CSV 文件格式
在文本文件中存储数据的一种简单方法是将数据写成一系列用逗号分隔的值,称为逗号分隔值。这样得到的文件就是 CSV 文件。例如,下面是一大段 CSV 格式的天气数据:
"USW00025333","SITKA AIRPORT, AK US","2021-01-01",,"44","40"这是 2021 年 1 月 1 日阿拉斯加锡特卡的天气数据节选。其中包括当天的最高气温和最低气温,以及当天的其他一些测量数据。对于人类来说,阅读 CSV 文件可能比较乏味,但程序却可以快速、准确地从中处理和提取信息。
我们将从 Sitka 记录的一小组 CSV 格式的天气数据开始;它可在本书的资源中找到,网址是 https://ehmatthes.github.io/pcc_3e 。在保存本章程序的文件夹中建立一个名为 weather_data 的文件夹。将 sitka_weather_07-2021_simple.csv 文件复制到这个新文件夹中。(下载本书资源后,您将拥有本项目所需的所有文件)。
|
本项目中的气象数据最初是从 https://ncdc.noaa.gov/cdo-web 上下载的。 |
解析 CSV 文件头
Python 标准库中的 csv 模块会解析 CSV 文件中的各行,并允许我们快速提取我们感兴趣的值。让我们从文件的第一行开始,其中包含一系列数据的标题。这些标题告诉我们数据包含哪些信息:
from pathlib import Path
import csv
path = Path('weather_data/sitka_weather_07-2021_simple.csv') (1)
lines = path.read_text().splitlines()
reader = csv.reader(lines) (2)
header_row = next(reader) (3)
print(header_row)我们首先导入 Path 和 csv 模块。然后,我们在 weather_data 文件夹中创建一个 Path 对象,并指向我们要处理的特定天气数据文件❶。我们读取文件,并通过 splitlines() 方法获取文件中所有行的列表,然后将其赋值给行。
接下来,我们创建一个阅读器对象 ❷。这是一个可用于解析文件中每一行的对象。要创建一个阅读器对象,请调用函数 csv.reader(),并将 CSV 文件中的行列表传递给它。
如果给定了一个阅读器对象,函数 next() 会从文件开头返回文件中的下一行。
在这里,我们只调用了一次 next(),因此我们得到了文件的第一行,其中包含文件头❸。我们将返回的数据赋值给 header_row。正如你所看到的,header_row 包含有意义的、与天气相关的标题,告诉我们每行数据包含哪些信息:
['STATION', 'NAME', 'DATE', 'TAVG', 'TMAX', 'TMIN']阅读器对象处理文件中第一行逗号分隔的值,并将每个值作为一个项目存储在一个列表中。标题 STATION 代表记录该数据的气象站代码。该标头的位置告诉我们,每一行中的第一个值将是气象站代码。标头 NAME 表示每行的第二个值是记录数据的气象站名称。其余标头说明了每次读数记录的信息类型。我们现在最感兴趣的数据是日期 (DATE)、最高温度 (TMAX) 和最低温度 (TMIN)。这是一个简单的数据集,只包含与温度相关的数据。当您下载自己的天气数据时,您可以选择包含一些与风速、风向和降水数据相关的其他测量值。
打印标题及其位置
为了便于理解文件头数据,让我们打印每个文件头及其在列表中的位置:
--snip--
reader = csv.reader(lines)
header_row = next(reader)
for index, column_header in enumerate(header_row):
print(index, column_header)enumerate() 函数会返回每个项的索引和每个项在列表中循环的值。(请注意,我们删除了 print(header_row) 这一行,而使用了更详细的版本)。
下面的输出显示了每个标题的索引:
0 STATION
1 NAME
2 DATE
3 TAVG
4 TMAX
5 TMIN我们可以看到,日期及其最高气温存储在第 2 列和第 4 列中。为了探索这些数据,我们将处理 sitka_weather_07-2021_simple.csv 中的每一行数据,并使用索引 2 和索引 4 提取值。
提取和读取数据
既然我们已经知道需要哪几列数据,那就来读取其中的一些数据吧。首先,我们将读入每天的最高气温:
--snip--
reader = csv.reader(lines)
header_row = next(reader)
