绘制全球数据集:GeoJson 格式
在本节中,您将下载一个数据集,其中包含上个月全球发生的所有地震。然后,您将制作一张地图,显示这些地震的位置以及每次地震的严重程度。由于数据是以 GeoJSON 格式存储的,因此我们将使用 json 模块处理这些数据。使用 Plotly 的 scatter_geo() plot,您将创建清晰显示全球地震分布的可视化效果。
下载地震数据
在保存本章程序的文件夹内新建一个名为 eq_data 的文件夹。将 eq_1_day_m1.geojson 文件复制到这个新文件夹中。地震按里氏震级分类。该文件包含过去 24 小时内(截至本文撰写时)发生的所有震级为 M1 或以上的地震的数据。这些数据来自美国地质调查局的地震数据源之一,网址为 https://earthquake.usgs.gov/earthquakes/feed 。
检查 GeoJSON 数据
打开 eq_1_day_m1.geojson,你会发现它非常密集,难以阅读:
{"type":"FeatureCollection","metadata":{"generated":1649052296000,...
{"type":"Feature","properties":{"mag":1.6,"place":"63 km SE of Ped...
{"type":"Feature","properties":{"mag":2.2,"place":"27 km SSE of Ca...
{"type":"Feature","properties":{"mag":3.7,"place":"102 km SSE of S...
{"type":"Feature","properties":{"mag":2.92000008,"place":"49km SE...
{"type":"Feature","properties":{"mag":1.4,"place":"44 km NE of Sus...
--snip--该文件的格式更适合机器而非人类使用。但我们可以看到,该文件包含一些字典以及我们感兴趣的信息,如地震震级和地点。
json 模块提供了多种用于探索和处理 JSON 数据的工具。其中一些工具将帮助我们重新格式化文件,这样我们就能在以编程方式处理数据之前更轻松地查看原始数据。
让我们从加载数据开始,以更易于阅读的格式显示数据。这是一个较长的数据文件,因此我们不打印它,而是将数据重写到一个新文件中。然后,我们可以打开该文件,更方便地来回滚动数据:
from pathlib import Path
import json
# Read data as a string and convert to a Python object.
path = Path('eq_data/eq_data_1_day_m1.geojson')
contents = path.read_text()
all_eq_data = json.loads(contents) (1)
# Create a more readable version of the data file.
path = Path('eq_data/readable_eq_data.geojson') (2)
readable_contents = json.dumps(all_eq_data, indent=4) (3)
path.write_text(readable_contents)我们以字符串形式读取数据文件,然后使用 json.loads() 将文件的字符串表示转换为 Python 对象❶。这与我们在第 10 章中使用的方法相同。在本例中,我们将整个数据集转换为一个字典,并将其赋值给 all_eq_data。然后,我们定义一个新路径,将相同的数据以更易读的格式❷ 写入其中。你在第 10 章中看到的 json.dumps() 函数可以接受一个可选的缩进参数❸,这个参数可以告诉它数据结构中嵌套元素的缩进程度。
在 eq_data 目录中打开文件 readable_eq_data.json,你会看到以下第一部分内容:
{
"type": "FeatureCollection",
"metadata": { // 1
"generated": 1649052296000,
"url": "https://earthquake.usgs.gov/earthquakes/.../1.0_day.geojson",
"title": "USGS Magnitude 1.0+ Earthquakes, Past Day",
"status": 200,
"api": "1.10.3",
"count": 160
},
"features": [ // 2
--snip--文件的第一部分包括一个关键字 "metadata"❶ 的部分。这部分告诉我们数据文件的生成时间,以及在哪里可以在线找到这些数据。它还提供了一个人类可读的标题以及该文件中包含的地震次数。在这 24 小时内,共记录了 160 次地震。
这个 GeoJSON 文件的结构对基于位置的数据很有帮助。信息存储在一个与关键 "features"❷ 相关联的列表中。由于该文件包含地震数据,因此数据以列表形式存在,列表中的每个项目都对应一个地震。这种结构可能看起来令人困惑,但却非常强大。它允许地质学家在每个地震的字典中存储尽可能多的信息,然后将所有这些字典放入一个大列表中。
让我们来看看代表一次地震的字典:
--snip--
{
"type": "Feature",
"properties": { // 1
"mag": 1.6,
--snip--
"title": "M 1.6 - 27 km NNW of Susitna, Alaska" // 2
},
"geometry": { // 3
"type": "Point",
"coordinates": [
-150.7585, // 4
61.7591, // 5
56.3
]
},
"id": "ak0224bju1jx"
},"properties" 键包含每个地震❶ 的大量信息。我们主要关注的是与关键字 "mag" 相关联的每次地震的震级。我们还对每个事件的 "title" 感兴趣,它提供了一个关于震级和位置❷ 的很好的摘要。
