代码健壮性
在第 4 章《构建高效的测试套件》中,我们讨论了测试策略应涵盖的变量值类型。在这些值中,我们确定了涵盖参数的三种测试用例类型:
-
基本用例(Base Cases)
-
边缘用例(Edge Cases)
-
边界用例(Boundary Cases)
我们进一步确定了当多个输入变量提供边缘用例值时出现的 角落用例(Corner Cases)。我们应该编写涵盖提供给函数的输入的各种值的测试用例。
在微服务架构的世界中,我们通常无法控制提供给我们的服务和函数的值,因此我们编写的代码应在各种场景下保持稳定。为了实现这种稳定性,我们应该实现一个设计良好、经过充分测试的健壮代码库。
代码健壮性(Code Robustness) 是一个经常被忽视的质量,它可以帮助我们实现即使在代码更改和重构周期中也能保持稳定的代码。图10.1 展示了健壮代码的主要特征:
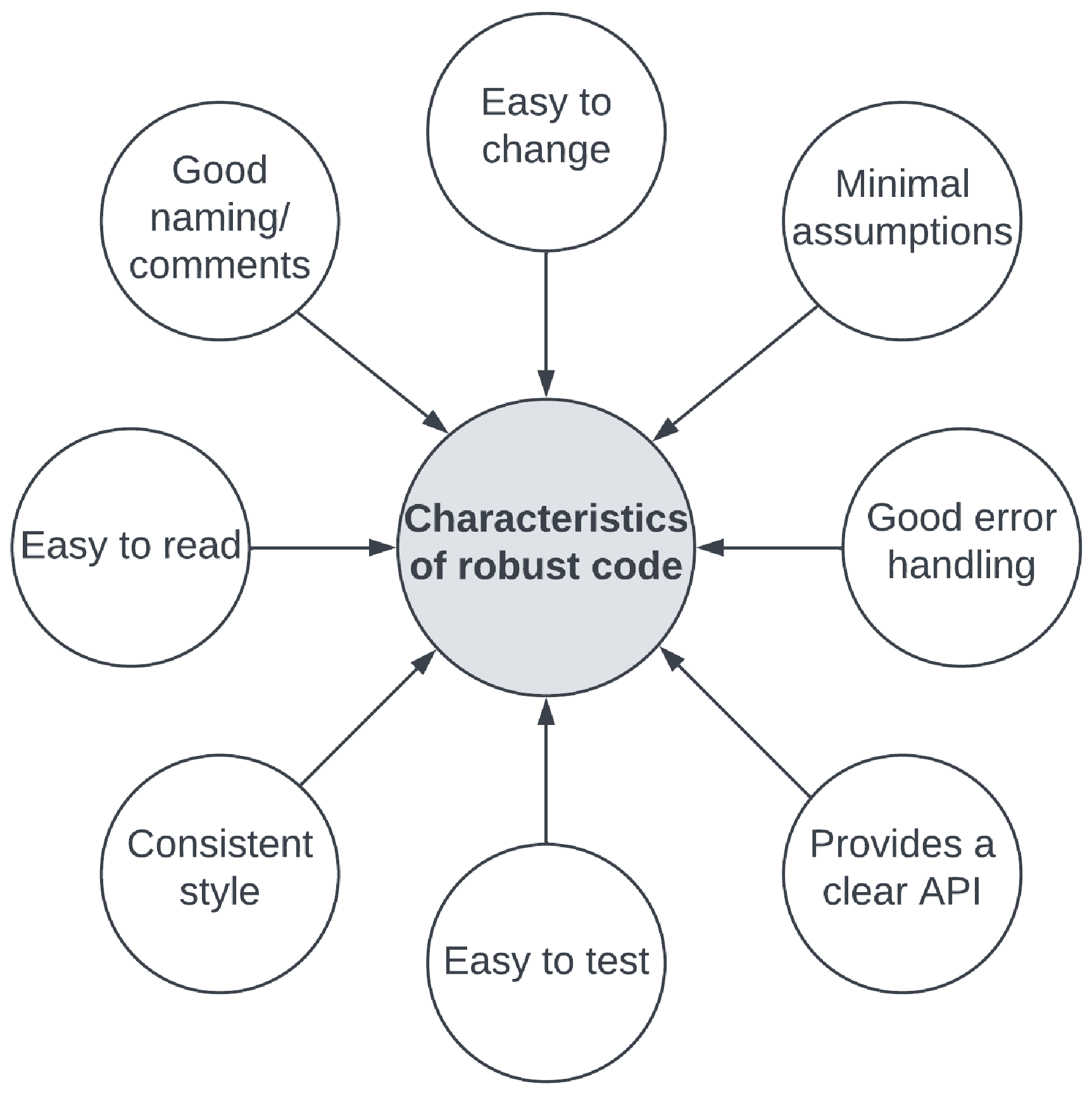
简而言之,健壮的代码由于以下特性而易于开发人员使用:
-
易于更改:健壮的代码能够处理各种外部因素,使其更容易重构和更改其依赖项。我们将看到其他特性将有助于使健壮的代码易于更改。
-
最小假设:健壮的代码对输入参数和可用资源的值做出最小假设。它应该检查任何不是内部生成的值,以确保其符合预期。
-
良好的错误处理:健壮的代码通过检查外部函数的错误、在发生错误时优雅地结束当前操作以及向调用者返回有意义的错误消息来实现良好的错误处理。
-
提供清晰的 API:健壮的代码为外部调用者提供易于阅读和理解的 API。它应该清楚地说明它期望的参数类型以及可能返回的错误。虽然文档是一个有用的补充,但我们不应该依赖它。健壮的代码应尽可能使用自定义类型和接口来利用编译器检查和类型安全。
-
易于测试:由于我们已经探讨的特性,健壮的代码易于测试。清晰的 API 使我们能够轻松设计测试用例、模拟所需的依赖项或为合同测试的实现制定合同。良好的错误处理(返回格式良好的错误)使我们能够编写简洁的断言来验证返回的错误消息。
-
一致的风格:健壮的代码使用一组一致的实践编写,包括命名标准和函数结构。这可以通过代码审查以及使用 Go 的格式化和 linting 功能来实现。您可以在官方文档中阅读有关如何使用
go vet命令实现此目的的更多信息: https://pkg.go.dev/cmd/vet 。 -
易于阅读:使用一致风格、处理错误并提供良好 API 的健壮代码减少了开发人员理解其行为所需的认知负荷。这使得它更容易阅读和搜索。
-
良好的命名/注释:文档是编写代码的另一个重要但经常被忽视的方面。变量命名应简短,但应代表其提供的功能。函数和类型应附有文档,清楚地说明其预期行为和提供的功能。您可以在官方博客上阅读有关如何编写 Go 注释的更多信息: https://tip.golang.org/doc/comment 。
在设计代码时考虑到健壮性将帮助我们创建稳定的系统和微服务架构。开发人员实现系统的常见方法之一是模仿 Unix 哲学 的原则,这些原则由其创建者和社区建立。它指出,健壮性源于透明性和简单性,这些原则与 Go 软件开发密切相关。查看这些原则,我们可以看到它们反映在图10.1 中我们探讨的特性中:
-
透明代码 易于阅读和理解。可读性通过一致的风格、良好的命名/注释和清晰的 API 定义得到帮助。
-
简单代码 也易于理解,但它也不复杂,并提供易于重用的明确定义的功能。这为我们的系统提供了模块化,使我们能够重用它们来解决各种问题和情况。然而,它也应该能够优雅地处理错误情况或未设计为适应的情况。
