RTP
从以上分析知道,实时通信产品首选的传输协议是 UDP。但 UDP 也有其缺陷,尤其是用它传输一些有前后逻辑关系的数据时,就显得捉襟见肘了,而音视频数据正是这种数据。为了解决这个问题,在传输音视频数据时,通常在 UDP 之上增加一个新协议,即 RTP。其在协议栈中的位置如图 9.3 所示。
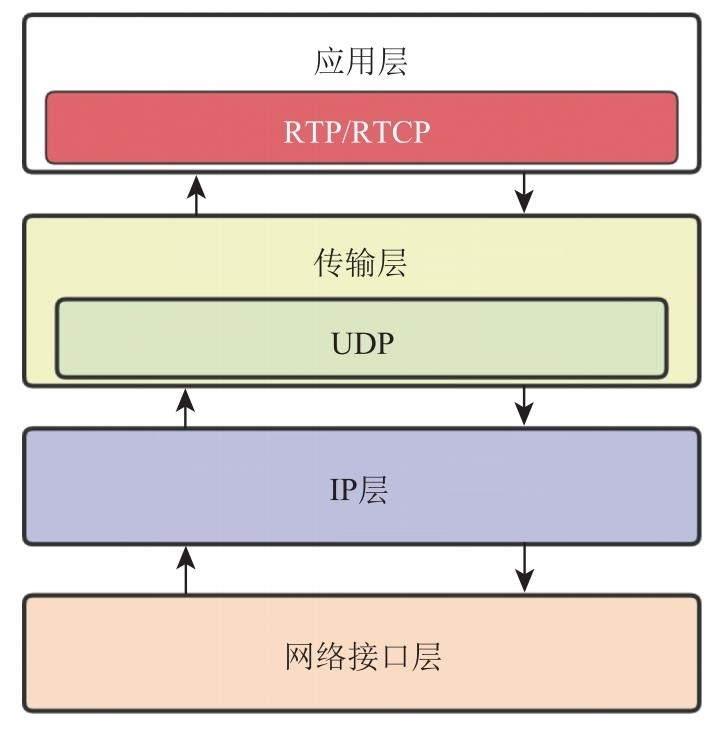
从图中可以看到,RTP 属于应用层传输协议的一种,它与 HTTP/HTTPS 处于同一级别。下面看一下 RTP 是如何传输有前后关系的音视频数据的。
RTP协议头
要想了解 RTP 是如何传输音视频数据的,需要知道 RTP 的结构是什么样子以及它都包括哪些字段。以下通过两个例子了解 RTP 头中包含哪些字段以及每个字段的含义。
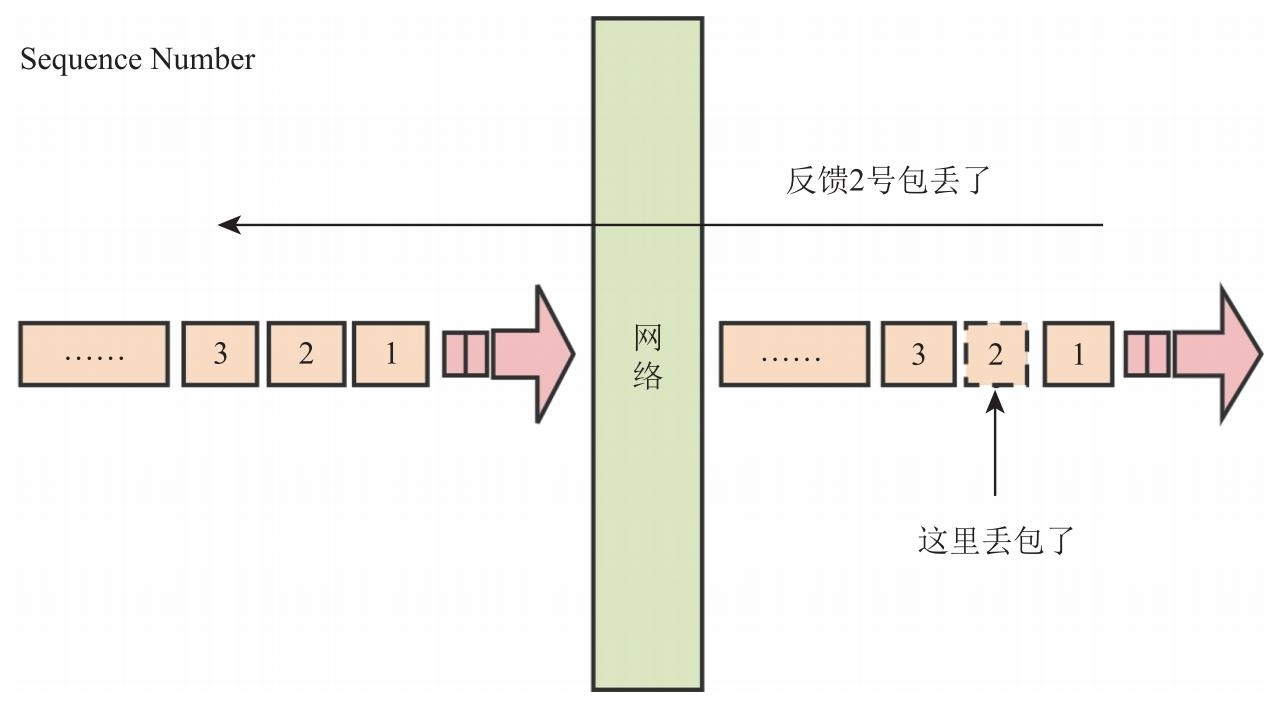
第一个例子,我们希望在使用 RTP 传输音视频数据时,一旦有数据丢失,可以快速定位是哪个数据包丢失了。对于这个问题,RTP 采用如图 9.4 所示的方案予以解决。
从图 9.4 中可以看到,如果给每个发送的数据包都打上一个编号,并且编号是连续的,那么,接收端就可以很容易地判断出哪些包丢失了。在 RTP 头中,有一个专门记录该编号的字段,称作 Sequence Number。在发送端,每产生一个 RTP 包,其 Sequence Number 字段中的值就被自动加 1,以保证每个包的编号唯一且连续。当接收端收到 RTP 包时,会对 SequenceNumber 字段进行检查,如果发现 Sequence Number 不连续了,就说明有包丢失或乱序了。
