消息队列负载与重新分布机制
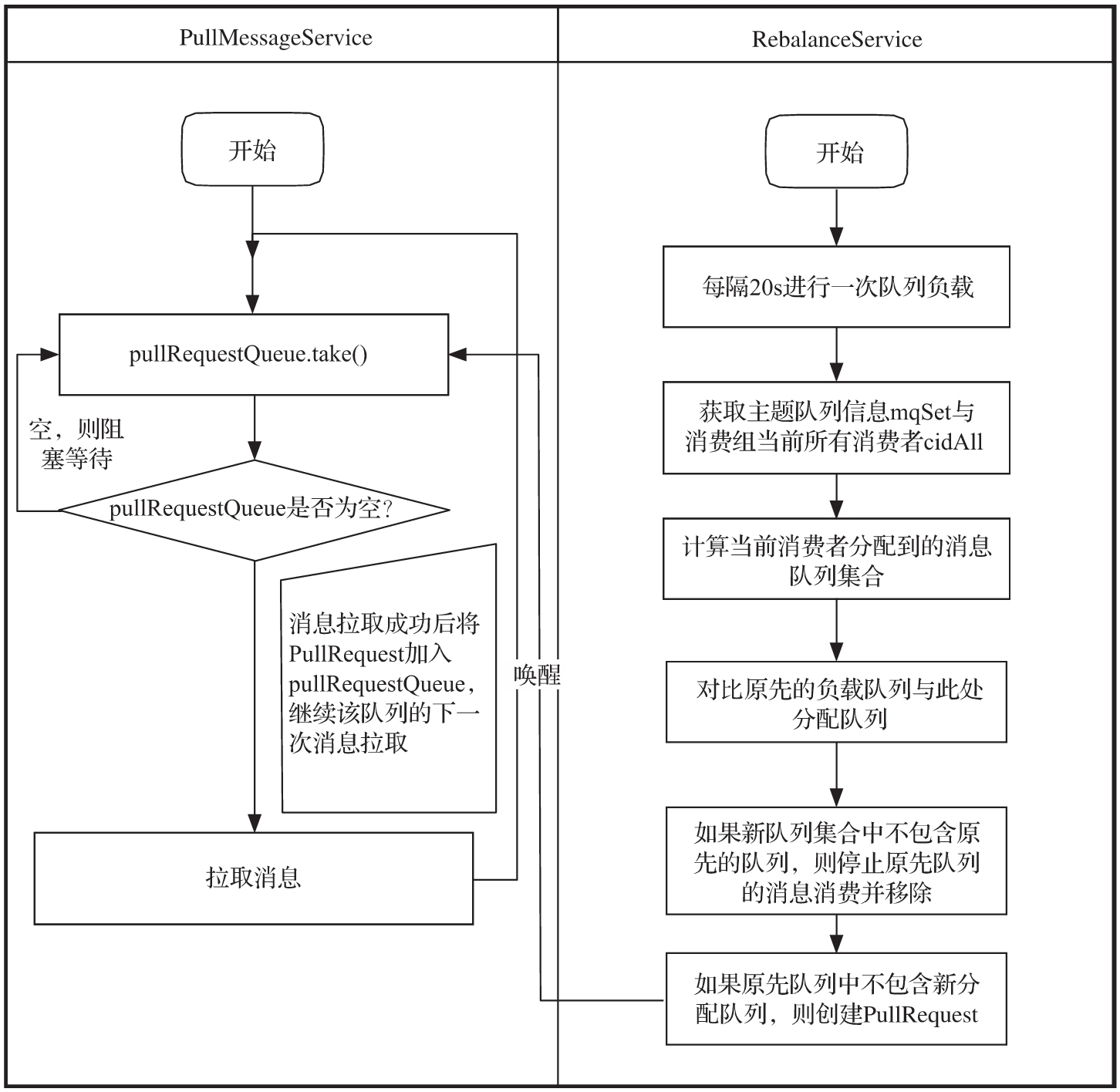
因为在启动PullMessageService时,LinkedBlockingQueue<PullRequest>pullRequestQueue中没有PullRequest对象,所以PullMessageService线程将阻塞。
-
问题1:PullRequest对象在什么时候创建并加入pullRequestQueue,可以唤醒PullMessageService线程?
-
问题2:集群内多个消费者是如何负载主题下多个消费队列的?如果有新的消费者加入,消息队列又会如何重新分布?