# Extract high temperatures.
highs = [] (1)
for row in reader: (2)
high = int(row[4]) (3)
highs.append(high)
print(highs)我们创建一个名为 highs ❶ 的空列表,然后循环浏览文件 ❷ 中的剩余行。阅读器对象会从 CSV 文件中停止的位置继续读取,并自动返回当前位置后的每一行。因为我们已经读取了标题行,所以循环将从实际数据开始的第二行开始。每次通过循环时,我们都会从索引 4(对应于标题 TMAX)中提取数据,并将其赋值给变量 high ❸。我们使用 int() 函数将以字符串形式存储的数据转换为数字格式,以便使用。然后,我们将此值追加到 high 中。
下面的列表显示了现在存储在 highs 中的数据:
[61, 60, 66, 60, 65, 59, 58, 58, 57, 60, 60, 60, 57, 58, 60,
61, 63, 63, 70, 64, 59, 63, 61, 58, 59, 64, 62, 70, 70, 73,66]我们提取了每个日期的最高温度,并将每个值存储在一个列表中。现在让我们创建一个可视化数据。
在温度图表中绘制数据
为了直观地显示气温数据,我们首先使用 Matplotlib 绘制一个简单的日最高气温图,如图所示:
from pathlib import Path
import csv
import matplotlib.pyplot as plt
path = Path('weather_data/sitka_weather_07-2021_simple.csv')
lines = path.read_text().splitlines()
--snip--
# Plot the high temperatures.
plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.plot(highs, color='red') (1)
# Format plot.
ax.set_title("Daily High Temperatures, July 2021", fontsize=24) (2)
ax.set_xlabel('', fontsize=16) (3)
ax.set_ylabel("Temperature (F)", fontsize=16)
ax.tick_params(labelsize=16)
plt.show()我们将高点列表传递给 plot(),并传递 color='red' 以用红色❶绘制点(我们将用红色绘制高点,用蓝色绘制低点)。(我们将用红色绘制最高点,用蓝色绘制最低点。)然后我们指定一些其他格式细节,如标题、字体大小和标签❷,就像我们在第 15 章中所做的那样。因为我们还没有添加日期,所以不会在 x 轴上添加标签,但 ax.set_xlabel() 会修改字体大小,使默认标签更易读❸。图 16-1 显示了绘制的结果:阿拉斯加锡特卡 2021 年 7 月最高气温的简单折线图。
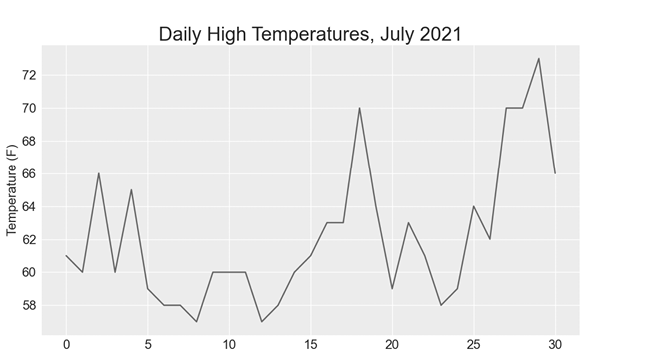
日期时间模块
让我们在图表中添加日期,使其更加有用。天气数据文件中的第一个日期位于文件的第二行:
"USW00025333","SITKA AIRPORT, AK US","2021-07-01",,"61","53"数据将以字符串形式读入,因此我们需要一种方法将字符串 "2021-07-01 "转换为表示该日期的对象。我们可以使用 datetime 模块中的 strptime() 方法构建一个表示 2021 年 7 月 1 日的对象。让我们看看 strptime() 如何在终端会话中工作:
>>> from datetime import datetime
>>> first_date = datetime.strptime('2021-07-01', '%Y-%m-%d')
>>> print(first_date)
