并发问题
在 Go 中编写并发代码既优雅又简单。然而,它确实使我们的代码更加复杂。开发人员需要熟悉并发机制的行为,才能理解他们正在阅读的代码。此外,由于时间在 goroutine 的行为中起着至关重要的作用,我们可能很难重现潜在的 bug。在本节中,我们将探讨三种常见的并发问题。在深入探讨每个示例时,我们还将有机会理解 Go 并发机制的行为。
数据竞争
数据竞争(Data Race) 是最常见的并发问题。当多个 goroutine 同时访问和修改相同的共享资源时,就会发生此问题。这是我们应该避免在 goroutine 之间共享状态的原因之一,更倾向于使用通道在 goroutine 之间共享信息。
我们修改了之前的问候示例,将格式化的问候语保存到一个切片中,而不是立即将问候语打印到终端:
const workerCount = 3
var greetings []string
func greet(id int, wg *sync.WaitGroup) {
defer wg.Done()
g := fmt.Sprintf("Hello, friend! I'm Goroutine %d.", id)
greetings = append(greetings, g)
}
func main() {
var wg sync.WaitGroup
wg.Add(workerCount)
for i := 0; i < workerCount; i++ {
go greet(i, &wg)
}
wg.Wait()
for _, g := range greetings {
fmt.Println(g)
}
fmt.Println("Goodbye, friend!")
}乍一看,代码示例并没有太大修改:
-
在程序顶部,我们声明了
greetings字符串切片,用于保存问候语。我们还将workerCount常量声明为 3,这是我们运行的goroutine数量。 -
greet函数接收两个参数:goroutine ID 和一个指向sync.WaitGroup的指针。在函数末尾,我们将格式化的问候语g追加到greetings切片中。 -
在
main函数中,我们创建了sync.WaitGroup并在多个 goroutine 中运行greet函数。WaitGroup用于确保主 goroutine 等待所有工作goroutine完成。在main函数的末尾,一旦所有greetgoroutine 完成,我们遍历greetings切片并将每个条目打印到终端。
由于 main 函数等待所有 goroutine 完成,我们期望所有 goroutine 都能正确保存其问候语。由于 workerCount 等于 3,我们期望在终端打印三行。让我们以通常的方式运行此程序并查看其输出:
$ go run chapter09/concurrency/data-races/main.go
Hello, friend! I'm Goroutine 2.
Hello, friend! I'm Goroutine 1.
Goodbye, friend!从输出中,我们看到只有两个 goroutine 的结果被记录。我们可以看到,我们所做的代码更改出了问题。
此代码示例存在数据竞争。图9.6 描绘了此示例中发生的事件序列:
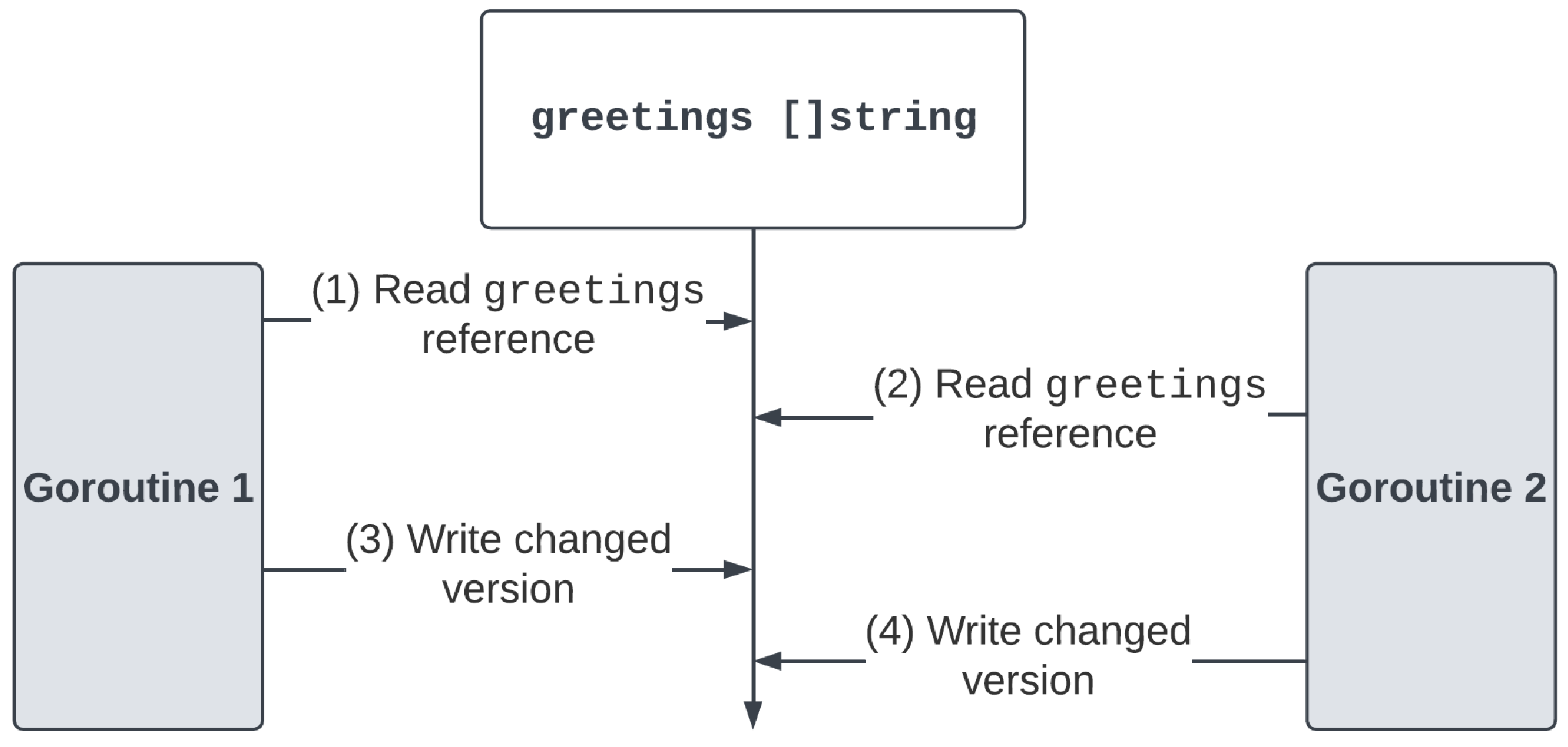
当多个 goroutine 尝试将其结果追加到 greetings 切片时,它们实际上在底层执行了几个操作:
-
(1) 读取
greetings引用:Goroutine 1 通过读取greetings切片的引用来开始其执行。它将基于此值完成其操作。 -
(2) 读取
greetings引用:稍后,Goroutine 2 通过读取greetings切片的引用来开始其执行。这可能与 Goroutine 1 读取的值相同,也可能不同。 -
(3) 写入更改后的版本:在执行过程中,Goroutine 1 准备好写入其更改并完成执行。如果底层数组中有空间,则将元素追加到其中。否则,将创建一个更大的新数组,并将元素复制到其中。创建一个新的切片,引用更新后的底层数组。
-
(4) 写入更改后的版本:最后,Goroutine 2 也准备好写入其更改。然而,它并不知道 Goroutine 1 到目前为止所做的任何更改。它仍然基于在步骤 2 中读取的引用工作。Goroutine 2 写入其更改,覆盖 Goroutine 1 在步骤 3 中保存的所有工作。
由于 greetings 切片没有受到锁的保护,goroutine 可以在此过程中的任何时刻被中断。随着这些更改的交错,goroutine 最终可能会覆盖彼此的更改,导致不一致的结果。根据时间的不同,您的输出可能与前面的结果不同。同样,根据时间的不同,我们可能会看到所有问候语都打印到终端,并假设程序运行正常,或者我们可能会在测试运行期间看到不一致的行为。数据竞争是并发世界中常见的问题,它们可能很难发现和复现。
死锁
死锁(Deadlock) 是另一个常见的并发问题。当 goroutine 被阻塞等待一个永远不会可用的资源时,就会发生此问题。goroutine 将永远无法继续执行。Go 运行时会在程序被阻塞时检测到并触发 panic,关闭并清理资源。
为了修复上一节中的数据竞争,我们将修改代码以使用通道,一次只允许一个 goroutine 追加到 greetings 切片:
var greetings []string
const workerCount = 3
func greet(id int, ch chan struct{}, wg *sync.WaitGroup) {
defer wg.Done()
g := fmt.Sprintf("Hello, friend! I'm Goroutine %d.", id)
<-ch
greetings = append(greetings, g)
ch <- struct{}{}
}
func main() {
ch := make(chan struct{})
var wg sync.WaitGroup
wg.Add(workerCount)
for i := 0; i < workerCount; i++ {
go greet(i, ch, &wg)
}
ch <- struct{}{}
wg.Wait()
for _, g := range greetings {
fmt.Println(g)
}
fmt.Println("Goodbye, friend!")