第二个例子,我们在做网络应用开发时,通常会使用同一个端口传输不同类型的数据,如音视频数据。但接收端是如何区分出不同类型的数据的?RTP 很好地解决了这个问题。为了让接收端可以区分出从同一端口获取的不同类型的数据,RTP 在其协议头中设置了 PT(PayloadType)字段,通过该字段就可以将不同类型的数据区分出来。比如 VP8 的 PT 一般为 96,而 Opus 的 PT 一般为 111。其过程如图 9.5 所示。
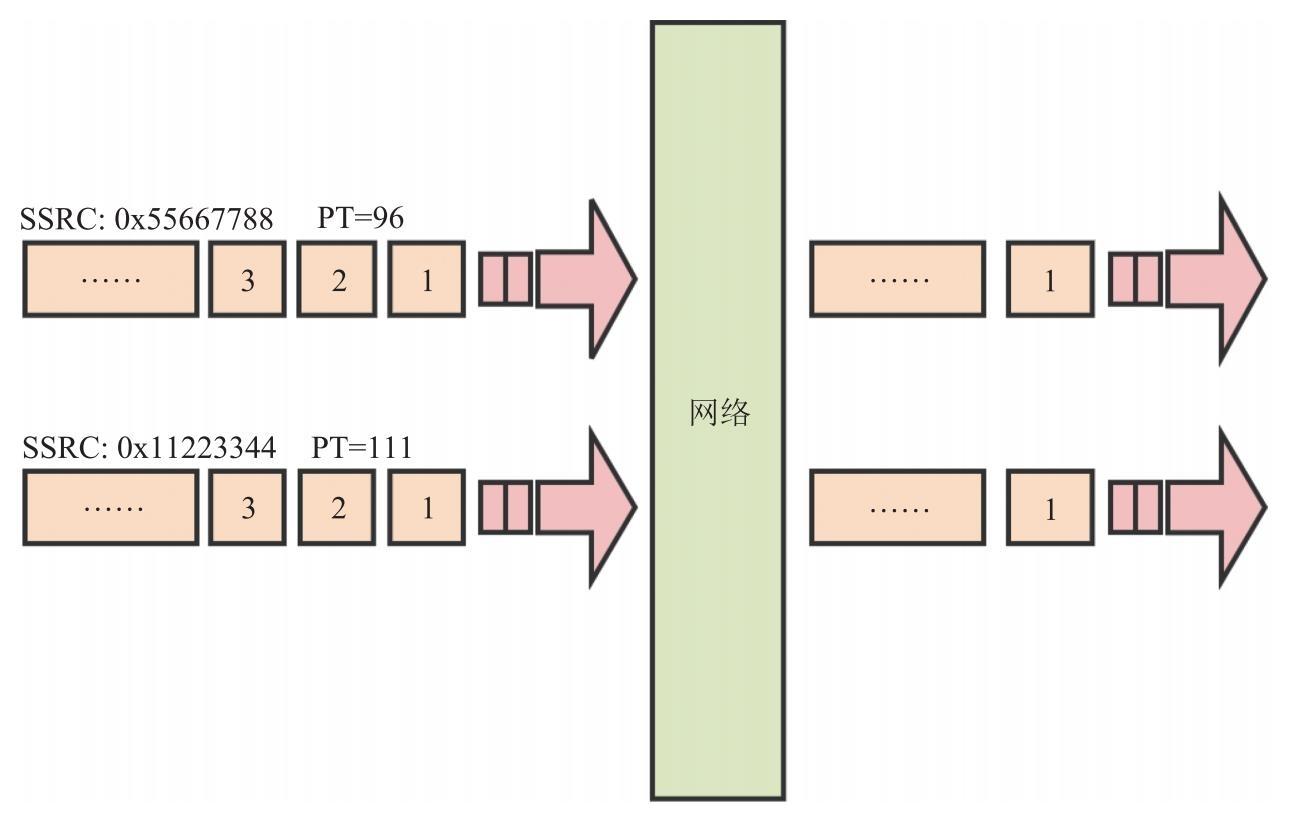
同理,同一个端口不仅可以同时传输不同类型的数据包,还可以传输同一类型但不同源的数据包。比如流媒体服务就可以将多个不同源(参与人)的视频通过同一个端口发送给客户端。那么客户端(接收端)又是如何将不同源的数据区分出来的呢?这就要说到 RTP 中另一个字段 SSRC 了。
RTP 要求所有不同的源的数据流之间可以通过 SSRC 字段进行区分,且每个源的 SSRC 必须唯一。前面介绍的 SequenceNumber 也是与 SSRC 关联在一起的。也就是说,每个 SSRC 所代表的数据流的 Sequence Number 都是单独计数的,正如图 9.5 中展示的两路流(不同 SSRC)分别计数一样。
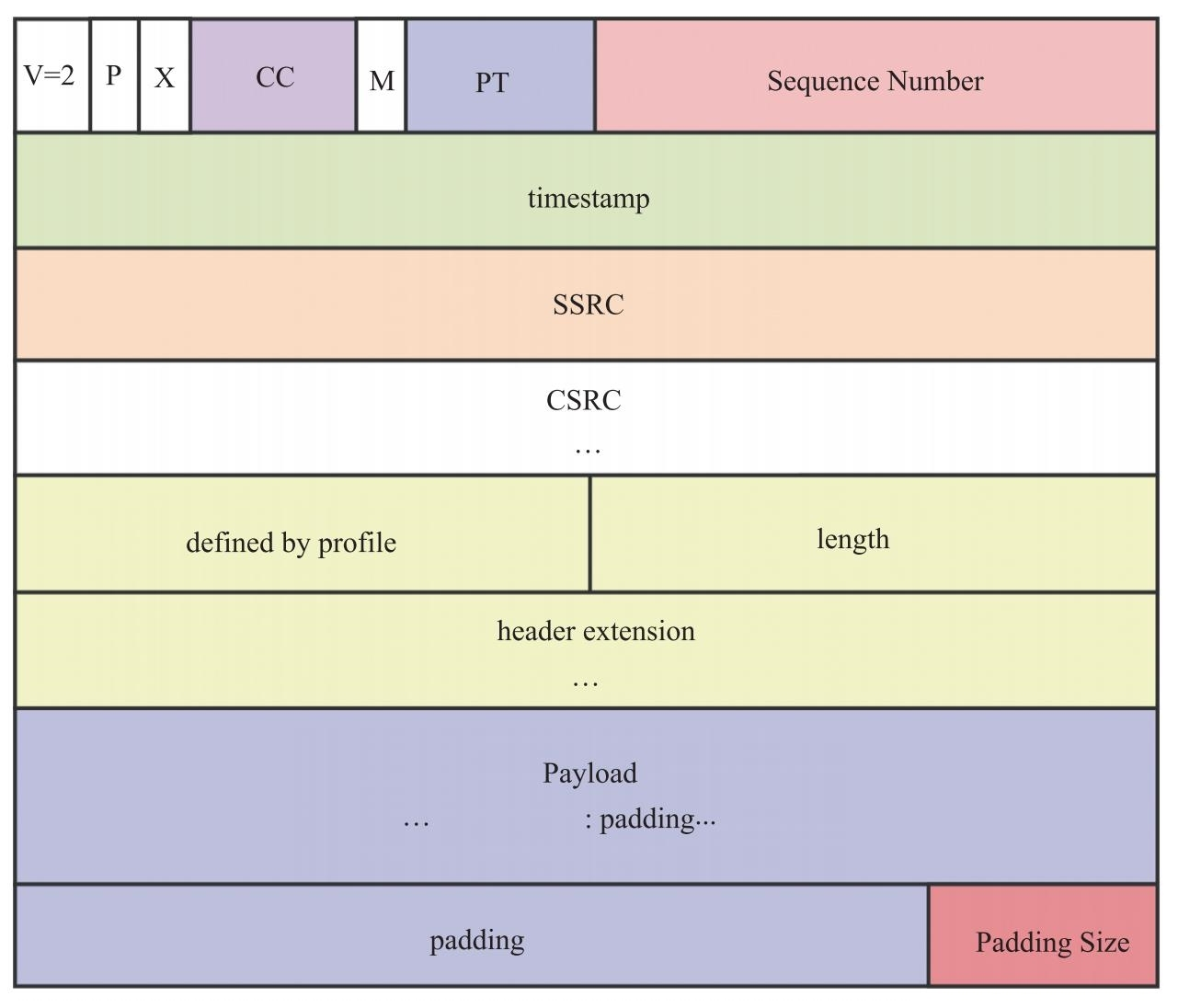
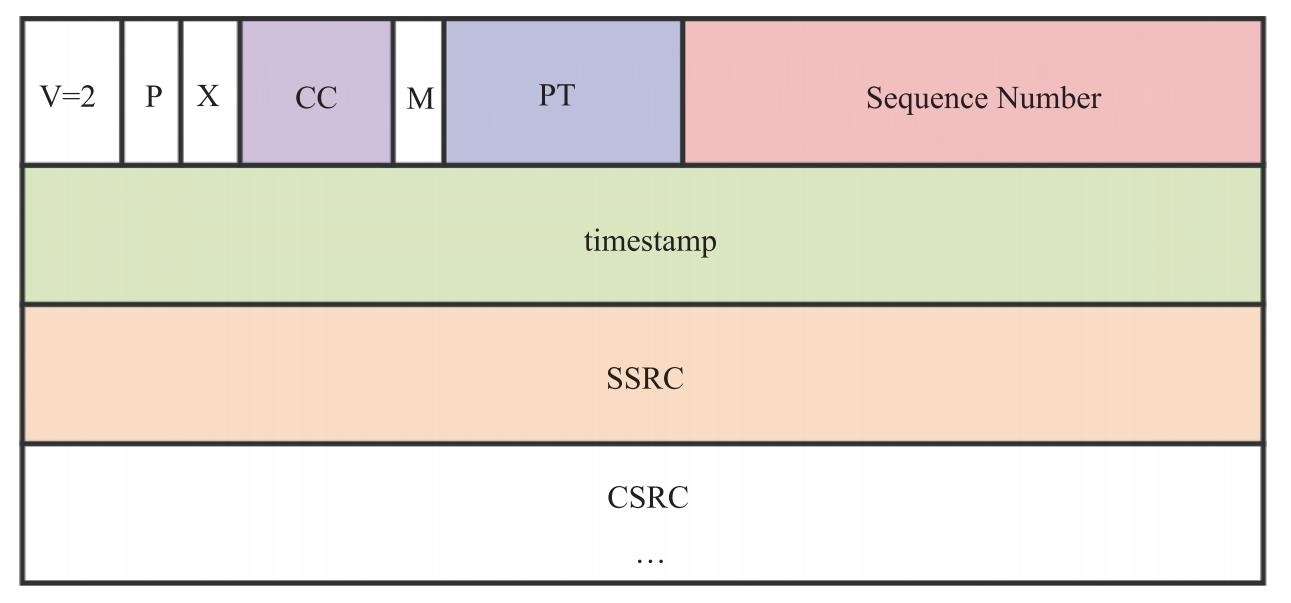
了解了上面这些内容后,再看RTP格式时,就不会觉得它里边的字段难以理解了。其格式如图 9.6 所示。
前面已经将 RTP 中最为重要的三个字段做了介绍,下面再来看看其他几个字段的含义。V(Version)字段,占2位,表示RTP的版本号,现在使用的都是第2个版本,所以该域固定为2。P(Padding)字段,占1位,表示RTP包是否有填充值。为1时表示有填充,填充以字节为单位。一般数据加密时需要固定大小的数据块,此时需要将该位置1。