AST技术简介
前面我们介绍了一些 JavaScript 混淆的基本知识,可以看到混淆方式多种多样,比如字符串混淆、变量名混淆、对象键名替换、控制流平坦化等。当然,我们也学习了一些相关的调试技巧,比如 Hook、断点调试等。但是这些方法本质上其实还是在已经混淆的代码上进行的操作,所以代码的可读性依然比较差。
有没有什么办法可以直接提高代码的可读性呢? 比如说,字符串混淆了,我们想办法把它还原了; 对象键名替换了,我们想办法把它们重新组装好,控制流平坦化之后逻辑不直观了,我们想办法把它还原成一个代码控制流。
到底应该怎么做呢? 这就需要用到 AST 相关的知识了。本节中,我们就来了解 AST 相关的基础知识,并介绍操作 AST 的相关方法。
AST介绍
首先,我们来了解什么是 AST。AST 的全称叫作 Abstract Syntax Tree,中文翻译叫作抽象语法树。如果你对编译原理有所了解的话,一段代码在执行之前,通常要经历这么三个步骤。
-
词法分析:一段代码首先会被分解成一段段有意义的词法单元,比如说
const name = 'Germey'这段代码,它就可以被拆解成四部分:const、name、=、'Germey',每一个部分都具备一定的含义。 -
语法分析:接着编译器会尝试对一个个词法单元进行语法分析,将其转换为能代表程序语法结构的数据结构。比如,
const就被分析为VariableDeclaration类型,代表变量声明的具体定义;name就被分析为Identifier类型,代表一个标识符。代码内容多了,这一个个词法就会有依赖、嵌套等关系,因此表示语法结构的数据结构就构成了一个树状的结构,也就成了语法树,即 AST。 -
指令生成:最后将 AST 转换为实际真正可执行的指令并执行即可。
AST 是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,这种数据结构其实可以类别成一个大的 JSON 对象。前面我们也介绍过 JSON 对象,它可以包含列表、字典并且层层嵌套,因此它看起来就像一棵树,有树根、树干、树枝和树叶,无论多大,都是一棵完整的树。
在前端开发中,AST 技术应用非常广泛,比如 webpack 打包工具的很多压缩和优化插件、Babel 插件、Vue 和 React 的脚手架工具的底层等都运用了 AST 技术。有了 AST,我们可以方便地对 JavaScript 代码进行转换和改写,因此还原混淆后的 JavaScript 代码也就不在话下了。
接下来,我们通过一些实例了解 AST 的一些基本理念和操作。
实例引入
首先,推荐一个 AST 在线解析的网站 https://astexplorer.net/ ,我们先通过一个非常简单的实例来感受下 AST 究竟是什么样子的。输入上述的示例代码:
const name = 'Germey'这时候我们就可以看到在右侧就出现了一个树状结构,这就是 AST,如图 11-81 所示。
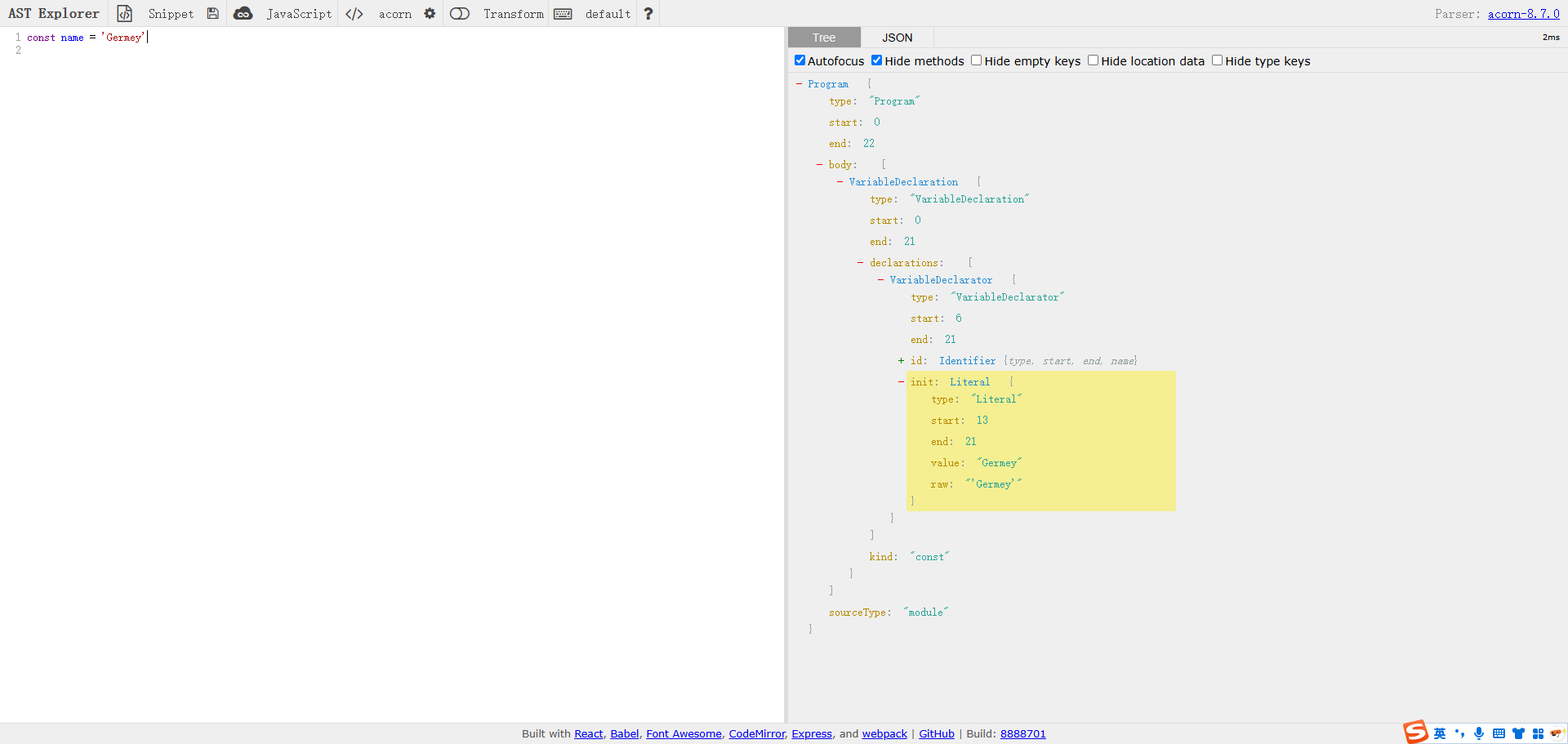
这就是一个层层嵌套的数据结构,可以看到它把代码的每一个部分都进行了拆分并分析出对应的类型、位置和值。比如说,name 被解析成一个 type 为 Identifier 的数据结构,start 和 end 分别代表代码的起始和终止位置,name 属性代表该 Identifier 的名称。另外,Germey 这个字符串被解析成了 StringLiteral 类型的数据结构,它同样有 start、end 等属性,同时还有 extra 属性。extra 属性还带有子属性 rawValue,该子属性的值就是 Germey 这个字符串。我们所看到的这些数据结构就构成了一个层层嵌套的 AST。
另外,在右上角,我们还看到一个 Parser 标识,其内容是 @babel/parser。这是一个目前最流行的 JavaScript 语法编译器 Babel 的 Node.js 包,同时它也是主流前端开发技术中必不可少的一个包。它内置了很多分析 JavaScript 代码的方法,可以实现 JavaScript 代码到 AST 的转换。更多的介绍可以参考 Babel 的官网。
接下来,我们使用 Babel 来实现一下 AST 的解析、修改。
准备工作
