集成测试
在本节中,我们将探讨测试金字塔的下一层:集成测试。我们将了解它的重要性,回顾有用的工具,并理解集成测试在整个测试体系中的作用。
集成测试 的存在是为了测试我们的代码是否能够成功与外部系统集成。我们的核心应用程序逻辑由单元测试进行测试,而单元测试在设计上不与外部系统交互。这意味着我们需要在某个时刻测试与这些外部系统的交互行为。
集成测试是测试金字塔的第二层。它们有其优势和局限性,如下表总结:
| 优点 | 限制 |
|---|---|
测试软件组件在连接时是否正确交互 |
需要设置和维护测试环境 |
提供更接近软件系统实际使用的仿真 |
测试运行速度比单元测试慢 |
容易受到测试环境问题的影响,例如数据不正确或网络连接失败 |
集成测试的数量应少于单元测试。理想情况下,数量要少得多。虽然单元测试通过使用测试替身(test doubles)避免了测试外部系统的许多问题,但集成测试现在必须面对这些挑战。从本质上讲,它们更难以设置。它们的测试结果可能不太可重复。它们通常比单元测试运行得更慢,因为它们需要等待外部系统的响应。
为了说明这一点,一个典型的系统可能有数千个单元测试和数百个验收测试。在这之间,我们有少量的集成测试。许多集成测试指向一个设计机会。我们可以重构代码,使集成测试被推向下层成为单元测试,或者提升为验收测试。
减少集成测试的另一个原因是 不稳定的测试(flaky tests)。不稳定的测试是指有时通过有时失败的测试。当它失败时,通常是由于与外部系统交互的某些问题,而不是我们测试的代码中的缺陷。这种失败被称为 假阴性测试结果——一种可能误导我们的结果。
不稳定的测试之所以令人烦恼,正是因为我们无法立即确定失败的根本原因。如果不深入研究错误日志,我们只知道测试失败了。这导致开发人员学会忽略这些失败的测试,通常选择重新运行测试套件多次,直到不稳定的测试通过。
这里的问题是,我们正在训练开发人员对他们的测试失去信心。我们正在训练他们忽略测试失败。这不是一个好的状态。
集成测试应该覆盖什么?
在我们目前的设计中,我们已经使用 依赖倒置原则(Dependency Inversion Principle)将外部系统与领域代码解耦。我们创建了一个接口,定义了我们如何使用该外部系统。这个接口的某些实现将由我们的集成测试覆盖。在六边形架构术语中,这被称为 适配器(adapter)。
这个适配器应该只包含与外部系统交互所需的最少量的代码,以满足我们的接口要求。它不应该包含任何应用程序逻辑。这些逻辑应该位于领域层中,并由单元测试覆盖。我们称之为 薄适配器(thin adapter),它只做足够的工作来适应外部系统。这意味着我们的集成测试的范围被很好地限制住了。
我们可以用以下方式表示集成测试的范围:
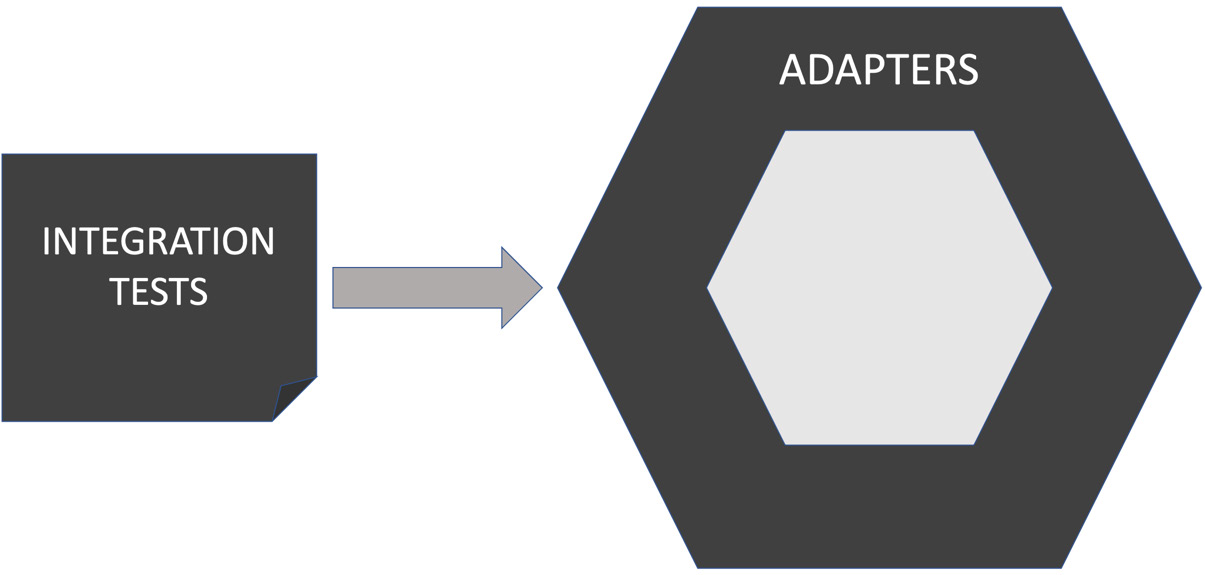