X(eXtension)字段,占1位,表示是否有扩展头。如果有扩展头,扩展头会放在CSRC之后。扩展头主要用于携带一些附加信息。CC(CSRC Count)字段,占4位,记录了CSRS标识符的个数。每个CSRC占4字节,如果CC=2,则表示有两个CSRC,共占8字节。M(Marker)字段,其含义是由配置文件决定的,一般情况下用于标识边界。比如一帧H264被分成多个包发送,那么最后一个包的M位就会被置位,表示这一帧数据结束了。timestamp字段,占4字节,用于记录该包产生的时间,主要用于组包和音视频同步。CSRC字段,指该RTP包中的数据是由哪些源贡献的。比如混音数据是由三个音频混成的,那么这三个音频源都会被记录在CSRS列表中。
以上就是 RTP 协议头的内容。如果读者想更深入地分析 RTP 协议头,可以通过 Wire Shark 工具从网卡上抓取 RTP 包进行分析,这样可以让你对 RTP 包有更直观的感觉。
RTP的使用
关于 RTP 的使用主要包括以下两个方面:一是创建/解析 RTP 包;二是根据 RTP 包进行逻辑处理。
首先看一下如何创建/解析 RTP 包。从上一节的讲解中你应该知道,RTP 协议头并不是特别复杂,如果你对 C/C++ 非常熟悉的话,完全可以自己实现 RTP 协议头的解析程序。不过还有更简便的办法:在 WebRTC 的源码中,已经实现了一个高效的 RTP 处理类,称作 RtpPacket。该类定义在 WebRTC 源码的 module/rtp_rtcp/source 目录下的 rtp_packet.cc|h 文件中。通过 RtpPacket 类,可以生成或解析 RTP 包。
使用 RtpPacket 时,只需定义一个 RtpPacket 对象,即可完成对 RTP 协议头中各字段的设置或提取。比如想设置/获得 PayloadType 字段,就可以通过代码 9.1 实现。
