大规模账号池的搭建
我们在 10.1 节已经提过账号池,要想降低账号被封的风险,同时还能实现大规模爬取,自然而然想到的方法就是分流。在现在的场景中,分流是指将请求分摊到不同的账号上。我们利用分流可以达成下面两个目标。
-
如果单位时间内所有账号的总请求量一定,每次都随机选取一个账号请求,那么账号越多,单个账号访问网站的频率就降低,被封禁的概率也越低。
-
如果单位时间内单个账号的请求量一定,同样是每次随机选取一个账号请求,那么账号越多,单位时间内的总请求量就越大。
所以,利用分流的思想,可以在保证爬取规模的情况下降低单个账号被封的概率。如何实现这个过程?如何维护多个账号的登录信息?这时就要用到账号池了。接下来看看账号池的搭建方法。
案例介绍
图10-9 案例网站的登录页面
用户名和密码还是填入 admin,登录后的页面如图 10-10 所示。
此时如果多次在登录状态下刷新页面,刷新几次后就会发现,页面不再返回任何信息,只显示 “403 Forbidden”,如图 10-11 所示。
此页面对应的状态码是 403,代表当前账号已经被封,无法获取有效内容。过一段时间后,这个账号又可以正常访问该网站,但如果像之前一样多次刷新,会再次被封。虽然这个账号被封,但是新开一个独立的窗口,使用另一个账号(如用户名和密码都为 admin2 的账户)登录,还是可以正常地访页面,如图10-12所示。
图10-10 登录后的页面
图10-11 刷新几次后的页面
图10-12 换一个账号登录
所以说,如果有多个账号,在总请求量一定的情况下,可以将爬取请求分流到多个账号上,可以降低封号的概率。
本节目标
本节的目标就是搭建一个账号池,例如在账号池内维护 100 个账号信息以及对应的 Cookie,并存放到数据库中。每次爬取的时候,随机取用其中一个账号的 Cookie。
这个账号池需要具备如下几个功能。
-
需要保存能登录目标站点的账号和登录后的 Cookie 信息。
-
需要定时检测每个 Cookie 的有效性,如果检测到 Cookie 无效,就删除它并模拟登录生成新的 Cookie。
-
还需要一个接口,即获取随机 Cookie 的接口。账号池在运行中,只需请求该接口,即可随机获得一个 Cookie 并用其爬取数据。
由此可见,账号池需要有自动生成 Cookie、定时检测 Cookie、提供随机 Cookie 这几个核心功能。账号池有了,当然要使用它来爬取本章的案例网站,实现在不封任何一个账号的情况下高效完成全站数据的爬取。
准备工作
请确保已经安装好 Redis 数据库并使其能正常运行,安装方式可以参考 https://setup.scrape.center/redis 。另外需要安装 Python 的 redis-py、requests、selelnium、flask、loguru 和 environs 库,安装命令如下:
pip3 install redis requests selenium flask loguru environs
账号池的架构
账号池的架构和代理池类似,也是分为 4 个核心模块:存储模块、获取模块、检测模块和接口模块,如图 10-13 所示。
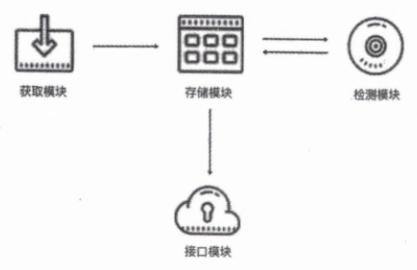
4 个模块的功能分别如下。
-
存储模块负责存储每个账号的用户名、密码,以及每个账号对应的 Cookie 信息,同时需要提供一些实现存取操作的方法。
-
获取模块负责生成新的 Cookie。该模块会从存储模块中逐个拿取账号对应的用户名和密码,然后模拟登录目标页面,如果登录成功,就把返回的 Cookie 交给存储模块存储。
-
检测模块需要定时检测存储模块中的 Cookie。这里需要设置一个检测链接,不同的网站的检测链接不同。检测模块会逐个拿取账号对应的 Cookie 去请求检测链接,如果返回的状态是有效的,就表示此 Cookie 没有失效,否则代表此 Cookie 失效,需要将其删除,然后等待获取模块重新生成。
-
接口模块需要用 API 提供对外服务的接口。由于可用的 Cookie 可能有多个,所以可以随机返回 Cookie 的接口,用这样的方式保证每个 Cookie 都有被取到的可能。Cookie 越多,每个 Cookie 被取到的概率就越小,从而减少了被封号的风险。
以上账号池的基本设计思路和第 9 章讲的代理池有相似之处,下一节我们用代码实现。
账号池架构的实现
首先,分别了解各个模块的实现原理。
存储模块
其实,需要存储的内容无非就是账号信息和 Cookie 信息。账号由用户名和密码两部分组成,我们可以把它存成用户名和密码的映射。Cookie 可以存成字符串,但是新的 Cookie 需要根据账号生成,在生成的时候我们需要知道哪些账号已经生成了 Cookie,哪些没有,所以要同时保存和 Cookie 对应的用户名信息,其实也是用户名和 Cookie 的映射。加起来就是两组映射,我们自然而然能够想到 Redis 的 Hash,于是就建立两个 Hash,结构分别如图 10-14 和图 10-15 所示。
图10-14 Hash结构1
图10-15 Hash结构2
两个 Hash 结构中的键名都是用户名,键值分别是密码和 Cookie。需要注意,账号池具有可扩展性,其中存储的一些账号和 Cookie 不一定适用于本案例,其他网站也可以对接此账号池,所以这里可以对 Hash 结构的名称做二级分类,例如把存账号的 Hash 结构的名称设置为 account:antispider6,把存 Cookie 信息的 Hash 名称设置为 credential:antispider6。如果要扩展微博的账号池,可以使用 account:webo 和 credential:weibo,这样比较方便。
接下来我们就创建一个存储模块类,用来提供一些 Hash 结构的基本操作,代码如下:
import random
import redis
from accountpool.setting import *
class RedisClient(object):
def __init__(self, type, website, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD):
