并发的循环
本节中,我们会探索一些用来在并行时循环迭代的常见并发模型。我们会探究从全尺寸图片生成一些缩略图的问题。gopl.io/ch8/thumbnail 包提供了 ImageFile 函数来帮我们拉伸图片。我们不会说明这个函数的实现,只需要从 gopl.io 下载它。
Unresolved include directive in modules/ROOT/pages/ch8/ch8-05.adoc - include::example$/ch8/thumbnail/thumbnail.go[]下面的程序会循环迭代一些图片文件名,并为每一张图片生成一个缩略图:
Unresolved include directive in modules/ROOT/pages/ch8/ch8-05.adoc - include::example$/ch8/thumbnail/thumbnail_test.go[]显然我们处理文件的顺序无关紧要,因为每一个图片的拉伸操作和其它图片的处理操作都是彼此独立的。像这种子问题都是完全彼此独立的问题被叫做易并行问题(译注:embarrassingly parallel,直译的话更像是尴尬并行)。易并行问题是最容易被实现成并行的一类问题(废话),并且最能够享受到并发带来的好处,能够随着并行的规模线性地扩展。
下面让我们并行地执行这些操作,从而将文件 IO 的延迟隐藏掉,并用上多核 cpu 的计算能力来拉伸图像。我们的第一个并发程序只是使用了一个 go 关键字。这里我们先忽略掉错误,之后再进行处理。
Unresolved include directive in modules/ROOT/pages/ch8/ch8-05.adoc - include::example$/ch8/thumbnail/thumbnail_test.go[]这个版本运行的实在有点太快,实际上,由于它比最早的版本使用的时间要短得多,即使当文件名的 slice 中只包含有一个元素。这就有点奇怪了,如果程序没有并发执行的话,那为什么一个并发的版本还是要快呢?答案其实是 makeThumbnails 在它还没有完成工作之前就已经返回了。它启动了所有的 goroutine,每一个文件名对应一个,但没有等待它们一直到执行完毕。
没有什么直接的办法能够等待 goroutine 完成,但是我们可以改变 goroutine 里的代码让其能够将完成情况报告给外部的 goroutine 知晓,使用的方式是向一个共享的 channel 中发送事件。因为我们已经确切地知道有 len(filenames) 个内部 goroutine,所以外部的 goroutine 只需要在返回之前对这些事件计数。
Unresolved include directive in modules/ROOT/pages/ch8/ch8-05.adoc - include::example$/ch8/thumbnail/thumbnail_test.go[]注意我们将 f 的值作为一个显式的变量传给了函数,而不是在循环的闭包中声明:
for _, f := range filenames {
go func() {
thumbnail.ImageFile(f) // NOTE: incorrect!
// ...
}()
}回忆一下之前在5.6.1节中,匿名函数中的循环变量快照问题。上面这个单独的变量 f 是被所有的匿名函数值所共享,且会被连续的循环迭代所更新的。当新的 goroutine 开始执行字面函数时,for 循环可能已经更新了 f 并且开始了另一轮的迭代或者(更有可能的)已经结束了整个循环,所以当这些 goroutine 开始读取 f 的值时,它们所看到的值已经是 slice 的最后一个元素了。显式地添加这个参数,我们能够确保使用的 f 是当 go 语句执行时的“当前”那个 f 。
如果我们想要从每一个 worker goroutine 往主 goroutine 中返回值时该怎么办呢?当我们调用 thumbnail.ImageFile 创建文件失败的时候,它会返回一个错误。下一个版本的 makeThumbnails 会返回其在做拉伸操作时接收到的第一个错误:
Unresolved include directive in modules/ROOT/pages/ch8/ch8-05.adoc - include::example$/ch8/thumbnail/thumbnail_test.go[]这个程序有一个微妙的 bug。当它遇到第一个非 nil 的 error 时会直接将 error 返回到调用方,使得没有一个 goroutine 去排空 errors channel。这样剩下的 worker goroutine 在向这个 channel 中发送值时,都会永远地阻塞下去,并且永远都不会退出。这种情况叫做 goroutine 泄露(§8.4.4),可能会导致整个程序卡住或者跑出 out of memory 的错误。
