流处理
流处理有点类似数据库的 SQL 语句,可以执行非常复杂的过滤、映射、查找和收集功能,并且代码量很少。唯一的缺点是代码可读性不高,如果开发者基础不好,可能会看不懂流 API 所表达的含义。
为了能让读者更好地理解流 API 的处理过程和结果,本节先创建一个公共类— Employee 员工类。员工类包含员工的姓名、年龄、薪资、性别和部门属性,并给这些属性提供了 getter 方法。重写 toString() 方法可以方便查看员工对象的所有信息。公共类提供了一个静态方法 getEmpList(),这个方法已经创建好了一些员工对象,然后将这些员工封装成一个集合并返回。本节将重点对这些员工数据进行流处理。
员工集合的详细数据如表14.2所示。
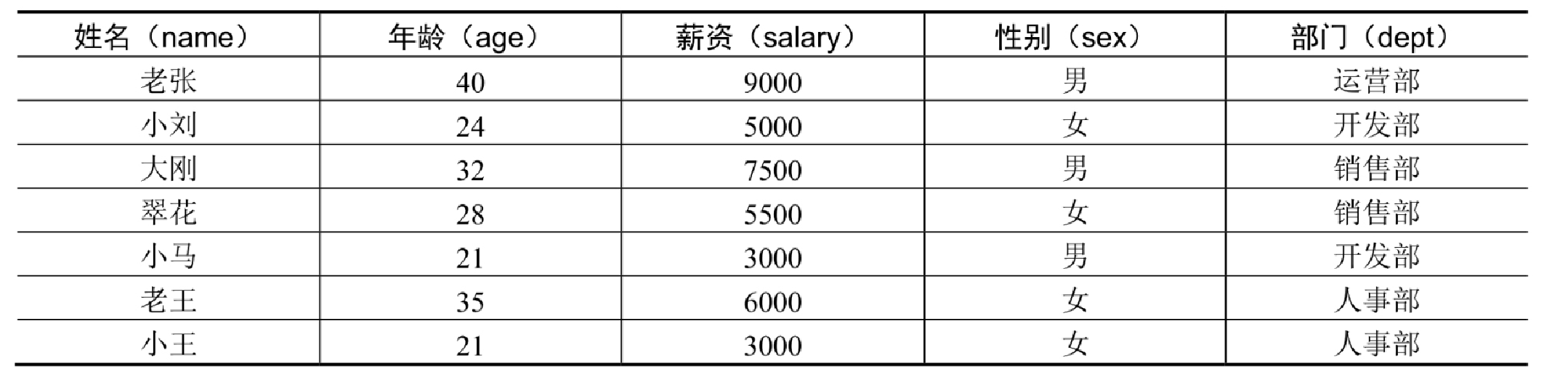
【例14.14】创建员工类,并按照表14.2创建初始化数据(实例位置:资源包\TM\sl\14\14)
创建 Employee 类,在类中创建姓名、年龄、工资、性别和部门属性,创建对应这些属性的构造方法和 getter 方法。最后将初始化的员工数据放到一个 ArrayList 列表中。
import java.util.ArrayList;
import java.util.List;
public class Employee { // 员工类
private String name; // 姓名
private int age; // 年龄
private double salary; // 工资
private String sex; // 性别
private String dept; // 部门
// 构造方法
public Employee(String name, int age, double salary, String sex, String dept) {
this.name = name;
this.age = age;
this.salary = salary;
this.sex = sex;
this.dept = dept;
}
// 重写此方法,方便打印输出员工信息
public String toString() {
return "name=" + name + ", age=" + age + ", salary=" + salary + ", sex=" + sex + ", dept=" + dept;
}
// 以下是员工属性的getter方法
public String getName() {
return name;
}
public int getAge() {
return age;
}
public double getSalary() {
return salary;
}
public String getSex() {
return sex;
}
public String getDept() {
return dept;
}
static List<Employee> getEmpList() { // 提供数据初始化方法