关键字 "geometry" 可以帮助我们了解地震发生的位置❸。我们需要这些信息来绘制每个事件的地图。我们可以在与关键字 "coordinates" 相关的列表中找到每个地震的经度❹ 和纬度❺。
这个文件包含的嵌套比我们写的代码要多得多,所以如果看起来很混乱,不用担心:Python 会处理大部分复杂的问题。我们每次只处理一到两个嵌套层。首先,我们将为 24 小时内记录的每一次地震创建一个字典。
|
当我们谈论地点时,通常会先说该地点的纬度,然后是经度。这一习惯的形成可能是因为人类发现纬度的时间远早于经度的概念。然而,许多地理空间框架先列出经度,然后再列出纬度,因为这与我们在数学表达中使用的 (x, y) 约定一致。GeoJSON 格式遵循(经度、纬度)惯例。如果您使用的是不同的框架,那么了解该框架所遵循的惯例非常重要。 |
列出所有地震
首先,我们将列出一份清单,其中包含发生的每一次地震的所有信息。
from pathlib import Path
import json
# Read data as a string and convert to a Python object.
path = Path('eq_data/eq_data_1_day_m1.geojson')
contents = path.read_text()
all_eq_data = json.loads(contents)
# Examine all earthquakes in the dataset.
all_eq_dicts = all_eq_data['features']
print(len(all_eq_dicts))我们获取与 all_eq_data 字典中的关键字 "features" 相关联的数据,并将其赋值给 all_eq_dicts。我们知道这个文件包含 160 个地震的记录,输出结果验证了我们已经捕获了文件中的所有地震:
160请注意这段代码有多短。格式整齐的 readable_eq_data.json 文件有 6000 多行。但只需几行代码,我们就能读取所有数据并将其存储在 Python 列表中。接下来,我们将提取每次地震的震级。
提取震级
我们可以在包含每次地震数据的列表中循环,提取我们想要的任何信息。让我们提取每次地震的震级:
--snip--
all_eq_dicts = all_eq_data['features']
mags = [] # 1
for eq_dict in all_eq_dicts:
mag = eq_dict['properties']['mag'] # 2
mags.append(mag)
print(mags[:10])我们先创建一个空列表来存储震级,然后在列表 all_eq_dicts ❶ 中循环。在这个循环中,每个地震都由字典 eq_dict 表示。每个地震的震级都存储在字典的 "属性" 部分,关键字为 "mag" ❷。我们将每个震级存储在变量 mag 中,然后将其追加到列表 mags 中。
我们将打印前 10 个震级,以便查看我们是否获得了正确的数据:
[1.6, 1.6, 2.2, 3.7, 2.92000008, 1.4, 4.6, 4.5, 1.9, 1.8]接下来,我们将提取每次地震的位置数据,然后我们可以制作地震地图。
提取位置数据
每次地震的位置数据都存储在 "geometry"(几何)键下。几何字典中有一个 "coordinates" 键,该列表中的前两个值是经度和纬度。下面是我们提取这些数据的方法:
--snip--
all_eq_dicts = all_eq_data['features']
mags, lons, lats = [], [], []
for eq_dict in all_eq_dicts:
mag = eq_dict['properties']['mag']
lon = eq_dict['geometry']['coordinates'][0] # 1
lat = eq_dict['geometry']['coordinates'][1]
mags.append(mag)
lons.append(lon)
lats.append(lat)
print(mags[:10])
print(lons[:5])
print(lats[:5])我们为经度和纬度创建空列表。代码 eq_dict['geometry'] 访问表示地震❶ 的几何元素的字典。第二个关键字 "坐标" 将调出与 "坐标" 相关的值列表。最后,0 索引会询问坐标列表中的第一个值,它对应于地震的经度。
当我们打印前 5 个经度和纬度时,输出结果显示我们提取的数据是正确的:
[1.6, 1.6, 2.2, 3.7, 2.92000008, 1.4, 4.6, 4.5, 1.9, 1.8]
[-150.7585, -153.4716, -148.7531, -159.6267, -155.24833679199
2]
[61.7591, 59.3152, 63.1633, 54.5612, 18.7551670074463]有了这些数据,我们就可以着手绘制每一次地震的地图了。
构建世界地图
利用我们目前获得的信息,我们可以绘制一幅简单的世界地图。虽然它看起来还不够美观,但我们要先确保信息显示正确,然后再关注风格和表现形式的问题。这是初始地图:
from pathlib import Path
import json
import plotly.express as px
--snip--
for eq_dict in all_eq_dicts:
--snip--
title = 'Global Earthquakes'
fig = px.scatter_geo(lat=lats, lon=lons, title=title) (1)
fig.show()与第 15 章中一样,我们导入 plotly.express 时使用了别名 px。使用 scatter_geo() 函数❶ 可以在地图上叠加地理数据的散点图。在这种图表类型的最简单应用中,只需提供一个纬度列表和一个经度列表。我们将列表 lats 传递给 lat 参数,将 lons 传递给 lon 参数。
