CI/CD 流水线和测试环境
CI/CD 流水线和测试环境是软件工程中的重要组成部分。它们是开发工作流程的一部分,将我们从编写代码带到将系统交付到用户手中。在这一部分,我们将探讨这些术语的含义,以及如何在我们的项目中使用这些理念。
什么是 CI/CD 流水线?
让我们从定义这些术语开始:
-
CI 代表持续集成(Continuous Integration)
集成是指我们将单独的软件组件组合在一起,形成一个整体。持续集成意味着我们在编写新代码时始终在进行这一过程。
-
CD 代表持续交付(Continuous Delivery)或持续部署(Continuous Deployment)
我们稍后会讨论两者的区别,但在这两种情况下,核心思想是我们将集成软件的最新版本交付给利益相关者。持续交付的目标是,如果我们愿意,只需点击一个按钮,就可以将每一个代码更改部署到生产环境中。
需要注意的是,CI/CD 是一种工程实践,而不是一套工具。无论我们如何实现它,CI/CD 的目标都是构建一个始终处于可用状态的系统。
为什么我们需要持续集成?
在测试金字塔的背景下,我们需要 CI/CD 的原因是为了将所有测试整合在一起。我们需要一种机制来使用最新的代码构建整个软件。我们需要运行所有测试,并确保它们全部通过,然后才能打包和部署代码。如果有任何测试失败,我们就知道代码不适合部署。为了确保我们能够快速获得反馈,我们必须按照从最快到最慢的顺序运行测试。我们的CI流水线将首先运行单元测试,然后是集成测试,最后是端到端测试和验收测试。如果有任何测试失败,构建将生成该阶段的测试失败报告,然后停止构建。如果所有测试都通过,我们将打包代码,准备部署。
更广泛地说,集成 的概念是构建软件的基础,无论我们是单独工作还是在开发团队中工作。当单独工作时,按照本书中的实践,我们正在用多个构建块构建软件。有些是我们自己制作的,而对于其他部分,我们选择了合适的库组件并使用它们。我们还编写了适配器——允许我们访问外部系统的组件。所有这些都需要集成——作为一个整体结合在一起——将我们的代码行转化为一个可工作的系统。
在团队中工作时,集成甚至更为重要。我们不仅需要将我们编写的部分整合在一起,还需要整合团队其他成员编写的所有其他部分。整合同事正在进行的工作是紧迫的。我们最终会基于其他人已经编写的内容进行构建。当我们在主要集成代码库之外工作时,存在不包括最新设计决策和可重用代码片段的风险。
下图展示了 CI 的目标:
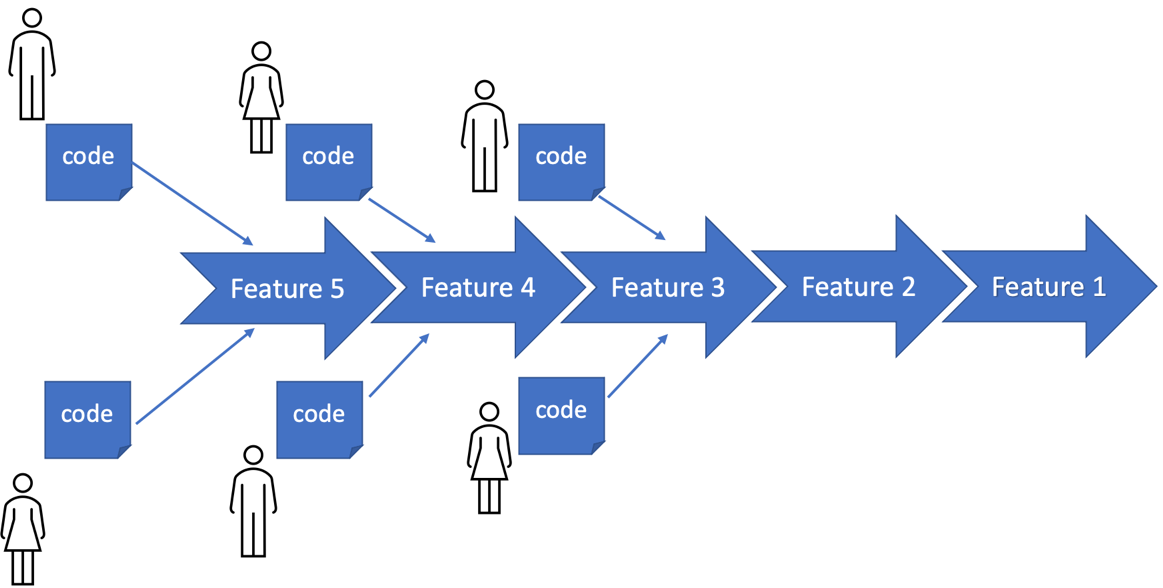
CI 的动机是为了避免经典的瀑布式开发陷阱,即团队在遵循计划的同时,作为孤立的个体编写代码,并仅在最后进行集成。很多时候,这种集成未能产生可工作的软件。通常存在一些误解或缺失的部分,导致组件无法组合在一起。在瀑布式项目的后期阶段,修复错误的成本很高。
不仅仅是大型团队和大型项目会遭受这种情况。我的转折点是在为英国的RAF红箭飞行表演队编写飞行模拟器游戏时。我们两个人根据我们商定的共同API开发了这款游戏。当我们第一次尝试整合我们的部分时——当然是在凌晨3点,在公司总经理面前——游戏运行了大约三帧,然后就崩溃了。哎呀!我们缺乏 CI 的实践给我们上了一堂尴尬的课。如果能更早地知道这种情况会发生,尤其是在没有总经理观看的情况下,那将会更好。
为什么我们需要持续交付?