List<Employee> list = new ArrayList<Employee>();
// 添加员工数据
list.add(new Employee("老张", 40, 9000, "男", "运营部"));
list.add(new Employee("小刘", 24, 5000, "女", "开发部"));
list.add(new Employee("大刚", 32, 7500, "男", "销售部"));
list.add(new Employee("翠花", 28, 5500, "女", "销售部"));
list.add(new Employee("小马", 21, 3000, "男", "开发部"));
list.add(new Employee("老王", 35, 6000, "女", "人事部"));
list.add(new Employee("小王", 21, 3000, "女", "人事部"));
return list;
}
}Stream接口
流处理的接口都被定义在 java.uil.stream 包中。BaseStream 接口是最基础的接口,但最常用的是 BaseStream 接口的一个子接口— Stream 接口。基本上绝大多数的流处理都是在 Stream 接口上实现的。
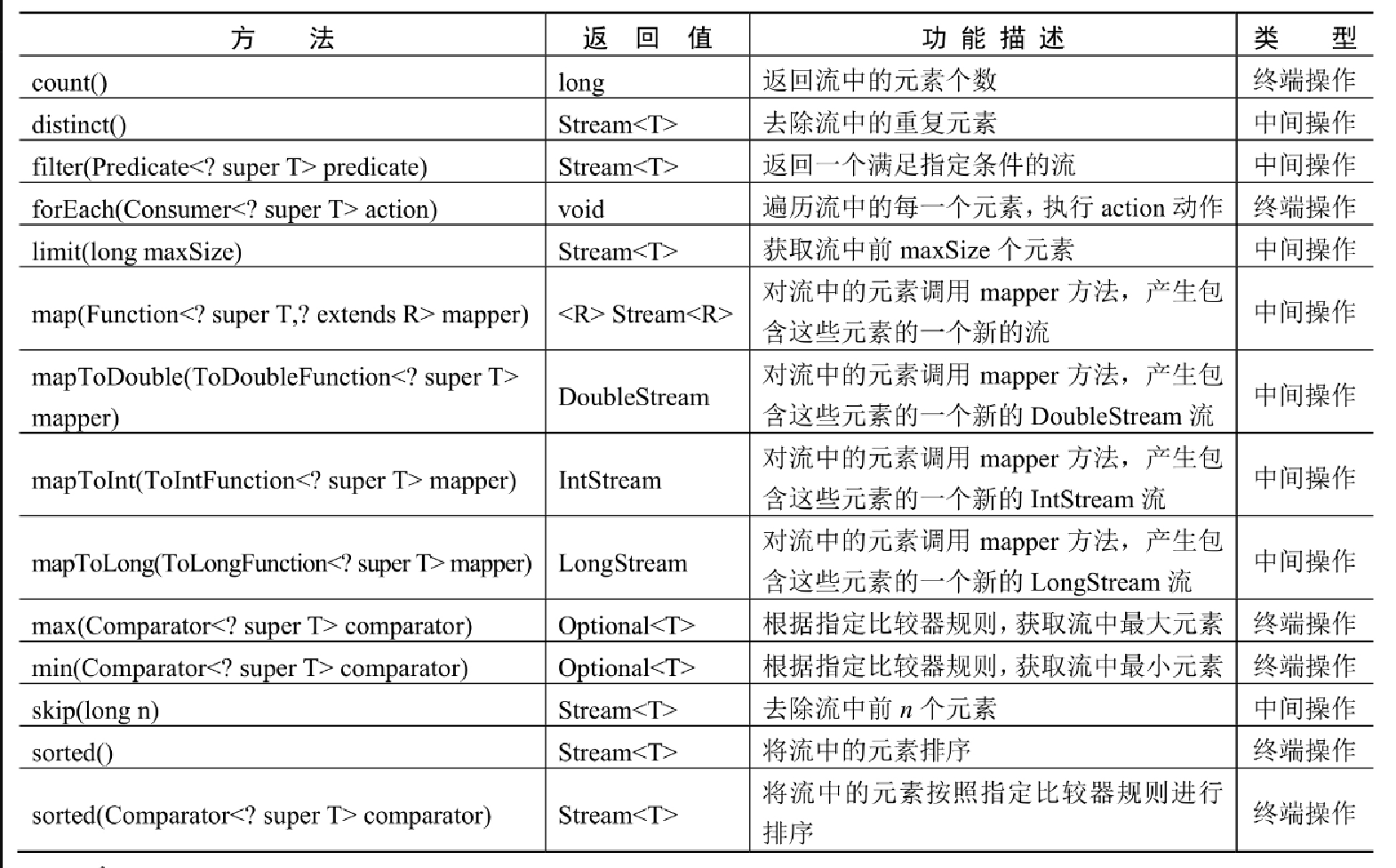
Stream 接口是泛型接口,因此流中操作的元素可以是任何类的对象。Stream 接口的常用方法如表14.3所示。
|
表14.3中最后一列 “类型” 中有两种值:中间操作和终端操作。中间操作类型的方法会生成一个新的流对象,被操作的流对象仍然可以执行其他操作;终端操作会消费流,操作结束之后,被操作的流对象就不能再次执行其他操作了。这是二者的最大区别。 |
Collection 接口新增两个可以获取流对象的方法。第一个方法最常用,可以获取集合的顺序流,方法如下:
Stream<E> stream();第二个方法可以获取集合的并行流,方法如下:
Stream<E> parallelstream();因为所有集合类都是 Collection 接口的子类,如 ArrayList 类、HashSet 类等,所以这些类都可以进行流处理。例如:
List<Integer> list = new ArrayList<Integer>(); // 创建集合
Stream<Integer> s = list.stream(); // 获取集合流对象Optional类
Optional 类像是一个容器,可以保存任何对象,并且针对 NullPointerException 空指针异常做了优化,保证 Optional 类保存的值不会是 null。因此,Optional 类是针对 “对象可能是 null 也可能不是 null” 的场景为开发者提供了优质的解决方案,减少了烦琐的异常处理。
Optional 类由于是用 final 修饰的,因此不能有子类。Optional 类由于是带有泛型的类,因此可以保存任何对象的值。