运行该文件后,您将看到如图 16-7 所示的地图。这再次显示了 Plotly Express 库的强大功能;只需三行代码,我们就能得到全球地震活动的地图。
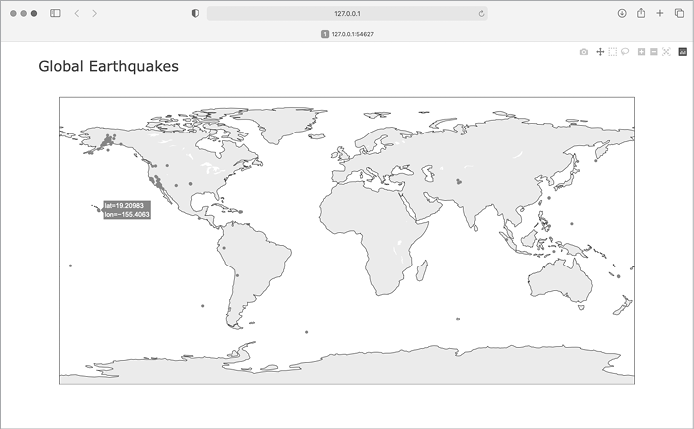
既然我们已经知道数据集中的信息被正确绘制,我们就可以做一些改动,使地图更有意义,更容易阅读。
代表数量级
地震活动图应显示每次地震的震级。既然我们知道数据的绘制是正确的,我们还可以加入更多的数据。
--snip--
# Read data as a string and convert to a Python object.
path = Path('eq_data/eq_data_30_day_m1.geojson')
contents = path.read_text()
--snip--
title = 'Global Earthquakes'
fig = px.scatter_geo(lat=lats, lon=lons, size=mags, title=title)
fig.show()我们加载 eq_data_30_day_m1.geojson 文件,以包含整整 30 天的地震活动。我们还在 px.scatter_geo() 调用中使用了 size 参数,它指定了地图上点的大小。我们将列表 mags 传递给 size,因此震级较高的地震将在地图上显示为较大的点。
生成的地图如图 16-8 所示。地震通常发生在构造板块边界附近,该地图中包含的较长时间地震活动揭示了这些边界的确切位置。
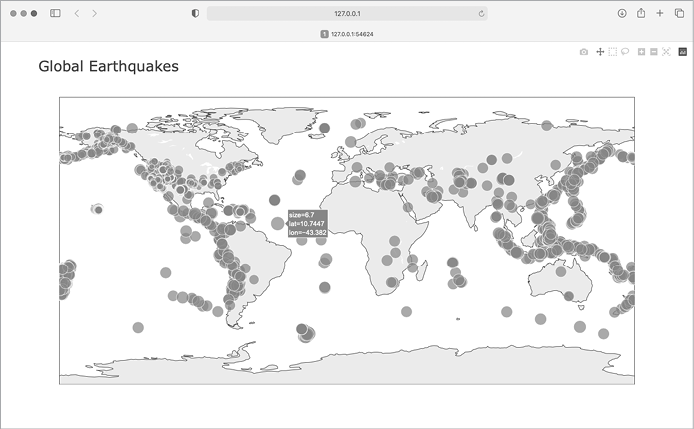
这张地图更好看一些,但仍然很难分辨出哪些点代表最重要的地震。我们还可以用颜色来表示震级,从而进一步改进。
自定义标记颜色
我们可以使用 Plotly 的色标,根据相应地震的严重程度自定义每个标记的颜色。我们还将为底图使用不同的投影。
--snip--
fig = px.scatter_geo(lat=lats, lon=lons, size=mags, title=title,
color=mags, # 1
color_continuous_scale='Viridis', # 2
labels={'color':'Magnitude'}, # 3
projection='natural earth', # 4
)