self.db = redis.StrictRedis(host=host, port=port, password=password, decode_responses=True)
self.type = type
self.website = website
def name(self):
return f'{self.type}:{self.website}'
def set(self, username, value):
return self.db.hset(self.name(), username, value)
def get(self, username):
return self.db.hget(self.name(), username)
def delete(self, username):
return self.db.hdel(self.name(), username)
def count(self):
return self.db.hlen(self.name())
def random(self):
return random.choice(self.db.hvals(self.name()))
def usernames(self):
return self.db.hkeys(self.name())
def all(self):
return self.db.hgetall(self.name())这里我们新建了一个 RedisClient 类,其构造方法 init 有 type 和 website 两个关键参数,分别代表存储的内容类型和网站名称,是用来拼接 Hash 结构名称的两个字段。如果这个 Hash 是用来存储账号的,那么 type 是 account,website 是 antispider6;如果是用来存储 Cookie 的,那么 type 是 credential,website 是 antispider6。剩下几个参数代表 Redis 的连接信息,给这些参数传入值来初始化一个 StrictRedis 对象,建立 Redis 连接。
接下来的 name 方法将 type 和 website 拼接在了一起,组成 Hash 结构的名称。set 方法、get 方法和 delete 方法分别代表设置、获取和删除 Hash 结构中的某一个键值对,count 方法用于获取 Hash 结构的长度。
random 也是一个比较重要的方法,主要用于从 Hash 结构里随机选取一个 Cookie 并返回。每调用一次 random 方法,就会获得一个随机的 Cookie,将此方法与接口模块对接即可实现请求接口获取随机 Cookie。
获取模块
获取模块负责从存储模块中拿取各个账号信息并模拟登录,然后将登录成功后生成的 Cookie 保存到存储模块中。相关代码如下:
from accountpool.exceptions.init import InitException
from accountpool.storages.redis import RedisClient
from loguru import logger
class BaseGenerator(object):
def __init__(self, website=None):
self.website = website
if not self.website:
raise InitException
self.account_operator = RedisClient(type='account', website=self.website)
self.credential_operator = RedisClient(type='credential', website=self.website)
def generate(self, username, password):
raise NotImplementedError
def init(self):
pass
def run(self):
self.init()
logger.debug('start to run generator')
for username, password in self.account_operator.all().items():
if self.credential_operator.get(username):
continue
logger.debug(f'start to generate credential of {username}')
self.generate(username, password)这里新建了一个基类 BaseGenerator,在其构造方法中,初始化了两个 RedisClient 对象,分别是 account_operator 和 credential_operator。
接着声明了 generate 方法和 init 方法,这两个方法目前都没有具体的实现。generate 方法用于接收用户名和密码,生成 Cookie 并返回,这里直接抛出了 NotImplementedError 异常,因此子类必须实现该方法,否则运行时会报错。init 方法则是在运行开始之前做一些准备工作,这里留空,子类可以选择性复写。
最后就是最主要的 run 方法了,其主要逻辑是找出那些还没有对应 Cookie 信息的账号,然后逐个调用 generate 方法获取 Cookie。
对于本节的案例网站,我们可以直接实现 generate 方法来完成模拟登录。代码如下:
class Antispider6Generator(BaseGenerator):
def generate(self, username, password):
if self.credential_operator.get(username):
logger.debug(f'credential of {username} exists, skip')
return
login_url = 'https://antispider6.scrape.center/login'
s = requests.Session()
