用例 – 扩展 BookSwap 应用
《BookSwap》网页应用程序在《第 4 章 构建高效的测试套件》中介绍。其主要功能允许用户列出他们的书籍,并与其他用户交换。我们了解了其主要组件和端点,以及如何将表格测试应用于其 BookService。在《第 5 章 执行集成测试》中,我们学习了如何为其 Index 请求处理程序编写集成测试。在本章中,我们将继续扩展该应用程序的功能,深入分析每个端点的用户流程和预期功能。
图6.1 概述了《BookSwap》应用程序的三个主要服务——BookService、UserService 和 PostingService 的职责:
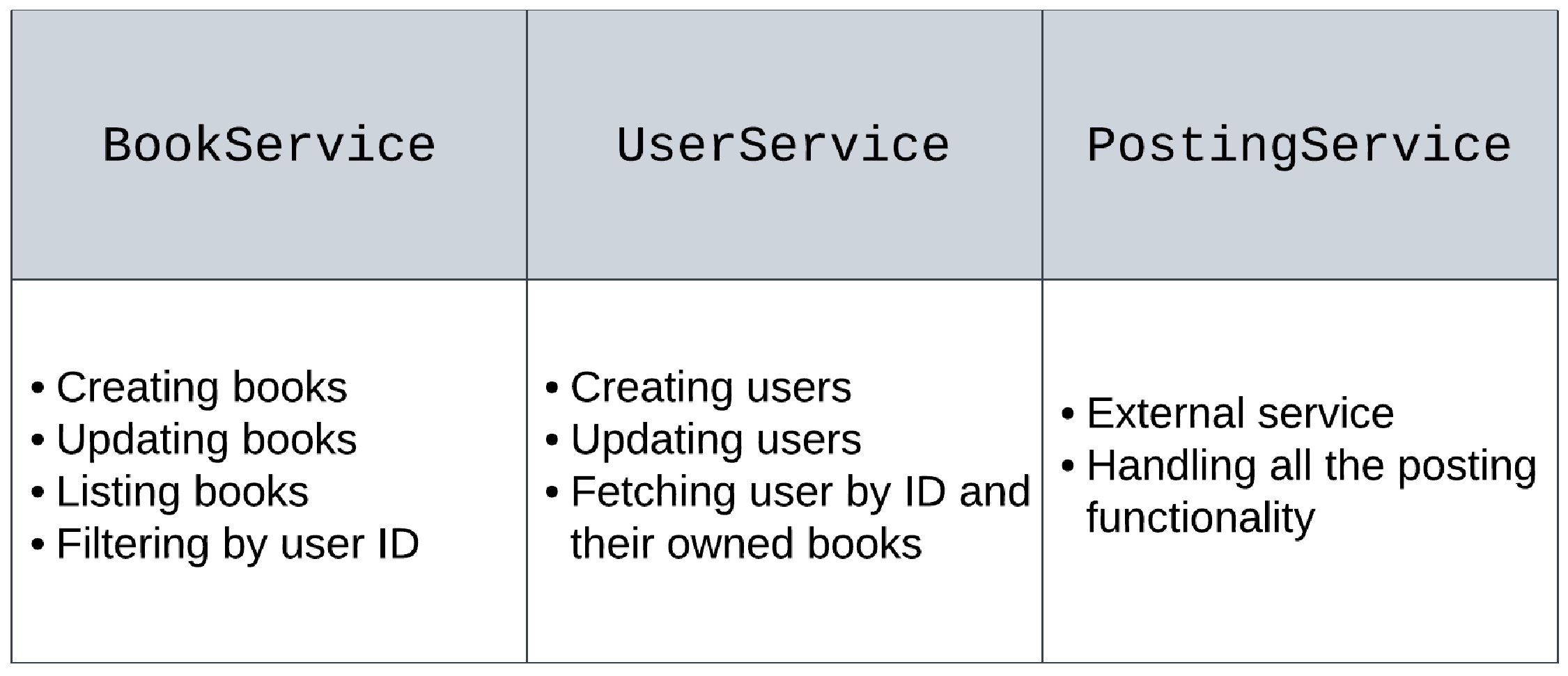
每个服务都有其独立的职责和专门化功能:
-
BookService 负责所有与书籍管理相关的功能。该服务实现了创建、更新、列出和过滤书籍的功能。由于该应用功能较为简单,书籍仅根据所有者的用户 ID 进行过滤,我们不打算实现书籍库存的搜索功能。
-
UserService 负责所有与用户管理相关的功能。该服务实现了创建和更新用户资料的功能,能够根据 ID 获取指定用户,并依赖 BookService 来接收与用户 ID 对应的所有书籍列表。
-
PostingService 是 BookSwap 应用的外部服务,负责书籍发布和交换的具体细节。在实现中,我们将使用一个模拟实现的 PostingService,这个服务并不是真实存在的,但我们在应用内使用一个内部存根来模拟调用外部服务。
|
什么是存根 (Stub)?