从 Optional 类的声明代码中就可以看出这些特性,JDK 中的部分代码如下:
public final class Optional<T> {
private final T value;
...
}Optional 类中有一个叫作 value 的成员属性,这个属性就是用来保存具体值的。value 是用泛型 T 修饰的,并且还用了 final 修饰,这表示一个 Optional 对象只能保存一个值。
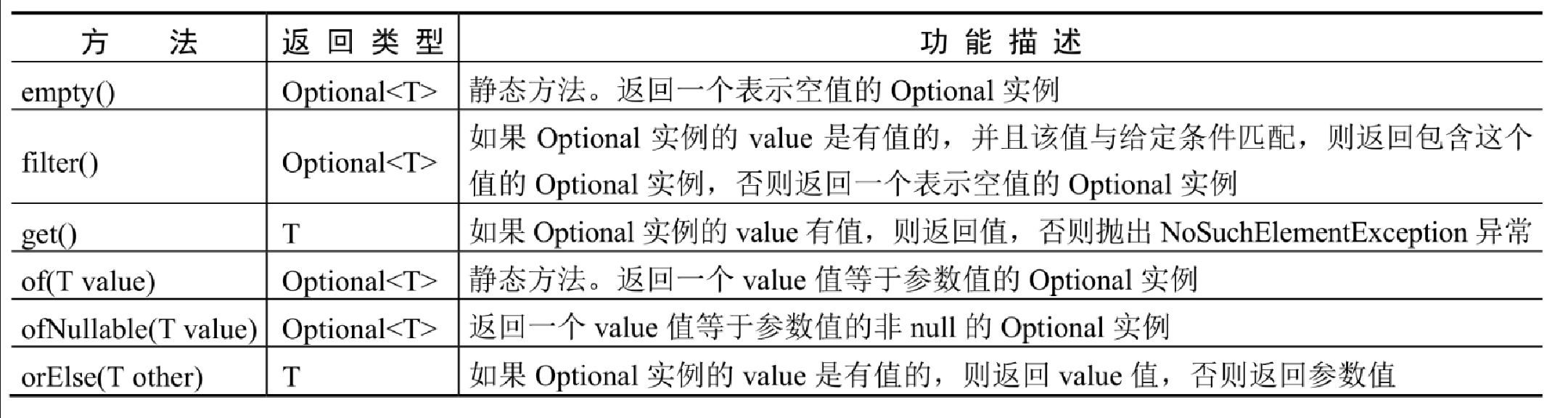
Optional 类提供了很多封装、校验和获取值的方法,这些方法如表14.4所示。
|
除 Optional 类外,还可以使用 OptionalDouble、OptionalInt 和 OptionalLong 3个类,开发者可以根据不同的应用场景进行灵活选择。 |
【例14.15】使用Optional类创建“空”对象(实例位置:资源包\TM\sl\14\15)
创建一个 Optional 对象,并赋予一个字符串类型的值,然后判断此对象的值是否为空;再使用 empty() 方法创建一个 “空值” 的 Optional 对象,然后判断此对象的值是否为空。
import java.util.Optional;
public class OptionalDemo {
public static void main(String[] args) {
Optional<String> strValue = Optional.of("Hello"); // 创建有值对象
boolean haveValueFlag = strValue.isPresent(); // 判断对象中的值是不是空的
System.out.println("strValue对象是否有值:" + haveValueFlag);
if (haveValueFlag) { // 如果不是空的
String str = strValue.get(); // 获取对象中值
System.out.println("strValue对象的值是:" + str);
}
Optional<String> noValue = Optional.empty(); // 创建空值对象
boolean noValueFlag = noValue.isPresent(); // 判断对象中的值是不是空的
System.out.println("noValue对象是否有值:" + noValueFlag);
if (noValueFlag) { // 如果不是空的
String str = noValue.get(); // 获取对象中值
System.out.println("noValue对象的值是:" + str);
} else { // 如果是空的
String str = noValue.orElse("使用默认值"); // 使用默认值
System.out.println("noValue对象的值是:" + str);
}
}
}运行结果如下:
strValue对象是否有值:true
strValue对象的值是:Hello
noValue对象是否有值:false
noValue对象的值是:使用默认值Collectors类
Collectors 类为收集器类,该类实现了 java.util.Collector 接口,可以将 Stream 流对象进行各种各样的封装、归集、分组等操作。同时,Collectors 类还提供了很多实用的数据加工方法,如数据统计计算等。Collectors 类的常用方法如表14.5所示。
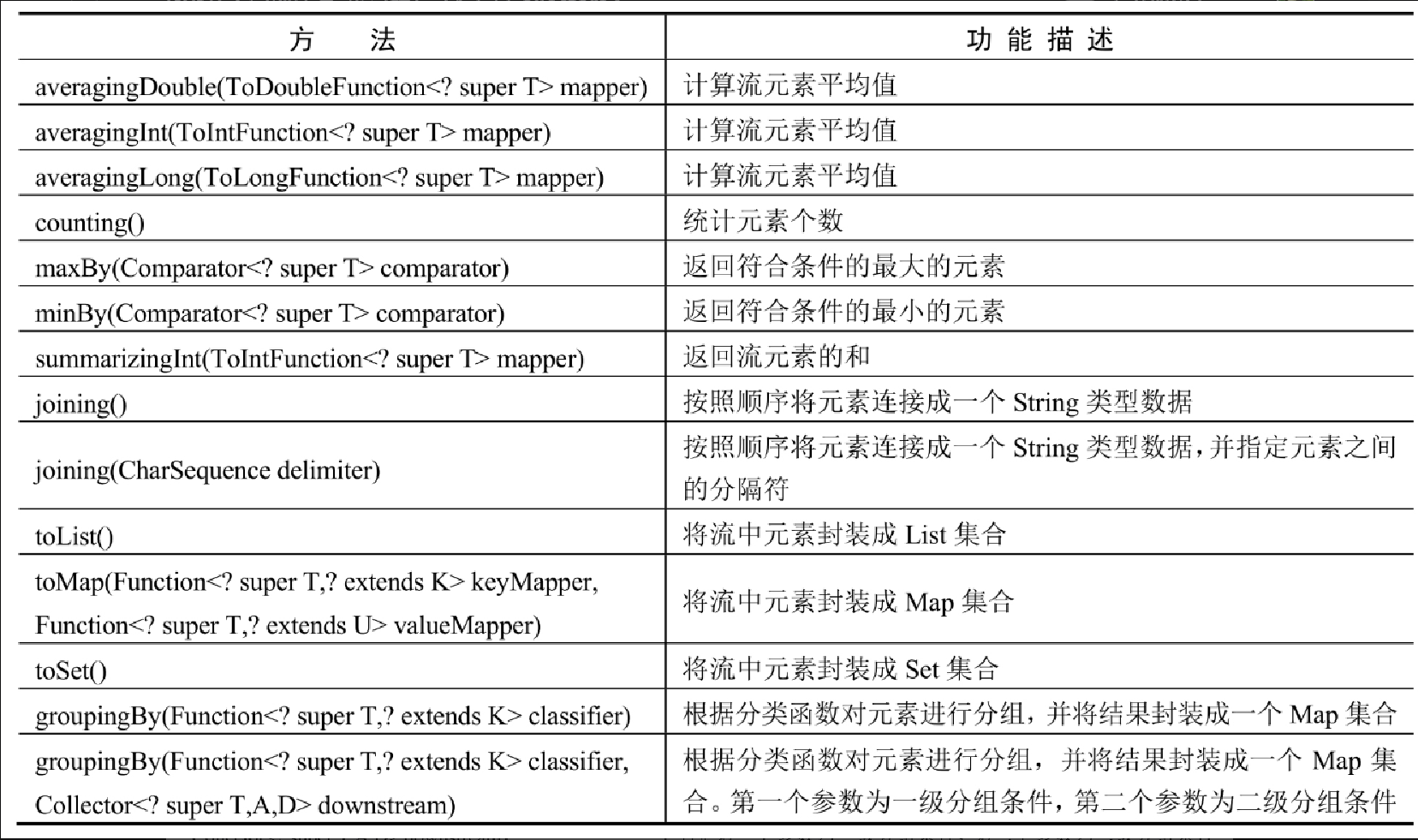
Collectors 类的具体用法将在后面章节做重点讲解。
数据过滤
数据过滤就是在杂乱的数据中筛选出需要的数据,类似 SQL 语句中的 WHERE 关键字,给出一定的条件,将符合条件的数据过滤并展示出来。
filter()方法
filter() 方法是 Stream 接口提供的过滤方法。该方法可以将 lambda 表达式作为参数,然后按照 lambda 表达式的逻辑过滤流中的元素。过滤出想要的流元素后,还需使用 Stream 提供的 collect() 方法按照指定方法重新进行封装。
【例14.16】输出1~10的所有奇数(实例位置:资源包\TM\sl\14\16)
将1~10的数字放到一个 ArrayList 列表中,调用该列表的 Stream 对象的 filter() 方法,该方法的参数为过滤奇数的 lambda 表达式。查看该方法被执行完毕后 Stream 对象返回的结果。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class FilterOddDemo {
static void printeach(String message, List list) { // 输出集合元素
System.out.print(message); // 输出文字信息
// 使用forEach方法遍历集合并打印元素
list.stream().forEach(n -> {
System.out.print(n + " ");
});
System.out.println(); // 换行
}
public static void main(String[] args) {
List<Integer> list = new ArrayList<>(); // 创建空数组
for (int i = 1; i <= 10; i++) { // 从1循环到10
list.add(i); // 给集合赋值
}
printeach("集合原有元素:", list); // 输出集合元素
Stream<Integer> stream = list.stream(); // 获取集合流对象
// 将集合中的所有奇数过滤出来,把过滤结果重新赋值给流对象
stream = stream.filter(n -> n % 2 == 1);
// 将流对象重新封装成一个List集合