RocketMQ消息队列重新分布是由RebalanceService线程实现的,如代码清单5-38所示。一个MQClientInstance持有一个RebalanceService实现,并随着MQClientInstance的启动而启动。接下来我们带着上面两个问题,了解一下RebalanceService的run()方法。
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
this.waitForRunning(waitInterval);
this.mqClientFactory.doRebalance();
}
log.info(this.getServiceName() + " service end");
}RebalanceService线程默认每隔20s执行一次mqClientFactory.doRebalance()方法,如代码清单5-39所示。可以使用Drocketmq.client.rebalance.waitInterval=interval改变默认值。
public void doRebalance() {
for (Map.Entry<String, MQConsumerInner> entry : this.consumerTable.entrySet()) {
MQConsumerInner impl = entry.getValue();
if (impl != null) {
try {
impl.doRebalance();
} catch (Throwable e) {
log.error("doRebalance exception", e);
}
}
}
}MQClientIinstance遍历已注册的消费者,对消费者执行doRebalance()方法,如代码清单5-40所示。
public void doRebalance(final boolean isOrder) {
Map<String, SubscriptionData> subTable = this.getSubscriptionInner();
if (subTable != null) {
for (final Map.Entry<String, SubscriptionData> entry : subTable.entrySet()) {
final String topic = entry.getKey();
try {
this.rebalanceByTopic(topic, isOrder);
} catch (Throwable e) {
if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
log.warn("rebalanceByTopic Exception", e);
}
}
}
}
this.truncateMessageQueueNotMyTopic();
}每个DefaultMQPushConsumerImpl都持有一个单独的RebalanceImpl对象,该方法主要遍历订阅信息对每个主题的队列进行重新负载。RebalanceImpl的Map<String,SubscriptionData>subTable在调用消费者DefaultMQPushConsumerImpl#subscribe方法时填充。如果订阅信息发生变化,例如调用了unsubscribe()方法,则需要将不关心的主题消费队列从processQueueTable中移除。接下来重点分析RebalanceImpl#rebalanceByTopic,了解RocketMQ如何针对单个主题进行消息队列重新负载(以集群模式),如代码清单5-41所示。
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
List<String> cidAll = this.mQClientFactory.findConsumerIdList(topic,consumerGroup);第一步:从主题订阅信息缓存表中获取主题的队列信息。发送请求从Broker中获取该消费组内当前所有的消费者客户端ID,主题的队列可能分布在多个Broker上,那么请求该发往哪个Broker呢?RocketeMQ从主题的路由信息表中随机选择一个Broker。Broker为什么会存在消费组内所有消费者的信息呢?我们不妨回忆一下,消费者在启动的时候会向MQClientInstance中注册消费者,然后MQClientInstance会向所有的Broker发送心跳包,心跳包中包含MQClientInstance的消费者信息,如代码清单5-42所示。如果mqSet、cidAll任意一个为空,则忽略本次消息队列负载。
Collections.sort(mqAll);
Collections.sort(cidAll);
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
allocateResult = strategy.allocate(
this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll
);
} catch (Throwable e) {
log.error("AllocateMessageQueueStrategy.allocate Exception. allocateMessageQueueStrategyName={}", strategy.getName(), e);
return;
}第二步:对cidAll、mqAll进行排序。这一步很重要,同一个消费组内看到的视图应保持一致,确保同一个消费队列不会被多个消费者分配。RocketMQ消息队列分配算法接口,如代码清单5-43所示。
/**
* Strategy Algorithm for message allocating between consumers
*/
public interface AllocateMessageQueueStrategy {
List<MessageQueue> allocate(
String consumerGroup,
String currentCID,
List<MessageQueue> mqAll,
List<String> cidAll
);
/**
* Algorithm name
*
* @return The strategy name
*/
String getName();
}RocketMQ默认提供5种分配算法。 1)AllocateMessageQueueAveragely:平均分配,推荐使用。 举例来说,如果现在有8个消息消费队列q1、q2、q3、q4、q5、q6、q7、q8,有3个消费者c1、c2、c3,那么根据该负载算法,消息队列分配如下。
c1:q1、q2、q3。