2021-07-01 00:00:00首先,我们从 datetime 模块中导入 datetime 类。然后,我们调用 strptime() 方法,其第一个参数是包含我们要处理的日期的字符串。第二个参数告诉 Python 日期的格式。在这个例子中,"%Y-" 告诉 Python 在第一个破折号之前查找四位数的年;"%m-" 表示在第二个破折号之前查找两位数的月;"%d" 表示字符串的最后部分是月的一天,从 1 到 31。
strptime() 方法可以使用多种参数来决定如何解释日期。表 16-1 列出了其中一些参数。
| 参数 | 描述 |
|---|---|
%A |
Weekday name, such as Monday |
%B |
Month name, such as January |
%m |
Month, as a number (01 to 12) |
%d |
Day of the month, as a number (01 to 31) |
%Y |
Four-digit year, such as 2019 |
%y |
Two-digit year, such as 19 |
%H |
Hour, in 24-hour format (00 to 23) |
%I |
Hour, in 12-hour format (01 to 12) |
%p |
AM or PM |
%M |
Minutes (00 to 59) |
%S |
Seconds (00 to 61) |
绘制日期
我们可以通过提取每日最高气温读数的日期,并在 x 轴上使用这些日期来改进我们的绘图:
from pathlib import Path
import csv
from datetime import datetime
import matplotlib.pyplot as plt
path = Path('weather_data/sitka_weather_07-2021_simple.csv')
lines = path.read_text().splitlines()
reader = csv.reader(lines)
header_row = next(reader)
# Extract dates and high temperatures.
dates, highs = [], [] (1)
for row in reader:
current_date = datetime.strptime(row[2], '%Y-%m-%d') (2)
high = int(row[4])
dates.append(current_date)
highs.append(high)
# Plot the high temperatures.
plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.plot(dates, highs, color='red') (3)
# Format plot.
ax.set_title("Daily High Temperatures, July 2021", fontsize=24)
ax.set_xlabel('', fontsize=16)
fig.autofmt_xdate() (4)
ax.set_ylabel("Temperature (F)", fontsize=16)
ax.tick_params(labelsize=16)
plt.show()我们创建两个空列表来存储文件 ❶ 中的日期和高温信息。然后,我们将包含日期信息的数据(row[2])转换为 datetime 对象❷,并将其附加到日期中。我们将日期和高温值传递给 plot() ❸。对 fig.autofmt_xdate() ❹ 的调用会以对角线绘制日期标签,以防止它们重叠。图 16-2 显示了改进后的图形。
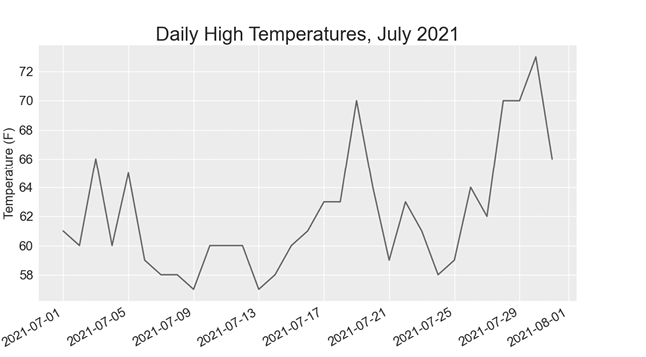
绘制更长的时间范围
图表绘制完成后,让我们加入更多数据,以便更全面地了解锡特卡的天气情况。将包含 Sitka 全年天气数据的 sitka_weather_2021_simple.csv 文件复制到存储本章程序数据的文件夹中。
现在我们可以生成一张全年天气图:
--snip--
path = Path('weather_data/sitka_weather_2021_simple.csv')
lines = path.read_text().splitlines()