s.post(login_url, data={
'username': username,
'password': password
})
result = []
for cookie in s.cookies:
print(cookie.name, cookie.value)
result.append(f'{cookie.name}={cookie.value}')
result = ';'.join(result)
logger.debug(f'get credential {result}')
self.credential_operator.set(username, result)运行这段代码,会遍历那些生成 Cookie 的账号,然后模拟登录生成新的 Cookie。
检测模块
我们现在可以利用获取模块生成 Cookie 了,但是免不了由于时间过长或者使用过于频繁等导致 Cookie 失效。对于这样的 Cookie,肯定不能把它继续保存在存储模块里。
此时检测模块闪亮登场,它要做的就是检测出失效 Cookie,然后将其从存储模块中删除。把失效 Cookie 删除后,获取模块就会检测到与之对应的账号没有了 Cookie 信息,继而用此账号重新模拟登录获取新的 Cookie,从而实现了此账号对应 Cookie 的更新。相关代码如下:
import requests
from requests.exceptions import ConnectionError
from accountpool.storages.redis import RedisClient
from accountpool.exceptions.init import InitException
from loguru import logger
class BaseTester(object):
def __init__(self, website=None):
self.website = website
if not self.website:
raise InitException
self.account_operator = RedisClient(type='account', website=self.website)
self.credential_operator = RedisClient(type='credential', website=self.website)
def test(self, username, credential):
raise NotImplementedError
def run(self):
credentials = self.credential_operator.all()
for username, credential in credentials.items():
self.test(username, credential)为了实现通用性和可扩展性,我们定义了一个检测器父类,在其中声明一些通用组件。这个父类叫做 BaseTester,在其构造方法里指定了网站的名称 website,并且同样初始化了两个 RedisClient 对象,分别是 account_operator 和 credential_operator。
然后最主要的方法就是 run 了,其主要逻辑是遍历所有 Cookie 并逐个做测试,具体是利用 credential_operator 拿到所有的 Cookie,然后调用 test 方法进行测试。这里的 test 方法同样抛出了 NotImplementedError 异常,所以子类必须实现这个方法。下面我们再写一个子类继承这个 BaseTester,并重写其 test 方法,代码如下:
class Antispider6Tester(BaseTester):
def __init__(self, website=None):
BaseTester.__init__(self, website)
def test(self, username, credential):
logger.info(f'testing credential for {username}')
try:
test_url = TEST_URL_MAP[self.website]
response = requests.get(test_url, headers={
'Cookie': credential
}, timeout=5, allow_redirects=False)
if response.status_code == 200:
logger.info('credential is valid')
else:
logger.info('credential is not valid, delete it')
self.credential_operator.delete(username)
except ConnectionError:
logger.info('test failed')test 方法的主要逻辑是拿到测试 URL,然后获取 Cookie 进行模拟登录。如果返回的状态码是 200,就证明 Cookie 有效,否则 Cookie 无效,将其对应的记录删除。
为了实现可配置化,我们们将测试 URL 也定义成字典,代码如下:
TEST_URL_MAP = {
'antispider6': 'https://antispider6.scrape.center/'
}如果要扩展其他网站,可以统一添加在字典里。
接口模块
如果获取模块和检测模块决定时运行,就可以完成 Cookie 的实时检测和更新。此处的 Cookie 最终是要为爬虫所用的,一个账号池可同时供多个爬虫使用,所以我们有必要定义一个 Web 接口,爬虫访问此接口便可以获取随机的 Cookie。我们采用 Flask 来实现接口的搭建,代码如下:
import json
from flask import Flask, g
app = Flask(__name__)
GENERATOR_MAP = {
'antispider6': 'Antispider6Generator'
}
