Ajax分析与爬取实战
本节我们会结合一个实际的案例,来看一下 Ajax 分析和爬取页面的具体实现。
准备工作
开始分析之前,需要做好如下准备工作。
-
安装好 Python3(最低为 3.6 版本),并成功运行 Python 3 程序。
-
了解 Python HTTP 请求库
requests的基本用法。 -
了解 Ajax 基础知识和分析 Ajax 的基本方法。
以上内容在前面的章节中均有讲解,如尚未准备好,建议先熟悉一下这些内容。
爬取目标
本节我们以一个示例网站来试验一下 Ajax 的爬取,其链接为: https://spa1.scrape.center/ ,该示例网站的数据请求是通过 Ajax 完成的,页面的内容是通过 JavaScript 渲染出来的,页面如图 5-10 所示。
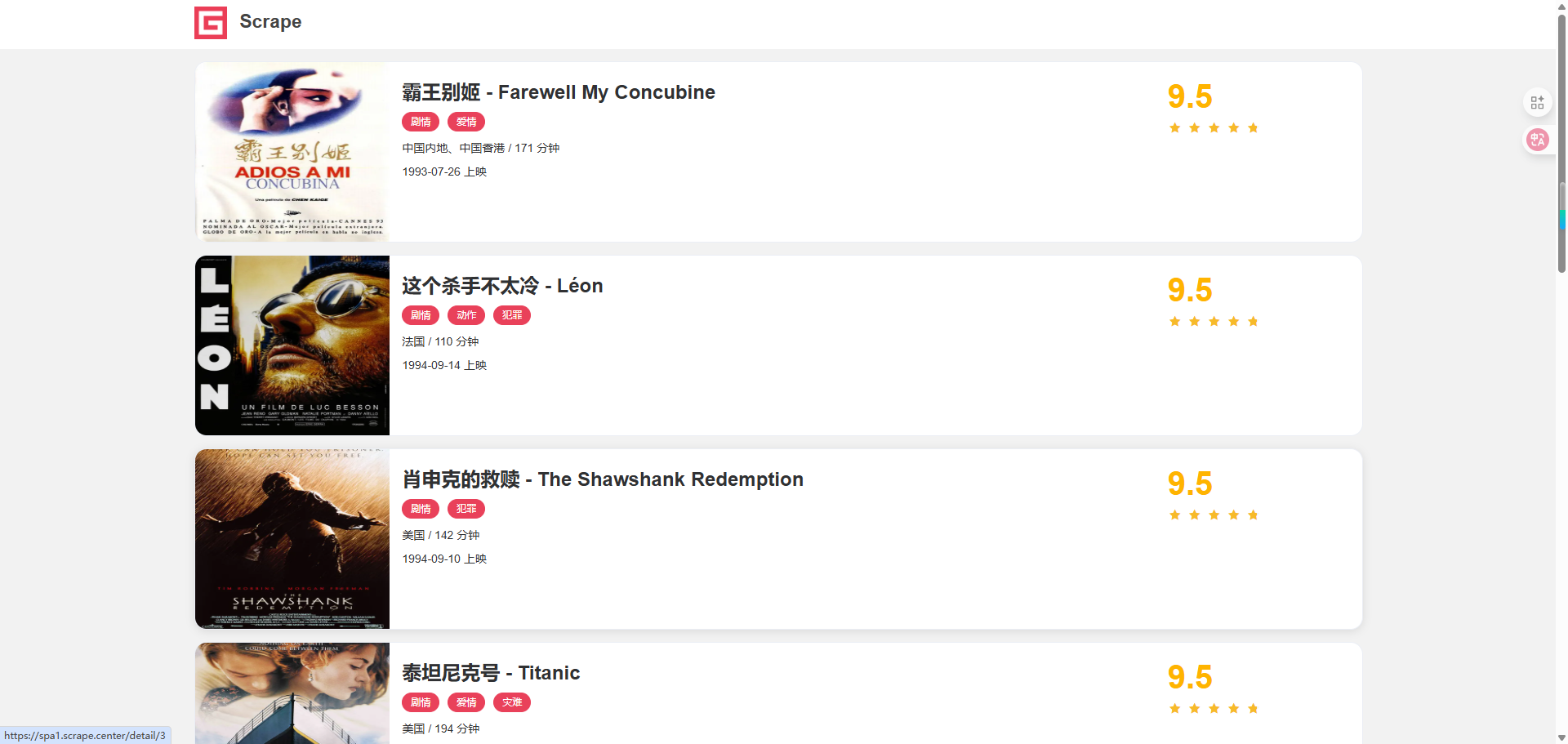
大家看着这个页面可能觉得似曾相识,这个网站不是第 2 章也列举过吗?其实不是一个网站。两个网站的后台实现逻辑和数据加载方式完全不同,只有最后呈现的样式是一样的。
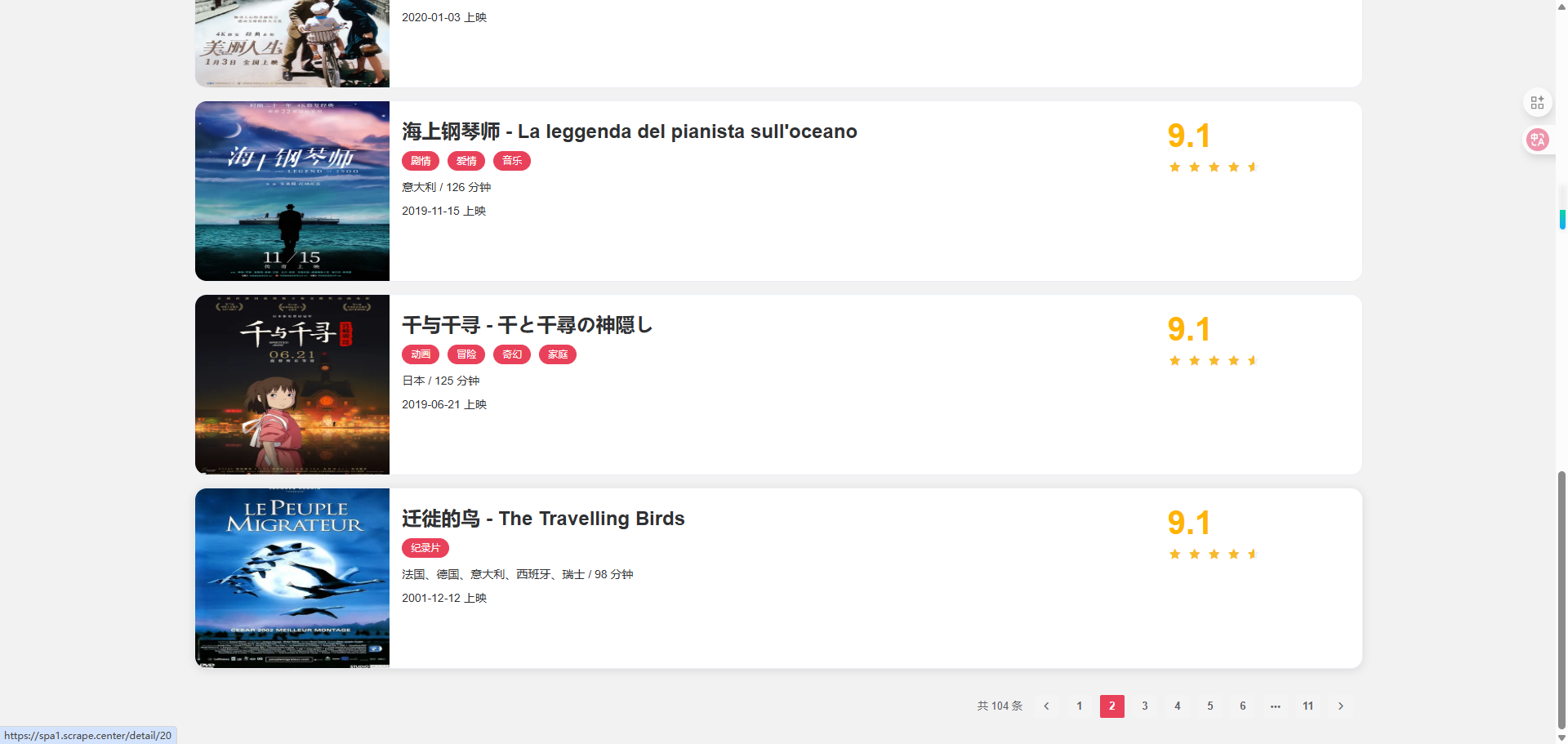
这个网站同样支持翻页,可以单击页面最下方的页码来切换到下一页,如图 5-11 所示。
单击每部电影进入对应的详情页,这些页面的结构也是完全一样的,图 5-12 展示的是《迁徒的鸟》的详情页。
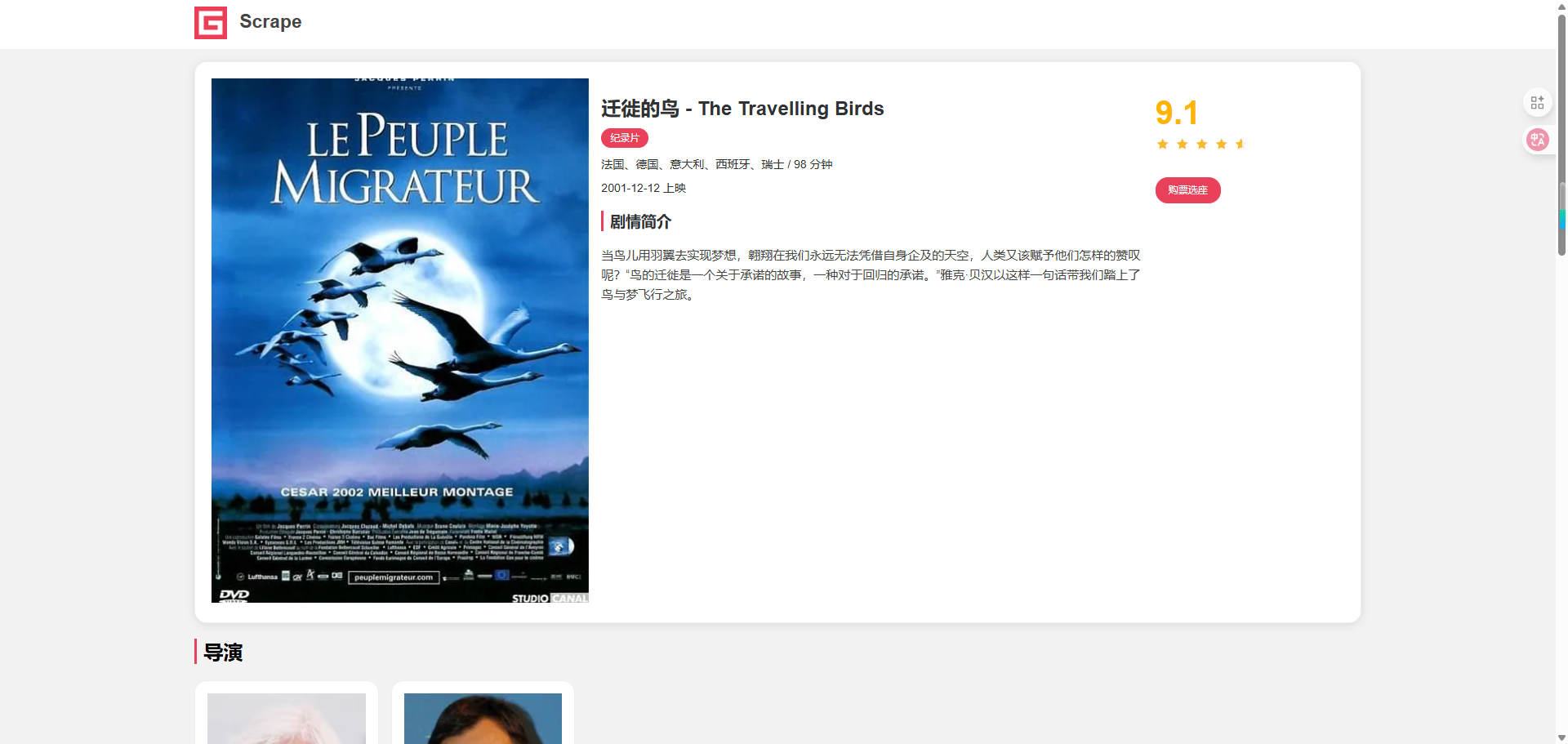
此时我们需要爬取的数据和第 2 章也是相同的,包括电影的名称、封面、类别、上映日期、评分、剧情简介等信息。
本节我们需要完成的目标如下。
-
分析页面数据的加载逻辑。
-
用
requests实现 Ajax 数据的爬取。 -
将每部电影的数据分别保存到 MongoDB 数据库。
由于本节主要讲解 Ajax,所以数据存储和加速部分就不再展开详细实现了,主要是讲解 Ajax 分析和爬取的实现。
好,现在就开始吧。
初步探索
我们先尝试用之前的 requests 直接提取页面,看看会得到怎样的结果。用最简单的代码实现一下 requests 获取网站首页源码的过程,代码如下:
import requests
url = "https://spa1.scrape.center/"
html = requests.get(url).text
