Stable Diffusion软件界面
Stable Diffusion 由 Stability AI 公司发布,是一款可以在消费级 GPU 上快速生成高质量图像的 AI 绘画软件。Stable Diffusion 可以安装在本地计算机上,如果读者拥有一台带有性能强劲显卡的计算机,则可以使用这台计算机进行 AI 绘画图像计算。另外,相比购买一台高性能计算机来说,读者还可以选择付费给第三方公司,使用其云部署的软件来进行 AI 图像的绘画。
根据官方说明,在个人计算机上安装 Stable Diffusion 较为复杂,个人比较推荐直接安装 Stable Diffusion WebUI 整合包,如 bilibili 知名 UP 主秋叶aaaki 发布的绘世启动器,如图1-13所示。单击页面上右下角的 “一键启动” 按钮后,即可在网页浏览器中打开 Stable Diffusion 软件界面,如图1-14所示。需要注意的是,本地安装 Stable Diffusion 软件完成后,还需要读者单独去 Civitai 模型网站下载大量模型素材,并将模型复制至软件提示的文件夹内才能使用。
读者还可以选择使用云部署 Stable Diffusion 软件的第三方公司所提供的产品来进行 AI 绘画创作,如网易 AI 设计工坊,如图1-15所示。单击页面上下方的 “开始创作” 按钮后,即可在网页浏览器中打开 Stable Diffusion WebUI 软件界面,如图1-16所示。

Stable Diffusion模型
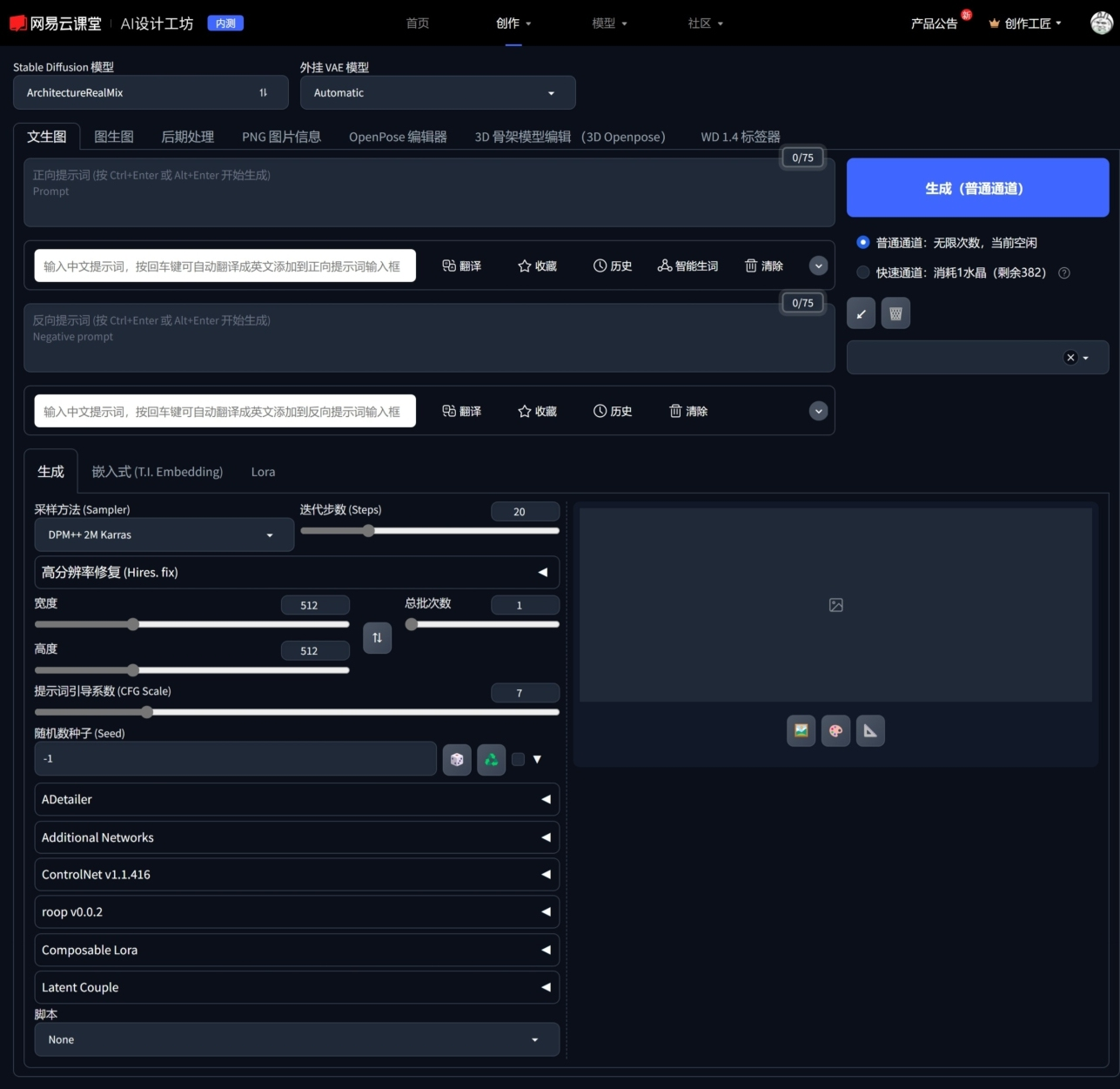