fig.show()这里的所有重要变化都发生在 px.scatter_geo() 函数调用中。color 参数告诉 Plotly 应该使用哪些值来确定每个标记在色标❶上的位置。我们使用 mags 列表来确定每个点的颜色,就像使用 size 参数一样。
color_continuous_scale 参数告诉 Plotly 使用哪个色标❷。Viridis 是一种从深蓝到亮黄的色标,在此数据集上使用效果很好。默认情况下,地图右侧的色标标注为颜色;这并不代表颜色的实际含义。第 15 章所示的标签参数将字典作为值❸。我们只需在这张图表上设置一个自定义标签,确保颜色标度的标签是 "幅度 "而不是 "颜色"。
我们增加了一个参数,用于修改绘制地震的底图。投影参数接受一系列常见的地图投影❹。这里我们使用 "自然地球 "投影,它将地图的两端修圆。另外,请注意最后一个参数后面的逗号。当一个函数调用有一长串跨行的参数时,通常的做法是在后面加上一个逗号,这样你就可以随时在下一行添加另一个参数。
现在运行程序,你会看到一个看起来更漂亮的地图。在图 16-9 中,颜色标度显示了单个地震的严重程度;最严重的地震以浅黄色点突出,与许多深色点形成鲜明对比。您还可以看出世界上哪些地区的地震活动更为频繁。
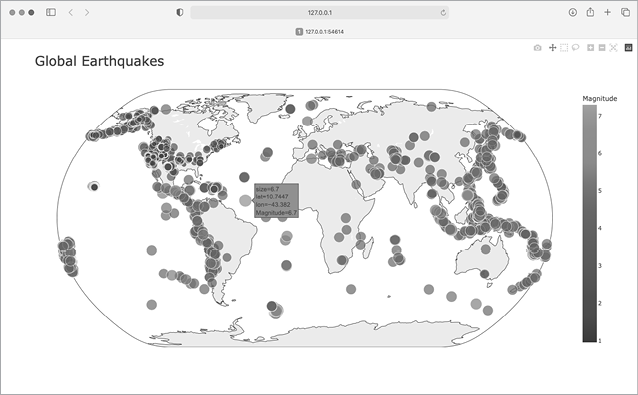
其他色标
您还可以选择其他一些颜色比例。要查看可用的颜色标度,请在 Python 终端会话中输入以下两行:
>>> import plotly.express as px
>>> px.colors.named_colorscales()
['aggrnyl', 'agsunset', 'blackbody', ..., 'mygbm']欢迎在地震地图或任何数据集中尝试使用这些颜色标度,不断变化的颜色有助于显示数据中的模式。
添加悬停文本
为了完成这张地图,我们将添加一些信息文本,当您将鼠标悬停在代表地震的标记上时,这些文本就会出现。除了显示默认的经度和纬度外,我们还将显示震级,并提供大致位置的描述。
要进行这一更改,我们需要从文件中提取更多数据:
--snip--
mags, lons, lats, eq_titles = [], [], [], [] # 1
mag = eq_dict['properties']['mag']
lon = eq_dict['geometry']['coordinates'][0]
lat = eq_dict['geometry']['coordinates'][1]
