Schemas 和 tables
关系型数据库系统通常具有相同的结构。它们将数据存储在不同的数据库或模式中,将不同应用程序的数据分开。这些 schemas 只是表的集合。tables 是特定数据结构的定义,由字段组成。fields 是一种基本数据类型,它定义了信息的最小组成部分,就好像数据的原子。因此,模式是由字段组成的表组。让我们逐一了解这些元素。
理解 Schemas
如前所述,模式或数据库(在 MySQL 中是同义词)是具有共同上下文的表集合,通常属于同一个应用程序。实际上,这并没有什么限制,如果需要,你可以有多个属于同一应用程序的模式。不过,对于小型网络应用来说,就像我们的情况一样,我们将只有一个模式。
你的服务器可能已经有了一些模式。它们通常包含 MySQL 运行所需的元数据,我们强烈建议你不要修改它们。相反,让我们创建自己的模式。模式是非常简单的元素,只有一个必须的名称和一个可选的字符集。名称标识模式,字符集定义字符串应遵循的编码或 "字母表 "类型。默认字符集为 latin1,如果不需要更改,则无需指定。
使用 "创建模式"(CREATE SCHEMA),然后输入模式名称,创建我们将用于书店的模式。模式名称必须具有代表性,就叫它 bookstore 吧。记得在行尾加上分号。请看下面的内容:
mysql> CREATE SCHEMA bookstore;
Query OK, 1 row affected (0.00 sec)如果需要记住模式是如何创建的,可以使用 SHOW CREATE SCHEMA 查看其描述,如下所示:
mysql> SHOW CREATE SCHEMA bookstore \G
*************************** 1. row ***************************
Database: bookstore
Create Database: CREATE DATABASE `bookstore` /*!40100 DEFAULT CHARACTER SET latin1 */
1 row in set (0.00 sec)正如您所看到的,我们用 \G 而不是分号结束了查询。这会告诉客户端以不同于分号的方式格式化响应。在使用 SHOW CREATE 系列命令时,我们建议您使用 \G 结束命令,以获得更好的理解。
|
应该使用大写还是小写?
在编写查询时,您可能会注意到,我们使用大写字母表示关键字,小写字母表示标识符,如模式名称。这只是一个广泛使用的惯例,目的是让大家清楚什么是 SQL 的一部分,什么是你的数据。不过,MySQL 关键字不区分大小写,所以你可以使用任何大小写。 |
所有数据必须属于一个模式。不能有数据在所有模式之外漂浮。这样,除非指定要使用的模式,否则就无法执行任何操作。为此,只需在启动客户端后,使用 USE 关键字,并在后面跟上模式名称即可。另外,还可以告诉客户端在连接时使用哪种模式,如下所示:
mysql> USE bookstore;
Database changed如果不记得自己的模式名称,或者想查看服务器中还有哪些模式,可以运行 SHOW SCHEMAS; 命令来获取它们的列表,如下所示:
mysql> SHOW SCHEMAS;
+--------------------+
| Database |
+--------------------+