就像 Linux 一样,开源软件和库通常被认为比其专有对应物更健壮,因为它们有更广泛的受众可以发现和纠正错误。这是我们在整个 TDD 探索中仅探索开源库和工具的原因之一。
与健壮代码相反的是脆弱且容易出错的代码。这种类型的代码难以理解,即使使用我们在第 7 章《Go 中的重构》中探讨的策略,也可能难以重构。通常,代码重构涉及使用我们将在下一节中探讨的一些最佳实践来更改代码以增加代码的健壮性。
最佳实践
现在我们已经很好地掌握了健壮代码的特性,我们可以开始探讨在 Go 中实现它的一些最佳实践。我们可以通过查看一个脆弱的代码示例并探讨如何使其更健壮来开始我们的探索。
我们将编写一个函数,该函数以键排序顺序返回 Go 映射中包含的值。为了实现这一点,我们的函数将执行以下操作:
-
提取映射中包含的键。
-
根据给定的顺序参数对键进行排序。
-
提取与其键对应的值并将它们作为切片返回。
映射复习
Go 映射是键值对的动态、无序集合。可以使用唯一键访问和修改值。它们使用内置的 map 类型表示。映射的零值是 nil,因此使用 make 函数初始化它。自 Go 1.12 以来,fmt 包将按键排序顺序打印映射,但重要的是要记住集合是无序的。
基于这些知识,我们可以编写一个简单的函数来从映射中返回排序后的值:
var input map[int]string
func GetValues(dir string) []string {
var keys []int
for k := range input {
keys = append(keys, k)
}
if dir == "asc" {
sort.Ints(keys)
}
if dir == "desc" {
sort.Slice(keys, func(i, j int) bool {
return keys[i] > keys[j]
})
}
var vals []string
for _, k := range keys {
vals = append(vals, input[k])
}
return vals
}这个示例函数确实可以工作,返回排序后的值,但它有一些需要改进的地方,以减少其脆弱性:
-
全局变量:
input映射是一个全局变量,定义在函数范围之外。从签名中看不清楚函数和映射之间的依赖关系。 -
函数名称和签名:函数名称
GetValues没有给出任何排序功能的指示。也不清楚dir参数的用途及其允许的值。 -
nil 输入行为:如前所述,映射的零值是
nil。函数立即使用input映射,而不检查是否为nil。range操作符能够处理传递给它的nil映射而不会引发 panic,但在这种情况下,GetValues函数的预期行为尚不清楚。 -
输入验证:该函数允许两个值用于按升序或降序对键进行排序,如
dir参数所指定的那样。函数处理参数的值并执行相应的排序,但在另一种值的情况下,值将保持未排序状态。相反,如果函数的调用者收到一些指示,表明函数无法执行其预期工作,那将更好。 -
硬编码字符串:
dir参数的另一个问题是它针对函数内部定义的硬编码值进行验证。除非排序方向的值相同(包括字母大小写),否则函数将不匹配它。此外,除非检查实现代码,否则调用者不知道可接受的值是什么。 -
不一致的风格:该函数使用内置的
sort包以正确的顺序对键进行排序。这比从头实现排序算法要好得多,但两个排序案例使用不同的sort包函数实现。 -
内存分配:用于键和排序值的切片被声明为其零值,即使我们已经知道我们将排序的键和值的数量。在底层,随着值数量的增加,Go 运行时将不得不扩展底层数组并复制数据。