print(html)运行结果如下:
<!DOCTYPE html><html lang=en><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible content="IE=edge"><meta name=viewport content="width=device-width,initial-scale=1"><link rel=icon href=/favicon.ico><title>Scrape | Movie</title><link href=/css/chunk-700f70e1.1126d090.css rel=prefetch><link href=/css/chunk-d1db5eda.0ff76b36.css rel=prefetch><link href=/js/chunk-700f70e1.0548e2b4.js rel=prefetch><link href=/js/chunk-d1db5eda.b564504d.js rel=prefetch><link href=/css/app.ea9d802a.css rel=preload as=style><link href=/js/app.17b3aaa5.js rel=preload as=script><link href=/js/chunk-vendors.683ca77c.js rel=preload as=script><link href=/css/app.ea9d802a.css rel=stylesheet></head><body><noscript><strong>We're sorry but portal doesn't work properly without JavaScript enabled. Please enable it to continue.</strong></noscript><div id=app></div><script src=/js/chunk-vendors.683ca77c.js></script><script src=/js/app.17b3aaa5.js></script></body></html>可以看到,爬取结果就只有这么一点 HTML 内容,而我们在浏览器中打开这个网站,却能看到如图 5-13 所示的页面。
在 HTML 中,我们只能看到源码引用的一些 JavaScript 和 CSS 文件,并没有观察到任何电影数据信息。
遇到这样的情况,说明我们看到的整个页面都是 JavaScript 染得到的,浏览器执行了 HTML 中引用的 JavaScript 文件,JavaScript 通过调用一些数据加载和页面渲染方法,才最终呈现了图 5-13 展示的结果。这些电影数据一般是通过 Ajax 加载的,JavaScript 在后台调用 Ajax 数据接口,得到数据之后,再对数据进行解析并谊染呈现出来,得到最终的页面。所以要想爬取这个页面,直接爬取 Ajax 接口,再获取数据就好了。
在 5.2 节,我们已经了解了 Ajax 分析的基本方法,下面一起分析一下 Ajax 接口的逻辑并实现数据爬取吧。
爬取列表页
首先分析列表页的 Ajax 接口逻辑,打开浏览器开发者工具,切换到 Network 面板,勾选 Preserve Log 并切换到 XHR 选项卡,如图 5-14 所示。
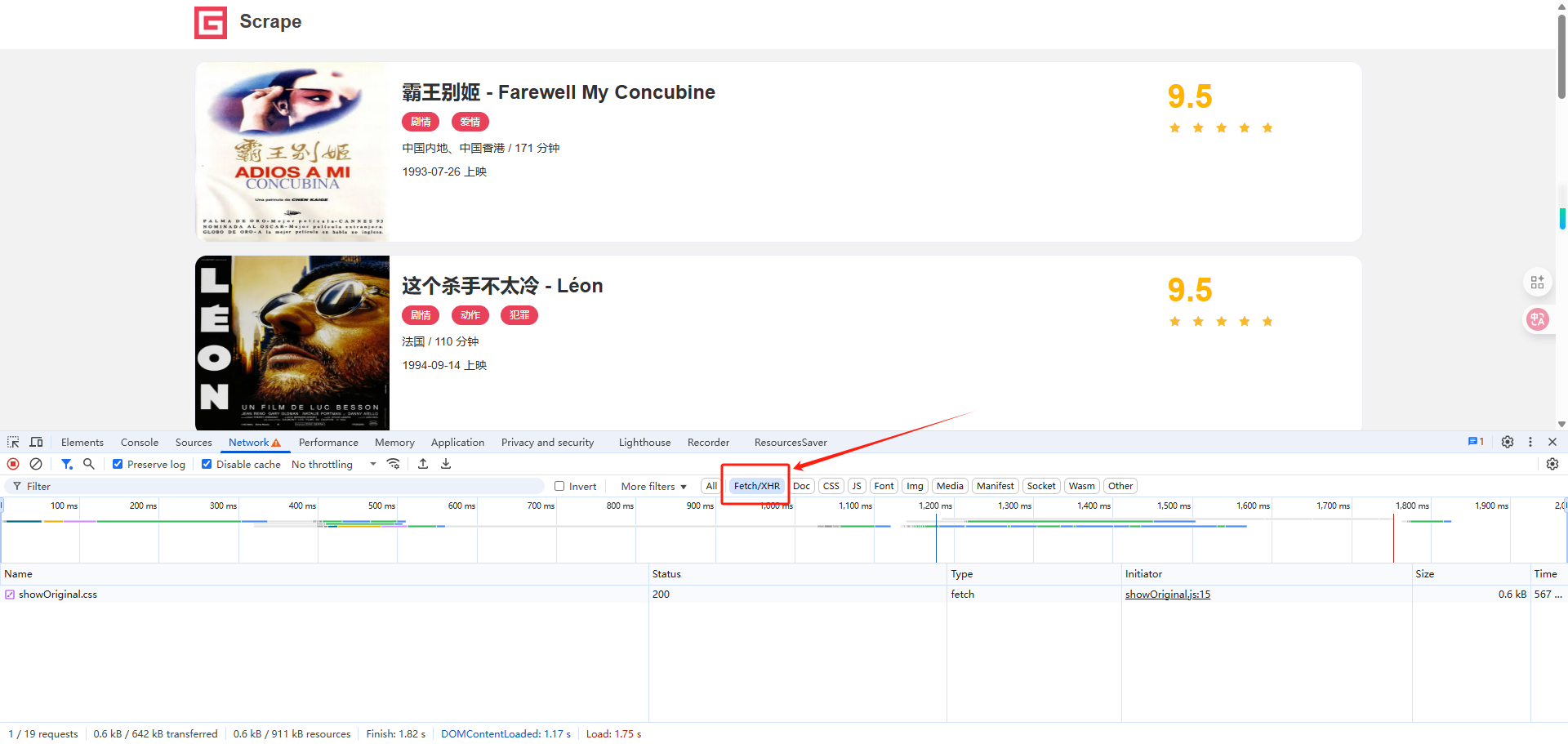
接着重新刷新页面,再单击第 2 页、第 3 页、第 4 页的按钮,这时可以观察到不仅页面上的数据发生了变化,开发者工具下方也监听到了几个 Ajax 请求,如图 5-15 所示。
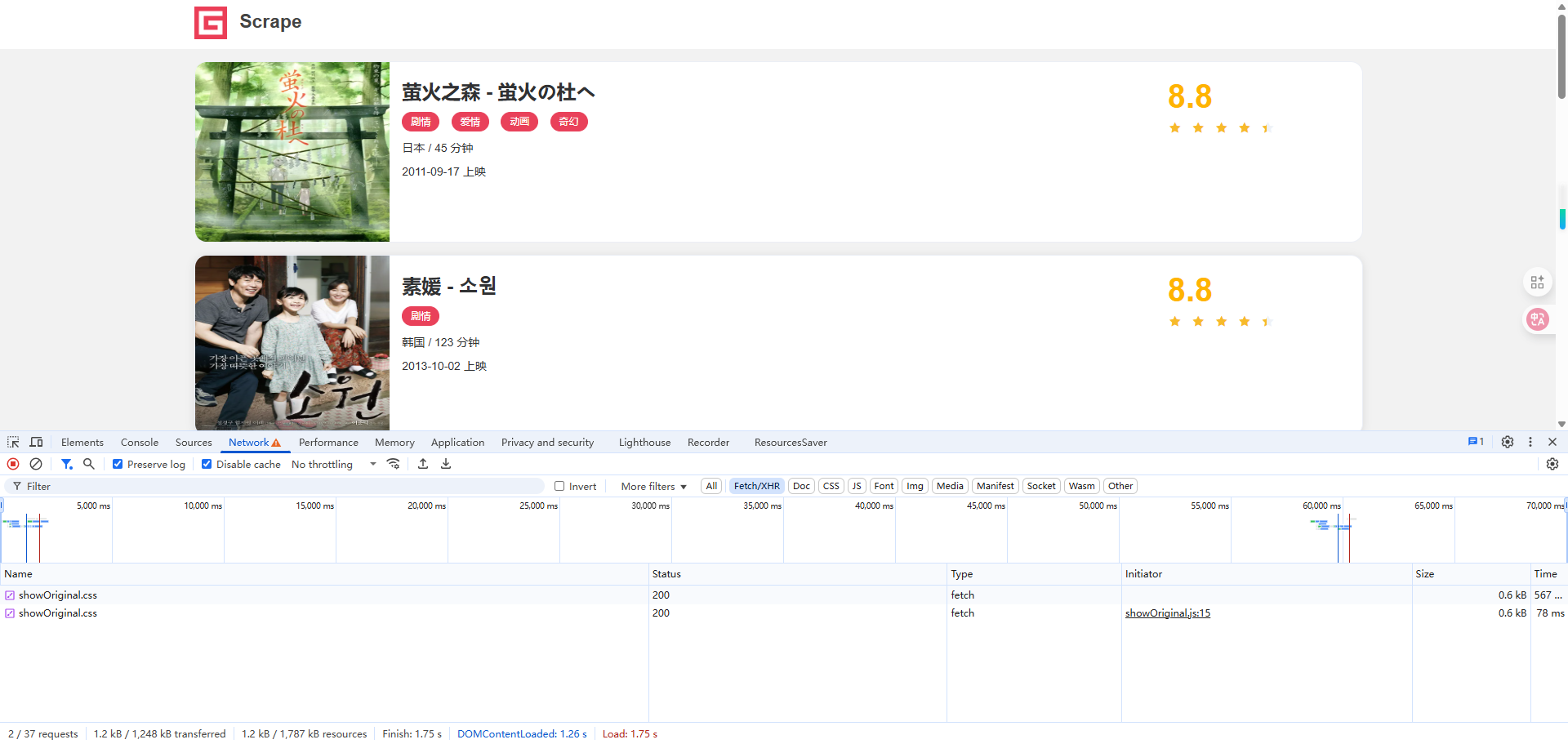
我们切换了 4 页,每次翻页也出现了对应的 Ajax 请求。可以点击查看其请求详情,观察请求 URL、参数和响应内容是怎样的,如图 5-16 所示。
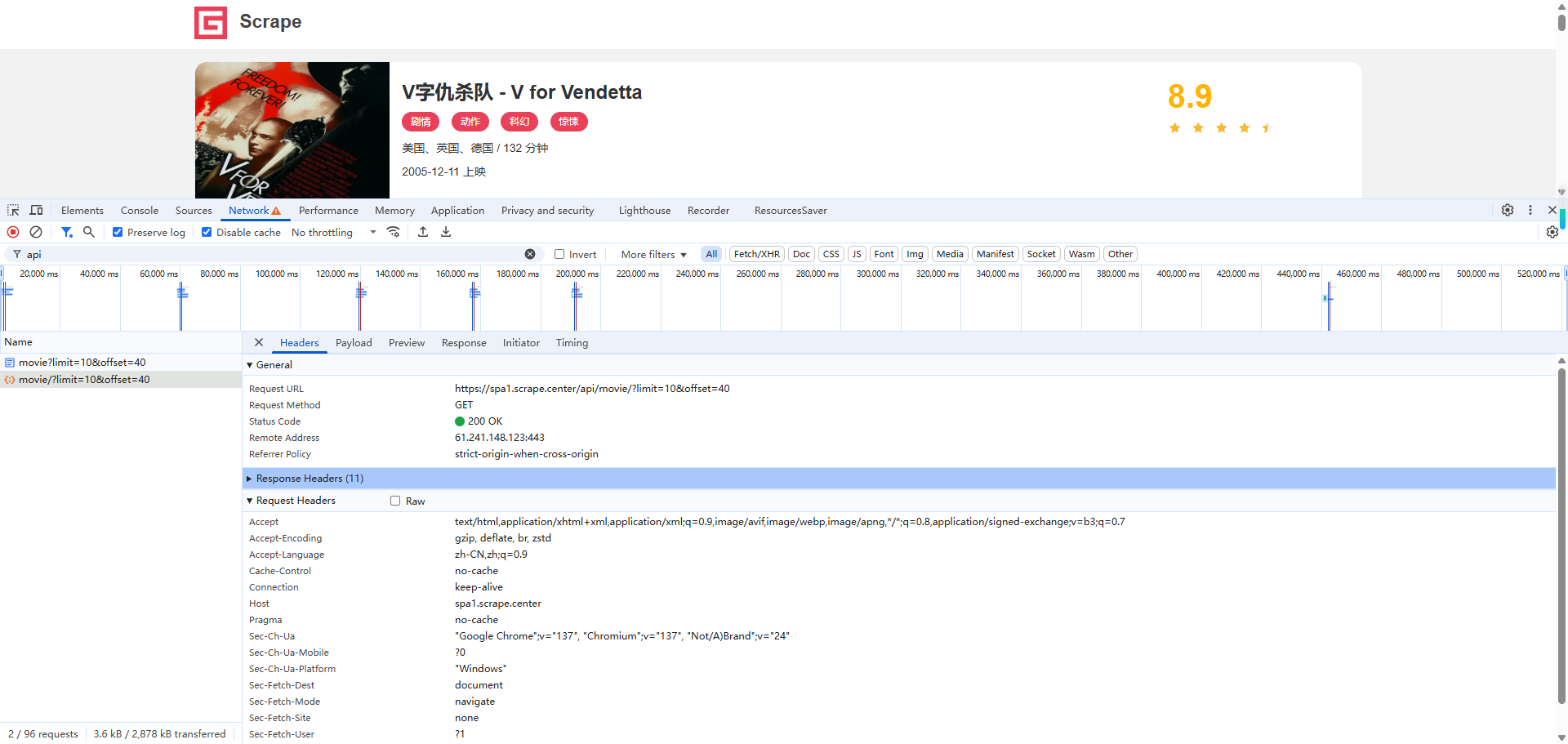
这里我点开了最后一个结果,观察到其 Ajax 接口的请求 URL 为 https://spa1.scrape.center/api/movie?limit=10&offset=40 ,这里有两个参数:一个是 limit,这里是 10;一个是 offset,这里是 40。
观察多个 Ajax 接口的参数,我们可以总结出这么一个规律:limit 一直为 10,正好对应每页 10 条数据;offset 在依次变大,页数每加 1,offset 就加 10,因此其代表页面的数据偏移量。例如第 2 页的 offset 为 10 就代表跳过 10 条数据,返回从 11 条数据开始的内容,再加上 limit 的限制,最终页面呈现的就是第 11 条至第 20 条数据。