| information_schema |
| bookstore |
| mysql |
| test |
+--------------------+
4 rows in set (0.00 sec)数据库数据类型
与 PHP 一样,MySQL 也有数据类型。它们用于定义字段可包含的数据类型。与 PHP 一样,MySQL 的数据类型非常灵活,可以根据需要从一种类型转换为另一种类型。数据类型有很多,但我们将解释最重要的几种。如果您想使用更复杂的数据结构构建应用程序,我们强烈建议您访问 http://dev.mysql.com/doc/refman/5.7/en/data-types.html 上与数据类型相关的官方文档。
数字数据类型
数值数据可分为整数和十进制数。对于整数,MySQL 使用 INT 数据类型,尽管还有更小的数字(如 TINYINT、SMALLINT 或 MEDIUMINT)或更大的数字(如 BIGINT)的存储版本。下表显示了不同数值类型的大小,因此您可以根据实际情况选择使用哪种类型:
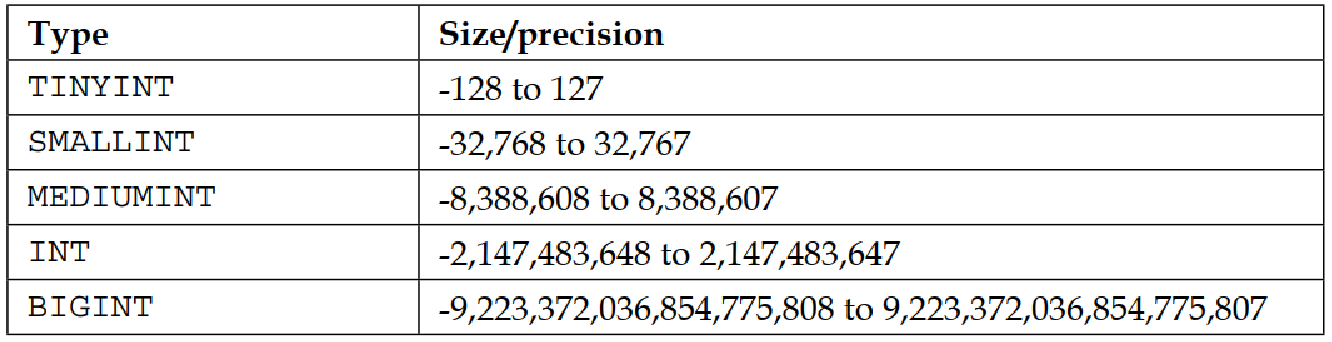
数值类型可以默认定义为有符号或无符号;也就是说,可以允许或不允许它们包含负值。如果将数值类型定义为无符号类型,由于不需要为负数保留空间,其可接受的数值范围将扩大一倍。
对于十进制数,我们有两种类型:近似值和精确值,近似值处理速度更快,但有时并不精确;精确值可提供精确的十进制值。对于近似值或浮点类型,我们有 FLOAT 和 DOUBLE。对于精确值或定点类型,我们有 DECIMAL。
MySQL 允许指定数字的位数和小数点位置。例如,要指定一个数字可以包含五位数,其中最多两位数可以是小数,我们将使用 FLOAT(5,2) 符号。当我们创建包含价格的表格时,就会发现这种约束非常有用。
字符串数据类型
尽管有多种数据类型可以存储从单个字符到大段文本或二进制代码,但这不在本章的讨论范围之内。在本节中,我们将向你介绍三种类型: CHAR、VARCHAR 和 TEXT。
CHAR 是一种允许存储精确字符数的数据类型。定义字段后,您需要指定字符串的长度,从此以后,该字段的所有值都必须是这个长度。在我们的应用程序中,一种可能的用法是存储图书的 ISBN,因为我们知道它总是 13 个字符。
VARCHAR 或变量 char 是一种数据类型,允许存储长度不超过 65,535 个字符的字符串。您无需指定字符串的长度,也可以顺利插入不同长度的字符串。当然,由于这种类型是动态的,因此处理速度比前一种慢,但几次之后,你就知道字符串的长度了。你可以告诉 MySQL,即使你想插入不同长度的字符串,最大长度也将是一个确定的数字。这将有助于提高性能。例如,名字有不同的长度,但可以肯定的是,没有名字会超过 64 个字符,因此可以将字段定义为 VARCHAR(64)。
最后,TEXT 是一种用于大字符串的数据类型。如果要存储用户的长评论、文章等,就可以使用它。与 INT 一样,这种数据类型也有不同的版本: TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。尽管这些数据类型在几乎所有与用户交互的网络应用程序中都非常重要,但我们不会在我们的应用程序中使用它们。
值列表
在 MySQL 中,可以强制字段具有一组有效值。它们有两种类型: ENUM(允许使用一个预定义值)和 SET(允许使用任意数量的预定义值)。
