RocketMQ 存储文件
RocketMQ存储路径为${ROCKET_HOME}/store,主要存储文件如图4-14所示。下面介绍RocketMQ主要的存储文件夹。
1)commitlog:消息存储目录。 2)config:运行期间的一些配置信息,主要包括下列信息。
-
consumerFilter.json:主题消息过滤信息。
-
consumerOffset.json:集群消费模式下的消息消费进度。
-
delayOffset.json:延时消息队列拉取进度。
-
subscriptionGroup.json:消息消费组的配置信息。
-
topics.json:topic配置属性。
3)consumequeue:消息消费队列存储目录。 4)index:消息索引文件存储目录。 5)abort:如果存在abort文件,说明Broker非正常关闭,该文件默认在启动Broker时创建,在正常退出之前删除。 6)checkpoint:检测点文件,存储CommitLog文件最后一次刷盘时间戳、ConsumeQueue最后一次刷盘时间、index文件最后一次刷盘时间戳。
CommitLog文件
CommitLog目录的结构在4.4节已经详细介绍过了,该目录下的文件主要用于存储消息,其特点是每一条消息长度不相同。CommitLog文件存储格式如图4-15所示,每条消息的前面4个字节存储该条消息的总长度。

CommitLog文件的存储目录默认为${ROCKET_HOME}/store/commitlog,可以通过在broker配置文件中设置storePathRootDir属性改变默认路径,如代码清单4-30所示。CommitLog文件默认大小为1GB,可通过在broker配置文件中设置mapedFileSizeCommitLog属性改变默认大小。本节将基于上述存储结构,重点分析消息的查找实现。
public long getMinOffset() {
MappedFile mappedFile = this.mappedFileQueue.getFirstMappedFile();
if (mappedFile != null) {
if (mappedFile.isAvailable()) {
return mappedFile.getFileFromOffset();
} else {
return this.rollNextFile(mappedFile.getFileFromOffset());
}
}
return -1;
}获取当前CommitLog目录的最小偏移量,首先获取目录下的第一个文件,如果该文件可用,则返回该文件的起始偏移量,否则返回下一个文件的起始偏移量,如代码清单4-31所示。
public long rollNextFile(final long offset) {
int mappedFileSize = this.defaultMessageStore.getMessageStoreConfig().getMapedFileSizeCommitLog();
return offset + mappedFileSize - offset % mappedFileSize;
}根据offset返回下一个文件的起始偏移量。获取一个文件的大小,减去offset % mapped-FileSize,回到下一文件的起始偏移量,如代码清单4-32所示。
public SelectMappedBufferResult getMessage(final long offset, final int size) {
int mappedFileSize = this.defaultMessageStore.getMessageStoreConfig().getMapedFileSizeCommitLog();
MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset, offset == 0);
if (mappedFile != null) {
int pos = (int) (offset % mappedFileSize);
return mappedFile.selectMappedBuffer(pos, size);
}
return null;
}根据偏移量与消息长度查找消息。首先根据偏移找到文件所在的物理偏移量,然后用offset与文件长度取余,得到在文件内的偏移量,从该偏移量读取size长度的内容并返回。如果只根据消息偏移量查找消息,则首先找到文件内的偏移量,然后尝试读取4字节,获取消息的实际长度,最后读取指定字节。