c2:q4、q5、q6。
c3:q7、q8。2)AllocateMessageQueueAveragelyByCircle:平均轮询分配,推荐使用。 举例来说,如果现在有8个消息消费队列q1、q2、q3、q4、q5、q6、q7、q8,有3个消费者c1、c2、c3,那么根据该负载算法,消息队列分配如下。
c1:q1、q4、q7。
c2:q2、q5、q8。
c3:q3、q6。3)AllocateMessageQueueConsistentHash:一致性哈希。因为消息队列负载信息不容易跟踪,所以不推荐使用。 4)AllocateMessageQueueByConfig:根据配置,为每一个消费者配置固定的消息队列。 5)AllocateMessageQueueByMachineRoom:根据Broker部署机房名,对每个消费者负责不同的Broker上的队列。
|
消息负载算法如果没有特殊的要求,尽量使用AllocateMessageQueueAveragely、AllocateMessageQueueAveragelyByCircle,这是因为分配算法比较直观。消息队列分配原则为一个消费者可以分配多个消息队列,但同一个消息队列只会分配给一个消费者,故如果消费者个数大于消息队列数量,则有些消费者无法消费消息。 |
对比消息队列是否发生变化,主要思路是遍历当前负载队列集合,如果队列不在新分配队列的集合中,需要将该队列停止消费并保存消费进度;遍历已分配的队列,如果队列不在队列负载表中(processQueueTable),则需要创建该队列拉取任务PullRequest,然后添加到PullMessageService线程的pullRequestQueue中,PullMessageService才会继续拉取任务,如代码清单5-44所示。
Iterator<Entry<MessageQueue, ProcessQueue>> it = this.processQueueTable.entrySet().iterator();
while (it.hasNext()) {
Entry<MessageQueue, ProcessQueue> next = it.next();
MessageQueue mq = next.getKey();
ProcessQueue pq = next.getValue();
if (mq.getTopic().equals(topic)) {
if (!mqSet.contains(mq)) {
pq.setDropped(true);
if (this.removeUnnecessaryMessageQueue(mq, pq)) {
it.remove();
changed = true;
log.info("doRebalance, {}, remove unnecessary mq, {}", consumerGroup, mq);
}
}
}
}第三步:ConcurrentMap〈MessageQueue, ProcessQueue〉 processQueueTable是当前消费者负载的消息队列缓存表,如果缓存表中的MessageQueue不包含在mqSet中,说明经过本次消息队列负载后,该mq被分配给其他消费者,需要暂停该消息队列消息的消费。方法是将ProccessQueue的状态设置为droped=true,该ProcessQueue中的消息将不会再被消费,调用removeUnnecessaryMessageQueue方法判断是否将MessageQueue、ProccessQueue从缓存表中移除。removeUnnecessaryMessageQueue在RebalanceImple中定义为抽象方法。removeUnnecessaryMessageQueue方法主要用于持久化待移除MessageQueue的消息消费进度。在推模式下,如果是集群模式并且是顺序消息消费,还需要先解锁队列,如代码清单5-45,关于顺序消息将在5.9节详细讨论。
List<PullRequest> pullRequestList = new ArrayList<PullRequest>();
for (MessageQueue mq : mqSet) {
if (!this.processQueueTable.containsKey(mq)) {
if (isOrder && !this.lock(mq)) {
log.warn("doRebalance, {}, add a new mq failed, {}, because lock failed", consumerGroup, mq);
continue;
}
this.removeDirtyOffset(mq);
ProcessQueue pq = new ProcessQueue();
long nextOffset = this.computePullFromWhere(mq);
if (nextOffset >= 0) {
ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);
if (pre != null) {
log.info("doRebalance, {}, mq already exists, {}", consumerGroup, mq);
} else {
log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);
PullRequest pullRequest = new PullRequest();
pullRequest.setConsumerGroup(consumerGroup);
pullRequest.setNextOffset(nextOffset);
pullRequest.setMessageQueue(mq);
pullRequest.setProcessQueue(pq);
pullRequestList.add(pullRequest);
changed = true;
}
} else {
log.warn("doRebalance, {}, add new mq failed, {}", consumerGroup, mq);
}
}
}第四步:遍历本次负载分配到的队列集合,如果processQueueTable中没有包含该消息队列,表明这是本次新增加的消息队列,首先从内存中移除该消息队列的消费进度,然后从磁盘中读取该消息队列的消费进度,创建PullRequest对象。这里有一个关键,如果读取到的消费进度小于0,则需要校对消费进度。RocketMQ提供了CONSUME_FROM_LAST_OFFSET、CONSUME_FROM_FIRST_OFFSET、CONSUME_FROM_TIMESTAMP方式,在创建消费者时可以通过调用DefaultMQPushConsumer#setConsumeFromWhere方法进行设置。 PullRequest的nextOffset计算逻辑位于RebalancePushImpl#computePullFromWhere。 1)ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET:从队列最新偏移量开始消费,如代码清单5-46所示。