List<Integer> result = stream.collect(Collectors.toList());
printeach("过滤之后的集合元素:", result); // 输出集合元素
}
}运行结果如下:
集合原有元素:1 2 3 4 5 6 7 8 9 10
过滤之后的集合元素:1 3 5 7 9这个实例把 “获取流”、“过滤流”、“封装流” 3 个部分的操作分开编写,是为了方便读者学习理解,通常为了代码简洁,将 3 部分操作可以写在一行代码中,例如:
List<Integer> result = list.stream().filter(n -> n % 2 == 1).collect(Collectors.toList());这种写法也可以避免终端操作造成的 “流被消费掉” 的问题,因为每次被操作的流都是从集合中重新获取的。
|
代码在 Eclipse 中出现黄色警告,这是由 printeach(String message, List list) 方法中的 list 参数没有指定泛型引起的。但是,这也体现出 lambda 表达式可以自动识别数据类型的优点。读者可以忽略此警告。 |
例14.16中演示的集合元素是数字类型,集合能保存的不止是数字,下面这个实例将演示如何利用过滤器以对象属性为条件过滤元素。
【例14.17】找出年龄大于30的员工(实例位置:资源包\TM\sl\14\17)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,将年龄大于 30 的员工过滤出来。如果将员工集合返回的流对象泛型定义为 <Employee>,就可以直接在 lambda 表达式中使用 Employee 类的方法。
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class FilerDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 将年龄大于30岁的员工过滤出来
stream = stream.filter(people -> people.getAge() > 30);
// 将流对象重新封装成一个List集合
List<Employee> result = stream.collect(Collectors.toList());
for (Employee emp : result) { // 遍历结果集
System.out.println(emp); // 输出员工对象信息
}
}
}运行结果如下:
name=老张, age=40, salary=9000.0, sex=男, dept=运营部
name=大刚, age=32, salary=7500.0, sex=男, dept=销售部
name=老王, age=35, salary=6000.0, sex=女, dept=人事部通过这个结果可以看出,年龄没超过 30 的员工都被过滤掉了。通过类的一个属性,就可以完整地获取到符合条件的类对象,可以输出员工的姓名、性别等属性。