由于本节内容需要用到 Babel,而 Babel 是基于 Node.js 的,所以这里需要先安装 Node.js,版本推荐为 14.x 及以上,安装方法可以参考: https://setup.scrape.center/nodejs 。
安装好 Node.js 之后,我们便可以使用 npm 命令了。接着,我们还需要安装一个 Babel 的命令行工具 @babel/node,安装命令如下:
npm install -g @babel/node接下来,我们再初始化一个 Node.js 项目 learn-ast,然后在 learn-ast 目录下运行初始化命令,具体如下:
npm init
npm install -D @babel/core@babel/cli@babel/preset-env运行完毕之后,就会生成一个 package.json 文件并在 devDependencies 中列出了刚刚安装的几个 Node.js 包。
接着,我们需要在 learn-ast 目录下创建一个 .babelrc 文件,其内容如下:
{
"presets": [
"@babel/preset-env"
]
}这样我们就完成了初始化操作。
节点类型
在刚才的示例中,我们看到不同的代码词法单元被解析成了不同的类型,所以这里先简单列举 Babel 中所支持的一些类型。
-
Literal:中文可以理解为字面量,即简单的文字表示,比如 3、"abc"、null、true 这些都是基本的字面表示。它又可以进一步分为 RegExpLiteral、NullLiteral、StringLiteral、BooleanLiteral、NumericLiteral、BigIntLiteral 等类型,更确切地代表某一种字面量。
-
Declarations:声明,比如 FunctionDeclaration 和 VariableDeclaration 分别用于声明一个方法和变量。
-
Expressions:表达式,它本身会返回一个计算结果,通常有两个作用:一个是放在赋值语句的右边进行赋值,另外还可以作为方法的参数。比如 LogicalExpression、ConditionalExpression、ArrayExpression 等分别代表逻辑运算表达式、三元运算表达式、数组表达式。另外,还有一些特殊的表达式,如 YieldExpression、AwaitExpression、ThisExpression。
-
Statements:语句,比如 IfStatement、SwitchStatement、BreakStatement 这些控制语句,还有一些特殊的语句,比如 DebuggerStatement、BlockStatement 等。
-
Identifier:标识符,指代一些变量的名称,比如说上述例子中
name就是一个 Identifier。 -
Classes:类,代表一个类的定义,包括 Class、ClassBody、ClassMethod、ClassProperty 等具体类型。
-
Functions:方法声明,它一般代表 FunctionDeclaration 或 FunctionExpression 等具体类型。
-
Modules:模块,可以理解为一个 Node.js 模块,包括 ModuleDeclaration、ModuleSpecifier 等具体类型。
-
Program:程序,整个代码可以成为 Program。
当然,除此之外还有很多类型,具体可以参考 https://babeljs.io/docs/en/babel-types 。
@babel/parser的使用
@babel/parser 是 Babel 中的 JavaScript 解析器,也是一个 Node.js 包,它提供了一个重要的方法,就是 Parse 和 ParseExpression 方法,前者支持解析一段 JavaScript 代码,后者则是尝试解析单个 JavaScript 表达式并考虑了性能问题。一般来说,我们直接使用 parse 方法就足够了。
对于 parse 方法来说,输入和输出如下。
-
输入:一段 JavaScript 代码
-
输出:该段 JavaScript 代码对应的抽象语法树,即 AST,它基于 ESTree 规范
由于 JavaScript 代码中包含多种类型的表达,比如变量名、变量值、方法声明、控制语句、类声明等。这里简单做下归类,具体可以参考: https://github.com/babel/babel/blob/master/packages/babel-parser/ast/spec.md。