case CONSUME_FROM_LAST_OFFSET: {
long lastOffset = offsetStore.readOffset(mq, ReadOffsetType.READ_FROM_STORE);
if (lastOffset >= 0) {
result = lastOffset;
} else if (-1 == lastOffset) {
if (mq.getTopic().startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
result = 0L;
} else {
try {
result = this.mQClientFactory.getMQAdminImpl().maxOffset(mq);
} catch (MQClientException e) {
result = -1;
}
}
} else {
result = -1;
}
break;
}offsetStore.readOffset(mq, ReadOffsetType.READ_FROM_STORE)返回-1表示该消息队列刚创建。从磁盘中读取消息队列的消费进度,如果大于0则直接返回,如果等于-1,在CONSUME_FROM_LAST_OFFSET模式下获取该消息队列当前最大的偏移量,如果小于-1,表示该消息进度文件中存储了错误的偏移量,则返回-1。 2)CONSUME_FROM_FIRST_OFFSET:从头开始消费,如代码清单5-47所示。
case CONSUME_FROM_FIRST_OFFSET: {
long lastOffset = offsetStore.readOffset(mq, ReadOffsetType.READ_FROM_STORE);
if (lastOffset >= 0) {
result = lastOffset;
} else if (-1 == lastOffset) {
result = 0L;
} else {
result = -1;
}
break;
}从磁盘中读取消息队列的消费进度,如果大于0则直接返回,如果等于-1,在CONSUME_FROM_FIRST_OFFSET模式下直接返回0,从头开始消费,如果小于-1,表示该消息进度文件中存储了错误的偏移量,则返回-1。 3)CONSUME_FROM_TIMESTAMP:从消费者启动时间戳对应消费进度开始消费,如代码清单5-48所示。
try {
long lastOffset = offsetStore.readOffset(mq, ReadOffsetType.READ_FROM_STORE);
if (lastOffset >= 0) {
result = lastOffset;
} else if (-1 == lastOffset) {
try {
long timestamp = UtilAll.parseDate(
this.defaultMQPushConsumerImpl.getDefaultMQPushConsumer().getConsumeTimestamp(),
UtilAll.YYYYMMDDHHMMSS
).getTime();
result = this.mQClientFactory.getMQAdminImpl().searchOffset(mq, timestamp);
} catch (MQClientException e) {
result = -1;
}
} else {
result = -1;
}
} catch (Exception e) {
// Handle outer exception if needed
}从磁盘中读取消息队列的消费进度,如果大于0则直接返回。如果等于-1,在CONSUME_FROM_TIMESTAMP模式下会尝试将消息存储时间戳更新为消费者启动的时间戳,如果能找到则返回找到的偏移量,否则返回0。如果小于-1,表示该消息进度文件中存储了错误的偏移量,则返回-1,如代码清单5-49所示。
|
ConsumeFromWhere相关消费进度校正策略只有在从磁盘中获取消费进度返回-1时才会生效,如果从消息进度存储文件中返回的消费进度小于-1,表示偏移量非法,则使用偏移量-1去拉取消息,那么会发生什么呢?首先第一次去消息服务器拉取消息时无法取到消息,但是会用-1去更新消费进度,然后将消息消费队列丢弃,在下一次消息队列负载时再次消费。 |
this.dispatchPullRequest(pullRequestList);
public void dispatchPullRequest(List<PullRequest> pullRequestList) {
for (PullRequest pullRequest : pullRequestList) {
this.defaultMQPushConsumerImpl.executePullRequestImmediately(pullRequest);
log.info("doRebalance, {}, add a new pull request {}", consumerGroup, pullRequest);
}
}第五步:将PullRequest加入PullMessageService,以便唤醒PullMessageService线程。消息队列负载机制就介绍到这里,回到本节的两个问题。
问题1:PullRequest对象在什么时候创建并加入pullRequestQueue,可以唤醒PullMessageService线程?
RebalanceService线程每隔20s对消费者订阅的主题进行一次队列重新分配,每一次分配都会获取主题的所有队列、从Broker服务器实时查询当前该主题该消费组内的消费者列表,对新分配的消息队列会创建对应的PullRequest对象。在一个JVM进程中,同一个消费组同一个队列只会存在一个PullRequest对象。
问题2:集群内多个消费者是如何负载主题下多个消费队列的?如果有新的消费者加入,消息队列又会如何重新分布?
每次进行队列重新负载时,会从Broker实时查询当前消费组内所有的消费者,并且对消息队列、消费者列表进行排序,这样新加入的消费者就会在队列重新分布时分配到消费队列,从而消费消息。
本节分析了消息队列的负载机制,RocketMQ消息拉取由PullMessageService与Rebalance-Service共同协作完成,如图5-13所示。