接着我们再观察一下响应内容,切换到 Preview 选项卡,结果如图 5-17 所示。
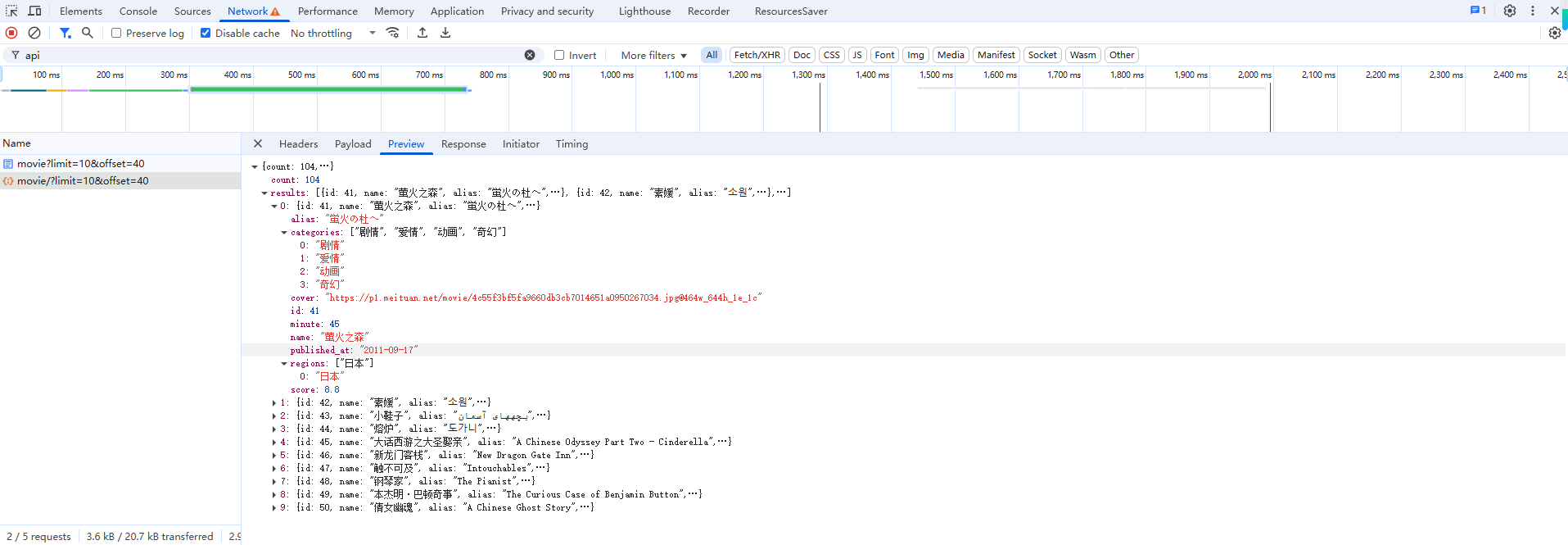
可以看到,结果就是一些 JSON 数据,其中有一个 results 字段,是一个列表,列表中每一个元素都是一个字典。观察一下字典的内容,里面正好可以看到对应电影数据的字段,如 name、alias、 cover、categories。对比一下浏览器页面中的真实数据,会发现各项内容完全一致,而且这些数据已经非常结构化了,完全就是我们想要爬取的数据,真的是得来全不费工夫。
这样的话,我们只需要构造出所有页面的 Ajax 接口,就可以轻松获取所有列表页的数据了。
先定义一些准备工作,导人一些所需的库并定义一些配置,代码如下:
import requests
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s:%(message)s')
INDEX_URL = 'https://spa1.scrape.center/api/movie/?limit={limit}%offset={offset}'这里我们引入了 requests 和 logging 库,并定义了 logging 的基本配置。接着定义了 INDEX_URL,这里把 limit 和 offset 预留出来变成占位符,可以动态传入参数构造一个完整的列表页 URL。
下面我们实现一下详情页的爬取。还是和原来一样,我们先定义一个通用的爬取方法,其代码如下:
def scrape_api(url):
logging.info('scraping %s...', url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requeests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)这里我们定义了一个 scrape_api 方法,和之前不同的是,这个方法专门用来处理 JSON 接口。最后的 response 调用的是 json 方法,它可以解析响应内容并将其转化成 JSON 字符串。
接着在这个基础之上,定义一个爬取列表页的方法,其代码如下:
LIMIT = 10
def scrape_index(page):