eq_title = eq_dict['properties']['title'] # 2
mags.append(mag)
lons.append(lon)
lats.append(lat)
eq_titles.append(eq_title)
title = 'Global Earthquakes'
fig = px.scatter_geo(lat=lats, lon=lons, size=mags, title=title,
--snip--
projection='natural earth',
hover_name=eq_titles, # 3
)
fig.show()我们首先创建一个名为 eq_titles 的列表,用于存储每个地震❶ 的标题。数据的 "标题 "部分包含每个地震的震级和位置的描述性名称,以及经度和纬度。我们提取这些信息并将其赋值给变量 eq_title ❷,然后将其附加到列表 eq_titles。
在 px.scatter_geo() 调用中,我们将 eq_titles 传递给 hover_name 参数 ❸。Plotly 现在会将每个地震的标题信息添加到每个点的悬停文本中。运行该程序后,您应该可以将鼠标悬停在任何标记上,查看该地震发生地点的描述,并读取其确切震级。图 16-10 展示了这些信息的一个示例。
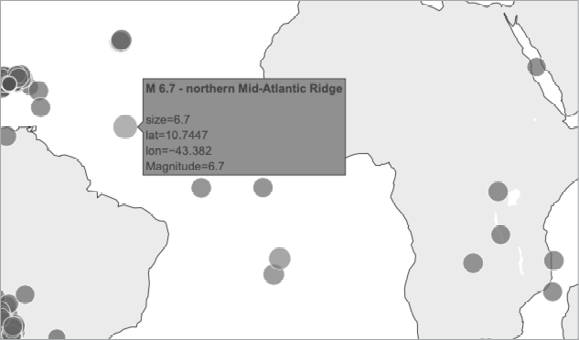
这令人印象深刻!只用了不到 30 行代码,我们就绘制出了一幅视觉效果极佳、意义深远的全球地震活动地图,同时还展示了地球的地质结构。Plotly 提供了多种自定义可视化外观和行为的方法。利用 Plotly 的众多选项,你可以制作出完全符合你要求的图表和地图。
总结
在本章中,你学习了如何处理真实世界的数据集。您处理了 CSV 和 GeoJSON 文件,并提取了想要关注的数据。通过使用历史天气数据,你进一步了解了如何使用 Matplotlib,包括如何使用日期时间模块以及如何在一个图表上绘制多个数据序列。你在 Plotly 的世界地图上绘制了地理数据,并学会了自定义地图样式。
随着你在处理 CSV 和 JSON 文件方面经验的积累,你几乎可以处理任何你想分析的数据。您可以下载大多数在线数据集的 CSV 和 JSON 格式。通过使用这些格式,你还能学会如何更轻松地处理其他数据格式。
在下一章中,你将编写能自动从在线资源中收集数据的程序,然后创建可视化数据。如果你想把编程作为业余爱好,这些技能会很有趣;如果你对专业编程感兴趣,这些技能也很关键。