现在我们来测试一下。
新建一个 JavaScript 文件,将其保存为 codes/code1.js,其内容如下:
const a = 3;
let string = "hello";
for (let i = 0; i < a; i++) {
string += "world";
}
console.log("string", string);下面我们需要使用 parse 方法将其转化为一个抽象语法树,即 AST。
新建一个 basic1.js 文件,其内容如下:
import { parse } from "@babel/parser";
import fs from "fs";
const code = fs.readFileSync("codes/code1.js", "utf-8");
let ast = parse(code);
console.log(ast);
console.log(ast.program.body);接着,我们可以使用 babel-node 运行:
babel-node basic1.js运行结果如下:
可以看到,整个 AST 的根节点就是一个 Node,其 type 是 File,代表一个 File 类型的节点,其中包括 type、start、end、loc、program 等属性。其中 program 也是一个 Node,但它的 type 是 Program 代表一个程序。同样,Program 也包括了一些属性,比如 start、end、loc、interpreter、body 等。其中,body 是最为重要的属性,是一个列表类型,列表中的每个元素也都是一个 Node,但这些不同的 Node 其实也是不同的类型,它们的 type 多种多样,不过这里控制台并没有把其中的节点内容输出出来。
我们可以增加一行代码,再专门输出一下 body 的内容:
console.log(ast.program.body);重新运行,可以发现这里又多输出了一些内容,具体如下:
由于内容过多,这里省略了一些内容。可以看到,我们直接通过 ast.program.body 即可将 body 获取到。可以看到,刚才的四个 Node 的具体结构也被输出出来了。前两个 Node 都是 VariableDeclaration 类型,这正好对应了前两行代码:
const a=3;
let string ="hello";这里我们分别声明了一个数字类型和字符串类型的变量,所以每句都被解析为 VariableDeclaration 类型。每个 VariableDeclaration 都包含了一个 declarations 属性,其内部又是一个 Node 列表,其中包含了具体的详情信息。
接着,我们再继续观察下一个 Node。它是 ForStatement 类型,代表一个 for 循环语句,对应的代码如下:
for(let i=o;ia; i++) {
string += "world";
}for 循环通常包括四个部分,for 初始逻辑、判断逻辑、更新逻辑以及 for 循环区块的主循环执行逻辑,所以对于一个 ForStatement,它也自然有几个对应的属性表示这些内容,分别为 init、test、update 和 body。
对于 init,即循环的初始逻辑,其代码如下:
let i = 0;它相当于一个变量声明,所以它又被解析为 VariableDeclaration 类型,这和上文是一样的。
对于 test,即判断逻辑,其代码如下:
i < a
它是一个逻辑表达式,被解析为 BinaryExpression,代表逻辑运算。
对于 update,即更新逻辑,其代码如下:
i++
它就是对 i 加 1,也是一个表达式,被解析为 UpdateExpression 类型。
对于 body,它被一个大括号包围,其内容为:
{
string += "world";
}整个内容算作一个代码块,所以被解析为 BlockStatement 类型,其 body 属性又是一个列表。
对于最后一行,代码如下:
console.log('string',string);它被解析为 ExpressionStatement 类型,expression 的属性是 CallExpression。CallExpression 文包含了 callee 和 arguments 属性,对应的就是 console 对象的 log 方法的调用逻辑。
