行为驱动测试
我们现在已经学习了如何通过集成测试来补充单元测试,从而扩大了我们要测试的组件的范围。端到端测试具有最大的范围,因为它们测试整个系统。端到端测试通常与行为驱动开发(BDD)一起讨论,BDD 是 TDD 的一个分支,专注于根据用户需求编写可读性强的测试。
BDD 基础
BDD 从业者的第一步是建立不同利益相关者之间的共享词汇:业务相关者、领域专家和其他各个工程职能。基于这种共享且易于理解的词汇,用户需求会转化为用户验收测试(UAT)。这些测试是端到端测试,确保所有新的发布都涵盖了系统需求。
测试通常采用 Given-When-Then 的结构,使用之前由业务方建立的共享词汇和业务语言。我们之前实现的 GET / 端点的集成测试的 BDD 表述如下:
-
故事:查看书籍列表
-
Given 一个用户
-
When 用户访问
GET /根端点 -
Then 返回可用书籍的列表给用户
该测试规格读起来就像普通英语,并且明确了测试用例的主要方面:
-
测试用例的主要行为者是谁
-
他们的预期行为是什么
-
用户将从执行的操作中获得什么
请注意,测试用例没有指定应用程序的任何实现细节,而是专注于应用程序的行为。测试用例将应用程序视为黑箱。这种简洁性是 BDD 的优势,测试规格不仅仅是工程师和测试专家能够编写的内容。
|
BDD 是弥合差距的工具
BDD 强调共享语言和易读的测试,确保了技术和非技术利益相关者之间的差距被弥合。这避免了误解和延迟,确保系统的预期行为能够及时实现。 |
图 5.5 突出了使用 BDD 编写测试的一些优点和缺点:
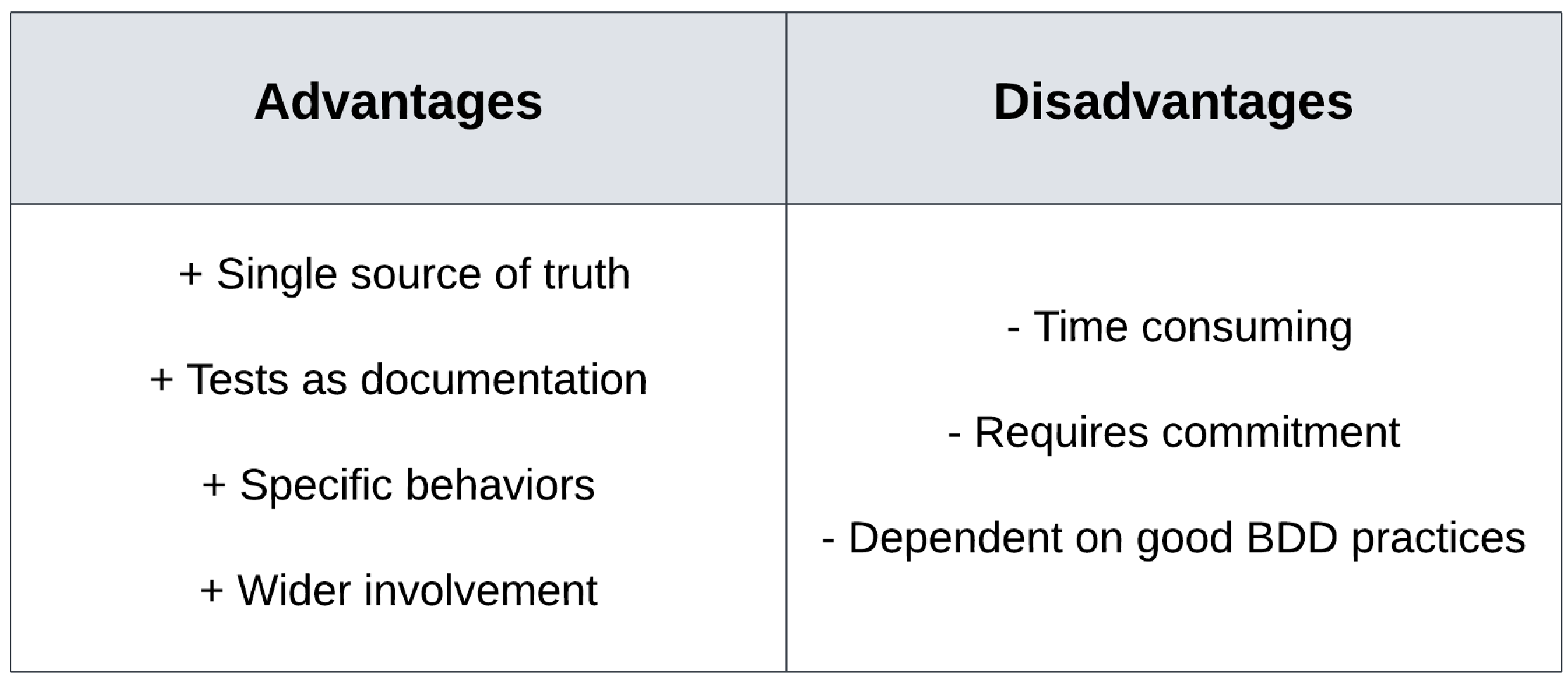
BDD 的优点:
-
单一的真实来源:BDD 的最大优势是它允许团队拥有应用程序预期行为的单一真实来源。此外,团队还可以使用统一的词汇表达这种行为。
-
测试即文档:虽然单元测试也可以作为应用程序的文档,BDD 测试更容易阅读和理解,因为它们专注于可读性。
-
特定行为:通过 Given-When-Then 的结构,BDD 测试鼓励为特定的行为编写测试用例。这有助于明确项目开始时较大或潜在模糊的用户需求。
-
更广泛的参与:团队或业务中的任何人都可以参与编写这些测试的规范,从而更容易在早期发现任何漏洞或功能上的疏忽。
BDD 的缺点:
-
耗时:在项目开始时,汇集多个利益相关者以制定测试用例可能会耗费大量时间。此外,在项目生命周期内维护这些测试也可能会非常耗时。
-
需要承诺:不同的利益相关者需要承诺在项目初期参与制定和讨论这些测试用例的工作。
-
依赖良好的 BDD 实践:除非与正确的利益相关者一起正确指定,否则 BDD 测试可能会变得模糊并且难以实施。因此,测试的成功规范依赖于业务中良好的 BDD 实践。
现在我们了解了 BDD 测试的一些优点以及如何编写它们,我们可以将注意力转向在 Go 中实现它们。
使用 Ginkgo 实现 BDD 测试