RtpPacket rtp;
// 设置 PayloadType
rtp.SetPayloadType(111);
// 获得 PayloadType
uint8_t pt = rtp.PayloadType();从上述代码中可以看到,通过 RtpPacket 对象访问 RTP 协议头中的 PayloadType 字段非常方便,同理,也可以像访问 PayloadType 字段一样方便地访问其他字段。
知道了如何创建/分析 RTP 包后,接下来以消除 RTP 包抖动为例,介绍一下 RTP 包的逻辑处理。对于 WebRTC 而言,其在接收 RTP 包时,会为之创建一个接收队列来消除包抖动,其大体过程如图 9.7 所示。
从图中可以看到,一开始,队列中只收到了 100、101、102 和 104 号包。由于 103 号包还没到,所以无法将 100∼104 号包组成一帧数据。103 号包没有到有两种可能的原因:一种原因是 103 号包丢失了;另一种原因是网络抖动导致包乱序了。
如何才能判断出 103 号包属于哪种情况呢?最简单的办法就是判断缓冲队列有没有满。如果缓冲队列满了,就说明包真的丢失了。对于 103 号包来说,由于现在缓冲队列还不满,因此该包处于待定状态。同理,当 107 号包到达时,105 号包和 106 号包也处于待定状态。
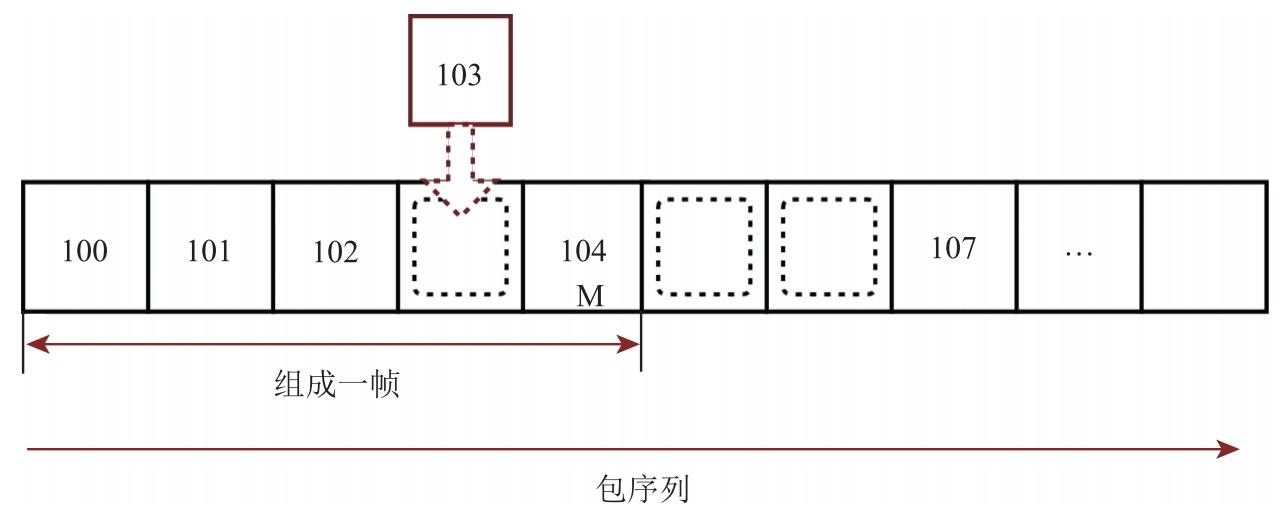
很快 103 号包来了,通过对其 RTP 头中 Sequence Number 字段的计算,它会被插到队列中对应的空缺位置,此时 100∼104 号包连成了一串。又由于 104 号包上有M标记,因此可以将这几个 RTP 包组成一个完整的帧。接下来,100∼104 号包将从缓冲队列中弹出,交由组帧模块处理,空出的位置可以继续接收新包。WebRTC 也是通过类似的方法从网络上将一个个 RTP 包接收下来。