url = INDEX_URL.format(limit=LIMIT, offset=LIMIT * (page - 1))
return scrape_api(url)这里我们定义了一个 scrape_index 方法,它接收一个参数 page,该参数代表列表页的页码。
scrape_index 方法中,先构造了一个 url,通过字符串的 format 方法,传入 limit 和 offset 的值。这里 limit 就直接使用了全局变量 LIMIT 的值;offset 则是动态计算的,计算方法是页码数减一再乘以 limit,例如第 1 页的 offset 就是 0,第 2 页的 offset 就是 10,以此类推。构造好 url 后,直接调用 scrape_api 方法并返回结果即可。
这样我们就完成了列表页的爬取,每次发送 Ajax 请求都会得到 10 部电影的数据信息。
由于这时爬取到的数据已经是 JSON 类型了,所以无须像之前那样去解析 HTML 代码来提取数据,爬到的数据已经是我们想要的结构化数据,因此解析这一步可以直接省略啦。
到此为止,我们能成功爬取列表页并提取电影列表信息了。
爬取详情页
虽然我们已经可以拿到每一页的电影数据,但是这些数据实际上还缺少一些我们想要的信息,如剧情简介等信息,所以需要进一步进入详情页来获取这些内容。
单击任意一部电影,如《教父》,进入其详情页,可以发现此时的页面 URL 已经变成了 https://spa1.scrape.center/detail/40 ,页面也成功展示了《教父》详情页的信息,如图 5-18 所示。
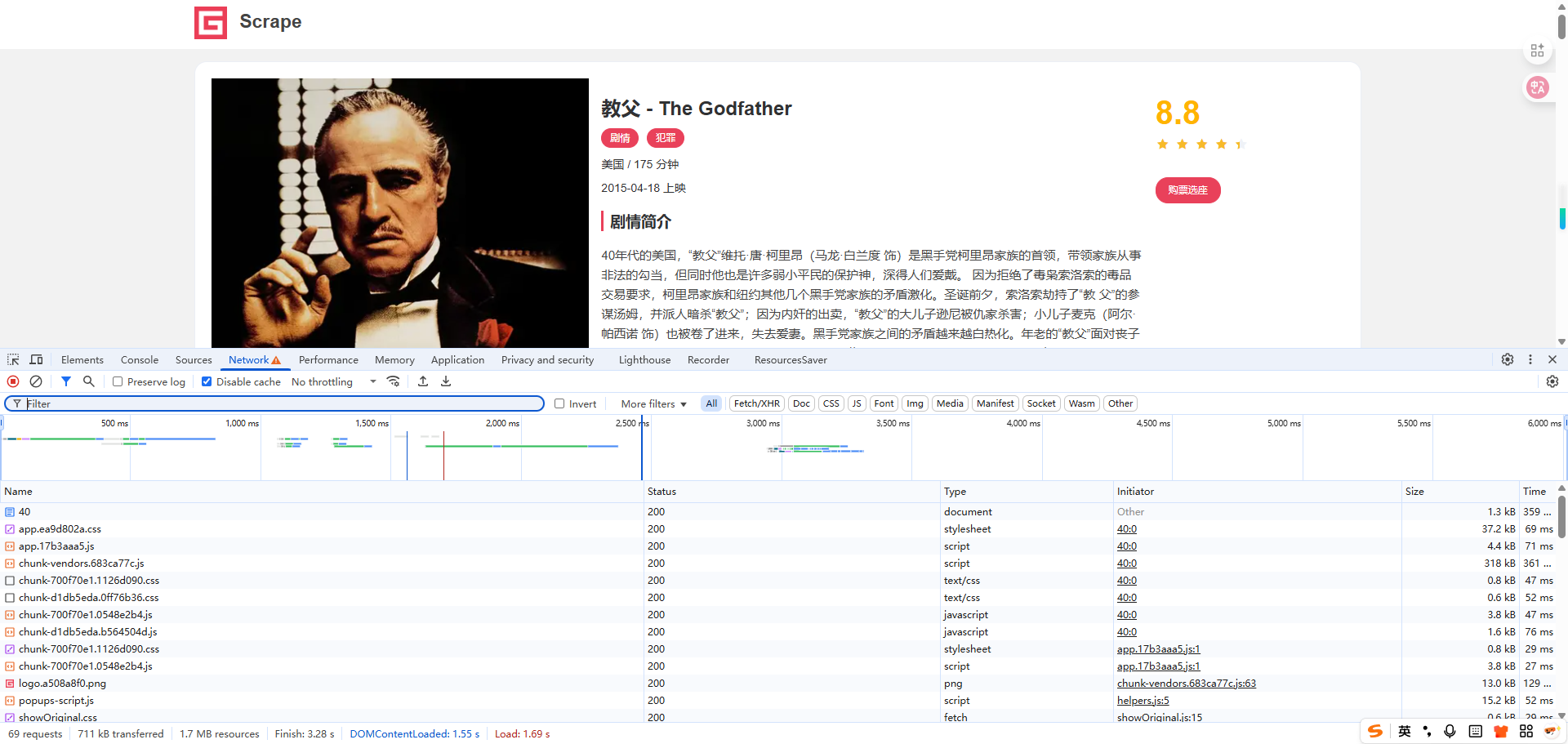
另外,我们也可以观察到开发者工具中又出现了一个 Ajax 请求,其 URL 为 https://spa1.scrape.center/api/movie/40/ ,通过 Preview 选项卡也能看到 Ajax 请求对应的响应信息,如图 5-19 所示。
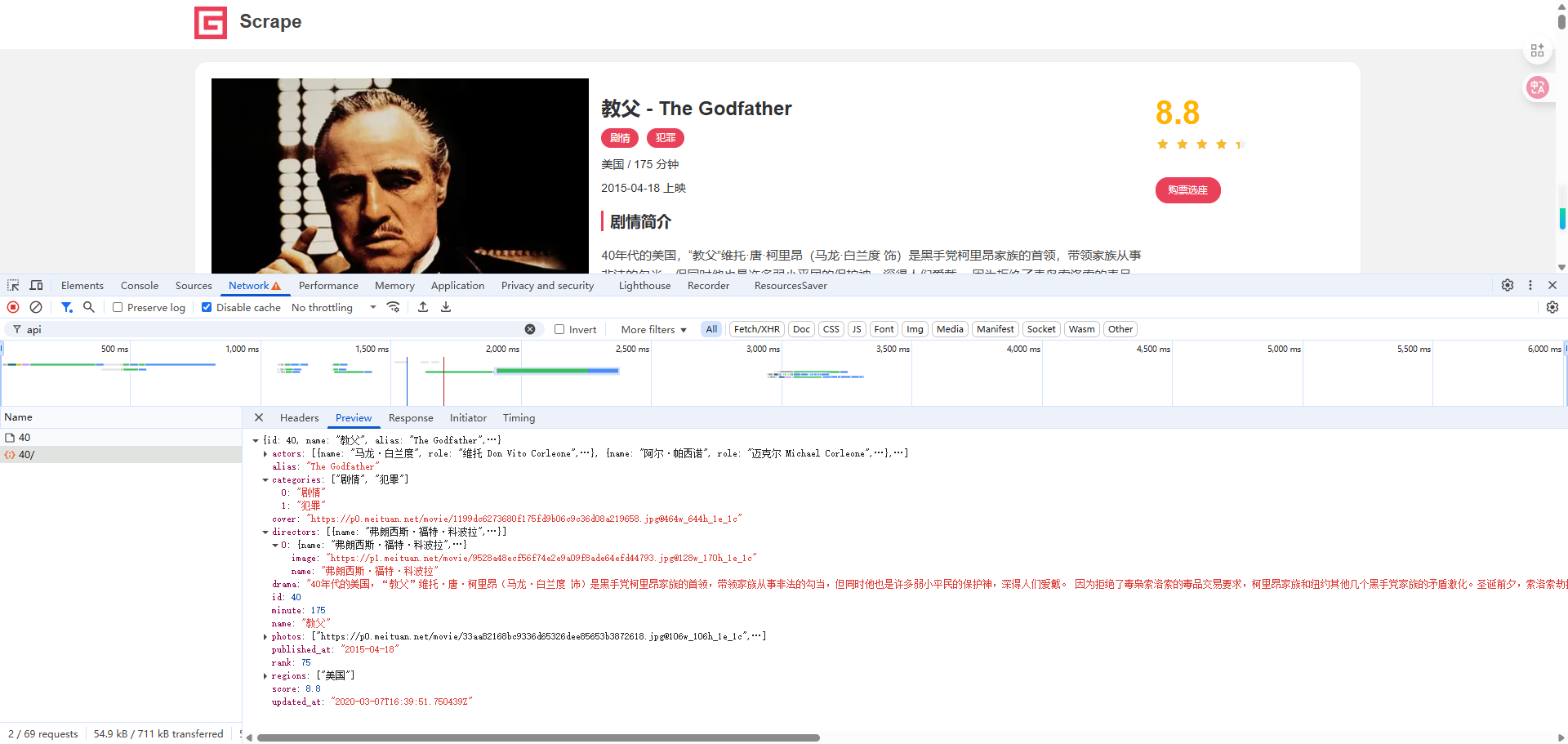
稍加观察就可以发现,Ajax 请求的 URL 后面有一个参数是可变的,这个参数是电影的 id,这里是 40,对应《教父》这部电影。