例如,在我们的应用程序中,我们有两种类型的客户:基本客户和高级客户。如果我们想在数据库中存储客户,那么其中一个字段就有可能是客户类型。由于客户必须是 "基本 "或 "高级",一个好的解决方案是将该字段定义为一个枚举,如 ENUM("basic"、"premium")。这样,我们就能确保数据库中存储的所有客户都是正确的类型。
虽然枚举的使用非常普遍,但集合的使用却不那么广泛。通常,使用一个额外的表来定义列表的值是一个更好的主意,这一点在本章讨论外键时会提到。
日期和时间数据类型
日期和时间类型是 MySQL 中最复杂的数据类型。尽管想法很简单,但围绕这些类型有多种函数和边缘情况。我们无法一一列举,因此只解释最常见的用途,也是我们的应用程序所需要的用途。
DATE 存储日期,即日、月、年的组合。时间存储时间,即小时、分钟和秒的组合。DATETIME 是日期和时间的数据类型。对于这些数据类型中的任何一种,您都可以只提供一个字符串来指定值是什么,但需要注意使用的格式。尽管可以随时指定输入数据的格式,但也可以直接以默认格式输入日期或时间—例如,日期为 2014-12-31,时间为 14:34:50,日期和时间为 2014-12-31 14:34:50。
第四种类型是 TIMESTAMP。该类型存储一个整数,表示从 1970 年 1 月 1 日开始的秒数,也称为 Unix 时间戳。这是一种非常有用的类型,因为在 PHP 中,使用 now() 函数很容易获得当前的 Unix 时间戳,而且这种数据类型的格式总是相同的,因此使用它更安全。缺点是与其他类型相比,它能表示的日期范围有限。
有一些函数可以帮助您管理这些类型。这些函数可以提取整个值的特定部分、以不同格式返回值、添加或减去日期等。让我们来看看这些函数的简短列表:
| 函数名称 | 描述 |
|---|---|
DAY(),MONTH(),YEAR() |
从提供的 DATE 或 DATETIME 值中提取日、月或年的特定值。 |
HOUR(),MINUTE(),SECOND() |
从 TIME 或 DATETIME 提供的值中提取小时、分钟或秒的特定值。 |
CURRENT_DATE() 和 CURRENT_TIME() |
返回当前日期或当前时间。 |
NOW() |
返回当前日期和时间。 |
DATE_FORMAT() |
返回具有指定格式的 DATE、TIME 或 DATETIME 值。 |
DATE_ADD() |
将指定的时间间隔添加到给定的日期或时间类型。 |
如果您对如何使用这些函数感到困惑,请不要担心;在本书的其余部分,我们将在应用程序中使用这些函数。此外,所有类型的详细列表请访问 http://dev.mysql.com/doc/refman/5.7/en/dateand-time-functions.html 。
管理表
在了解了字段所能承载的不同数据类型后,现在是介绍表格的时候了。正如在 "模式和表格" 一节中所定义的,表格是定义信息类型的字段集合。我们可以将其与 OOP 相比较,将表视为类,字段是其属性。类的每个实例都是表中的一行。
定义表格时,必须声明表格包含的字段列表。对于每个字段,都需要指定其名称、类型以及一些与字段类型相关的额外信息。最常见的有:
-