如果 CI 的核心是将我们的软件组件作为一个不断增长的整体保持在一起,那么 CD 的核心则是将这个整体交到关心它的人手中。下图展示了 CD 的概念:

向最终用户持续交付价值是敏捷开发的核心原则。无论你使用哪种敏捷方法,将功能交到用户手中始终是目标。我们希望以规律的、短的时间间隔交付可用的功能。这样做有三个好处:
-
用户获得他们想要的价值
最终用户并不关心我们的开发过程。他们只关心能否解决他们的问题。无论是等待Uber时的娱乐问题,还是在跨国企业中支付员工工资的问题,我们的用户只希望他们的需求得到满足。向用户交付有价值的功能成为我们的竞争优势。
-
我们获得宝贵的用户反馈
是的,这是我要求的——但这不是我的意思!这是敏捷方法提供的极其宝贵的用户反馈。一旦最终用户看到我们实现的功能,有时会发现它并没有完全解决他们的问题。我们可以迅速纠正这一点。
-
使代码库和开发团队保持一致
要实现这一目标,你需要让团队和工作流程保持一致。除非你的工作流程能够持续提供已知可用的软件作为一个整体,否则你无法有效地做到这一点。
持续交付还是持续部署?
这些术语的确切定义似乎有所不同,但我们可以这样理解:
-
持续交付(Continuous Delivery)
我们将软件交付给内部利益相关者,例如产品负责人和 QA 工程师。
-
持续部署(Continuous Deployment)
我们将软件部署到生产环境并交付给最终用户。
在这两者中,持续部署设定了更高的标准。它要求一旦我们将代码集成到流水线中,代码就准备好上线——进入生产环境,面向真实用户。这当然很难。它需要一流的测试自动化,以确保我们对代码的部署充满信心。它还受益于在生产环境中拥有快速回滚系统——如果我们发现测试未覆盖的缺陷,可以快速回滚部署。持续部署是终极的工作流程。对于所有实现它的人来说,周五最后时刻部署新代码根本不会让人感到恐惧。嗯,也许恐惧会少一些。
实践中的 CI/CD 流水线
大多数项目使用 CI 工具来处理这些顺序任务。流行的工具包括 Jenkins、GitLab、CircleCI、Travis CI 和 Azure DevOps。它们的工作方式类似,按顺序执行不同的构建阶段。这就是 “流水线” 名称的由来——它类似于一个管道,一端加载下一个构建阶段,然后从另一端输出,如下图所示:

CI 流水线包括以下步骤:
-
源代码控制:拥有一个存储代码的公共位置对于 CI/CD 至关重要。这是代码集成的地方。流水线从这里开始,拉取最新版本的源代码并执行干净的构建。这可以防止由于计算机上存在旧版本代码而导致的错误。
-
构建:在这一步骤中,我们运行构建脚本来下载所有所需的库,编译所有代码并将其链接在一起。输出通常是可执行的文件,例如一个 Java 归档文件(