@app.route('/')
def index():
return '<h2>Welcome to Cookie Pool System</h2>'
def get_conn():
for website in GENERATOR_MAP:
if not hasattr(g, website):
setattr(g, f'{website}_credential', RedisClient(credential, website))
setattr(g, f'{website}_account', RedisClient(account, website))
return g
@app.route('/<website>/random')
def random(website):
g = get_conn()
result = getattr(g, f'{website}_credential').random()
logger.debug(f'get credential {result}')
return result这里同样需要实现通用的配置以对接不同的站点,所以接口链接的第一个字段定义为网站名称,第二个字段定义为获取方法,例如 /antispider/random 代表获取当前案例网站的随机 Cookie,如果要扩展其他站点,可以更改 website 参数,例如 /weibo/random 代表获取微博的随机 Cookie。
调度模块
调度模块的作用是让前面 4 个模块配合运行,主要工作是驱动几个模块定时运行,同时各个模块需要运行在不同进程上,相关代码如下:
import time
import multiprocessing
from accountpool.processors.server import app
from accountpool.processors import generator as generators
from accountpool.processors import tester as testers
from accountpool.setting import CYCLE_GENERATOR, CYCLE_TESTER, API_HOST, API_THREADED, API_PORT, \
ENABLE_SERVER, ENABLE_GENERATOR, ENABLE_TESTER, IS_WINDOWS, TESTER_MAP, GENERATOR_MAP
from loguru import logger
if IS_WINDOWS:
multiprocessing.freeze_support()
tester_process, generator_process, server_process = None, None, None
class Scheduler(object):
def run_tester(self, website, cycle=CYCLE_TESTER):
if not ENABLE_TESTER:
logger.info('tester not enabled, exit')
return
tester = getattr(testers, TESTER_MAP[website])(website)
loop = 0
while True:
logger.debug(f'tester loop {loop} start...')
tester.run()
loop += 1
time.sleep(cycle)
def run_generator(self, website, cycle=CYCLE_GENERATOR):
if not ENABLE_GENERATOR:
logger.info('getter not enabled, exit')
return
generator = getattr(generators, GENERATOR_MAP[website])(website)
loop = 0
while True:
logger.debug(f'getter loop {loop} start...')
generator.run()
loop += 1
time.sleep(cycle)
def run_server(self, _):
if not ENABLE_SERVER:
logger.info('server not enabled, exit')
return
app.run(host=API_HOST, port=API_PORT, threaded=API_THREADED)
def run(self, website):
global tester_process, generator_process, server_process
try:
logger.info('starting account pool...')
if ENABLE_TESTER:
tester_process = multiprocessing.Process(target=self.run_tester, args=(website,))
logger.info(f'starting tester, pid {tester_process.pid}...')
tester_process.start()
if ENABLE_GENERATOR:
generator_process = multiprocessing.Process(target=self.run_generator, args=(website,))
logger.info(f'starting getter, pid {generator_process.pid}...')
generator_process.start()
if ENABLE_SERVER:
server_process = multiprocessing.Process(target=self.run_server, args=(website,))
logger.info(f'starting server, pid {server_process.pid}...')