如果我们想要获取 id 为 50 的电影,只需要把 URL 最后的参数改成 50 即可,即 https://spa1.scrape.center/api/movie/50/ ,请求这个新的 URL 便能获取 id 为 50 的电影对应的数据了。
同样,响应结果也是结构化的 JSON 数据,其字段也非常规整,我们直接爬取即可。
现在,详情页的数据提取逻辑分析完了,怎么和列表页关联起来呢?电影 id 从哪里来呢?我们回过头看看列表页的接口返回数据,如图 5-20 所示。
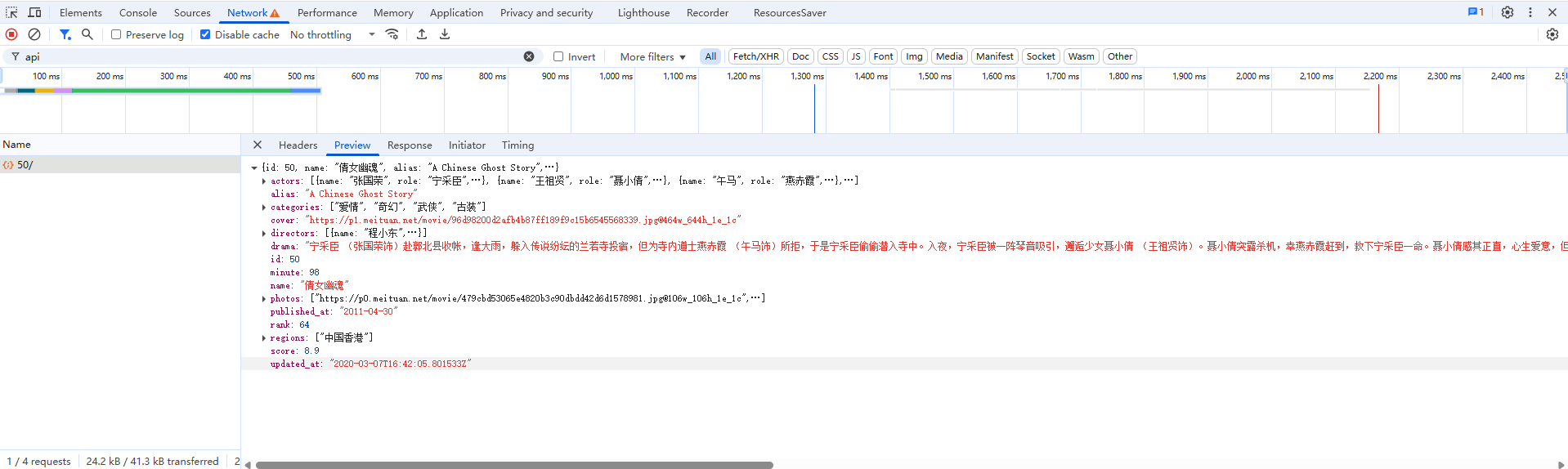
可以看到,列表页原本的返回数据中就带有 id 这个字段,所以只需要拿列表页结果中的 id 来构造详情页的 Ajax 请求的 URL 就好了。
接着,我们就先定义一个详情页的爬取逻辑,代码如下:
DETAIL_URL = 'https://spa1.scrape.center/api/movie/{id}'
def scrape_detail(id):
url = DETAIL_URL.format(id=id)
return scrape_api(url)这里定义了一个 scrape_detail 方法,它接收一个参数 id。这里的实现也非常简单,先根据定义好的 DETAIL_URL 加 id 构造一个真实的详情页 Ajax 请求的 URL,再直接调用 scrape_api 方法传入这个 url 即可。
最后,我们定义一个总的调用方法,对以上方法串联调用,代码如下:
TOTAL_PAGE = 10
def main():
for page in range(1, TOTAL_PAGE + 1):
index_data = scrape_index(page)
for item in index_data.get(results'):
id = item.get('id')
detail_data = scrape_detail(id)
logging.info('detail data %s',detail_data)
if __name__ == '__main__':
main()我们定义了一个 main 方法,该方法首先遍历获取页码 page,然后把 page 当作参数传递给 scrape_index 方法,得到列表页的数据。接着遍历每个列表页的每个结果,获取每部电影的 id。之后把 id 当作参数传递给 scrape_detail 方法来爬取每部电影的详情数据,并将此数据赋值为 detail_data,最后输出 detail_data 即可。