存根是另一个组件的具体实现。存根不使用模拟框架,因为它们是由实现代码使用的。存根使测试变得更简单,并允许我们在外部组件尚未构建或实现时继续构建代码。由于 Go 中接口的灵活性,存根实现可以很容易地替换为真实的实现。 |
如第 4 章《构建高效的测试套件》中所提到,BookSwap 当前使用映射 (maps) 来保存数据,并没有数据库或持久化存储。在本章中,我们将修改实现,改为使用 PostgreSQL 数据库。
用户旅程
在本章中,我们将重点关注 E2E 测试的实现。这些测试的目的是验证应用程序在典型用户旅程下的行为。因此,在编写任何 E2E 测试用例之前,确定典型的用户旅程或请求流是非常重要的。
|
什么是用户旅程?
用户旅程是用户为实现其目标而在应用程序中进行的一系列请求或操作。这些旅程通常会在生产环境中进行追踪,以获取用户如何使用服务的洞察。 |
图6.2 描绘了 BookSwap 应用程序中新用户的预期请求流程。
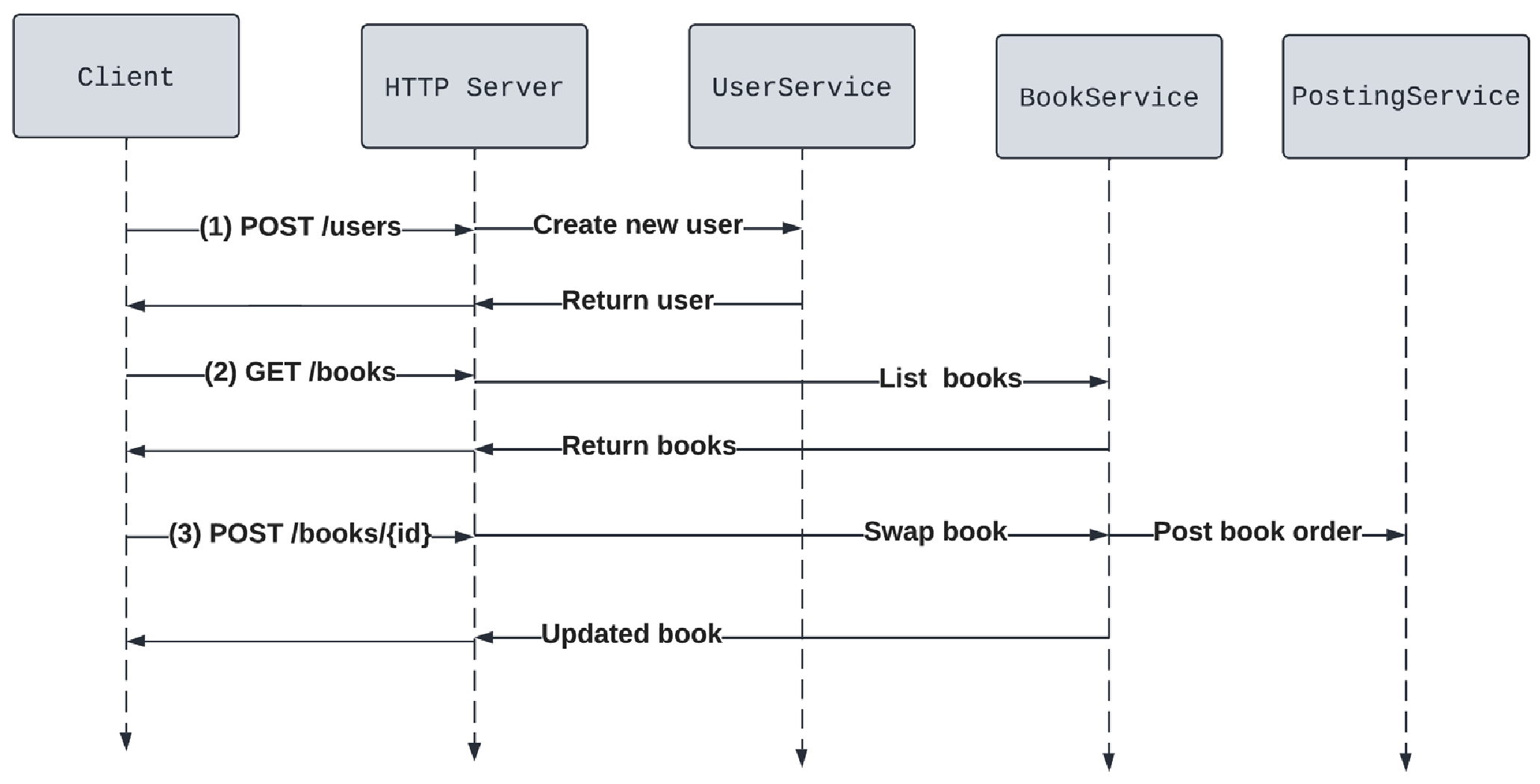
请求流程图为我们提供了对应用程序在用户旅程中需要哪些部分的洞察。新用户的预期使用流程如下:
-
创建新用户:用户需要创建一个新用户资料并获取其用户 ID。在真实应用中,这里是应用程序进行身份验证的部分。如前所述,我们将忽略应用程序中的密码和身份验证部分。相反,我们将用户 ID 视为一个秘密号码,由系统分配。新用户通过向
POST /users端点发送请求来创建,传递用户资料的详细信息作为 JSON 请求体。然后,UserService服务将创建该用户并返回给客户端。 -