--snip--
# Format plot.
ax.set_title("Daily High Temperatures, 2021", fontsize=24)
ax.set_xlabel('', fontsize=16)
--snip--我们修改文件名以使用新的数据文件 sitka_weather_2021_simple.csv,并更新绘图标题以反映其内容的变化。图 16-3 显示了生成的曲线图。
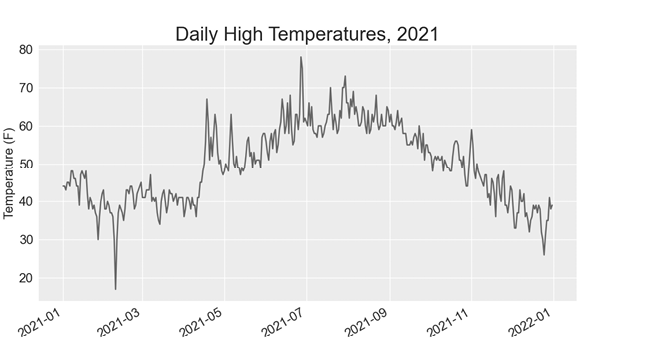
绘制第二个数据系列
我们可以通过加入低温来使图表更加有用。我们需要从数据文件中提取低温,然后将其添加到图表中,如图所示:
--snip--
reader = csv.reader(lines)
header_row = next(reader)
# Extract dates, and high and low temperatures.
dates, highs, lows = [], [], [] (1)
for row in reader:
current_date = datetime.strptime(row[2], '%Y-%m-%d')
high = int(row[4])
low = int(row[5]) (2)
dates.append(current_date)
highs.append(high)
lows.append(low)
# Plot the high and low temperatures.
plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.plot(dates, highs, color='red')
ax.plot(dates, lows, color='blue') (3)
# Format plot.
ax.set_title("Daily High and Low Temperatures, 2021", fontsize=24) (4)
--snip--我们添加一个空列表 lows 来保存低温❶,然后从每一行的第六个位置(row[5])提取并存储每个日期的低温❷。我们为低温添加一个 plot() 调用,并将这些值染成蓝色❸。最后,我们更新标题❹。图 16-4 显示了生成的图表。
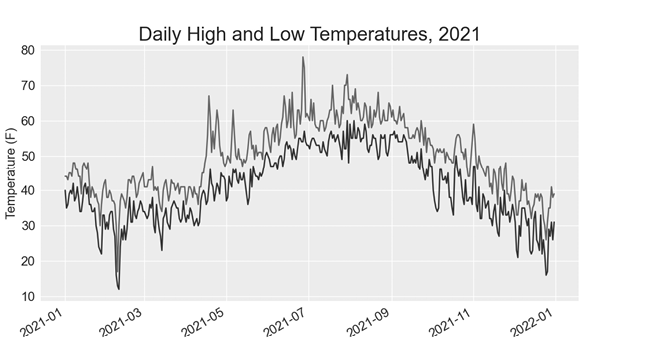
为图表中的区域添加阴影
添加了两个数据序列后,我们现在可以查看每天的气温范围。让我们用阴影来显示每天最高温度和最低温度之间的范围,为图表画龙点睛。为此,我们将使用 fill_between() 方法,该方法获取一系列 x 值和两个一系列 y 值,并填充两个一系列 y 值之间的空间:
--snip--
# Plot the high and low temperatures.
plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.plot(dates, highs, color='red', alpha=0.5) (1)
ax.plot(dates, lows, color='blue', alpha=0.5)
ax.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1) (2)
--snip--alpha 参数控制颜色的透明度❶。alpha 值为 0 表示完全透明,值为 1(默认值)表示完全不透明。通过将 alpha 设置为 0.5,我们可以使红色和蓝色的绘图线看起来更浅。
我们通过 fill_between() 传递 x 值的日期列表,然后传递两个 y 值系列的高点和低点❷。facecolor 参数决定了阴影区域的颜色;我们将其设为 0.1 的低 alpha 值,这样填充区域就能将两个数据序列连接起来,而不会干扰它们所代表的信息。图 16-5 显示了高点和低点之间的阴影区域。
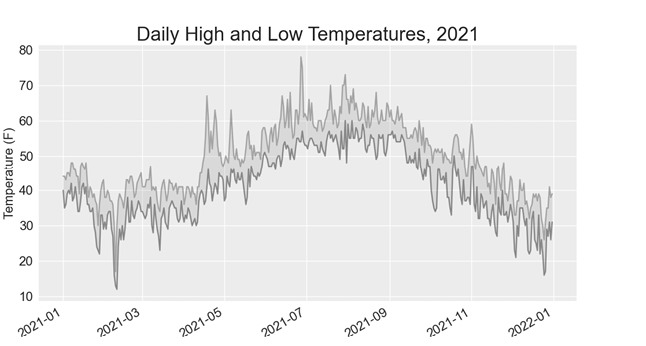
阴影有助于使两个数据集之间的范围立即显而易见。
错误检查
我们应该能够使用任何地点的数据运行 sitka_highs_lows.py 代码。但是,有些气象站收集的数据与其他气象站不同,有些气象站偶尔会出现故障,无法收集到一些应该收集的数据。数据缺失会导致异常,从而使我们的程序崩溃,除非我们处理得当。
例如,让我们看看当我们尝试生成加利福尼亚死亡谷的温度曲线图时会发生什么。将文件 death_valley_2021_simple.csv 复制到存储本章程序数据的文件夹中。
首先,让我们运行代码来查看该数据文件中包含的标头:
from pathlib import Path
import csv
path = Path('weather_data/death_valley_2021_simple.csv')
lines = path.read_text().splitlines()
reader = csv.reader(lines)
header_row = next(reader)
for index, column_header in enumerate(header_row):
print(index, column_header)下面是输出结果:
0 STATION
1 NAME
2 DATE
3 TMAX
4 TMIN
5 TOBS日期在相同的位置,位于索引 2。但最高温度和最低温度分别位于索引 3 和 4,因此我们需要更改代码中的索引,以反映这些新位置。该站不包含当天的平均温度读数,而是包含特定观测时间的 TOBS 读数。
修改 sitka_highs_lows.py,使用我们刚才提到的指数为死亡谷生成图表,看看会发生什么:
--snip--
path = Path('weather_data/death_valley_2021_simple.csv')
lines = path.read_text().splitlines()
--snip--
# Extract dates, and high and low temperatures.
dates, highs, lows = [], [], []
for row in reader:
current_date = datetime.strptime(row[2], '%Y-%m-%d')
high = int(row[3])
low = int(row[4])
dates.append(current_date)
--snip--我们更新程序,从死亡谷数据文件中读取数据,并将索引改为与该文件的 TMAX 和 TMIN 位置相对应。
当我们运行程序时,出现了错误:
Traceback (most recent call last):
File "death_valley_highs_lows.py", line 17, in <module>
high = int(row[3])
ValueError: invalid literal for int() with base 10: '' (1)回溯告诉我们,Python 无法处理其中一个日期的高温,因为它无法将空字符串 ('') 转换成整数 ❶。我们将直接处理数据丢失的情况,而不是通过查找数据来找出丢失的读数。
我们将在从 CSV 文件读取数值时运行错误检查代码,以处理可能出现的异常情况。
具体方法如下:
--snip--
for row in reader:
current_date = datetime.strptime(row[2], '%Y-%m-%d')
try: (1)
high = int(row[3])
low = int(row[4])
except ValueError:
print(f"Missing data for {current_date}") (2)
else: (3)
dates.append(current_date)
highs.append(high)
lows.append(low)