ConsumeQueue文件
RocketMQ基于主题订阅模式实现消息消费,消费者关心的是一个主题下的所有消息,但同一主题的消息是不连续地存储在CommitLog文件中的。如果消息消费者直接从消息存储文件中遍历查找订阅主题下的消息,效率将极其低下。RocketMQ为了适应消息消费的检索需求,设计了ConsumeQueue文件,该文件可以看作CommitLog关于消息消费的“索引”文件,ConsumeQueue的第一级目录为消息主题,第二级目录为主题的消息队列,如图4-16所示。

为了加速ConsumeQueue消息条目的检索速度并节省磁盘空间,每一个ConsumeQueue条目不会存储消息的全量信息,存储格式如图4-17所示。
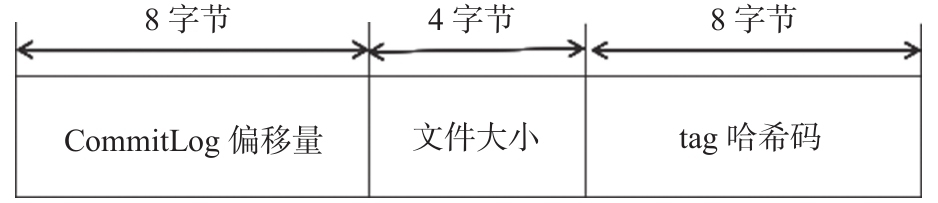
单个ConsumeQueue文件中默认包含30万个条目,单个文件的长度为3×106 ×20字节,单个ConsumeQueue文件可以看作一个ConsumeQueue条目的数组,其下标为ConsumeQueue的逻辑偏移量,消息消费进度存储的偏移量即逻辑偏移量。ConsumeQueue即为CommitLog文件的索引文件,其构建机制是当消息到达CommitLog文件后,由专门的线程产生消息转发任务,从而构建ConsumeQueue文件与下文提到的Index文件,如代码清单4-33所示。本节只分析如何根据消息逻辑偏移量、时间戳查找消息,4.6节将重点讨论消息消费队列的构建、恢复等内容。
public SelectMappedBufferResult getIndexBuffer(final long startIndex) {
int mappedFileSize = this.mappedFileSize;
long offset = startIndex * CQ_STORE_UNIT_SIZE;
if (offset >= this.getMinLogicOffset()) {
MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset);
if (mappedFile != null) {
SelectMappedBufferResult result = mappedFile.selectMappedBuffer((int) (offset % mappedFileSize));
return result;
}
}
return null;
}根据startIndex获取消息消费队列条目。通过startIndex×20得到在ConsumeQueue文件的物理偏移量,如果该偏移量小于minLogicOffset,则返回null,说明该消息已被删除,如果大于minLogicOffset,则根据偏移量定位到具体的物理文件。通过将该偏移量与物理文件的大小取模获取在该文件的偏移量,从偏移量开始连续读取20个字节即可。
ConsumeQueue文件提供了根据消息存储时间来查找具体实现的算法getOffsetInQueue-ByTime(final long timestamp),其具体实现如下。 第一步:根据时间戳定位到物理文件,就是从第一个文件开始,找到第一个文件更新时间大于该时间戳的文件,如代码清单4-34所示。
int low = minLogicOffset > mappedFile.getFileFromOffset()
? (int) (minLogicOffset - mappedFile.getFileFromOffset())
: 0;
int high = 0;
int midOffset = -1, targetOffset = -1, leftOffset = -1, rightOffset = -1;
long leftIndexValue = -1L, rightIndexValue = -1L;
long minPhysicOffset = this.defaultMessageStore.getMinPhyOffset();
SelectMappedBufferResult sbr = mappedFile.selectMappedBuffer(0);
if (null != sbr) {
ByteBuffer byteBuffer = sbr.getByteBuffer();
high = byteBuffer.limit() - CQ_STORE_UNIT_SIZE;
}第二步:采用二分查找来加速检索。首先计算最低查找偏移量,取消息队列最小偏移量与该文件注销偏移量的差为最小偏移量low。获取当前存储文件中有效的最小消息物理偏移量minPhysicOffset,如果查找到的消息偏移量小于该物理偏移量,则结束该查找过程,如代码清单4-35所示。