在第3章《模拟与断言框架》中,我们学习了如何使用 testify 开源测试库创建模拟对象并编写断言,这使我们能够创建简化的单元测试并轻松创建模拟。然而,创建更具表达性的 BDD 风格的测试需要一个更强大的测试库。ginkgo( https://github.com/onsi/ginkgo )项目就是在 2013 年成立的,旨在满足这一需求。它是一个基于 Go 的测试包构建的测试框架,设计目的是帮助我们编写具有表达性的 BDD 测试。它与 gomega( https://github.com/onsi/gomega )匹配器库一起使用,后者提供了我们可以在测试中使用的断言匹配器。
这个框架在社区中得到了混合的支持,因为它将 Ruby 风格的测试写法引入到 Go 中。然而,它目前是编写 BDD 风格测试的默认方式,并且在我们的 TDD 之旅中占据重要地位。
Ginkgo 支持 Go 模块,可以像安装 testify 一样轻松安装,使用 go install 命令:
$ go get github.com/onsi/ginkgo/v2@v2.4.0
$ go install -mod=mod github.com/onsi/ginkgo/v2/ginkgo@v2.4.0|
Ginkgo 安装位置
安装命令会将 ginkgo CLI 安装到 |
go get 命令将获取 gomega 断言库:
$ go get github.com/onsi/gomega/...Ginkgo 测试与常规单元测试一样也存储在 _test.go 文件中,但它们被组织在测试套件中。套件类似于我们之前实现的表格测试,其中我们按功能和场景对测试进行分组。
使用 ginkgo bootstrap 命令在当前目录下生成套件:
$ cd chapter05/handlers && ginkgo bootstrap
Generating ginkgo test suite bootstrap for handlers in: handlers_suite_test.go该文件的命名根据当前目录中声明的包来命名。生成的文件包含包声明和一些套件声明的必要代码。请注意,如果套件已存在,该命令将会失败。
bootstrap 命令是一个便捷的工具,用于生成这些样板代码,并确保所有测试文件在所有项目中具有相同的基本结构。它还确保我们套件的命名是一致的,因此它是一个强大的标准化工具。
|
测试术语
Ginkgo 使用与 Ruby 社区相同的术语。一个 套件(suite) 是一组测试,它们都验证同一个包。一个测试被称为 spec。我们将继续使用相同的术语来指代 Ginkgo 测试。 |
生成的 chapter05/handlers/handlers_suite_test.go 文件包含如下代码:
package handlers_test
import (
"testing"