运行结果如下:
由于内容较多,这里省略了部分内容。
可以看到,整个爬取工作已经完成了,这里会依次爬取每一个列表页的 Ajax 接口,然后依次爬取每部电影的详情页 Ajax 接口,并打印出每部电影的 Ajax 接口响应数据,而且都是 JSON 格式。至此,所有电影的详情数据,我们都爬取到啦。
保存数据
好,成功提取详情页信息之后,下一步就要把它们保存起来了。第 5 章我们学习了 MongoDB 的相关操作,接下来我们就把数据保存到 MongoDB 吧。
保存之前,请确保自已有一个可以正常连接和使用的 MongoDB 数据库,这里我就以本地 localhost 的 MongoDB 数据库为例来进行操作,其运行在 27017 端口上,无用户名和密码。
将数据导入 MongoDB 需要用到 PyMongo 这个库。接下来我们把它们引入一下,同时定义一下 MongoDB 的连接配置,实现方式如下:
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'movies'
import pymongo
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client['movies']
collection = db['movies']这里我们先声明了几个变量,如下为对它们的介绍。
-
MONGO_CONNECTION_STRING:MongoDB 的连接字符串,里面定义的是 MongoDB 的基本连接信息,这里是 host、port,还可以定义用户名、密码等内容。
-
MONGO_DBNAME:MongoDB 数据库的名称。
-
MONGO_COLLECTION_NAME:MongoDB 的集合名称。
然后用 MongoClient 声明了一个连接对象 client,并依次声明了存储数据的数据库和集合。
接下来,再实现一个将数据保存到 MongoDB 数据库的方法,实现代码如下:
def save_data(data):
collection.update_one({
'name': data.get('name')
},{
'$set': data