列出可用书籍:用户随后可以获取书籍列表。这对应于浏览 BookSwap 应用程序的首页并查看哪些书籍可以交换。客户端发出
GET /books请求,BookService会获取书籍列表,并按可用状态进行筛选。 -
交换书籍:一旦用户完成了个人资料设置并确定了想要的书籍,他们可以决定交换一本书。客户端发出
POST /books/{id}请求,传递他们想要预订的书籍 ID。然后,他们将自己的用户ID作为URL参数传递,完成请求 URL 为POST /books/id?user={userId}。这也可以通过请求体来实现。
从图6.2中的主要组件来看,我们注意到有一个额外的组件——HTTP服务器。在 BookSwap 应用程序中,HTTP 服务器的实现由几个不同的部分组成:
-
一个自定义的 handler类型,其 handler 函数接收 HTTP 请求和响应写入器。在第 5 章《执行集成测试》中,我们看到了一个 handler 函数的例子。通常,handler 自定义类型可以访问它所需要的所有依赖,以完成其公开的操作。
-
每个 handler 函数都配置为服务于 HTTP 服务器的一个端点。我们使用
gorilla/mux库来处理请求的配置和路由,将其定向到相应的 handler 函数。你可以在 https://github.com/gorilla/mux 阅读更多关于gorilla/mux库的内容。 -
最后,一旦路由和 handlers 设置完成,我们启动服务器并配置其监听指定端口。这是通过 Go 标准库中的
net/http库完成的。
|
什么是 mux?