集成测试仅测试适配器层组件,即那些直接与外部系统(如数据库和 Web 端点)交互的代码片段。集成测试将创建被测适配器的实例,并安排其连接到外部服务的测试版本。这一点很重要。我们仍然不会连接到生产服务。在集成测试通过之前,我们不确定适配器代码是否正确工作。因此,我们还不想访问真实的服务。我们还希望对这些服务有额外的控制。我们希望能够安全、轻松地创建测试账户和假数据以用于我们的适配器。这意味着我们需要一组类似真实的服务和数据库来使用。这意味着它们必须在某个地方运行。
测试环境(test environments)是我们用于集成测试的外部系统配置的名称。它是一个专门用于测试的 Web 服务和数据源运行环境。
测试环境使我们的代码能够连接到真实外部系统的测试版本。与单元测试级别相比,它更接近生产准备状态。然而,使用测试环境涉及一些挑战。让我们探讨一下测试与数据库和Web服务集成的最佳实践。
测试数据库适配器
测试数据库适配器的基本方法是在测试环境中设置一个数据库服务器,并让被测代码连接到它。集成测试将在其 Arrange 步骤中将已知数据集预加载到数据库中。然后,测试在 Act 步骤中运行与数据库交互的代码。Assert 步骤可以检查数据库,看看是否发生了预期的数据库更改。
测试数据库的最大挑战是它会记住数据。这似乎有点显而易见,因为使用数据库的初衷就是存储数据。但这与测试的一个目标相冲突:隔离的、可重复的测试。例如,如果我们的测试为用户 testuser1 创建了一个新用户账户,并将其存储在数据库中,那么再次运行该测试时就会有问题。它将无法创建 testuser1,而是会收到 “用户已存在” 的错误。
有几种方法可以克服这个问题,每种方法都有其优缺点:
-
在每个测试用例之前和之后删除数据库中的所有数据
这种方法保持了测试的隔离性,但速度较慢。我们必须在每次测试之前重新创建测试数据库模式。
-
在完整的一组适配器测试运行之前和之后删除所有数据
我们减少删除数据的频率,允许多个相关测试在同一个数据库上运行。由于存储的数据,这会导致测试隔离性的丧失,因为数据库在下一个测试开始时不会处于预期状态。我们必须以特定的顺序运行测试,并且它们都必须通过,以避免破坏下一个测试的数据库状态。这不是一个好方法。
-
使用随机化数据
在我们的测试中,我们不再创建
testuser1,而是随机化用户名。因此,在一次运行中,我们可能会得到testuser-cfee-0a9b-931f。在下一次运行中,随机选择的用户名将是其他内容。存储在数据库中的状态不会与同一测试的另一次运行冲突。这是另一种保持测试隔离性的方法。然而,这意味着测试可能更难阅读。它需要定期清理测试数据库。 -
回滚事务
我们可以在数据库事务中添加测试所需的数据。我们可以在测试结束时回滚事务。
-
忽略问题
有时,如果我们使用只读数据库,我们可以添加永远不会被生产代码访问的测试数据,并将其留在那里。如果这有效,这是一个有吸引力的选项,不需要额外的努力。
诸如 database-rider(可从 https://database-rider.github.io/getting-started/ 获取)等工具通过提供库代码来连接到数据库并用测试数据初始化它们来提供帮助。
