无论这些命令是从哪里请求的。获取 SalesReport 对象就是这样,无论你从哪种技术请求它。
|
端口提供了我们应用程序从外部系统需要的逻辑视图,而不限制这些需求在技术上应该如何满足。 |
端口是我们倒置依赖的地方。端口代表我们的领域模型需要这些外部系统的原因。如果适配器代表如何,端口代表为什么。
端口连接到我们的领域模型
链中的最后一步是连接到领域模型本身。这是我们应用程序逻辑所在的地方。将其视为我们应用程序解决的问题的纯逻辑。由于端口和适配器,领域逻辑不受外部系统细节的约束:
领域模型代表我们用户想要做的事情,用代码描述。每个用户故事都在这里用代码描述。理想情况下,这一层的代码使用我们解决问题的语言,而不是技术细节。当我们做得好时,这段代码就变成了讲故事——它用用户告诉我们的术语描述了用户关心的动作。它使用他们的语言——我们用户的语言——而不是晦涩的计算机语言。
领域模型可以包含用任何范式编写的代码。它可能使用函数式编程(FP)思想。它甚至可能使用面向对象编程(OOP)思想。它可能是过程式的。它甚至可能使用我们声明性配置的现成库。我目前的风格是使用 OOP 进行程序的整体结构和组织,然后在对象方法内部使用 FP 思想来实现它们。无论我们如何实现这个领域模型,对六边形架构或 TDD 都没有影响。无论哪种方式适合你的编码风格,只要使用端口和适配器的思想,这里都很好。
|
领域模型包含描述用户问题如何解决的代码。这是我们应用程序创造业务价值的基本逻辑。 |
整个应用程序的中心是领域模型。它包含将用户故事变为现实的逻辑。
黄金法则 – 域永远不直接连接适配器
为了保持将领域模型与适配器和外部系统隔离的好处,我们遵循一个简单的规则:领域模型从不直接连接到任何适配器。这总是通过端口完成的。
当我们的代码遵循这种设计方法时,检查我们是否正确分割了端口和适配器是很简单的。我们可以做出两个高级结构决策:
-
领域模型位于域包(和子包)中
-
适配器位于适配器包(和子包)中
我们可以分析代码以检查域包中的任何内容是否不包含来自适配器包的导入语句。导入检查可以在代码审查或配对/群体编程中视觉上进行。静态分析工具如 SonarQube 可以将导入检查自动化作为构建管道的一部分。
|
六边形架构的黄金规则
领域模型从不直接连接到适配器层中的任何内容,以便我们的应用程序逻辑不依赖于外部系统的细节。 适配器连接到端口,以便连接到外部系统的代码被隔离。 端口是领域模型的一部分,以创建外部系统的抽象。 领域模型和适配器仅依赖于端口。这是依赖倒置在工作。 |
这些简单的规则使我们的设计保持一致,并保持领域模型的隔离。