当我们使用 Stable Diffusion 进行 AI 绘画时,第一步需要我们先选择合适的 Stable Diffusion 模型,Stable Diffusion 模型也被称为主模型、大模型、底模型或 Checkpoint 模型。StableDiffusion 模型会对 AI 绘画作品的内容及效果起到决定性作用,例如当用户要生成一张人物角色的 AI 绘画作品时,需要先选择相关的人物角色模型,如果用户选择的是一个建筑模型,则很难得到较为满意的图像,甚至可能会得到较为混乱的图像结果。在输入提示词之前,用户选择合适的 Stable Diffusion 模型显得尤为重要。Stable Diffusion 的一个重要优势就在于其可以使用成百上千的开源模型,用户可以通过 Civitai、吐司、哩布哩布等网站下载 AI 绘画爱好者所制作的各类模型,这些模型文件通常都比较大,一般为 2GB~7GB,如图1-17所示。所以本地安装 Stable Diffusion 之后,读者还应考虑预留一定的硬盘空间用于存储这些模型文件。
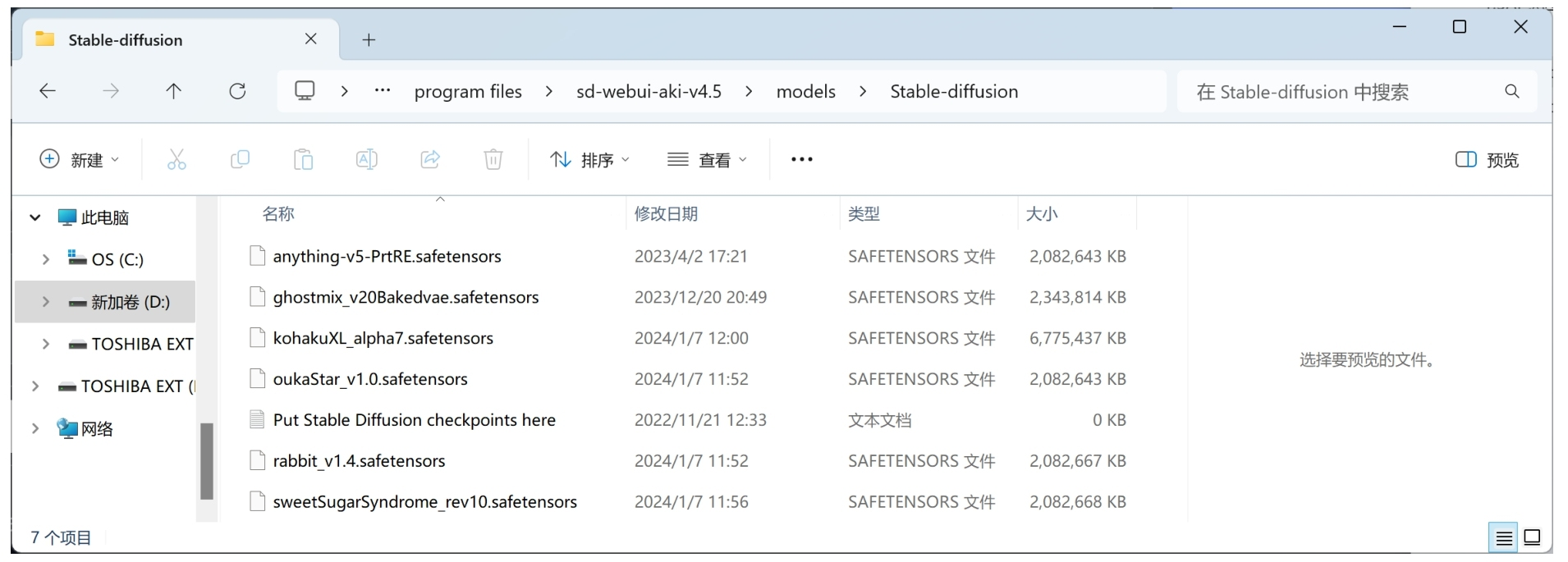
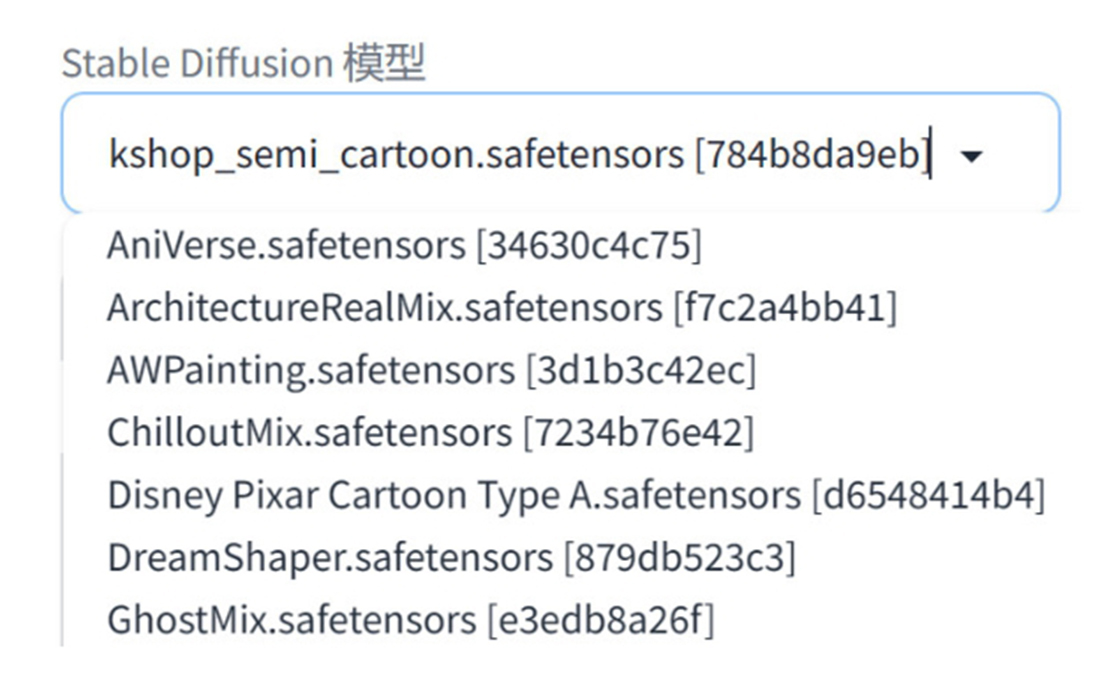
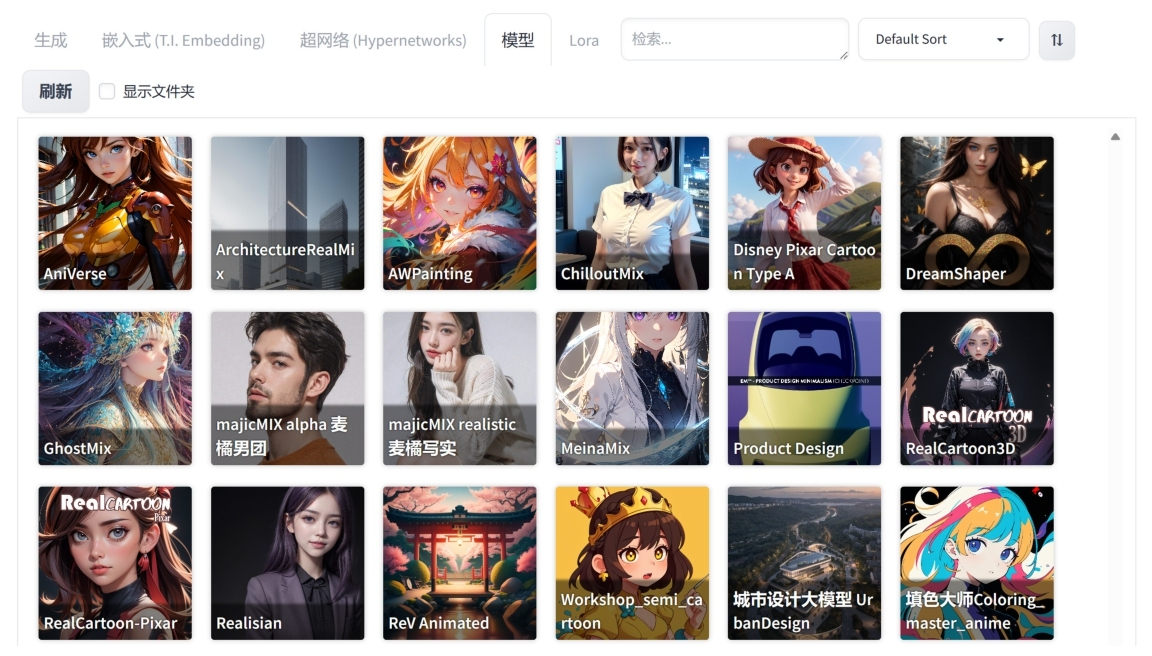
对于选择本地安装的用户来说,Stable Diffusion 模型通常需要放置在软件根目录的 models\Stable-diffusion 文件夹中。用户将下载完成的 Stable Diffusion 模型文件复制至 Stable-diffusion 文件夹后,即可在网页页面顶端左侧的 “Stable Diffusion模型” 下拉列表中选择这些模型,如图 1-18 所示。用户也可以在 “模型” 选项卡中选择这些下载的模型,如图 1-19 所示。