我们可以通过解决我们在原始实现中发现的问题来增加此函数的健壮性。此代码重构相对简单,因为此函数目前与任何其他代码隔离运行。修订后的版本如下:
type SortDirection int
const (
ASC SortDirection = iota
DESC
)
// GetSortedValues 返回给定映射的按键排序的值。
func GetSortedValues(input map[int]string, dir SortDirection) ([]string, error) {
if input == nil {
return nil, fmt.Errorf("cannot sort nil input map")
}
keys := make([]int, 0, len(input))
for k := range input {
keys = append(keys, k)
}
switch dir {
case ASC:
sort.Slice(keys, func(i, j int) bool {
return keys[i] < keys[j]
})
case DESC:
sort.Slice(keys, func(i, j int) bool {
return keys[i] > keys[j]
})
default:
return nil, fmt.Errorf("sort direction not recognized")
}
vals := make([]string, 0, len(input))
for _, k := range keys {
vals = append(vals, input[k])
}
return vals, nil
}我们对这个简单函数所做的更改解决了许多我们之前发现的问题:
-
我们引入了一个新的
SortDirection类型来替换dir参数的字符串值。此类型用于创建具有可接受排序方向值的枚举。 -
函数的签名已更改为将
input映射作为参数,从而消除了其对input映射全局变量的依赖。如果函数无法完成其操作,该函数还会返回第二个错误值。 -
或者,我们可以允许
GetSortedValues函数将排序函数作为参数,允许调用者实现其自定义排序函数。这将允许我们将整个排序逻辑移到函数外部,但也会给调用代码带来更多的灵活性。 -
如果
input映射为nil,函数将返回错误并停止执行。这是我们决定为函数实现的行为,向用户明确表示未初始化的映射被视为错误情况。 -
用于保存键和值的切片以与
input映射长度相同的容量初始化。向这些切片追加值不会导致底层数据的重新分配和复制。由于这是一个小示例函数,我们假设映射的大小足以加载到内存中,但在处理非常大的数据集时可能并非如此。 -
我们使用
switch语句检查新实现的SortDirection的值。该函数有两个可接受的升序和降序排序案例,并在引入另一个枚举值而没有正确实现的情况下返回错误。两个案例都使用sort.Slice函数实现排序。
这些更改增加了我们简单函数的健壮性,使其更易于使用且更直观。我们还看到,增加代码健壮性就是关于小的更改,这些更改加起来可以大大提高代码的稳定性和可读性。
一旦我们养成了编写代码时考虑到健壮性和稳定性的习惯,它就会成为一种习惯,将其构建到我们的解决方案中,从而消除了以后返回和重构它的需要。正如我们多次提到的,测试代码与实现代码一样重要。因此,它也应该在设计时考虑到健壮性。在接下来的部分中,我们将探讨两种编写验证边缘情况的健壮测试代码的策略。