作为依赖的接口
和往常一样,实施和探索单元测试技术从探索代码编写技术开始。这是本书中我们将经常看到的主题。我们无法孤立地研究测试,它需要对代码设计及其预期目的的深入理解。
在本节中,我们将探讨软件依赖的概念以及如何管理这些依赖。
图 3.1 展示了三种主要类型的依赖关系:
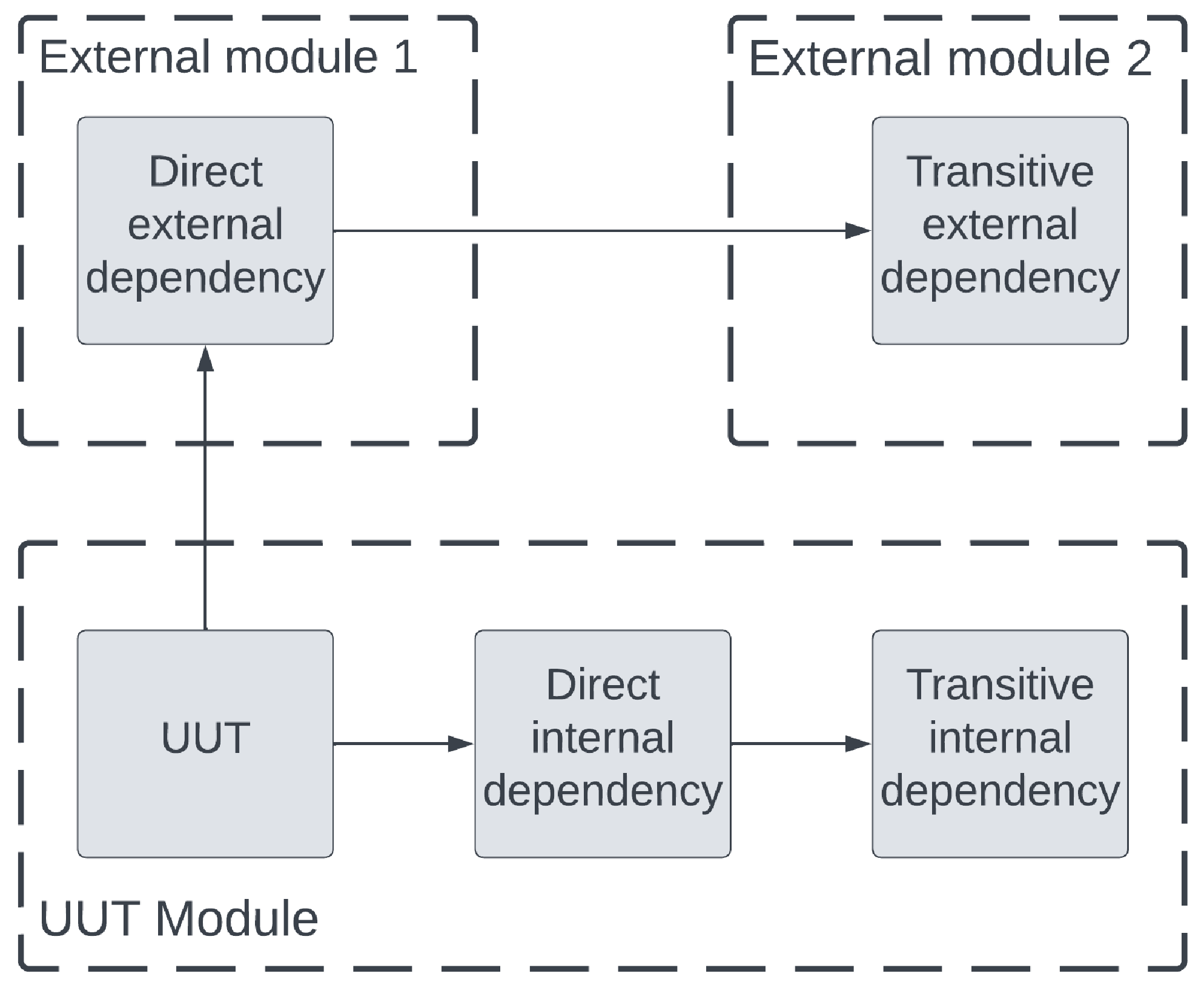
从 UUT(单元测试对象)的角度来看,主要有四种依赖类型:
-
直接内部依赖:这些包含了 UUT 引入的内部功能。这些依赖可以在与 UUT 相同的包或模块中定义,但它们是 UUT 功能实现所必需的。
-
传递性内部依赖:这些包含了直接内部依赖部分的内部功能。它们也可以在与 UUT 相同的包或模块中定义。
-
直接外部依赖:这些包含了 UUT 引入的第三方功能。它们可能是您依赖的库或服务 API,但并不包含在当前模块中。
-
传递性外部依赖:这些包含了直接外部依赖所依赖的外部功能,但它们位于单独的模块中。由于 Go 构建源代码和所需库为可执行文件的方式,这些传递性依赖也将与您的代码一起包含在应用程序的发布版本中。
UUT 的依赖是 UUT 正确交付其功能所必需的。因此,这些依赖对于完全测试其功能也是必需的。在本节和本章中,我们将探索处理代码依赖的技术。
|
不要重新发明轮子
编写依赖于其他组件的代码是软件设计中的一种正常且推荐的做法。它允许我们在多个地方重用行为和实现。结合 Go 强大的模块和包系统,使得编写复杂代码变得既容易又快速。我们在第 2 章《单元测试基础》中探讨了 Go 的模块和包系统。 |
依赖注入
处理代码依赖关系的一个流行且常见的技术是依赖注入(DI)概念。这是一个简单而有效的设计模式,用于创建松耦合的代码,允许我们在实现代码时不必过多关心其依赖关系。
DI 是一种编写代码的风格,其中 UUT 或函数在初始化时接收它所依赖的其他类型或函数。从根本上说,DI 仅仅是将正确的参数传递给一个函数,然后该函数使用这些参数来创建 UUT。
这一技术是 SOLID 设计原则之一,特别是其中的字母 D,代表依赖倒置原则(Dependency Inversion)。我们将在本章后面的《编写可测试代码》一节中探讨所有这些原则。
|
为什么叫做注入?
术语 “注入” 简单地意味着依赖关系不是由需要它们的 UUT 创建的,而是从更高层次传递给它们。依赖可以通过构造函数/函数注入,或者通过使用框架来注入。 |
图 3.2 描述了 DI 通常涉及的主要步骤:
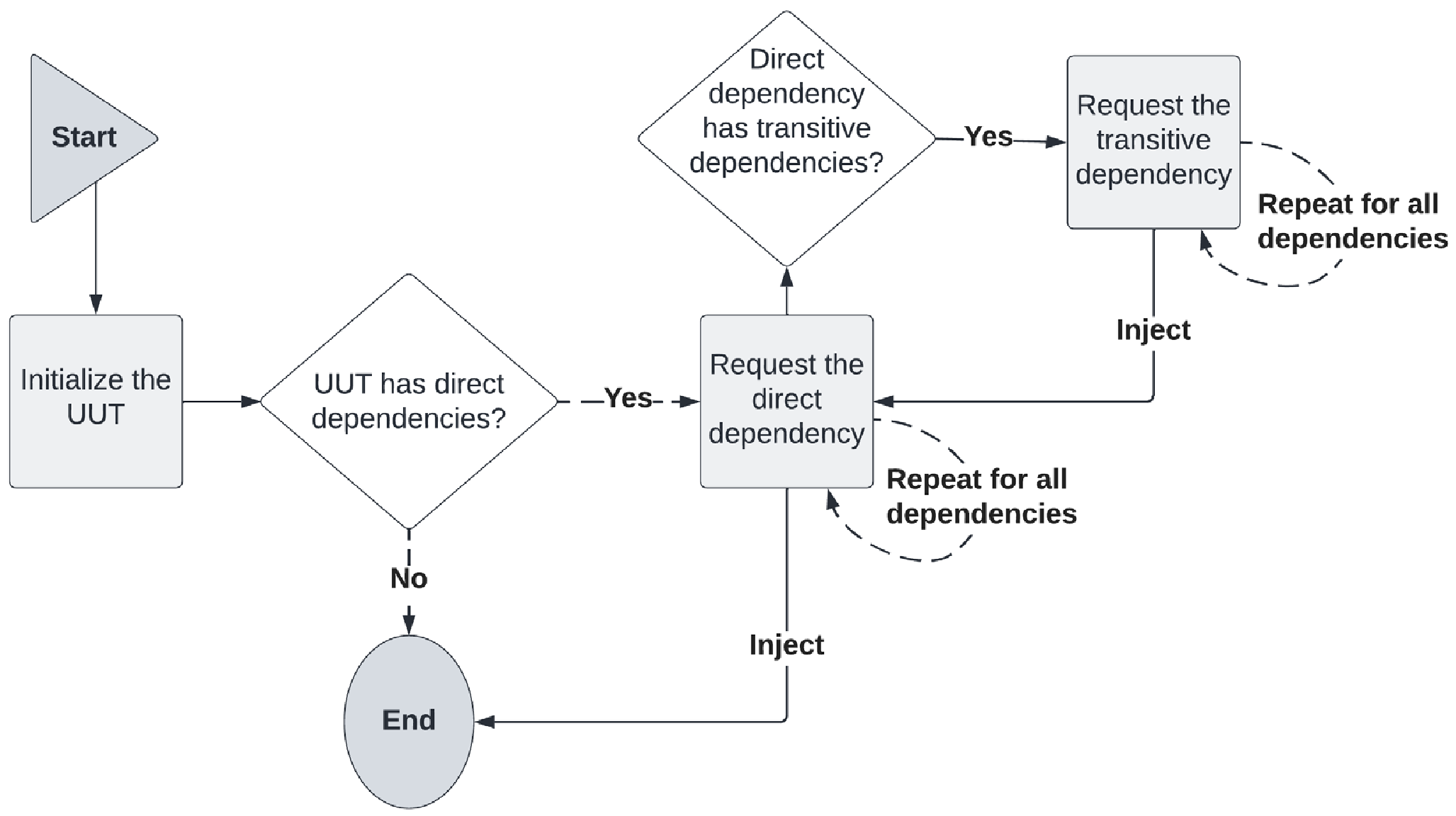
我们可以看到以下的调用顺序:
-