},upsert=True)这里我们定义了一个 save_data 方法,它接收一个参数 data,也就是上一节提取的电影详情信息。这个方法里面,我们调用了 update_one 方法,其第一个参数是查询条件,即根据 name 进行查询;第二个参数是 data 对象本身,就是所有的数据,这里我们用 $set 操作符表示更新操作;第三个参数很关键,这里实际上是 upsert 参数,如果把它设置为 True,就可以实现存在即更新,不存在即插入的功能,更新时会参照第一个参数设置的 name 字段,所以这样可以防止数据库中出现同名的电影数据。
|
实际上电影可能有同名现象,但此处场景下的爬取数据没有同名情况,当然这里更重要的是实现 MongoDB 的去重操作。 |
好的,接下来稍微改写一下 main 方法就好了,改写后如下:
def main():
for page in range(1,TOTALPAGE + 1):
index_data = scrape_index(page)
for item in index_data.get('results'):
id = item.get('id')
detail_data = scrape_detail(id)
logging.info('detail data %s', detail_data)
save_data(detail_data)
logging.info('data saved successfully')其实就是增加了对 save_data 方法的调用,并添加了一些日志信息。
重新运行,我们来看一下输出结果:
同样,由于输出内容较多,这里省略了部分内容。
可以看到,这里成功爬取到了数据,并且提示数据存储成功,没有任何报错信息。
接下来,我们使用 Robo 3T 连接 MongoDB 数据库看下爬取结果。由于我使用的是本地的 MongoDB 所以我直接在 Robo 3T 里面输入 localhost 的连接信息即可,这里请替换成自已的 MongoDB 连接信息如图 5-21 所示。
图5-21 输入 MongoDB 连接信息
连接之后,我们便可以在 movies 这个数据库中 movies 这个集合下看到刚才爬取的数据了,如图 5-22 所示。
图5-22 爬取的数据存入了数据库
可以看到,数据就是以 JSON 格式存储的,一条数据对应一部电影的信息,各种嵌套关系也一目了然,同时第三列还标识出了数据类型。
这样就证明我们的数据成功存储到 MongoDB 里了。