上面就是使用 RTP 消除包抖动的一个简要过程,我们从中学习到了 WebRTC 是如何使用 RTP 的。此外,WebRTC 中解决 RTP 包抖动的缓冲队列就是我们通常所说的 JitterBuffer,通过这个例子读者应该清楚 JitterBuffer 的基本原理是什么。
RTP扩展头
在上节中介绍过,RTP 头中的 X 位用于标识 RTP 包中是否有扩展头。即如果 X 位为 1,则说明 RTP 包中含有扩展头。图 9.8 所示的是含有 RTP 扩展头的 RTP 协议头格式。
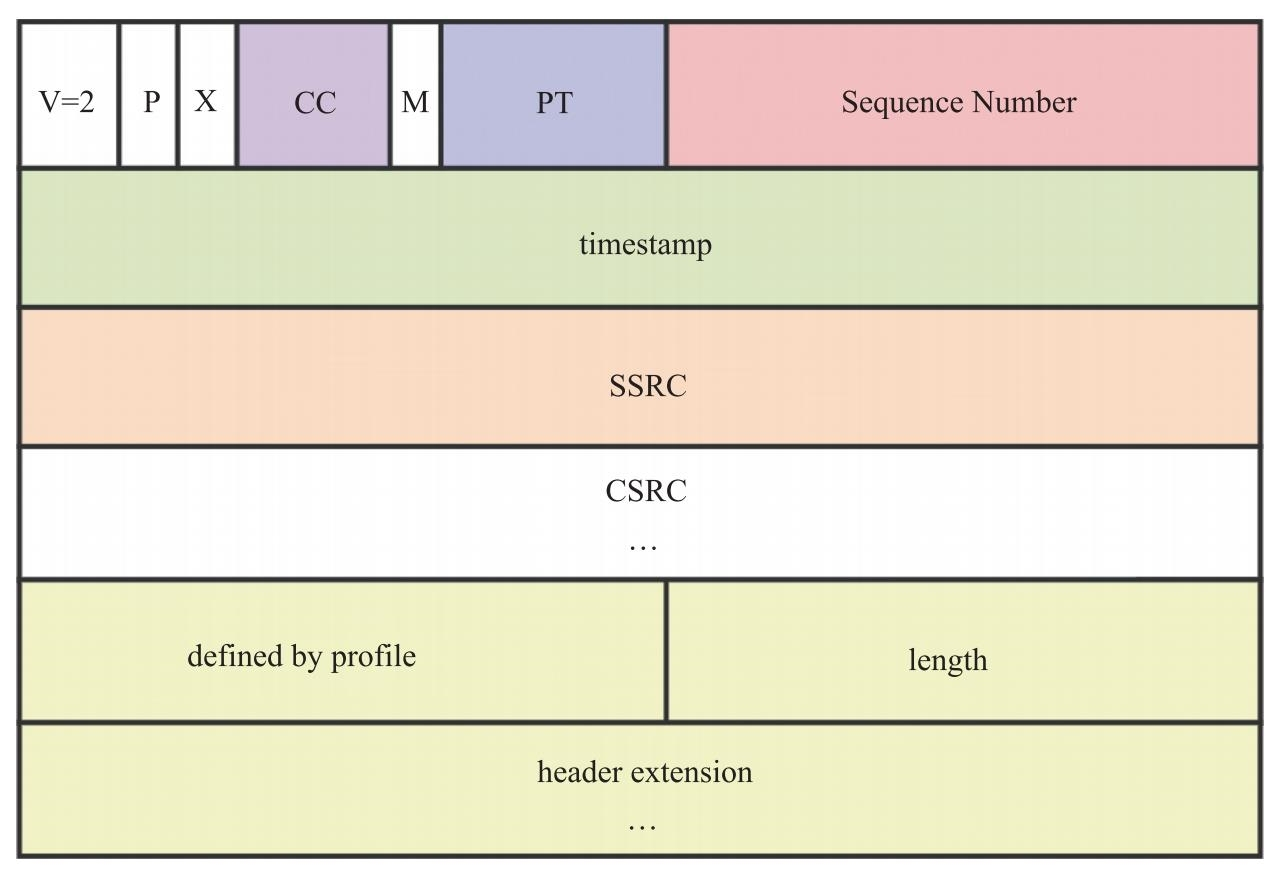
从图中可以看到,RTP 扩展头由三部分组成,分别为 profile、length 以及 header extension。其中,profile 字段用于区分不同的配置。在 RFC5285 中定义了两种 profile,分别是 {0xBE,0xDE} 和 {0x10,0x0X}。接收端解析 RTP 扩展头时,通过 profile 来区分 header extension 中的内容该如何解析。length 字段表示扩展头所携带的 header extension 的个数。如果 length 为 4,表示有 4 个 header extension;header extension 字段是扩展头信息,以 4 字节为单位,其具体含义由 profile 决定。
扩展头中的两个 profile 值 {0xBE,0xDE} 和 {0x10,0x0X} 分别代表存放在 header extension 中的两种不同的数据格式,即 one-byte-header 和 two-byte-header。