while (high >= low) {
midOffset = (low + high) / (2 * CQ_STORE_UNIT_SIZE) * CQ_STORE_UNIT_SIZE;
byteBuffer.position(midOffset);
long phyOffset = byteBuffer.getLong();
int size = byteBuffer.getInt();
if (phyOffset < minPhysicOffset) {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
continue;
}
long storeTime = this.defaultMessageStore.getCommitLog()
.pickupStoreTimestamp(phyOffset, size);
if (storeTime < 0) {
return 0;
} else if (storeTime == timestamp) {
targetOffset = midOffset;
break;
} else if (storeTime > timestamp) {
high = midOffset - CQ_STORE_UNIT_SIZE;
rightOffset = midOffset;
rightIndexValue = storeTime;
} else {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
leftIndexValue = storeTime;
}
}二分查找的常规退出循环为low>high,首先查找中间的偏移量midOffset,将ConsumeQueue文件对应的ByteBuffer定位到midOffset,然后读取4个字节,获取该消息的物理偏移量,如代码清单4-36所示。 1)如果得到的物理偏移量小于当前的最小物理偏移量,说明待查找消息的物理偏移量肯定大于midOffset,则将low设置为midOffset,继续折半查找。 2)如果得到的物理偏移量大于最小物理偏移量,说明该消息是有效消息,则根据消息偏移量和消息长度获取消息的存储时间戳。 3)如果存储时间小于0,则为无效消息,直接返回0。 4)如果存储时间戳等于待查找时间戳,说明查找到了匹配消息,则设置targetOffset并跳出循环。 5)如果存储时间戳大于待查找时间戳,说明待查找消息的物理偏移量小于midOffset,则设置high为midOffset,并设置rightIndexValue等于midOffset。 6)如果存储时间戳小于待查找时间戳,说明待查找消息的物理偏移量大于midOffset,则设置low为midOffset,并设置leftIndexValue等于midOffset。
if (targetOffset != -1) {
offset = targetOffset;
} else {
if (leftIndexValue == -1) {
offset = rightOffset;
} else if (rightIndexValue == -1) {
offset = leftOffset;
} else {
offset = Math.abs(timestamp - leftIndexValue) > Math.abs(timestamp - rightIndexValue)
? rightOffset : leftOffset;
}
}
return (mappedFile.getFileFromOffset() + offset) / CQ_STORE_UNIT_SIZE;第三步:如果targetOffset不等于-1,表示找到了存储时间戳等于待查找时间戳的消息。如果leftIndexValue等于-1,表示返回当前时间戳大于待查找消息的时间戳,并且最接近待查找消息的偏移量。如果rightIndexValue等于-1,表示返回的时间戳比待查找消息的时间戳小,并且最接近待查找消息的偏移量,如代码清单4-37所示。
public long rollNextFile(final long index) {
int mappedFileSize = this.mappedFileSize;
int totalUnitsInFile = mappedFileSize / CQ_STORE_UNIT_SIZE;