.jar文件),以便在 JVM 上运行。 -
静态代码分析:
Linter和其他分析工具检查源代码中的风格违规,例如变量长度和命名约定。开发团队可以选择在静态分析检测到特定代码问题时使构建失败。 -
单元测试:所有单元测试都针对构建的代码运行。如果有任何测试失败,流水线将停止。测试失败的消息会被报告。
-
集成测试:所有集成测试都针对构建的代码运行。如果有任何测试失败,流水线将停止并报告错误消息。
-
验收测试:所有验收测试都针对构建的代码运行。如果所有测试都通过,代码被认为是可工作的,并准备好交付/部署。
-
交付打包:代码被打包成适合交付的形式。对于 Java Web 服务,这可能是一个包含嵌入式 Web 服务器的 Java 归档文件(
.jar文件)。
接下来发生的事情取决于项目的需求。打包的代码可能会自动部署到生产环境,或者可能只是放置在某个内部存储库中,供产品负责人和 QA 工程师访问。正式的部署将在质量把关之后进行。
测试环境
需要一个 CI 流水线来运行集成测试所导致的一个明显问题是,需要有一个地方来运行这些测试。通常,在生产环境中,我们的应用程序会与外部系统(如数据库和支付提供商)集成。当我们运行 CI 流水线时,我们不希望代码处理支付或写入生产数据库。然而,我们确实希望测试代码是否能够与这些系统集成,一旦我们将其配置为连接到这些真实系统。
解决方案是创建一个测试环境。这些环境是由我们控制的数据库和模拟外部系统的集合。如果我们的代码需要与用户详细信息数据库集成,我们可以创建该用户数据库的副本并在本地运行。在测试期间,我们可以安排代码连接到这个本地数据库,而不是生产版本。外部支付提供商通常提供一个沙盒 API。这是他们服务的一个版本,同样不会连接到任何真实客户。它具有模拟的服务行为。实际上,它是一个外部测试替身。
这种设置被称为类生产环境或预发布环境。它允许我们的代码在更真实的集成条件下进行测试。我们的单元测试使用存根和模拟对象。现在,我们的集成测试可以使用这些更丰富的测试环境。
使用测试环境的优势和挑战
测试环境既有优势也有挑战,如下表所总结:
| 优点 | 挑战 |
|---|---|
环境是自包含的 我们可以随意创建和销毁它。它不会影响生产系统。 |
不是生产环境 无论我们如何让它像真实环境,测试环境始终是模拟的。风险在于,我们的虚假环境可能给出假阳性——仅因为使用了虚假的数据而通过的测试。这可能给我们带来虚假的信心,导致我们部署的代码在生产环境中失败。 真正的测试发生在我们将代码投入实际运行时。始终如此。 |
比存根更现实 这个环境让我们更接近于在生产负载和条件下进行测试。 |
需要额外的努力来创建和维护 需要更多的开发工作来设置这些环境,并确保它们与测试代码保持同步。 |