Mux 代表 HTTP 请求复用器。它提供了接收各种请求并根据 HTTP 方法、路径和查询值将它们路由到正确的 handler 函数的功能。尽管还有其他选项,但 |
图6.2 涵盖了新用户的成功旅程。E2E 测试应该涵盖多种场景,因此我们会绘制多个请求流程。然而,由于 E2E 测试的成本和运行时间较高,它们通常只覆盖基础案例或正常路径。
使用 Docker
到目前为止,我们使用 go run 命令运行应用程序,并使用 go test 命令进行测试。此方法的缺点是,我们必须在本地设置 Go 环境和任何依赖项,然后才能在本地构建和运行代码。在第 5 章《执行集成测试》中,我们介绍了 Docker 作为解决这些问题的方案。
|
什么是 Dockerfile?
|
我们需要为 BookSwap 应用程序创建一个自定义的 Dockerfile,因为它在 Docker Hub 镜像库中没有预定义的镜像。Dockerfile.book-swap.chapter06 文件包含了 BookSwap 的规范:
FROM golang:1.19-alpine
WORKDIR /app
COPY go.mod ./
COPY go.sum ./
COPY . .
RUN go mod download
RUN go build ./chapter06/cmd
EXPOSE ${BOOKSWAP_PORT}
CMD [ "./cmd" ]这个相对简单的文件展示了我们有效地将 Docker 与 Go 应用程序结合使用所需的所有基本知识:
-
FROM 语句表示此构建阶段的基础镜像。我们选择一个来自 Docker Hub 的镜像,该镜像包含我们需要的 Go 1.19 版本来运行我们的应用程序。在 Docker 术语中,alpine 镜像是轻量级的,基于 Linux BusyBox 发行版运行。
-
WORKDIR 语句创建并设置 Docker 容器的工作目录。之后的所有命令将在这个目录中执行。
-
接下来,COPY 语句将本地目录中的所有源文件复制到容器的工作目录中。请记住,容器是与底层本地目录隔离的,因此这些文件必须复制到容器中。
-
RUN 语句执行构建 Go 可执行文件所需的命令,首先下载其依赖项,然后指定包含应用程序入口点的目录。
Dockerfile与go.mod文件一起放在根目录中,因此我们需要显式地声明要从哪个章节的入口点进行构建。 -
EXPOSE 语句指示 Docker 容器监听指定端口的网络请求,端口由
BOOKSWAP_PORT环境变量指示。该变量对于 BookSwap 应用程序是必需的,因此在运行应用程序之前,请确保在终端会话中设置此变量。如何设置环境变量的指令会根据操作系统的不同而有所不同。如果您想使用默认设置,可以将BOOKSWAP_PORT环境变量设置为 3000。 -
最后,CMD 语句指定容器启动后应运行的命令。我们运行的是
go build步骤中的可执行文件。
这就是我们需要指定的内容,以便在任何运行 Docker 并具有互联网连接的环境中运行我们的应用程序!大多数 Docker 规范将使用这个简单的配方来编写和运行它们的自定义镜像。我们将在本章稍后看到此规范的实际应用。
持久存储
接下来,我们将对 BookSwap 应用程序进行更改,添加持久化存储,以便在应用程序关闭后保存状态。由于 SQL 数据库仍然是最流行的持久化存储解决方案,我们将在演示应用程序中使用 SQL 数据库。
|
SQL 数据库管理解决方案