|
下载好的模型一定要配一张该模型作者绘制的图片,图片的名称与模型名称应保持一致,这样 Stable Diffusion 可以将该图片当作对应模型的缩略图显示出来。 本书使用的大部分模型均可在 Civitai 网站和哩布哩布网站进行下载,另外,为了方便读者在 Civitai 网站查找这些模型,本书模型的名称均为模型作者对该模型的命名。 |
功能选项卡
功能选项卡汇集了 Stable Diffusion 的各种功能,以秋叶 aaaki 发布的绘世启动器为例,功能选项卡共分为文生图、图生图、后期处理、PNG图片信息、模型融合、训练、无边图像浏览、模型转换、超级模型融合、模型工具箱、WD1.4标签器、设置和扩展几部分,如图1-20所示。

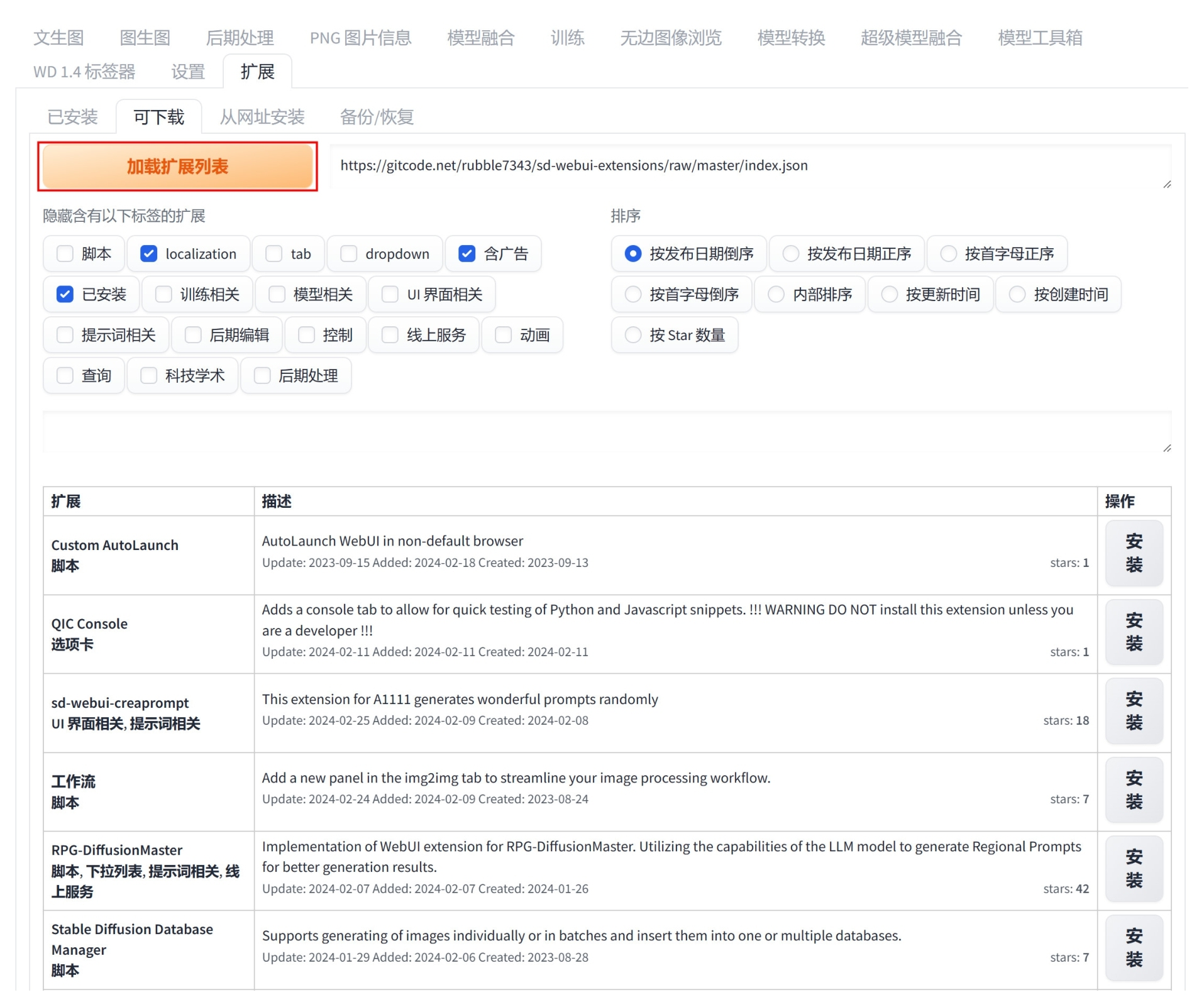