检查关于外部系统的假设 第三方沙箱环境允许我们确认代码是否使用了供应商发布的最新、正确的 API。 |
隐私问题 仅仅复制一部分生产数据并不足以构建一个测试环境。如果这些数据包含了根据 GDPR 或 HIPAA 定义的个人身份信息(PII),我们就不能直接使用它。 我们必须采取额外步骤来匿名化这些数据或生成伪真实的随机测试数据。 这两者都不是简单的任务。 |
生产环境中的测试
我已经能听到大家的惊呼了!在生产环境中运行测试通常是一个糟糕的想法。我们的测试可能会引入虚假订单,而生产系统会将其视为真实订单。我们可能不得不添加测试用户账户,这可能会带来安全风险。更糟糕的是,由于我们处于测试阶段,代码很可能还没有正常工作。这可能会导致各种问题——而所有这些问题都是在连接到生产系统时发生的。
尽管存在这些担忧,但有时必须在生产环境中进行测试。像谷歌和 Meta 这样的大数据公司,由于数据规模庞大,有些东西只能在生产环境中进行测试。无法创建一个有意义的类生产测试环境;它只会太小。在这种情况下我们能做些什么呢?
方法是降低风险。这里有两种技术非常有价值:蓝绿部署和流量分区。
蓝绿部署
蓝绿部署 是一种旨在快速回滚失败部署的部署技术。它通过将生产服务器分为两组来工作。它们被称为蓝色和绿色,选择这两种颜色是因为它们是中性的颜色,都表示成功。我们的生产代码在任何时候都只在一组服务器上运行。假设我们当前在蓝色组上运行。我们的下一次部署将部署到绿色组。如下图所示:
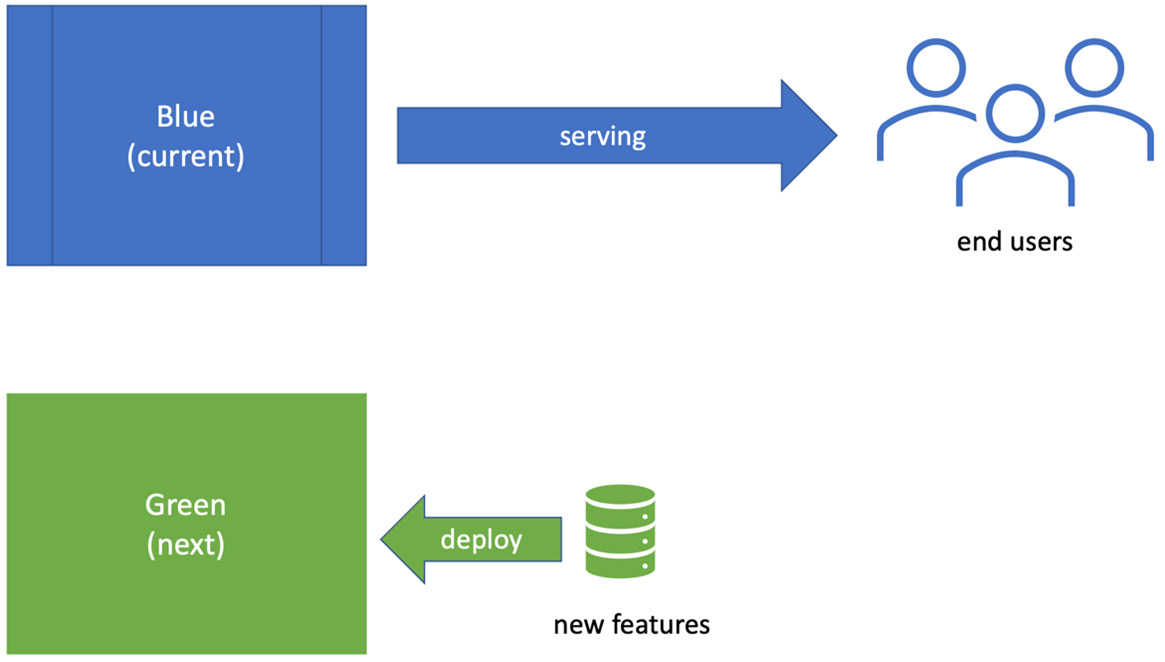
一旦代码部署到绿色组,我们将生产配置切换到连接绿色组服务器。我们保留之前在蓝色服务器上工作的生产代码。如果我们在绿色组上的测试顺利,那么我们就完成了。生产现在使用的是最新的绿色组代码。如果测试失败,我们将配置恢复到再次连接蓝色服务器。这是一个快速回滚系统,使我们能够进行实验。
流量分区
除了蓝绿部署,我们还可以限制发送到测试服务器的流量。与其将生产完全切换到使用正在测试的新代码,我们可以简单地发送一小部分用户流量到那里。因此,99% 的用户可能会被路由到我们已知可用的蓝色服务器,而 1% 的用户可以被路由到绿色服务器上的新代码进行测试,如下图所示:
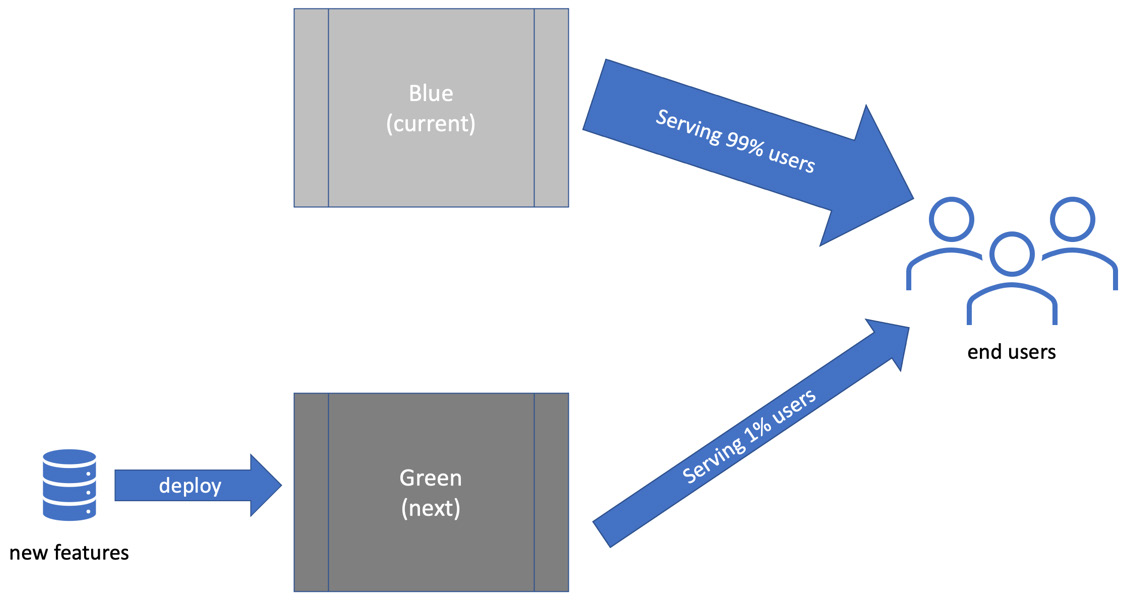
如果发现缺陷,只有 1% 的用户会受到影响,然后我们会恢复到 100% 的蓝色服务器。这为我们提供了一个快速回滚机制,减轻了因部署失败而导致的生产问题。
我们现在已经介绍了不同类型测试的作用,并了解了它们如何融入一个称为测试金字塔的连贯系统。在下一部分中,我们将通过编写集成测试将这些知识应用到我们的 Wordz 应用程序中。