}乍一看,这个示例似乎是合理的:
-
greet函数接收三个参数:一个 ID、一个通道和一个指向WaitGroup的指针。在函数内部,我们从通道读取,将问候语追加到greetings切片中,然后写入通道。 -
在
main函数内部,我们初始化了通道和WaitGroup。这些是我们的 goroutine 将使用的同步机制。 -
然后,我们编写一个
for循环,它将启动与workerCount(即 3)一样多的运行greet函数的 goroutine。 -
在循环之后,我们向通道发送一个值以启动第一个 goroutine。它还向工作 goroutine 发出信号,表明主
goroutine已准备好处理它们的结果。
这似乎是一个合理的技术解决方案,可以确保我们的数据竞争问题得到修复。让我们以通常的方式运行此程序并查看其输出:
$ go run chapter09/concurrency/deadlock/main.go
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [semacquire]:
sync.(*WaitGroup).Wait(0x0?)
/usr/local/go/src/sync/waitgroup.go:139 +0x52
main.main()
.../chapter09/deadlock/main.go:28 +0xd5
goroutine 19 [chan send]:
main.greet(0x0?, 0x0?, 0x0?)
.../chapter09/deadlock/main.go:17 +0x165
created by main.main
.../chapter09/deadlock/main.go:25 +0x4f
exit status 2该程序存在死锁,Go 运行时检测到了这一点。堆栈跟踪表明两个 goroutine 被阻塞:
-
主
goroutine无法完成WaitGroup的Wait方法。 -
其中一个工作
goroutine无法完成其通道发送操作。
这种死锁是由通道操作的同步性质引起的。最后一个工作 goroutine 尝试向通道发送信号以表明其工作已完成,但通道上没有剩余的接收者。因此,工作 goroutine 保持阻塞状态,WaitGroup 永远不会解除阻塞,整个程序冻结。
导致 goroutine 被阻塞的常见原因是等待完成通道操作或等待 sync 包中的某个锁变为可用。理解我们使用的并发机制的行为是避免问题和 bug 的最佳工具。
缓冲通道
默认情况下,通道是 无缓冲的(unbuffered),这意味着它们没有存储或缓冲值的能力。这就是为什么我们到目前为止看到的所有通道操作都是同步的。然而,这对于以不同速度运行的发送者和接收者来说可能是一种限制。一种特殊类型的通道解决了这一限制。
缓冲通道(Buffered Channels) 具有在没有接收者的情况下接受预定义、有限数量的值的能力。这使我们能够处理有限数量的异步操作。通道的容量在初始化时通过 make 函数的可选参数预定义:
ch := make(chan Type, capacity)容量是一个整数,对于无缓冲通道,其默认值为 0。此参数定义了将保存通道值的底层数组的大小。
图9.7 描绘了两种类型通道上的发送和接收操作:
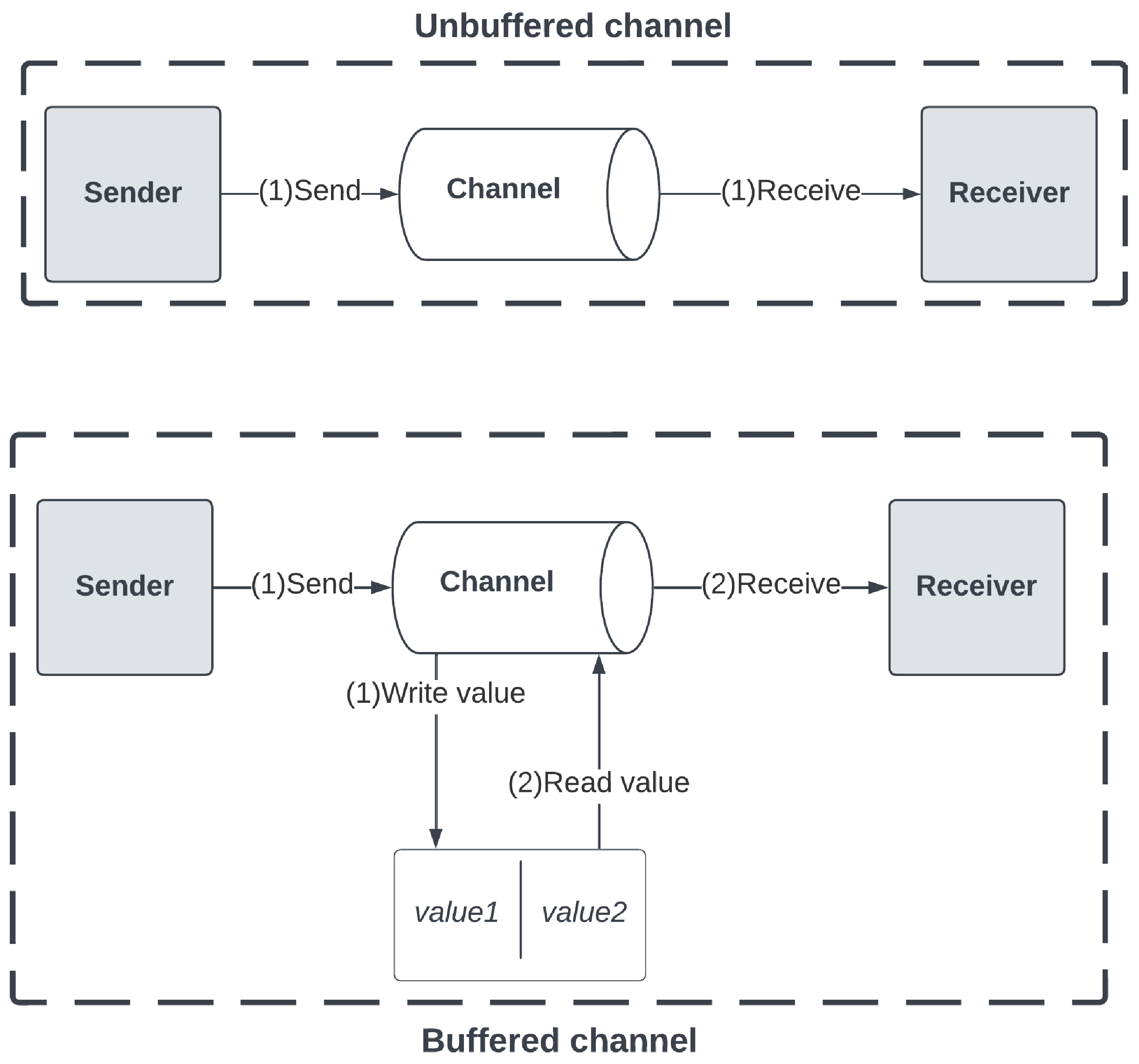
操作的时间安排是两种通道之间的关键区别:
-