安装好 Stable Diffusion 后,读者还可以选择安装一些 Stable Diffusion 的扩展应用插件,有些插件可以更好地控制角色的身体姿势、手势及面容,并且还可以进行 AI 视频的创作。在 “扩展” 选项卡中,用户可以单击 “加载扩展列表” 按钮,在下方显示出来的扩展程序列表中选择更多的扩展应用进行安装,如图 1-21 所示。
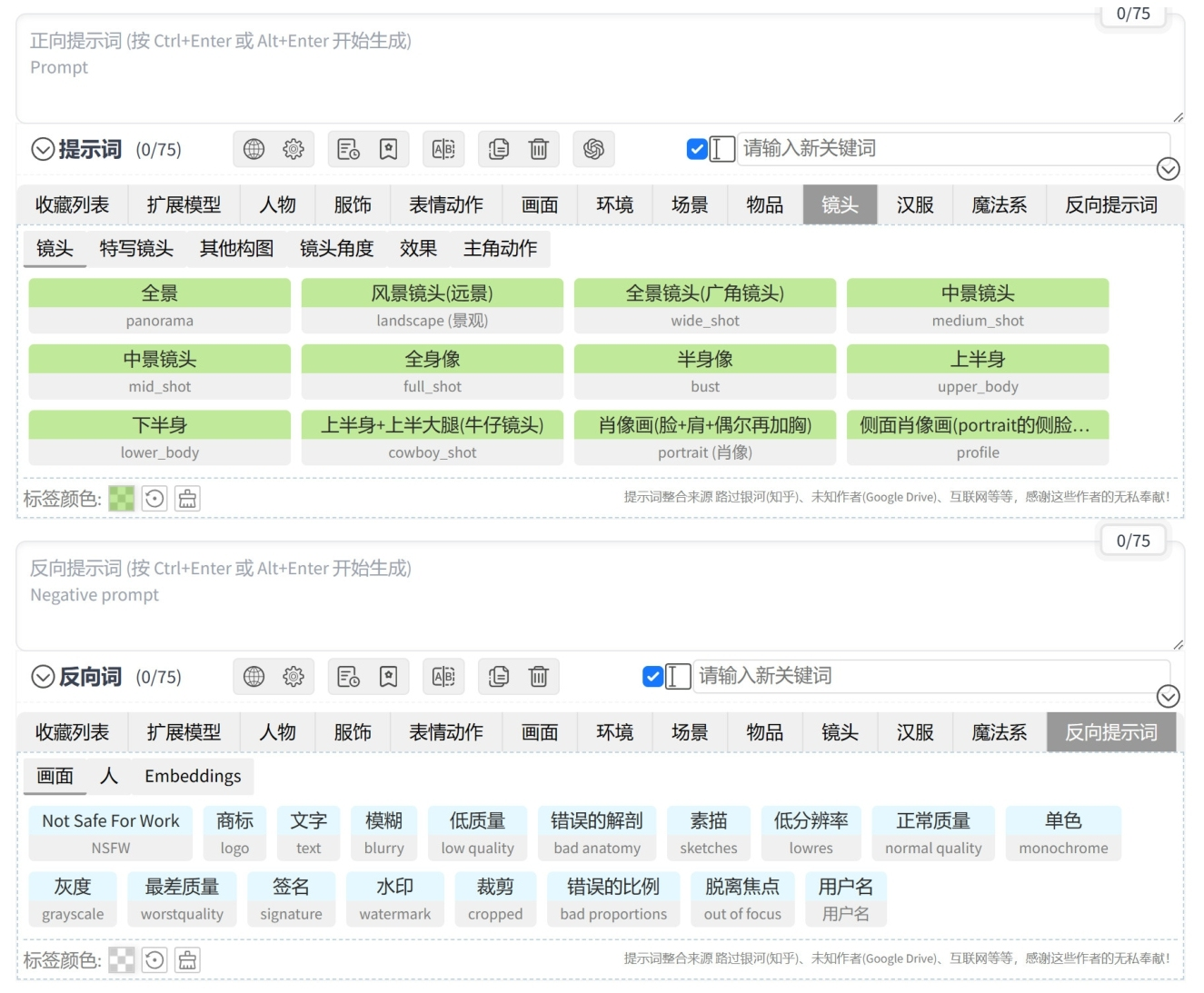
提示词文本框
Stable Diffusion 目前仅支持英文,即用户需要在提示词文本框内输入英文才可以正确地进行 AI 绘画,提示词文本框下方按不同分类提供了大量的中英文对照选项,其中几乎涵盖了大部分常用提示词,如图 1-22 所示。
“生成”选项卡