初始化 UUT:一开始,我们尝试初始化 UUT。在 Go 中,UUT 通常是一个结构体。我们已经知道,Go 的结构体不提供构造函数,因此初始化过程将涉及检查 UUT 所需的依赖项。在下一节中,我们将看到使依赖关系需求显式化的技术。
-
请求直接依赖:如果 UUT 有任何直接依赖关系,我们将请求直接依赖。这个直接依赖通常也是一个结构体,可以来自相同模块或另一个外部模块。
-
请求传递性依赖:在初始化直接依赖时,我们可能会发现直接依赖在初始化过程中需要的传递性依赖。我们将请求传递性依赖。
-
重复依赖请求过程:这个依赖请求过程会对所有直接和传递性依赖进行重复。
-
依赖注入:一旦每个依赖成功创建,它就会被注入到之前依赖的创建过程中,或者直接注入到 UUT 中,如果它是一个直接依赖。
|
依赖图
由于依赖关系需要被创建并随后被注入,这个过程被称为构建依赖图。它是一个有向无环图(DAG)。这个图允许编译器从根开始,然后在运行主程序时遍历图,构建所有需要的自定义类型。 |
实现依赖注入
在引入依赖注入(DI)时,我们简要提到过结构体没有构造函数,因此这个过程可能需要检查结构体的属性和字段。让我们看看如何在 Go 中实现 DI。
从根本上讲,有两种方式可以进行依赖注入:
-
构造函数注入:这包括将所有必需的依赖项传递给一个特殊的构造函数,该函数返回 UUT 结构体的实例。这是一种直观的实例化方式,但它要求在调用函数之前创建所有的依赖项。
-
属性/方法注入:这包括创建 UUT 结构体,然后根据需要设置依赖项的字段。可以通过直接将它们作为字段设置到 UUT 实例中,或者通过调用设置器方法将它们设置到字段上。依赖项不是不可变的,因此设置它们时不需要重新创建 UUT 实例。这种方式创建 UUT 及其依赖项时,不要求在初始化并开始使用 UUT 之前创建所有依赖项,但它也不能保证所有依赖项会在某个时间点被设置,或者不会在之后被更改。这可能需要更多的应用代码来进行空值检查,以及避免因依赖关系变化而导致的其他潜在问题。
然后,每种方法可以以两种方式使用:
-
手动调用:这意味着我们手动调用并创建 UUT 结构体及其依赖项。在这个过程中,您可以完全控制依赖项的创建和调用,但对于较大的代码库,管理起来可能会变得困难。
-
依赖注入框架:这意味着您可以将另一个依赖项导入到项目中,使用反射或代码生成等高级技术自动化这个过程,并利用依赖图按正确的顺序创建依赖项。对于大型代码库来说,这种方法更加可持续。
对于 DI 框架,有两个流行的开源选择可以在代码中使用:
-
dig:使用反射构建您的依赖图并成功构造实例。您可以在 https://github.com/uber-go/dig 查看如何使用它。
-
wire:使用反射和代码生成进行 DI。您可以在 https://github.com/google/wire 查看如何使用它。
|
降低复杂性