return index + totalUnitsInFile - index % totalUnitsInFile;
}根据当前偏移量获取下一个文件的起始偏移量。首先获取文件包含多少个消息消费队列条目,减去index%totalUnitsInFile的目的是选中下一个文件的起始偏移量。
index文件
ConsumeQueue是RocketMQ专门为消息订阅构建的索引文件,目的是提高根据主题与消息队列检索消息的速度。另外,RocketMQ引入哈希索引机制为消息建立索引,HashMap的设计包含两个基本点:哈希槽与哈希冲突的链表结构。RocketMQ索引文件Index存储格式如图4-18所示。
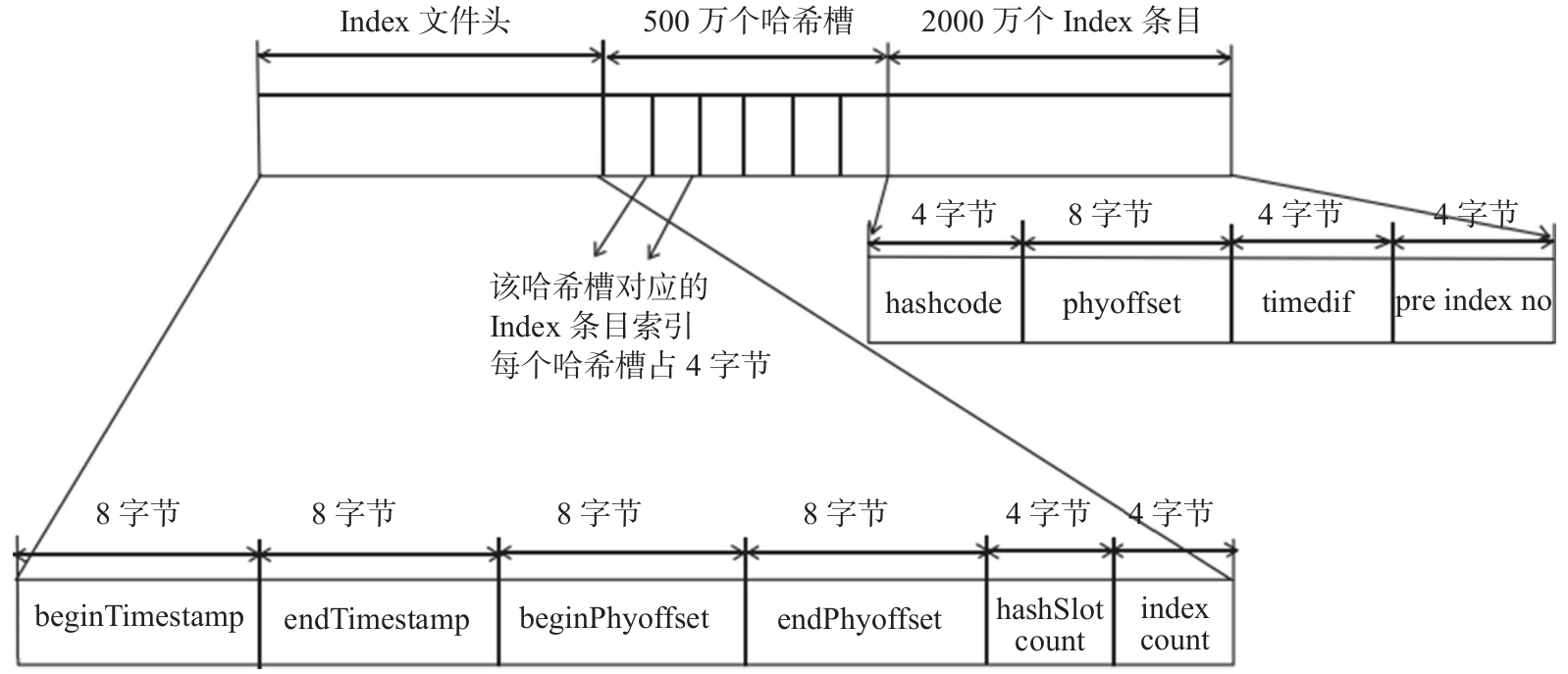
从图4-20可以看出,Index包含Index文件头、哈希槽、Index条目(数据)。Index文件头包含40字节,记录该Index的统计信息,其结构如下。
1)beginTimestamp:Index文件中消息的最小存储时间。 2)endTimestamp:Index文件中消息的最大存储时间。 3)beginPhyoffset:Index文件中消息的最小物理偏移量(CommitLog文件偏移量)。 4)endPhyoffset:Index文件中消息的最大物理偏移量(CommitLog文件偏移量)。 5)hashslotCount:hashslot个数,并不是哈希槽使用的个数,在这里意义不大。 6)indexCount:Index条目列表当前已使用的个数,Index条目在Index条目列表中按顺序存储。 一个Index默认包含500万个哈希槽。哈希槽存储的是落在该哈希槽的哈希码最新的Index索引。默认一个Index文件包含2000万个条目,每个Index条目结构如下。 1)hashcode:key的哈希码。 2)phyoffset:消息对应的物理偏移量。 3)timedif:该消息存储时间与第一条消息的时间戳的差值,若小于0,则该消息无效。 4)pre index no:该条目的前一条记录的Index索引,当出现哈希冲突时,构建链表结构。
接下来重点分析如何将Map<String/消息索引key/,long phyOffset/消息物理偏移量/>存入Index文件,以及如何根据消息索引key快速查找消息。
RocketMQ将消息索引键与消息偏移量的映射关系写入Index的实现方法为public booleanputKey(final String key, final long phyOffset, final long storeTimestamp),参数含义分别为消息索引、消息物理偏移量、消息存储时间,如代码清单4-38所示。
if (this.indexHeader.getIndexCount() < this.indexNum) {
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
}第一步:当前已使用条目大于、等于允许最大条目数时,返回fasle,表示当前Index文件已写满。如果当前index文件未写满,则根据key算出哈希码。根据keyHash对哈希槽数量取余定位到哈希码对应的哈希槽下标,哈希码对应的哈希槽的物理地址为IndexHeader(40字节)加上下标乘以每个哈希槽的大小(4字节),如代码清单4-39所示。
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}第二步:读取哈希槽中存储的数据,如果哈希槽存储的数据小于0或大于当前Index文件中的索引条目,则将slotValue设置为0,如代码清单4-40所示。
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}第三步:计算待存储消息的时间戳与第一条消息时间戳的差值,并转换成秒,如代码清单4-41所示。
int absIndexPos = IndexHeader.INDEX_HEADER_SIZE
+ this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());第四步:将条目信息存储在Index文件中。 1)计算新添加条目的起始物理偏移量:头部字节长度+哈希槽数量×单个哈希槽大小(4个字节)+当前Index条目个数×单个Index条目大小(20个字节)。 2)依次将哈希码、消息物理偏移量、消息存储时间戳与Index文件时间戳、当前哈希槽的值存入MappedByteBuffer。 3)将当前Index文件中包含的条目数量存入哈希槽中,覆盖原先哈希槽的值。 以上是哈希冲突链式解决方案的关键实现,哈希槽中存储的是该哈希码对应的最新Index条目的下标,新的Index条目最后4个字节存储该哈希码上一个条目的Index下标。如果哈希槽中存储的值为0或大于当前Index文件最大条目数或小于-1,表示该哈希槽当前并没有与之对应的Index条目。值得注意的是,Index文件条目中存储的不是消息索引key,而是消息属性key的哈希,在根据key查找时需要根据消息物理偏移量找到消息,进而验证消息key的值。之所以只存储哈希,而不存储具体的key,是为了将Index条目设计为定长结构,才能方便地检索与定位条目,如代码清单4-42所示。