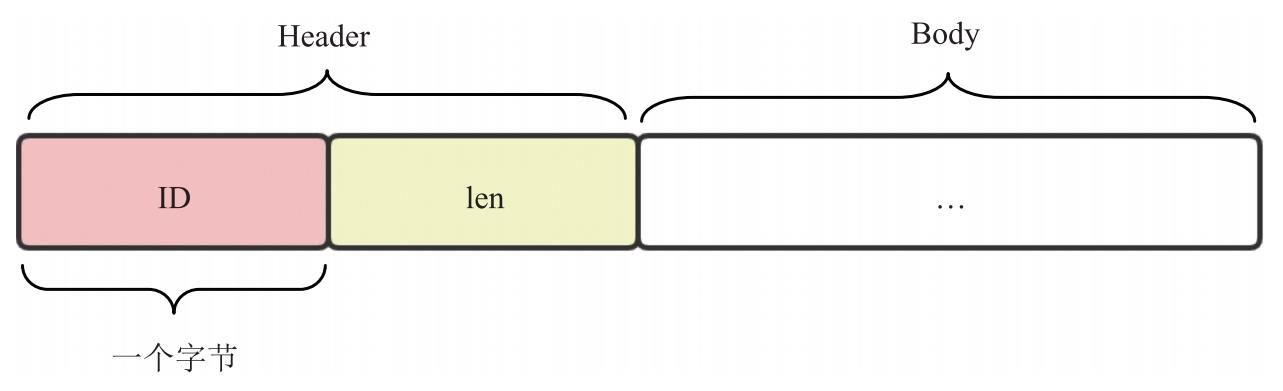
其中,one-byte-header 的含义为存放在扩展头 header extension 字段中的数据,由一个字节的 Header 和 N 字节的 Body 组成,而 Header 又由 4 位的 ID 和 4 位的 len 组成。其格式如图 9.9 所示。
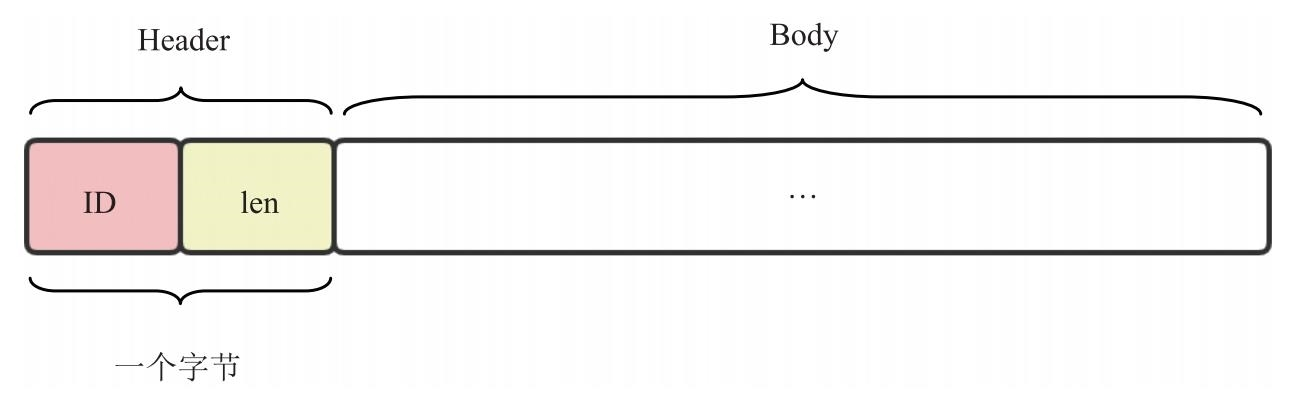
需要说明的是,图 9.9 中的 ID 是由 7.6 节中的表 7.1 指定的,length 的值为跟在 Header 后面的数据(以字节为单位)长度减 1,最后是跟随的数据。
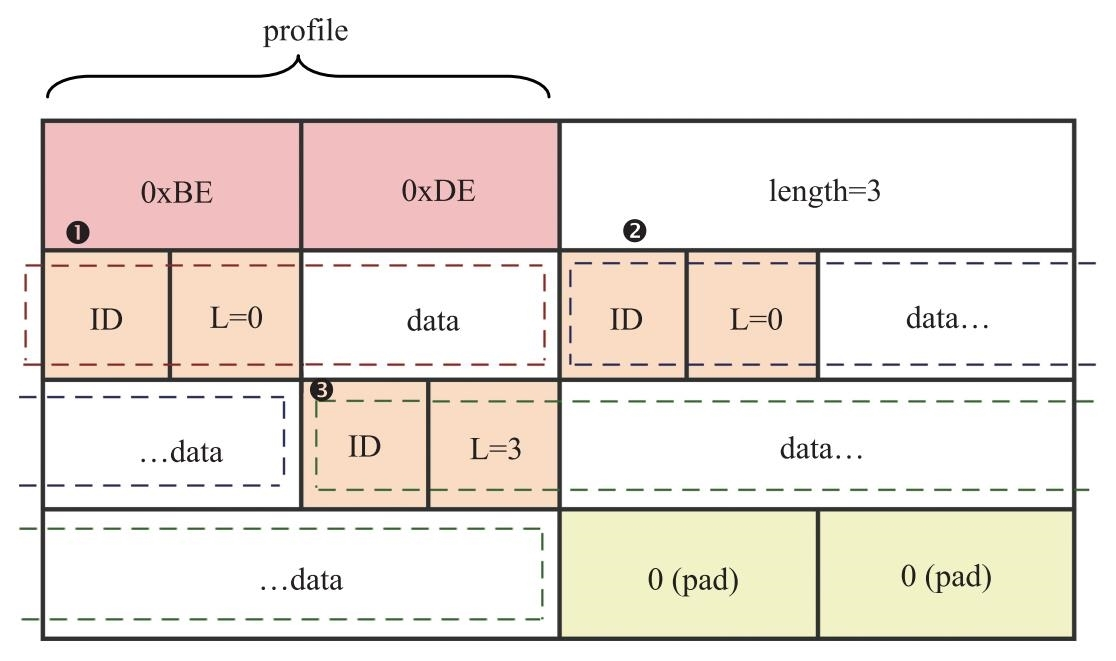
在 RFC5285 中举了一个经典的例子,如图 9.10 所示。在该例中,profile字段的值为{0xBE,0xDE},说明扩展头headerextension字段中携带的数据是one-byte-header格式的。length字段的值为3,说明header extension字段的长度一共占3个4字节,即12字节。在header extension中存放了3个one-byte-header格式的数据,第一个one-byte-header(图9.10中框➊)的length值为0,其数据长度为(0+1)=1字节;第二个one-byte-header(图9.10中框➋)的length值为1,其数据占(1+1)=2字节;第三个one-byte-header(图9.10中框➌)的length值为3,其数据占(3+1)=4字节。此外,由于扩展头要保持4字节对齐,所以最后两个字节是填充字节,设置为0。需要注意的是,在RFC5285文档中,one-byte-header示例填充位的位置有误,关于这一点,读者可以阅读WebRTC中的RtpPacket.c或RtpPacket.h代码。