server_process.start()
tester_process.join()
generator_process.join()
server_process.join()
except KeyboardInterrupt:
logger.info('received keyboard interrupt signal')
tester_process.terminate()
generator_process.terminate()
server_process.terminate()
finally:
tester_process.join()
generator_process.join()
server_process.join()
logger.info(f'tester is {"alive" if tester_process.is_alive() else "dead"}')
logger.info(f'getter is {"alive" if generator_process.is_alive() else "dead"}')
logger.info(f'server is {"alive" if server_process.is_alive() else "dead"}')
logger.info('accountpool terminated')这里用到了两个重要的配置,即产生模块类和测试模块类的字典配置,代码如下:
# 产生模块类的字典配置
GENERATOR_MAP = {
'antispider6': 'Antispider6Generator'
}
# 测试模块类的字典配置
TESTER_MAP = {
'antispider6': 'Antispider6Tester'
}这样的配置是为了方便动态扩展,键名为网站名称,键值为类名。如果要扩展其他站点,可以在字典中添加,例如扩展微博的产生模块可以配置成这样:
GENERATOR_MAP = {
'weibo': 'WeiboCookiesGenerator',
'antispider6': 'Antispider6Generator'
}在 Scheduler 类里对字典进行遍历,利用 module 的 getattr 方法获取对应的类,调用其入口 run 方法运行各个模块。同时,各个模块的多进程使用了 multiprocessing 中的 Process 类,调用其 start 方法即可启动各个进程。
另外,各个模块还没有模块开关,可以在配置文件中自由设置此开关的开启和关闭,代码如下:
from environs import Env
env = Env()
env.read_env()
ENABLE_TESTER = env.bool('ENABLE_TESTER', True)
ENABLE_GENERATOR = env.bool('ENABLE_GENERATOR', True)
ENABLE_SERVER = env.bool('ENABLE_SERVER', True)设置为 True 代表开启模块,为 False 则代表关闭模块,这里借助了 environs 库来实现测试。至此,我们所有的配置都完成了。接下来将所有模块同时开启,启动调度器,命令如下所示:
python3 run.py antispider6控制台的输出结果如下:
2020-10-13 00:34:27.308 | DEBUG | accountpool.scheduler:run_tester:31 - tester loop 0 start...
* Serving Flask app "accountpool.processors.server" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
2020-10-13 00:34:27.309 | DEBUG | accountpool.processors.generator:run:39 - start to run generator
2020-10-13 00:34:27.309 | INFO | accountpool.processors.tester:test:51 - testing credential for admin
2020-10-13 00:34:27.310 | DEBUG | accountpool.processors.generator:generate:41 - start to generate
credential of admin2
2020-10-13 00:34:27.310 | DEBUG | accountpool.processors.generator:generate:63 - credential of
admin exists, skip
2020-10-13 00:34:27.310 | DEBUG | accountpool.processors.generator:generate:41 - start to generate
credential of admin2
2020-10-13 00:34:27.310 | DEBUG | accountpool.processors.generator:generate:63 - credential of
admin2 exists, skip
2020-10-13 00:34:27.310 | DEBUG | accountpool.processors.generator:generate:41 - start to generate
credential of admin3
* Running on http://0.0.0.0:6789/ (Press CTRL+C to quit)
2020-10-13 00:34:32.073 | INFO | accountpool.processors.tester:test:58 - credential is valid
2020-10-13 00:34:32.073 | INFO | accountpool.processors.tester:test:51 - testing credential for admin2
2020-10-13 00:34:32.678 | DEBUG | accountpool.processors.generator:generate:76 - get credential
2020-10-13 00:34:32.680 | DEBUG | accountpool.processors.generator:generate:41 - start to generate
credential of admin4从控制台的输出内容可以看出,各个模块都正常启动,检测模块逐个测试 Cookie,获取模块获取尚未生成 Cookie 的账号,各个模块并行运行,互不干扰。
我们可以访问接口模块获取随机的 Cookie,如图 10-16 所示。
图10-16 访问接口模块
爬虫只需要请求该接口就可以获取随机的 Cookie。
账号池的使用
我们先将账号池运行一段时间,让其模拟登录一些账号并维护起来。接着便可以使用账号池实现全站数据的爬取了。这里我们使用 aiohttp 来实现,由于案例网站中每个电影详情页的 URL 是有一定规律的,所以我们直接构造 100 个详情页 URL 进行爬取,整体代码实现如下:
import asyncio
import aiohttp
from pyquery import PyQuery as pq
from loguru import logger
MAX_ID = 100
CONCURRENCY = 5
TARGET_URL = 'https://antispider6.scrape.center'
ACCOUNTPOOL_URL = 'http://localhost:6789/antispider6/random'
semaphore = asyncio.Semaphore(CONCURRENCY)