最简单的解决办法就是用一个具有合适大小的 buffered channel,这样这些 worker goroutine 向 channel 中发送错误时就不会被阻塞。(一个可选的解决办法是创建一个另外的 goroutine,当 main goroutine 返回第一个错误的同时去排空 channel 。)
下一个版本的 makeThumbnails 使用了一个 buffered channel 来返回生成的图片文件的名字,附带生成时的错误。
Unresolved include directive in modules/ROOT/pages/ch8/ch8-05.adoc - include::example$/ch8/thumbnail/thumbnail_test.go[]我们最后一个版本的 makeThumbnails 返回了新文件们的大小总计数(bytes)。和前面的版本都不一样的一点是我们在这个版本里没有把文件名放在 slice 里,而是通过一个 string 的 channel 传过来,所以我们无法对循环的次数进行预测。
为了知道最后一个 goroutine 什么时候结束(最后一个结束并不一定是最后一个开始),我们需要一个递增的计数器,在每一个 goroutine 启动时加一,在 goroutine 退出时减一。这需要一种特殊的计数器,这个计数器需要在多个 goroutine 操作时做到安全并且提供在其减为零之前一直等待的一种方法。这种计数类型被称为 sync.WaitGroup,下面的代码就用到了这种方法:
Unresolved include directive in modules/ROOT/pages/ch8/ch8-05.adoc - include::example$/ch8/thumbnail/thumbnail_test.go[]注意 Add 和 Done 方法的不对称。Add 是为计数器加一,必须在 worker goroutine 开始之前调用,而不是在 goroutine 中;否则的话我们没办法确定 Add 是在 "closer" goroutine 调用 Wait 之前被调用。并且 Add 还有一个参数,但 Done 却没有任何参数;其实它和 Add(-1) 是等价的。我们使用 defer 来确保计数器即使是在出错的情况下依然能够正确地被减掉。上面的程序代码结构是当我们使用并发循环,但又不知道迭代次数时很通常而且很地道的写法。
sizes channel 携带了每一个文件的大小到 main goroutine,在 main goroutine 中使用了 range loop 来计算总和。观察一下我们是怎样创建一个 closer goroutine,并让其在所有 worker goroutine 们结束之后再关闭 sizes channel 的。两步操作:wait 和 close,必须是基于 sizes 的循环的并发。考虑一下另一种方案:如果等待操作被放在了 main goroutine 中,在循环之前,这样的话就永远都不会结束了,如果在循环之后,那么又变成了不可达的部分,因为没有任何东西去关闭这个 channel,这个循环就永远都不会终止。
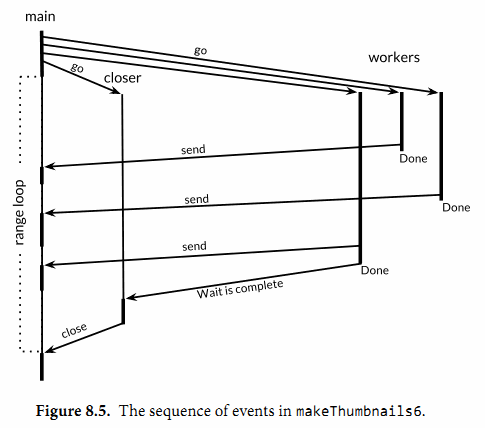
图8.5 表明了 makethumbnails6 函数中事件的序列。纵列表示 goroutine。窄线段代表 sleep,粗线段代表活动。斜线箭头代表用来同步两个 goroutine 的事件。时间向下流动。注意 main goroutine 是如何大部分的时间被唤醒执行其 range 循环,等待 worker 发送值或者 closer 来关闭 channel 的。
练习 8.4: 修改 reverb2 服务器,在每一个连接中使用 sync.WaitGroup 来计数活跃的 echo goroutine。当计数减为零时,关闭 TCP 连接的写入,像练习8.3中一样。验证一下你的修改版 netcat3 客户端会一直等待所有的并发“喊叫”完成,即使是在标准输入流已经关闭的情况下。
练习 8.5: 使用一个已有的 CPU 绑定的顺序程序,比如在3.3节中我们写的 Mandelbrot 程序或者3.2节中的3-D surface计算程序,并将他们的主循环改为并发形式,使用 channel 来进行通信。在多核计算机上这个程序得到了多少速度上的改进?使用多少个 goroutine 是最合适的呢?