. "github.com/onsi/ginkgo/v2"
. "github.com/onsi/gomega"
)
func TestHandlers(t *testing.T) {
RegisterFailHandler(Fail)
RunSpecs(t, "Handlers Suite")
}此文件包含与 Ginkgo 运行器交互所需的信息:
-
测试套件文件声明在与当前目录相对应的
handlers_test包中。单独的_test包确保我们只测试源包的已导出功能。这对于编写仅断言 API 外部行为的集成测试至关重要。 -
ginkgo和gomega库通过点操作符(.)导入,这允许我们访问测试和断言功能,而无需每次都使用包名进行限定。可以禁用此操作,但 BDD 社区不建议这么做,因为测试应该尽可能自然地读取。 -
测试的签名与预期一致。测试签名接受一个
*testing.T类型的参数,这是我们生成的套件的入口点。 -
测试中包含两个对
Ginkgo测试运行器的调用。我们不会深入讨论这些函数的内部实现,但由于所有测试库都是开源的,您可以自己查找它们的功能。RunSpecs调用指示测试运行器开始运行套件并执行所有现有的测试。
该套件仅作为入口点,供 specs 开始执行,这些 specs 通常定义在单独的测试文件中。
我们在 chapter05/handlers/handlers_index_test.go 文件中定义了 Ginkgo 等价的 Index 端点集成测试,如我们之前在“实现集成测试”部分看到的那样:
var _ = Describe("Handlers integration", func() {
var svr *httptest.Server
var book db.Book
BeforeEach(func() {
book = db.Book{
ID: uuid.New().String(),
Name: "My first integration test",
Status: db.Available.String(),
}
bs := db.NewBookService([]db.Book{book}, nil)
ha := handlers.NewHandler(bs, nil)
svr = httptest.NewServer(http.HandlerFunc(ha.Index))
})
AfterEach(func() {
svr.Close()
})
Describe("Index endpoint", func() {
Context("with one existing book", func() {
It("should return book", func() {
r, err := http.Get(svr.URL)
Expect(err).To(BeNil())
Expect(r.StatusCode).To(Equal(http.StatusOK))