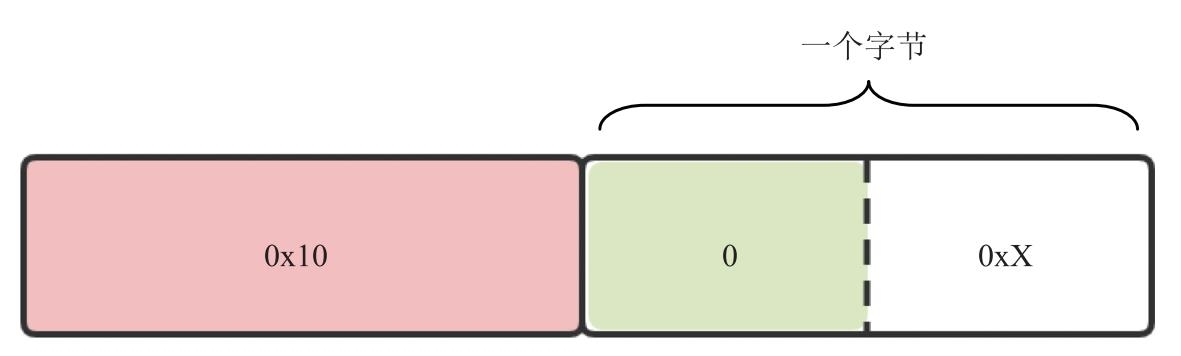
与 one-byte-header 不同的是,two-byte-header 的 Header 部分由两个字节组成,第一个字节表示 ID,第二个字节表示长度。此外,two-byte-header 中 length 字段的含义也与 one-byte-header 中的不同,它存放的是实际长度。two-byte-header 的格式如图 9.11 所示。
从图中可以看到,two-byte-header的格式与one-byte-header的格式类似,只不过one byte-header是将ID和len放在一个字节里,而two-byte-header则是将ID和len放在两个不同的字节里。
当扩展头中的profile为{0x10,0x0X}时,解析RTP扩展头时就会按照two-byte header的格式进行。其中profile中的X占4位,代表任意值,其含义由应用层自己定义。在RFC5285中,two-byte-header的profile格式如图 9.12 所示。
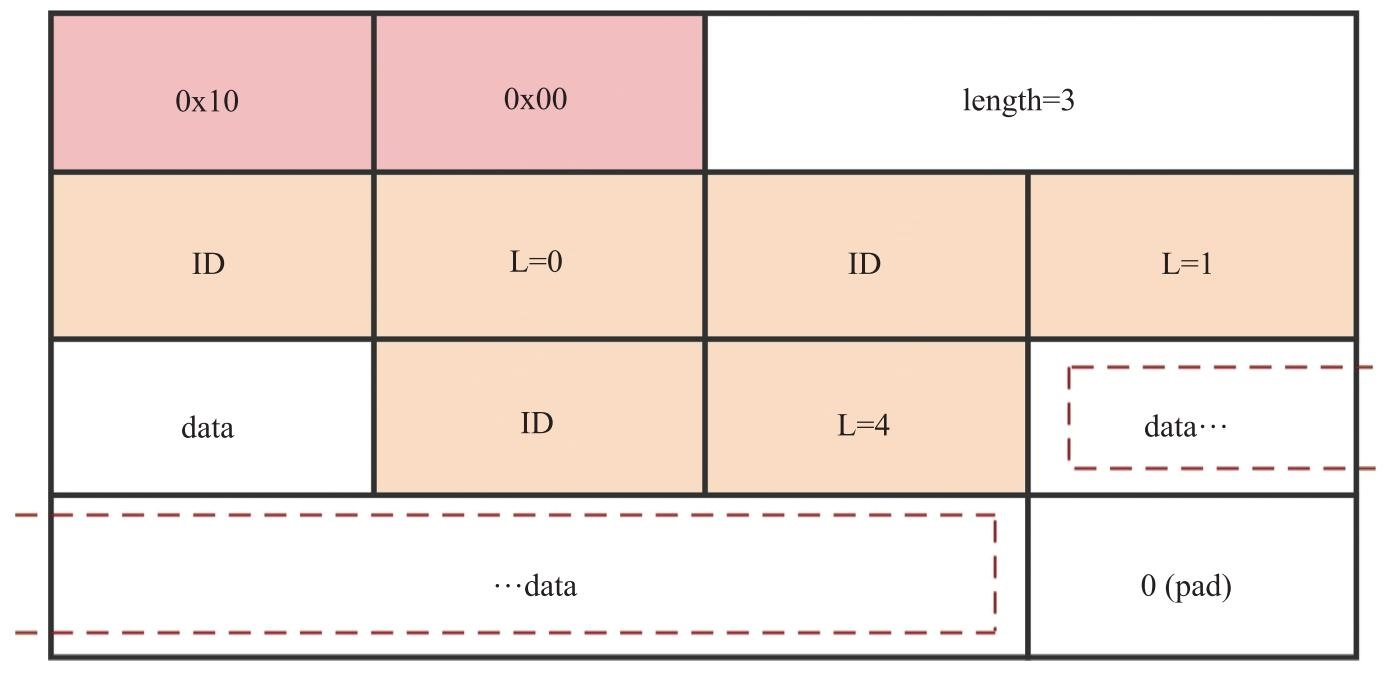
我们来看一个two-byte-header的例子,如图9.13所示。在该例中,profile字段的值为{0x10,0x00},说明扩展头header extension字段中携带的数据是two-byte-header格式的。length字段的值为3,说明header extension字段的长度一共占3个4字节。