有几种常见的 SQL 数据库解决方案,你可能已经熟悉它们。一些例子包括 |
我们将使用 PostgreSQL 数据库,这是一种开源的关系型数据库,广泛应用于生产环境中。它还在公共云提供商之间有很好的云支持,因此它是我们技术栈的自然选择。
你可以通过访问 PostgreSQL官网 下载并在本地安装它,按照适合你操作系统的安装说明进行安装。安装完成后,请记录下主机、端口、用户名和密码。你将需要这些信息来连接数据库并运行相关的指令。
图6.3 描述了我们应用程序所需的两个主要表:
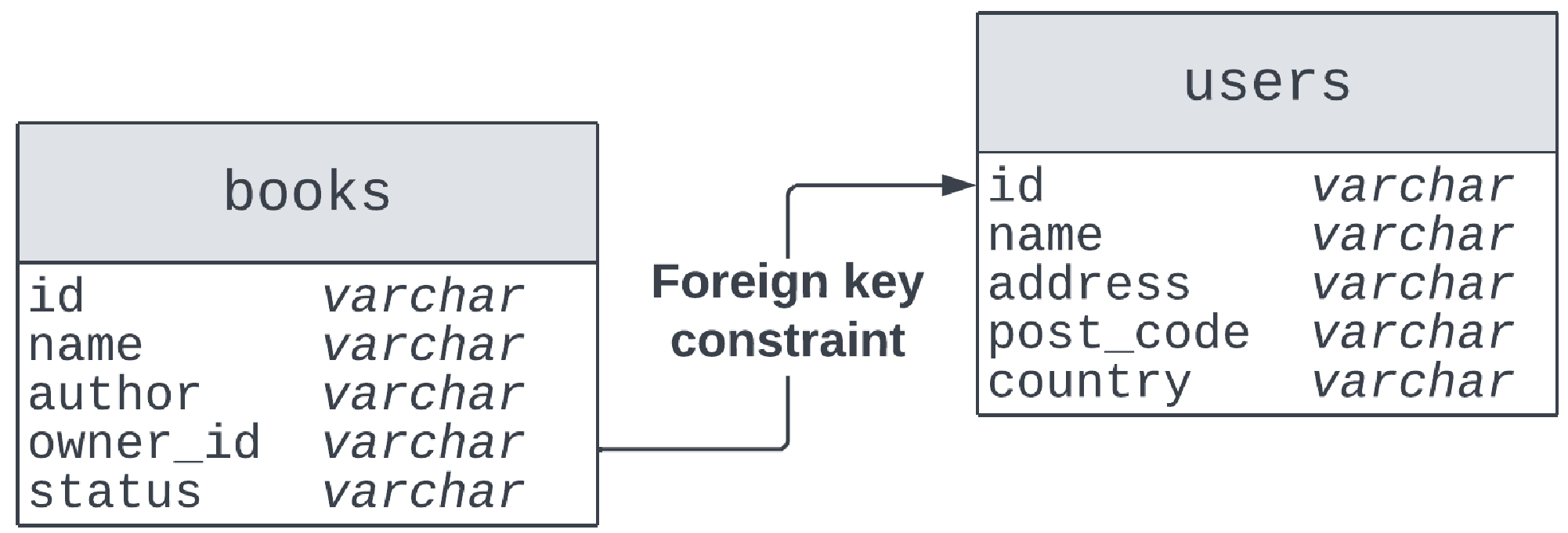
数据库包含两个表:books 和 users。每个表都有用于存储每种类型数据字段的列。由于书籍的 owner_id 值应该属于一个已存在的用户,因此这两个表之间在 user_id 字段上有一个外键约束。所有的列都是 varchar 类型,对应于字符串类型。
在启动应用程序之前,我们需要创建应用程序所需的表。然而,我们不想在源代码外部执行 SQL 指令,而是希望能够对其进行版本控制和审查。
golang-migrate项目( https://github.com/golang-migrate/migrate )允许我们编写迁移并在应用程序启动时运行它们。migrate CLI 工具可以通过在项目文档中的入门教程中按照安装步骤轻松安装到你的环境中。
安装完成后,我们可以为所需的两个表生成迁移:
$ migrate create -ext sql -dir chapter06/db/migrations -seq create_users_table
$ migrate create -ext sql -dir chapter06/db/migrations -seq create_books_tablemigrate CLI 工具会为每个表创建两个文件,分别是 .up.sql 和 .down.sql。这些文件的预期用途是:up 迁移在启动时创建表,down 迁移在应用程序关闭时删除表。这确保了表在每次运行应用程序后都被删除,并且始终在启动时被创建。然后,我们为每个表添加所需的列。以下是 users 表的配置:
BEGIN;
CREATE TABLE IF NOT EXISTS users
(
id VARCHAR (50) PRIMARY KEY,
name VARCHAR (50) NOT NULL,
// 其他列定义
);
COMMIT;该迁移会创建一个表(如果它不存在),并将 id 列标记为主键。该配置与图6.3 中定义的列匹配。down 迁移只有一行内容,用于删除表:
DROP TABLE IF EXISTS users;books 表的配置与此类似。最后,我们将迁移文件添加到 BookSwap 应用程序的入口点:
func main() {
// 其他初始化代码
postgresURL, ok := os.LookupEnv("BOOKSWAP_DB_URL")
if !ok {
log.Fatal("env variable BOOKSWAP_DB_URL not found")
}
m, err := migrate.New("file://chapter06/db/migrations", postgresURL)
if err != nil {
log.Fatal(err)
}
if err := m.Up(); err != nil {