// … 继续断言
})
})
})
})这个 Ginkgo 版本的 Index 集成测试看起来与我们习惯的代码有很大的不同。它专注于以易读的规范树(spec tree)设置测试的各个方面:
-
我们使用闭包来设置规范层次结构。
Describe函数允许我们创建容器节点,规范必须从顶层Describe节点开始。 -
BeforeEach函数创建在每个测试之前运行的设置节点。它们用于提取公共设置,使测试更加简化。 -
AfterEach函数创建在测试之后运行的清理节点。它们确保在测试运行后清理重要资源。 -
我们可以根据需要在顶层节点内进一步定义容器节点,以组织规范和它们的场景。
-
Context函数是Describe的别名,允许我们为规范添加额外的信息,帮助人们理解它们。它也创建容器节点,但可以用来组织信息。 -
It函数允许我们定义主题节点。主题节点包含待测对象的断言,不能包含任何其他嵌套节点。 -
断言写在主题节点中,并使用 gomega 断言库。这些断言可以像 testify 的断言一样嵌套,但它们采用人类可读的形式。所有断言必须以
Expect函数开始,它会包裹一个实际值。
图 5.6 显示了 spec 树结构的可视化表示:
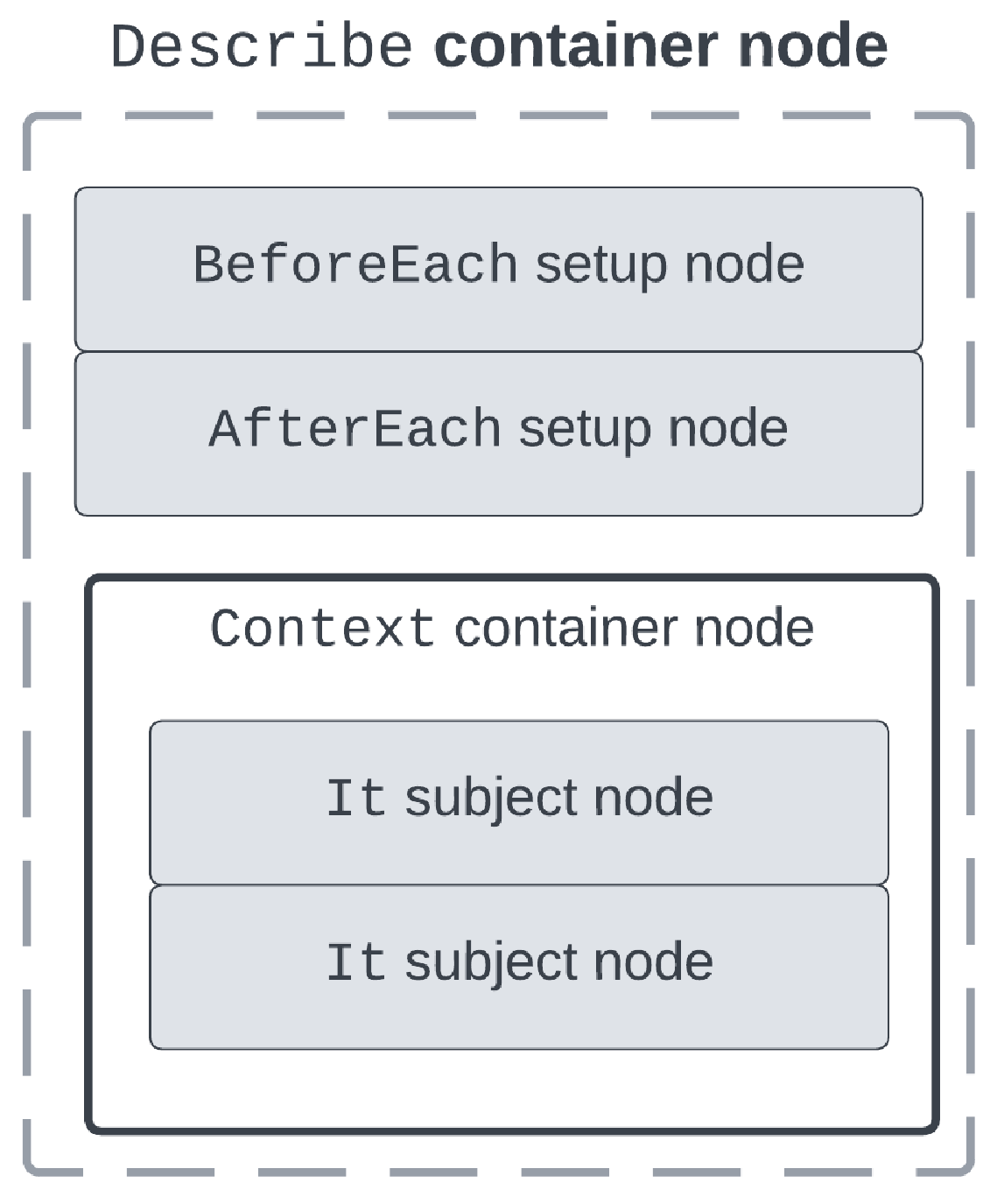
所有测试都从一个 Describe 容器节点开始。这个顶级节点可以包含多个 BeforeEach 设置节点、多个 AfterEach 节点、其他 Context 容器节点以及多个 It 主题节点。正如我们在处理程序集成测试中看到的,这些节点被安排成一个层次结构,反映了我们的测试场景。
|
嵌套规则
spec 树由嵌套的容器节点组成。设置节点可以嵌套在其中。与延迟函数的行为一样,最内层的函数将首先执行,然后其他函数将按相同方式向外执行。 |
一旦我们生成了测试套件并填充了测试规范,就可以使用 ginkgo 命令来运行它:
$ ginkgo -v ./chapter05/handlers
Running Suite: Handlers Suite
============================================================
Handlers integration Index endpoint with one existing book
should return book
SUCCESS! -- 1 Passed | 0 Failed | 0 Pending | 0 Skipped
PASS与我们之前使用的 go test 命令一样,ginkgo 也支持 ./… 运算符,它会遍历子目录并查找要运行的测试套件。
从输出中我们可以看到,容器节点和主题节点用于构造有意义的测试套件名称。Ginkgo 允许我们构建具有有意义输出的测试集合。我们将在未来的章节中继续探索它。