NOT NULL:如果字段不能为空,即每一行都需要一个具体的有效值,则使用该值。默认情况下,字段可以为空。
-
UNSIGNED:如前所述,用于禁止在该字段中使用负数。默认情况下,数值字段接受负数。
-
DEFAULT <value>:定义一个默认值,以防用户不提供任何值。如果未指定该子句,默认值通常为空。
与模式一样,表定义也需要一个名称和一些可选属性。你可以定义表的字符集或引擎。引擎是一个相当大的话题,但在本章的范围内,我们只需注意,如果我们需要表之间的强关系,就应该使用 InnoDB 引擎。更多有关 MySQL 引擎的信息,请访问 https://dev.mysql.com/doc/refman/5.0/en/storage-engines.html 。
了解了这些,让我们尝试创建一个表来保存我们的书籍。表的名称应该是 book,因为每一行都将定义一本书。字段可以具有与 Book 类相同的属性。让我们来看看创建表格的查询是怎样的:
mysql> CREATE TABLE book(
-> isbn CHAR(13) NOT NULL,
-> title VARCHAR(255) NOT NULL,
-> author VARCHAR(255) NOT NULL,
-> stock SMALLINT UNSIGNED NOT NULL DEFAULT 0,
-> price FLOAT UNSIGNED
-> ) ENGINE=InnoDb;
Query OK, 0 rows affected (0.01 sec)正如你所注意到的,我们可以添加更多新行,直到以分号结束查询。这样,我们就能以一种看起来更易读的方式格式化查询。MySQL 会让我们知道我们仍在编写相同的查询,并显示 -> 提示。由于该表包含五个字段,我们很可能需要不时刷新我们的记忆,因为我们会忘记它们。为了显示表的结构,可以使用 DESC 命令,如下所示:
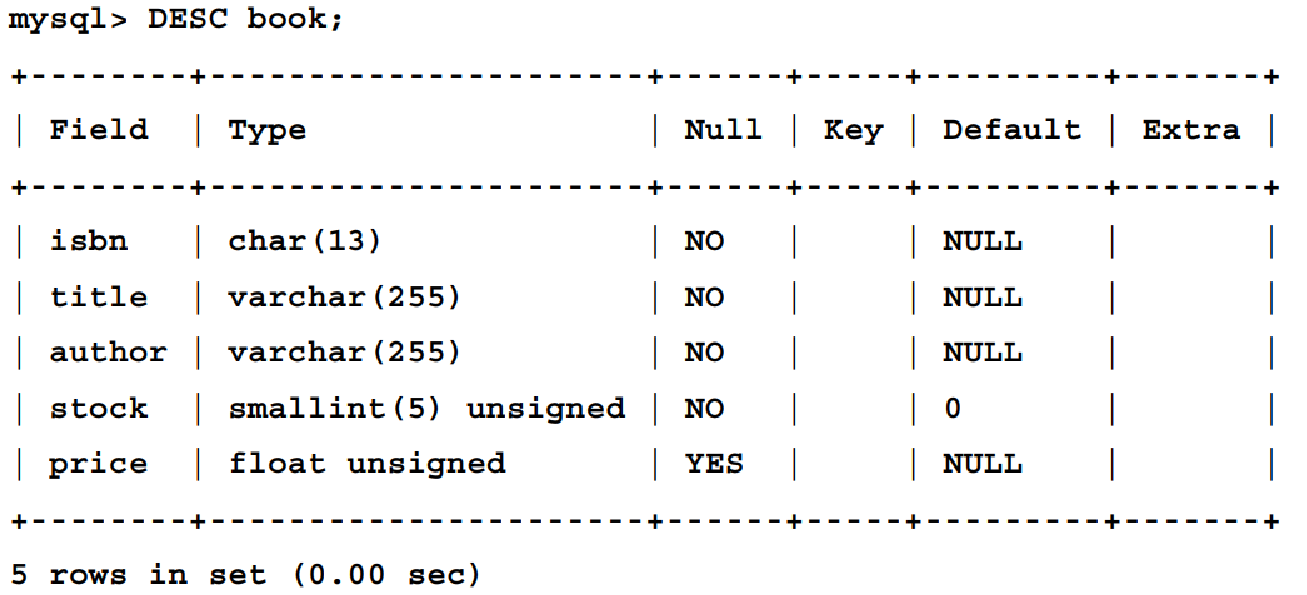
我们使用 SMALLINT 来表示库存量,因为同一本书的库存量不可能超过几千册。我们知道 ISBN 的长度为 13 个字符,因此在定义字段时强制执行了这一规定。最后, stock 和 price 都是无符号的,因为负值没有意义。现在,让我们通过以下脚本创建 customer 表:
mysql> CREATE TABLE customer(
-> id INT UNSIGNED NOT NULL,
-> firstname VARCHAR(255) NOT NULL,
-> surname VARCHAR(255) NOT NULL,
-> email VARCHAR(255) NOT NULL,
-> type ENUM('basic', 'premium')
-> ) ENGINE=InnoDb;
Query OK, 0 rows affected (0.00 sec)在设计类时,我们已经预料到要使用枚举来表示字段类型,因为我们可以画出一张图来确定数据库的内容。在这个图上,我们可以显示表及其字段。让我们来看看表格图目前的样子:

请注意,即使我们创建了与类类似的表,我们也不会为 Person 创建表。原因是数据库存储的是数据,而这个类没有任何数据可以存储,因为 customer 表已经包含了我们需要的一切。此外,有时我们可能会创建一些在代码中并不存在的类表,因此类表关系是一种非常灵活的关系。