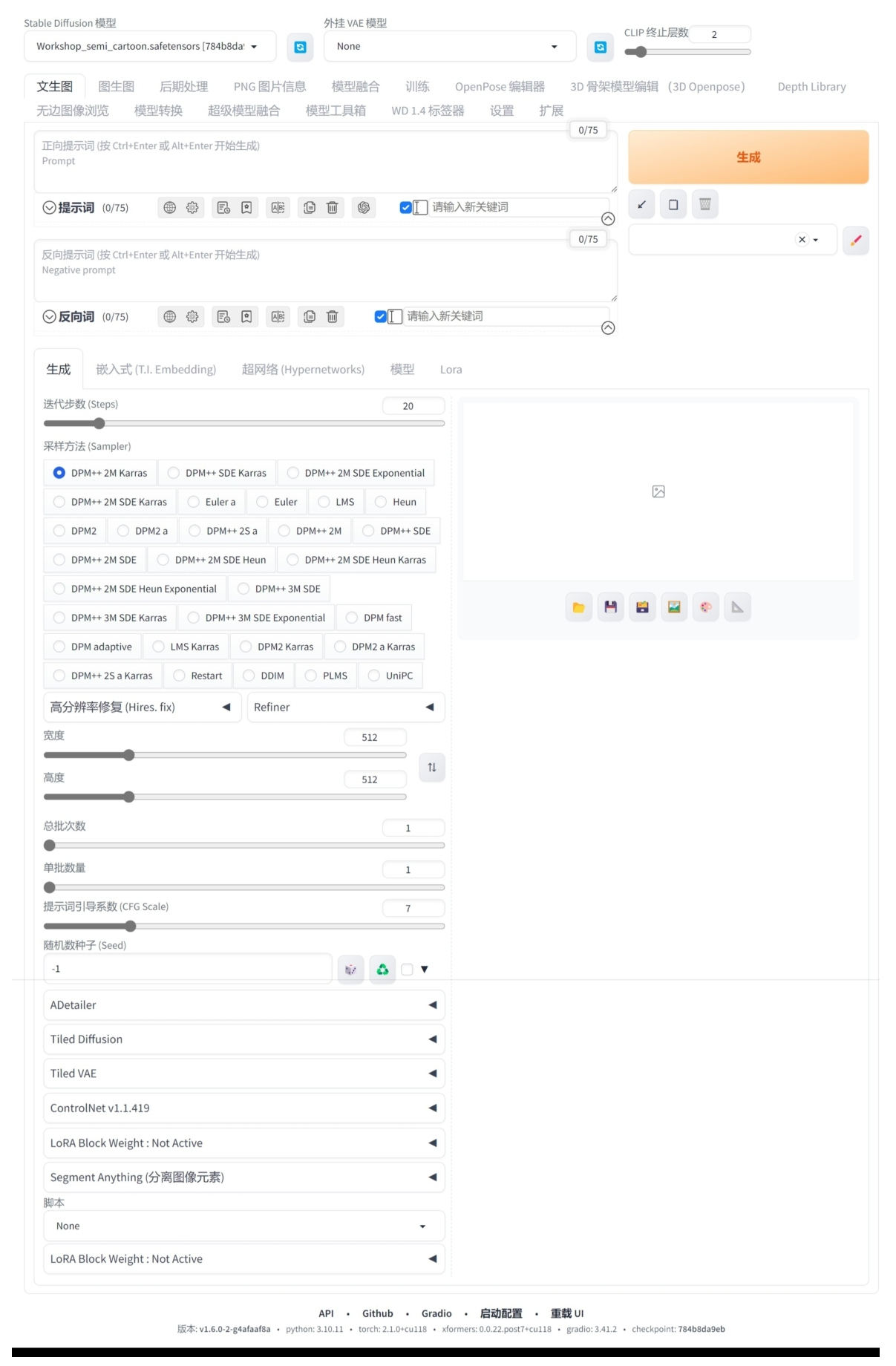
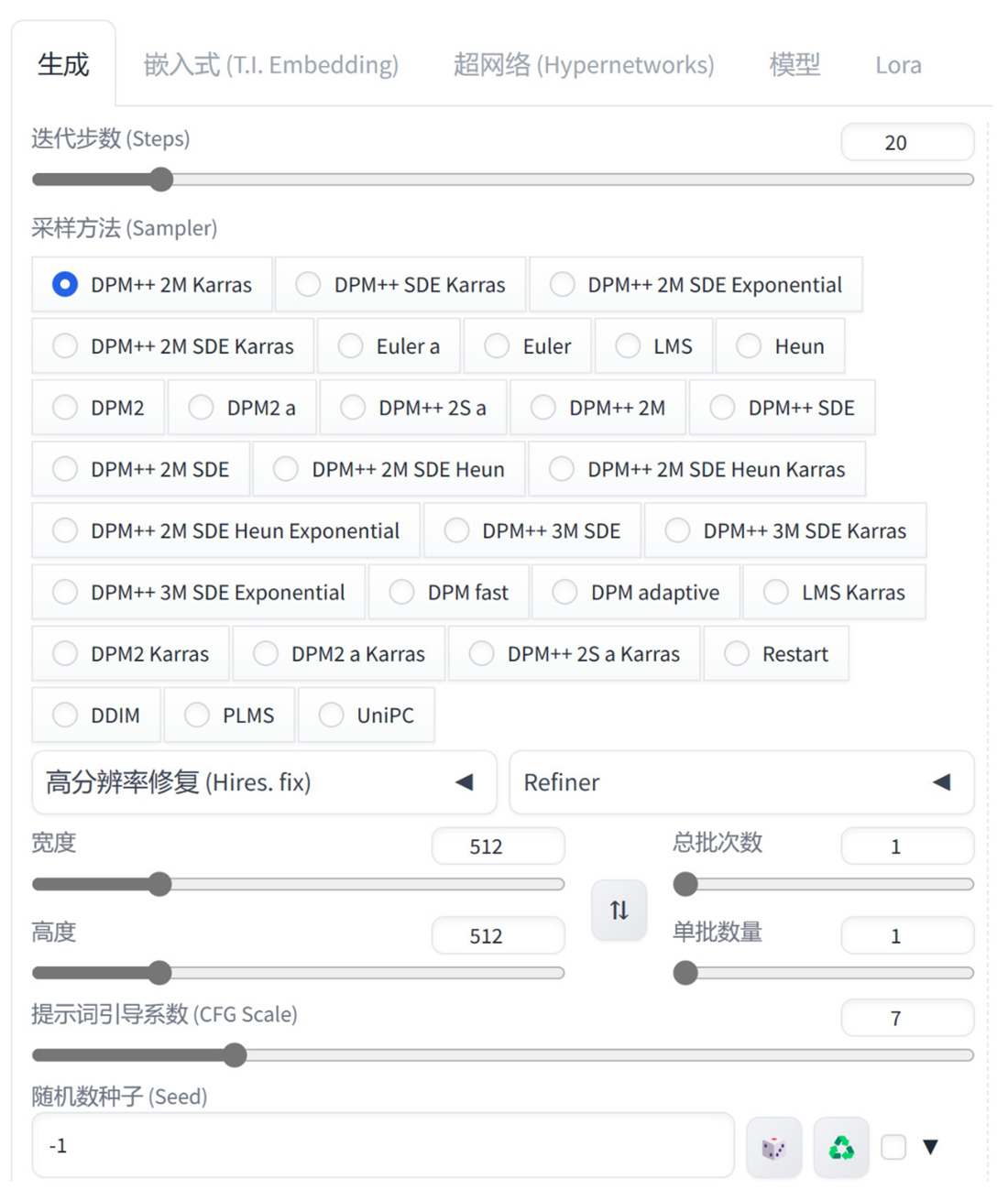
“生成” 选项卡主要用于设置有关图像生成的一些参数,如图 1-23 所示。
工具解析
-
迭代步数:Stable Diffusion 生成图像的步骤是从一个充满噪点的画布开始慢慢创建完成整个图像,然后进行去噪处理以得到最终完成效果,迭代步数则用于控制去噪过程的步数,该值默认为 20。
-
采样方法:计算图像的采样方法,通常使用默认的采样方法 “DPM++2M Karras” 即可,其他的采样方法则可以参考不同模型作者给出的说明来选择使用。
-
宽度:设置生成图像的宽度。
-
高度:设置生成图像的高度。
-
总批次数:设置生成图像的总批次数。
-
单批数量:设置一次生成图像的数量,最终生成的图像数量取决于单批数量×总批次数的值。
-
提示词引导系数:设置提示词对于图像的影响程度。
-
随机数种子:设置随机值。
|
早期很多的 Stable Diffusion 模型是基于 512×512 像素的图片进行训练的,所以当用户期望生成 1024×1024 像素或更高数值图像分辨率的图像时,Stable Diffusion 会试图将 3 或 4 幅图像的内容一起嵌入到AI绘画作品中,这样当我们创作较大尺寸的图像时,常常会生成较为明显的图像拼接错误效果。例如,当我们创作 1536×1536 像素的方形室内效果图时,较容易生成 2 或 3 个平层出现在一张图里的效果,且图像的拼接效果非常明显,如图 1-24 所示。而我们将图像分辨率变更为 1016×592 像素后,则可以有效避免出现多个平层出现在一张图里的效果,如图 1-25 所示。 |