测试 Web 服务
测试与 Web 服务的集成也采用了类似的方法。在测试环境中运行 Web 服务的测试版本。适配器代码被设置为连接到该 Web 服务的测试版本,而不是真实版本。然后,我们的集成测试可以检查适配器代码的行为。测试服务上可能还有额外的 Web API,以允许测试中的断言进行检查。
同样,缺点是测试运行速度较慢,并且由于网络拥塞等小问题可能导致不稳定的测试。
消费者驱动的契约测试
测试与Web服务交互的一种有用方法称为 消费者驱动的契约测试(Consumer-Driven Contract Testing)。我们将我们的代码视为与外部服务签订了合同。我们同意调用外部服务上的某些 API 函数,并提供所需格式的数据。我们需要外部服务以可预测的方式响应我们,返回已知格式的数据和易于理解的状态码。这形成了双方之间的合同——我们的代码和外部服务 API。
消费者驱动的契约测试基于该合同涉及两个组件,通常使用工具生成的代码。如下图所示:
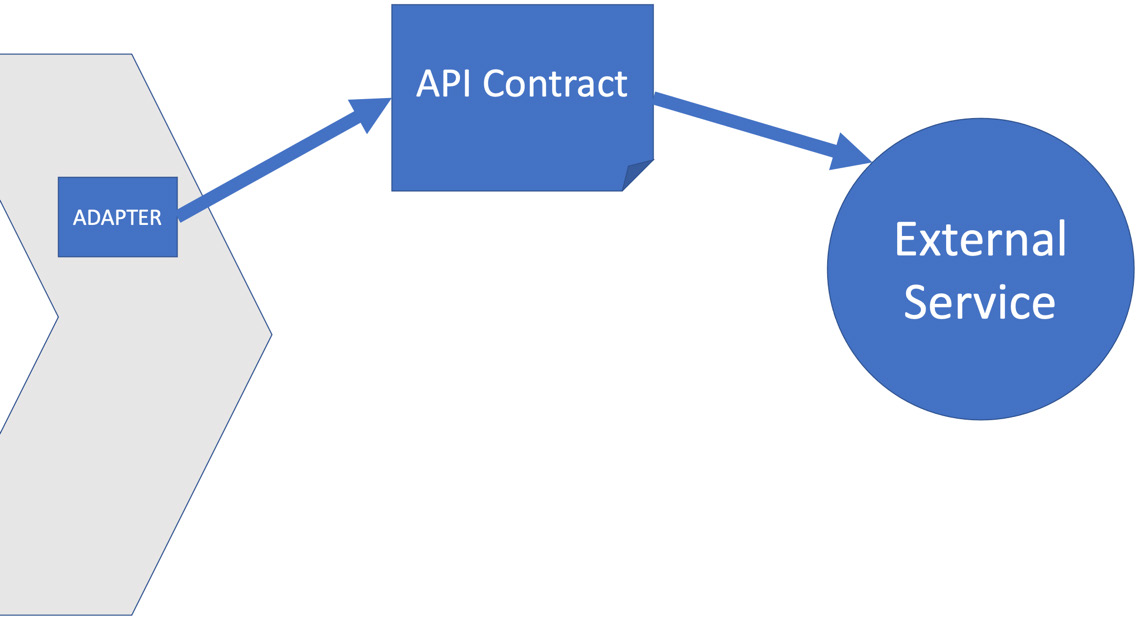
上图显示,我们已经将与外部服务的预期交互捕获为 API 合同。我们为该服务编写的适配器将实现该 API 合同。当使用消费者驱动的契约测试时,我们最终会得到两个测试,分别测试合同的双方。如果我们将服务视为一个黑盒,我们有一个由黑盒呈现的公共接口,以及一个实现,其细节隐藏在该黑盒内。契约测试是两个测试。一个测试确认外部接口与我们的代码兼容。另一个测试确认该接口的实现有效并给出预期结果。
典型的契约测试需要两段代码:
-
外部服务的存根:生成外部服务的存根。如果我们调用支付处理器,此存根在本地模拟支付处理器。这允许我们在编写适配器代码时将其用作支付处理器服务的测试替身。我们可以针对我们的适配器编写集成测试,配置它调用此存根。这使我们能够在不访问外部系统的情况下测试适配器代码逻辑。我们可以验证适配器是否向外部服务发送了正确的 API 调用,并正确处理了预期的响应。
-
对真实外部服务的一组调用的重放:合同还允许我们针对真实的外部服务运行测试——可能在沙盒模式下运行。我们在这里不是测试外部服务的功能——我们假设服务提供商已经完成了这一工作。相反,我们正在验证我们对 API 的理解是否正确。我们的适配器已编码为按特定顺序进行某些 API 调用。此测试验证了这一假设是否正确。如果测试通过,我们知道我们对外部服务 API 的理解是正确的,并且它没有改变。如果此测试以前工作但现在失败,那将是外部服务更改其 API 的早期迹象。然后,我们需要更新适配器代码以遵循新的 API。
一个推荐的工具是 Pact,可在 https://docs.pact.io 获取。阅读那里的指南以了解有关这一有趣技术的更多细节。
我们已经看到,集成测试使我们更接近生产环境。在下一节中,我们将探讨测试金字塔中的最终测试级别,这是迄今为止最接近真实环境的:用户验收测试。