log.Fatal(err)
}
defer func() {
m.Down()
}()
// 其他初始化代码
}与 migrate 库的交互需要我们在应用程序启动时添加三个额外的步骤:
-
创建 migrate 实例,并提供源 URL 和数据库 URL。如前所述,你的数据库实例的连接字符串将取决于你的 SQL 配置。数据库的格式类似于
postgres://user:password@host:port/database。BookSwap 应用程序需要一个名为BOOKSWAP_DB_URL的环境变量,其中包含此值。确保在启动应用程序之前设置该环境变量。 -
一旦创建了 migrate 实例,我们调用
Up()方法。此方法会查看当前的迁移版本,并应用所有在*.up.sql文件中定义的迁移。 -
如果我们想在应用程序关闭或发生错误时进行清理,我们可以延迟调用
Down()方法。该方法使用相同的版本管理机制,并运行*.down.sql文件中的内容。
golang-migrate 库和 CLI 工具使我们能够将数据库配置与源代码一起保存,便于版本控制和版本管理。
一旦我们的数据库和表创建完成,我们需要重构 UserService 和 BookService 实现,以便利用 SQL 表,而不是我们之前使用的内建映射(map)类型。
通常,工程师们会使用一个对象关系映射(ORM)库,这可以帮助我们在 Go 自定义类型和 PostgreSQL 数据库之间建立桥梁。
在 Go 生态系统中,有几个流行的 ORM 解决方案。其中一个最受欢迎的是 GORM( https://github.com/go-gorm/gorm ),它是一个开源的易于使用的 Go 库。这个库可以使我们更容易地与数据库交互,消除了在源代码中管理原始 SQL 的需求。
使用 GORM 的设置与我们使用 golang-migrate 时的过程非常相似:
func main() {
// 其他初始化代码
postgresURL, ok := os.LookupEnv("BOOKSWAP_DB_URL")
if !ok {
log.Fatal("$BOOKSWAP_DB_URL not found")
}
dbConn, err := gorm.Open(postgres.Open(postgresURL), &gorm.Config{})
if err != nil {
log.Fatal(err)
}
ps := db.NewPostingService()
b := db.NewBookService(dbConn, ps)
u := db.NewUserService(dbConn, b)
// 初始化代码继续
}首先,我们使用先前用于连接 golang-migrate 的数据库 URL 连接到数据库。一旦连接成功,它会返回一个 GORM 数据库包装器,类型为 *gorm.DB。
如果我们无法连接到数据库,应用程序将退出。我们还改变了 NewBookService 和 NewUserService 初始化函数的签名,现在它们接受初始化后的数据库会话。
BookService和UserService 之前保存到内建 map 的操作现在需要使用 GORM 数据库包装器的操作。例如,BookService 的 ListByUser 方法:
// ListByUser returns the list of books for a given user.