在无缓冲通道上,发送和接收操作同时发生。通道不存储任何值,只有在发送者和接收者都可用时才能完成操作。
-
在缓冲通道上,通道具有有限的容量缓冲区,可以在有能力的情况下保存值。发送和接收操作在不同的时间完成,因为通道将发送者的值保存在其缓冲区中。一旦接收者准备好,它可以从缓冲区读取可用值并将其传递给接收者。
-
当缓冲区达到容量时,缓冲通道将阻塞发送操作,表现得像无缓冲通道,直到接收者开始清空缓冲区。
我们可以利用缓冲通道让 greet 工作 goroutine 在写入值后立即完成,而不是等待主 goroutine 准备好接收它们的值:
const workerCount = 3
func greet(id int, ch chan string) {
g := fmt.Sprintf("Hello, friend! I'm Goroutine %d.", id)
ch <- g
fmt.Printf("Goroutine %d completed.\n", id)
}
func main() {
ch := make(chan string, workerCount)
for i := 0; i < workerCount; i++ {
go greet(i, ch)
}
fmt.Println(<-ch)
fmt.Println(<-ch)
fmt.Println("Goodbye, friend!")
}这个简单的示例演示了缓冲通道的用法:
-
greet函数再次接收两个参数:一个 ID 和一个字符串数据类型的通道。缓冲通道的类型与无缓冲通道相同,因此greet函数无法检测它使用的是缓冲通道还是无缓冲通道。 -
在
greet函数内部,我们格式化问候语并将其发送到通道。 -
在
main函数的顶部,我们通过传递workerCount作为通道的容量来初始化缓冲通道。然后,我们在for循环中启动greet函数,传递索引和通道作为函数的参数。 -
最后,我们从通道接收并打印两个值,然后终止程序。
我们以通常的方式运行程序以查看其行为:
$ go run chapter09/concurrency/buffered-channels/main.go
Goroutine 1 completed.
Goroutine 2 completed.
Goroutine 0 completed.
Hello, friend! I'm Goroutine 2.
Hello, friend! I'm Goroutine 1.
Goodbye, friend!程序按预期运行:工作 goroutine 立即完成,主 goroutine 打印两条消息到终端,然后成功完成。然而,这个程序确实存在一个问题。第三个 greet goroutine 的问候语成功发送到通道,但从未被接收。从 greet goroutine 的角度来看,它的结果已正确发送和处理,而实际上主 goroutine 从未处理过它。
由于接收者只准备好两次,我们的程序存在资源泄漏,即资源未正确释放。虽然 Go 垃圾收集器会收集未使用的内存,但我们应该避免编写此类代码,因为如果大规模执行这些操作,可能会导致问题和 bug。
缓冲通道具有有限的容量,以确保避免此类资源泄漏。它们通常用于实现 工作池(worker pool) 并发模式,即一组等待重复处理任务的 goroutine 的实现。
到目前为止,我们通过研究代码示例并推理我们能够重现的问题,讨论了并发机制的行为和问题。在下一节中,我们将讨论如何使用 Go 工具来检测程序中的并发问题。