# Plot the high and low temperatures.
--snip--
# Format plot.
title = "Daily High and Low Temperatures, 2021\nDeath Valley, CA" (4)
ax.set_title(title, fontsize=20)
ax.set_xlabel('', fontsize=16)
--snip--每次检查一行时,我们都会尝试提取日期、最高温度和最低温度 ❶。如果缺少任何数据,Python 将引发一个 ValueError,我们将通过打印包含缺少数据的日期 ❷ 的错误消息来处理。打印错误信息后,循环将继续处理下一行。如果检索到某一日期的所有数据而没有出错,则运行 else 块,并将数据追加到相应的列表中 ❸。由于我们正在绘制一个新地点的信息,因此我们会更新标题以包含绘图上的地点,并使用较小的字体以适应较长的标题 ❹。
现在运行 death_valley_highs_lows.py,你会发现只有一个日期缺少数据:
Missing data for 2021-05-04 00:00:00由于错误得到了适当处理,我们的代码能够生成跳过缺失数据的曲线图。图 16-6 显示了生成的曲线图。
将此图与 Sitka 图进行比较,我们可以看到死亡谷的总体温度高于阿拉斯加东南部,这与我们的预期相符。此外,沙漠中每天的温度范围更大。阴影区域的高度清楚地表明了这一点。
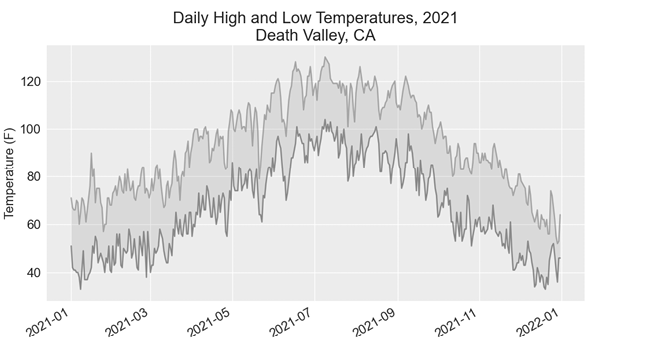
你处理的许多数据集都会有数据缺失、格式不当或不正确的情况。你可以使用本书前半部分学到的工具来处理这些情况。在这里,我们使用 try-except-else 块来处理缺失数据。有时,你会使用 continue 跳过某些数据,或者在提取数据后使用 remove() 或 del 删除某些数据。只要结果是有意义的、准确的可视化,使用任何可行的方法都可以。
下载您自己的数据
要下载自己的天气数据,请按照以下步骤操作:
访问 NOAA Climate Data Online 网站 https://www.ncdc.noaa.gov/cdo-web 。在 "发现数据" 部分,单击 "搜索工具"。在 "选择数据集" 框中,选择 "每日摘要"。
选择一个日期范围,然后在 "搜索 "部分选择 "邮政编码"。输入您感兴趣的 ZIP 代码,然后单击搜索。
在下一页,您将看到一张地图和一些关于您所关注地区的信息。在地点名称下方,单击 "查看完整详细信息",或单击地图,然后单击 "完整详细信息"。
向下滚动并单击气象站列表,查看该地区可用的气象站。单击其中一个站点名称,然后单击添加到购物车。虽然网站使用了购物车图标,但这些数据是免费的。在右上角,单击购物车。
在选择输出格式中,选择自定义 GHCN-Daily CSV。确保日期范围正确无误,然后点击继续。
在下一页,您可以选择所需的数据类型。您可以下载一种数据(例如,侧重于气温),也可以下载该台站的所有可用数据。做出选择后点击 "继续"。
在最后一页,您将看到订单摘要。输入您的电子邮件地址,然后单击提交订单。您将收到订单已收到的确认函,几分钟后,您应该会收到另一封电子邮件,其中包含下载数据的链接。
您下载的数据结构应与我们在本节中使用的数据相同。它的标题可能与你在本节中看到的不同,但如果你遵循我们在这里使用的相同步骤,你应该能够生成你感兴趣的可视化数据。