func (bs *BookService) ListByUser(userID string) ([]Book, error) {
var items []Book
if result := bs.DB.Where("owner_id = ?", userID).Find(&items); result.Error != nil {
return nil, result.Error
}
return items, nil
}该方法列出了所有拥有指定用户 ID 的书籍。使用 ORM 解决方案,我们可以在数据库上执行操作,服务通过调用方法构造正确的 SQL 查询。这样可以减少错误并避免在源代码中处理原始 SQL 字符串。
运行 BookSwap 应用
BookSwap 应用程序需要的最后一部分扩展是如何将其与数据库一起运行。如第五章《执行集成测试》中所述,docker-compose 工具用于管理多个 Docker 容器。现在我们有两个服务或部分组成:BookSwap 应用程序的服务器端和它的数据库。为了避免在每个环境中都需要设置数据库,我们还需要将数据库设置运行在 Docker 容器中。
docker-compose 命令通过 .yml 文件提供输入,这使得指定不同服务及其需求变得非常容易。我们在 docker-compose.book-swap.chapter06.yml 文件中的这个简单配置定义了 BookSwap 应用程序和它可以使用的 PostgreSQL 数据库:
version: '3'
services:
books:
build:
context: .
dockerfile: Dockerfile.book-swap.chapter06
ports:
- "${BOOKSWAP_PORT}:${BOOKSWAP_PORT}"
depends_on:
db:
condition: service_healthy
restart: on-failure
env_file:
- docker.env
db:
image: postgres:15.0-alpine
ports:
- "5432:5432"
expose:
- "5432"
env_file:
- docker.env
restart: on-failure这个相对简单的文件配置了我们需要的所有内容:
-
我们为所有启动的服务定义了一个
services块。在我们的案例中,我们将定义books服务和db服务,每个服务在各自的子块中配置。 -
books服务的配置如下:-
该服务从当前目录下的
Dockerfile文件构建。这就是我们在本章《使用 Docker》部分讨论的Dockerfile。 -
该服务在其网络上暴露由 BOOKSWAP_PORT 环境变量指定的端口。这将允许我们运行需要访问本地端口的测试。
-
该服务依赖于 db 服务的成功启动。Docker 引擎会在启动服务时考虑这一点,确保 db 服务先启动。
-
该服务使用
docker.env文件进行环境变量配置。该文件指定了我们所需的其他环境变量,如我们之前看到的 BOOKSWAP_DB_URL。
-
-
db 服务的配置如下:
-
该容器使用来自 Docker 仓库的现有镜像。在写作时,这是 PostgreSQL 镜像的最新版本,位于 https://hub.docker.com/_/postgres。
-
服务暴露
5432端口,这是 PostgreSQL 的常规端口。 -
根据该镜像的文档,它需要指定数据库的用户名、密码和数据库名等环境变量。所有这些变量将在我们提供给该服务的
docker.env文件中定义。
-
-
两个服务都有定义的重启策略。这意味着如果容器失败,Docker 会自动重启容器。
我们可以提供以下 docker.env 文件的示例配置,但您可以根据自己的需要编辑文件:
POSTGRES_USER=root
POSTGRES_PASSWORD=root
POSTGRES_DB=books
BOOKSWAP_DB_URL=postgres://root:root@db:5432/books?sslmode=disable
BOOKSWAP_PORT=3000这就是运行两个服务所需的所有配置,可以通过以下命令在项目根目录下运行:
docker-compose -f docker-compose.book-swap.chapter06.yml up --build这个文件包含了一个典型的配置,您可以在自己的项目中重用。此外,它使我们能够在不同环境中相同地启动和运行 BookSwap 应用程序。这个配置为我们提供了一个关键优势,即可以轻松地为整个应用程序启动测试环境。通过这些基础构件,让我们来看看如何利用这个关键优势来提高应用程序的测试覆盖率。