到现在为止,我们应该能弄明白这个基本过程了。
parser 会将代码根据逻辑区块进行划分,每个逻辑区块根据其作用都会归类成不同的类型,不同的类型拥有不同的属性表示。同时代码和代码之间有嵌套关系,所以最终整个代码就会被解析成一个层层嵌套的表示结果。
另外,个人还推荐使用上文提到的 https://astexplorer.net/ 网站来进行 AST 的解析和查看,它比代码更加直观。
转化为 AST 之后,怎样再把 AST 转回 JavaScript 代码呢?要还原,我们可以借助于 generate 方法。
@babel/generate的使用
@babel/generate 也是一个 Node.js 包,它提供了 generate 方法将 AST 还原成 JavaScript 代码,调用如下:
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import fs from "fs";
const code = fs.readFileSync("codes/code1.js", "utf-8");
let ast = parse(code);
const { code: output } = generate(ast);
console.log(output);重新运行,可以得到如下结果:
const a= 3;
let string = "hello";
for (let i = 0; i < a; i++) {
string += "world"
}
console.log("string", string)这时候我们可以看到,利用 generate 方法,我们成功地把一个 AST 对象转化为代码。
到这里我们就清楚了,如果要把一段 JavaScript 解析称 AST 对象,就用 parse 方法。如果要把 AST 对象还原成代码,就用 generate 方法。
另外,generate 方法还可以在第二个参数接收一些配置选项,第三个参数可以接收原代码作为输出的参考,用法如下:
const output = generate(ast, { /*options*/ }, code);其中 options 可以是一些其他配置。这里列举一部分配置,具体如表 11-1 所示。
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
auxiliaryCommentBefore |
string |
在输出文件的开头添加块注释可选字符串 |
|
auxiliaryCommentAfter |
string |
在输出文件的末尾添加块注释可选字符串 |
|
retainLines |
boolean |
false |
尝试在输出代码中使用与源代码中相同的行号 |
retainFunctionParens |
boolean |
false |
保留表达式周围的括号 |
comments |
boolean |
true |
输出中是否应包含注释 |
compact |
boolean 或’auto' |
opts.minified |
设置为true以避免添加空格进行格式化 |
minified |
boolean |
false |
是否应该压缩后输出 |
比如,如果我们想要和原代码维持相同的代码行,可以使用如下配置:
const { code: output } = generate(ast, {
retainLines: true,
});
console.log(output)运行结果如下:
const a= 3;
let string = "hello";
for (let i = 0; i < a; i++) {
string += "world"
}
console.log("string", string)这时候我们就可以看到,生成的代码中间没有再出现空行了,和原来的代码保持一致的格式。
@babel/traverse的使用
前面我们了解了 AST 的解析,输入任意一段 JavaScript 代码,我们便可以分析出其 AST。但是只了解 AST,我们并不能实现 JavaScript 代码的反混淆。下面我们还需要进—步了解另一个强大的功能,那就是 AST 的遍历和修改。