async def parse_detail(html):
doc = pq(html)
title = doc('.item h2').text()
categories = [item.text() for item in doc('.item .categories span').items()]
cover = doc('.item .cover').attr('src')
score = doc('.item .score').text()
drama = doc('.item .drama').text().strip()
return {
'title': title,
'categories': categories,
'cover': cover,
'score': score,
'drama': drama
}
async def fetch_credential(session):
async with session.get(ACCOUNTPOOL_URL) as response:
return await response.text()
async def scrape_detail(session, url):
async with semaphore:
credential = await fetch_credential(session)
headers = {'Cookie': credential}
logger.debug(f'scrape {url} using credential {credential}')
async with session.get(url, headers=headers) as response:
html = await response.text()
data = await parse_detail(html)
logger.debug(f'data {data}')
async def main():
session = aiohttp.ClientSession()
tasks = []
for i in range(1, MAX_ID + 1):
url = f'{TARGET_URL}/detail/{i}'
task = asyncio.ensure_future(scrape_detail(session, url))
tasks.append(task)
await asyncio.gather(*tasks)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())我们一共实现了 4 个方法。
-
main:入口方法。这里我们构造了 100 个详情页 URL,然后调用asyncio的ensure_future方法将scrape_detail方法初始化为一个个异步任务,再调用gather方法使它们运行起来。 -
scrape_detail:爬取方法。主要用来爬取详情页的信息,这里的关键点就是在爬取之前先调用fetch_credential方法获取一个 Cookie,然后利用 Cookie 进行数据爬取。如果不这样做,是爬取不到任何数据的,爬取完毕之后会调用parse_detail方法对页面数据进行解析。 -
fetch_credential:主要用来从账号池获取 Cookie 信息。这里我们将账号池的 API 为定义ACCOUNTPOOL_URL,每请求一次,就可以获取一个 Cookie。 -
parse_detail:解析方法。主要用来解析爬取的详情页,提取想要的电影名称、类别、封面、评分和简介等信息。
另外,为了限制爬取速度,这里还引入了信号量,限制并发量为 5。
上述的运行结果如下:
2020-10-14 00:51:40.685 | DEBUG | _main_:scrape_detail:39 - scrape https://antispider6.scrape.center/
detail/1 using credential sessionid=ht4uwjbf1o28qmqo8j87ozddm1kgzcqn
2020-10-14 00:51:40.695 | DEBUG | _main_:scrape_detail:39 - scrape https://antispider6.scrape.center/
detail/3 using credential sessionid=1mawdt4fpqw14jmgcyjtgrwyeprtfn6ui
2020-10-14 00:51:40.695 | DEBUG | _main_:scrape_detail:39 - scrape https://antispider6.scrape.center/
detail/5 using credential sessionid=nb1e6tmv7bfm0kokc1ot16o8lck8qp9m
2020-10-14 00:51:40.696 | DEBUG | _main_:scrape_detail:39 - scrape https://antispider6.scrape.center/
detail/2 using credential sessionid=dhiaxb1zd8xqaf8p7vygqvwbm4teueid
2020-10-14 00:51:40.696 | DEBUG | _main_:scrape_detail:39 - scrape https://antispider6.scrape.center/
detail/4 using credential sessionid=a3hcakqpszw73lwqktdbar4g190nayh1
2020-10-14 00:51:49.121 | DEBUG | _main_:scrape_detail:43 - data {'title': '泰坦尼克号 - Titanic',
'categories': ['剧情', '爱情', '灾难'], 'cover': 'https://p1.meituan.net/movie/b607fba7513e7f15eab170
aacle1400d878112.jpg@464w_644h_1e_1c', 'score': '9.5', 'drama': '...剧情简介^n1912 年 4 月 15 日,...让它
陪着杰克和Rose爱情长眠海底。'}
2020-10-14 00:51:49.127 | DEBUG | _main_:scrape_detail:39 - scrape https://antispider6.scrape.center/
detail/6 using credential sessionid=f1w5k8z3vo7d89mb1mmy2jsocejk63qz
2020-10-14 00:51:52.126 | DEBUG | _main_:scrape_detail:43 - data {'title': '这个杀手不太冷 - Léon',
'categories': ['剧情', '动作', '犯罪'], 'cover': 'https://p1.meituan.net/movie/6bea9af4524dfbd0b668eaa
7e187c3df767253.jpg@464w_644h_1e_1c', 'score': '9.5', 'drama': '剧情简介^n豆瓣译(让-雷诺饰)是名孤独的
职业杀手。...更久的冲突在所难免...'}
2020-10-14 00:51:52.129 | DEBUG | _main_:scrape_detail:39 - scrape https://antispider6.scrape.center/
detail/7 using credential sessionid=dqdbflf1rflica9j8i5fcncy9nvqcw1b可以看到此时的并发量被限制为了 5,每次爬取都会获取一个 Cookie,接着便会打印爬取的结果,不会再产生封号问题。