记住,Go 代码和软件设计的核心原则之一是简洁性。您应该保持代码尽可能简单,避免像其他传统语言中那样冗长的构造函数。 |
在依赖关系方面,它们通常使用对应的接口类型来表示。这是 Go 中的一种独特方式,无论您选择如何注入依赖项。让我们更仔细地看看接口在软件设计中的作用。
接口是命名的、包含零个或多个方法的集合。以下是它们行为的一些关键点:
-
它们是 Go 中实现多态的主要方式。
-
编译器会强制执行接口,并自动将结构体转换为其对应的接口。
-
要实现一个接口,结构体需要实现接口定义的方法。
-
一个结构体可以实现多个接口,只要它满足接口方法的签名。
-
一个包含零个方法的接口是空接口,类型为
interface{}。在某些情况下这很有用,但您创建的接口将会有一个或多个方法。 -
接口的零值是
nil。在开始使用接口来包装依赖项时,我们需要在代码中处理这一点。
|
接口定义的是方法,而不是函数
记住,接口定义的是方法,而不是函数。正如我们在 |
让我们来看一个依赖注入(DI)的示例;该示例可以在 chapter03/di/manual/calculator.go 中找到。我们可以定义一个简单的 Adder 接口,代码如下:
type Adder interface {
Add(x, y float64) float64
}Adder 接口定义了一个 Add 方法。注意,该方法接受两个 float64 类型的参数,并返回一个 float64 类型的返回值。在我们的例子中,Engine 将实现这个接口,因为它实现了这个方法:
func (e Engine) Add(x, y float64) float64 {
return x + y
}当我们初始化 Engine 时,可以返回 Engine 结构体的实例:
func NewEngine() *Engine {
return &Engine{}
}一个简单的 Calculator 使用这个 Engine 来实现加法功能并打印结果:
type Calculator struct {
Adder Adder
}
func NewCalculator(a Adder) *Calculator {
return &Calculator{Adder: a}
}
func (c Calculator) PrintAdd(x, y float64) {
fmt.Println("Result:", c.Adder.Add(x, y))
}Engine 是 Calculator 的依赖,因此它是 NewCalculator 函数的一个参数。然后,在 PrintAdd 方法中调用 Adder,在需要时使用它的功能。因此,Calculator 的初始化过程需要创建 Engine 的实例才能编译:
func main() {
engine := NewEngine()
calc := NewCalculator(engine)
calc.PrintAdd(2.5, 6.3)
}这个例子使用了手动调用的依赖注入(DI)。随着依赖图的增大和复杂化,初始化函数将变得越来越繁琐,并且需要修改。此时,DI 框架可以帮助简化代码。
使用之前介绍的 wire 框架,我们可以在 /chapter03/di/wire/wire.go 文件中定义一个 InitCalc 函数,该函数将负责初始化 Calculator 及其 Engine:
//go:build wireinject
package main
import "github.com/google/wire"
var Set = wire.NewSet(NewEngine, wire.Bind(new(Adder), new(*Engine)), NewCalculator)
func InitCalc() *Calculator {
wire.Build(Set)
return nil
}wire.Build 函数接受一个 Set,它将 Adder 接口与 Engine 结构体匹配。在文件的顶部,我们使用了一个构建标签来将这个文件从最终的二进制文件中排除,并在运行应用程序时使用生成的替代文件。
接下来,我们必须安装 wire 工具,并在正确的目录中运行它:
$ go install github.com/google/wire/cmd/wire@latest
$ cd chapter03/di/wire && wire
wire: github.com/PacktPublishing/Test-Driven-Development-in-Go/chapter03/di/wire: wrote /Users/adelinasimion/code/Test-DrivenDevelopment-in-Go/chapter03/di/wire/wire_gen.go此命令生成了 wire_gen.go 文件,其中包含了 InitCalc 函数的实现:
func InitCalc() *Calculator {
adder := NewEngine()
calculator := NewCalculator(adder)
return calculator
}这个函数包含了我们之前手动编写的依赖创建代码。现在,由于 wire 自动生成和维护这些代码,变化将不再需要手动维护,主函数也变得更简单:
func main() {
calc := InitCalc()
calc.PrintAdd(2.5, 6.3)
}最后,我们可以构建应用程序,生成初始化函数,并将其绑定到 Go 二进制文件中。然后,我们可以像往常一样运行可执行文件:
$ go build ./chapter03/di/wire
$ ./wire
Result: 8.8DI 框架简化了我们编写和维护的代码,但它确实需要在构建过程中添加新步骤,并且在刚开始使用时需要额外的认知负担。我们在本节中探讨了 wire DI 库的工作原理,但我们将继续使用手动注入,以便我们能更好地控制代码并一起探索。
用例 – 计算器的继续实现
在本节中,我们将利用到目前为止所学的技术,扩展第2章《单元测试基础》中实现的计算器部分。
撇开测试驱动开发(TDD)的正确程序,我们来考虑一下输入的 Parser 结构体的实现草图:
type Parser struct {
engine *calculator.Engine
validator *Validator
}
// ProcessExpression 解析表达式并将其发送到计算器
func (p *Parser) ProcessExpression(expr string) (*string, error) {
operation, err := p.getOperation(expr)
if err != nil {
return nil, format.Error(expr, err)
}
return p.engine.ProcessOperation(*operation)
}正如我们在第 2 章《单元测试基础》中所了解的,Parser 依赖于 Validator 和 calculator.Engine。这两个结构体是 Parser 的直接依赖项。
然后,这些依赖项用于实现 ProcessExpression 方法的功能。
无论我们使用第三方依赖注入框架,还是手动创建相应的结构体,编写这个相对简单代码片段的测试涉及以下几个步骤:
-
初始化
Parser结构体及其所有直接和传递依赖项。这可能涉及较长的设置过程,尤其是外部依赖项,这可能会扩展测试的范围。 -
一旦这些主要构建块被创建,我们还需要设置它们的前置条件状态。这可能会涉及更加复杂的设置,并且可能会带来一些意外的后果。
-
在验证方面,我们可能需要断言依赖项的内部状态,以确保它们按预期工作。对依赖项内部状态的依赖会使得测试更加脆弱,因为依赖项的变化会导致测试失败。
现在我们已经了解了如何构建需要直接依赖项的代码,我们将开始探索可以帮助我们测试这些依赖项的机制。我们将利用 Go 开发工具,使得测试和断言变得更加容易。
|
控制测试范围
当涉及到有许多依赖项的类型时,测试的设置和断言范围可能会超出 UUT(单元测试目标)。我们需要一种机制,使我们能够在隔离状态下测试 UUT,这样不仅有助于保持测试范围的小巧,而且能够有效地控制测试的复杂性。 |