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
this.indexHeader.incHashSlotCount();
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);第五步:更新文件索引头信息。如果当前文件只包含一个条目,则更新beginPhyOffset、beginTimestamp、endPyhOffset、endTimestamp以及当前文件使用索引条目等信息,如代码清单4-43所示。 RocketMQ根据索引key查找消息的实现方法为selectPhyOffset(List<Long> phy Offsets,String key, int maxNum,long begin, long end),其参数说明如下。 1)List<Long> phyOffsets:查找到的消息物理偏移量。 2)String key:索引key。 3)int maxNum:本次查找最大消息条数。 4)long begin:开始时间戳。 5)long end:结束时间戳。
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;第一步:根据key算出key的哈希码,keyHash对哈希槽数量取余,定位到哈希码对应的哈希槽下标,哈希槽的物理地址为IndexHeader(40字节)加上下标乘以每个哈希槽的大小(4字节),如代码清单4-44所示。
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()
|| this.indexHeader.getIndexCount() <= 1) {
// 返回;
}第二步:如果对应的哈希槽中存储的数据小于1或大于当前索引条目个数,表示该哈希码没有对应的条目,直接返回,如代码清单4-45所示。
for (int nextIndexToRead = slotValue; ; ){
// 省略部分代码
}第三步:因为会存在哈希冲突,所以根据slotValue定位该哈希槽最新的一个Item条目,将存储的物理偏移量加入phyOffsets,然后继续验证Item条目中存储的上一个Index下标,如果大于、等于1并且小于当前文件的最大条目数,则继续查找,否则结束查找,如代码清单4-46所示。
int absIndexPos = IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum *
hashSlotSize + nextIndexToRead * indexSize;
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);第四步:根据Index下标定位到条目的起始物理偏移量,然后依次读取哈希码、物理偏移量、时间戳、上一个条目的Index下标,如代码清单4-47所示。
if (timeDiff < 0) {
break;
}
timeDiff *= 1000L;
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
if (keyHash == keyHashRead && timeMatched) {
phyOffsets.add(phyOffsetRead);
}
if (prevIndexRead <= invalidIndex || prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
nextIndexToRead = prevIndexRead;第五步:如果存储的时间戳小于0,则直接结束查找。如果哈希匹配并且消息存储时间介于待查找时间start、end之间,则将消息物理偏移量加入phyOffsets,并验证条目的前一个Index索引,如果索引大于、等于1并且小于Index条目数,则继续查找,否则结束查找。