遍历我们使用的是 @babel/traverse 它可以接收一个 AST,利用 traverse 方法就可以遍历其中的所有节点。在遍历方法中,我们便可以对每个节点进行对应的操作了。
我们先来感受一下遍历的基本实现。新建一个 JavaScript 文件,将其命名为 basic2.js,内容如下:
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import fs from "fs";
const code = fs.readFileSync("codes/code1.js", "utf-8");
let ast = parse(code);
traverse(ast, {
enter(path) {
console.log(path)
},
});这里我们调用了 traverse 方法,给第一个参数传入 AST 对象,给第二个参数定义了相关的处理逻辑,这里声明了一个 enter 方法,它接收 path 参数。这个 enter 方法在每个节点被遍历到时都会被调用,其中 path 里面就包含了当前被遍历到的节点相关信息。这里我们先把 path 输出出来,看看遍历时能拿到代么信息。
运行如下代码:
babel-node basic2.js这时我们看到控制台输出了非常多的内容,调用很多次 log 代表一个 path 对象,我们拿其中一次输出结果看下,内容如下:
可以看到内容比较复杂,这里将不必要的内容省略了。首先,我们可以看到它的类型是 NodePath,拥有 parent、container、node、scope、type 等多个属性。比如 node 属性是一个 Node 类型的对象,和上文说的 Node 是同一类型,它代表当前正在遍历的节点。比如,利用 parent 也能获得一个 Node 类型对象,它代表该节点的父节点。
所以,我们可以利用 path.node 拿到当前对应的 Node 对象,利用 path.parent 拿到当前 Node 对象的父节点。
既然如此,我们便可以使用它来对 Node 进行一些处理。比如,我们可以把值变化一下,原来的代码如下:
const a = 3;
let string = "hello";
for (let i = 0; i < a; i++) {
string += "world";
}
console.log("string", string)我们要想利用修改 AST 的方式对如上代码进行修改,比如修改一下 a 变量和 string 变量的值, 变成如下代码:
const a = 5;
let string = "hi";
for (let i = 0; i < a; i++) {
string += "world";
}
console.log("string", string)我们可以实现这样的逻辑:
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import fs from "fs";
const code = fs.readFileSync("codes/code1.js", "utf-8");
let ast = parse(code);
traverse(ast, {
enter(path) {
let node = path.node;
if (node.type === "NumericLiteral" && node.value === 3) {
node.value = 5;
}
if (node.type === "StringLiteral" && node.value === "hello") {
node.value = "hi";
}
},
});
const { code: output } = generate(ast, {
retainLines: true,
});
console.log(output);这里我们判断了 node 的类型和值,然后将 node 的 value 进行了替换,这样执行完毕 traverse 方法之后, ast 就被更新完毕了。
运行结果如下:
const a = 5;
let string = "hi";
for (let i = 0; i < a; i++) {
string += "world";
}
console.log("string", string)可以看到,原始的 JavaScript 代码就被成功更改了!