在header extension中存放了3个two-byte-header格式的数据:第一个two-byte-header的length值为0,没有数据部分;第二个two-byte-header的length值为1,其数据占1字节;第三个two-byte-header的length值为4,其数据占4字节。同one-byte-header一样,由于扩展头要保持4字节对齐,所以最后要补一个填充字节,并将其设置为0。
通过上面的介绍我们知道RTP扩展头有三个要点。一是RTP标准头中的X位,该位置1时,RTP中才会有扩展头。二是扩展头中的profile字段指明了扩展头中数据的格式。如果profile为0xBEDE,则说明使用的扩展头格式为one-byte-header;如果profile为0x100X(X表示任意值),则说明使用的扩展头格式为two-byte-header。三是one-byte-header与two-byte-header的区别。如果ID和len放在一个字节中,说明它是one-byte-header格式;如果ID和len放在两个字节中,说明它是two-byte-header格式。
RTP中的填充数据
与RTP扩展头类似,RTP头中的P位用于标识RTP包中是否有填充数据。如果P位为1,说明RTP包中含有填充数据。图9.14 所示的是含有RTP填充数据的RTP格式,同时它也是一个最完整的RTP包。
当RTP包中包含有填充数据时,其数据包的最后一个字节记录着包中填充字节的个数,即图中的Padding Size部分。如果Padding Size为5,说明RTP包中共有5个填充字节,其中包括它自己。这些填充数据不属于RTP Payload的部分,因此在解析RTP Payload部分之前,应将填充部分去掉。
去掉填充字节的算法也非常简单,首先读取RTP包的最后一个字节,取出填充字节数,然后从最后一个字节算起,将其前面的Padding Size个字节丢掉即可。