另外,除了定义 enter 方法外,我们还可以直接定义对应特定类型的解析方法,这样遇到此类型的节点时,该方法就会被自动调用,用法类似如下:
import traverse from "@babel/traverse";
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import fs from "fs";
const code = fs.readFileSync("codes/code1.js", "utf-8");
let ast = parse(code);
traverse(ast, {
NumericLiteral(path) {
if (path.node.value === 3) {
path.node.value = 5;
}
},
StringLiteral(path) {
if (path.node.value === "hello") {
path.node.value = "hi";
}
},
});运行结果是完全相同的,单独定义特定类型的解析方法会同得更有条理。
另外,我们可以再看下其他的操作方法。比如,删除某个 node,这里可以试着删除最后一行代码对应的节点,此时直接调用 remove 方法即可,用法如下:
import traverse from "@babel/traverse";
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import fs from "fs";
const code = fs.readFileSync("codes/code1.js", "utf-8");
let ast = parse(code);
traverse(ast, {
CallExpression(path) {
let node = path.node;
if (
node.callee.object.name === "console" &&
node.callee.property.name === "log"
) {
path.remove();
}
},
});
const { code: output } = generate(ast, {
retainLines: true,
});
console.log(output);这样我们就可以删除所有的 console.log 语句。
运行结果如下:
const a = 3;
let string = "hello";
for (let i = 0; i < a; i++) {
string += "world";
}上面说了简单的替换和删除,那么如果我们要插入一个节点,该怎么办呢? 插入新节点时,需要先声明一个节点,怎么声明呢?这时候就要用到 types 了。
@babel/types的使用
@babe/types 也是一个 Node.js 包,它里面定义了各种各样的对象,我们可以方便地使用 types 声明一个新的节点。
比如说,这里有这样一个代码:
const a = 1;
我想增加一行代码,将原始的代码变成:
const a = 1; const b = a + 1;
该怎么办呢? 这时候我们可以借助 types 实现如下操作:
import traverse from "@babel/traverse";
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import * as types from "@babel/types";
const code = "const a = 1;";
let ast = parse(code);
traverse(ast, {
VariableDeclaration(path) {
let init = types.binaryExpression(
"+",
types.identifier("a"),
types.numericLiteral(1)
);
let declarator = types.variableDeclarator(types.identifier("b"), init);
let declaration = types.variableDeclaration("const", [declarator]);
path.insertAfter(declaration);
path.stop();
},
});
const { code: output } = generate(ast, {
retainLines: true,
});
console.log(output);运行结果如下:
const a = 1;const b = a + 1;这里我们成功使用 AST 完成了节点的插入,增加了一行代码。
但上面的代码看起来似乎不知道怎么实现的,init、declarator、declaration 都是怎么来的呢?
不用担心,接下来我们详细剖析一下。首先,我们可以把最终想要变换的代码进行 AST 解析,结果如图 11-82 所示。
这时候我们就可以看到第二行代码的节点结构了,现在需要做的就是构造这个节点,需要从内而外依次构造。
首先,看到整行代码对应的节点是 VariableDeclaration。要生成 VariableDeclaration,我们可以借助 types 的 variableDeclaration 方法,二者的差别仅仅是后者的开头字母是小写的。
API 怎么用呢?这就需要查阅官方文档了。我们查到 variableDeclaration 的用法如下:
t.variableDeclaration(kind,declarations)
可以看到,构造它需要两个参数,具体如下。
-
kind:必需,可以是 "var"|"let|"const"。
-
declarations:必需,是 Array<VariableDeclarator>,即 VariableDeclarator 组成的列表。
这里 kind 我们可以确定了,那么 declarations 怎么构造呢?
要构造 declarations,我们需要进一步构造 VariableDeclarator,它也可以借助 types 的 variableDeclarator 方法,用法如下:
t.variableDeclarator(id,init)
它需要 id 和 init 两个参数。
-
id:必需,即 Identifier 对象
-
init:Expression 对象,默认为空。
因此,我们还需要构造 id 和 init。这里 id 其实就是 b 了,我们可以借助于 types 的 identifier 方法来构造。而对于 init,它是 expression,在 AST 中我们可以观察到它是 BinaryExpression 类型,所以我们可以借助于 types 的 binaryExpression 来构造。binaryExpression 的用法如下:
t.binaryExpression(operator, left, right)
它有三个参数,具体如下。
-
operator:必需,"+"|"_"|"/"|"%"|"*"|**"|"&"|"|"|">>"">>>"|"<<"|"^" |"==" "===" |"!=" |"!==" |"in"|"instanceof"|">" |"<"|">=" |"<="。
-
left:必需,Expression,即
operator左侧的表达式。 -
right:必需,Expression,即
operator右侧的表达式。
这里又需要三个参数,operator 就是运算符,left 就是运算符左侧的内容,right 是右侧的内容。后面两个参数都需要是 Expression,根据 AST,这里的 Expression 可以直接声明为 Identifier 和 NumericLiteral,所以文可以分别用 types 的 identifier 和 numericLiteral 创建。
这样梳理清楚后,我们从里到外将代码实现出来,一层一层构造,最后就声明了一个 VariableDeclaration 类型的节点。
最后,调用 path 的 insertAfter 方法便可以成功将节点插入到 path 对应的节点。
这里关于 types 的更多方法,可以参考 https://babeljs.io/docs/en/babel-types/binaryexpression ,这里的很多方法和节点类型都是对应的,利用方法便可以创建一个节点,具体的参数可以查看每个方法的文档。