distinct()方法
distinct() 方法是 Stream 接口提供的过滤方法。该方法可以去除流中的重复元素,效果与 SQL 语句中的 DISTINCT 关键字一样。
【例14.18】去除List集合中的重复数字(实例位置:资源包\TM\sl\14\18)
创建一个 List 集合,保存一些数字(包含重复数字),获取集合的流对象,使用 distinct() 方法将重复的数字去掉。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class DistinctDemo {
static void printeach(String message, List list) { // 输出集合元素
System.out.print(message); // 输出文字信息
// 使用forEach方法遍历集合并打印元素
list.stream().forEach(n -> {
System.out.print(n + " ");
});
System.out.println();// 换行
}
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>(); // 创建集合
list.add(1); // 添加元素
list.add(2);
list.add(2);
list.add(3);
list.add(3);
printeach("去重前:", list); // 打印集合元素
Stream<Integer> stream = list.stream(); // 获取集合流对象
// 取出流中的重复元素
stream = stream.distinct();
// 将流对象重新封装成一个List集合
List<Integer> reslut = stream.collect(Collectors.toList());
printeach("去重后:", reslut); // 打印集合元素
}
}运行结果如下:
去重前:1 2 2 3 3
去重后:1 2 3因为 distinct() 方法属于中间操作,所以可以配合 filter() 方法一起使用。
limit()方法
limit() 方法是 Stream 接口提供的方法,该方法可以获取流中前 N 个元素。
【例14.19】找出所有员工列表中的前两位女员工(实例位置:资源包\TM\sl\14\19)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,取出所有员工中的前两位女员工,具体代码如下:
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class LimitDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 将所有女员工过滤出来
stream = stream.filter(people -> "女".equals(people.getSex()));
// 取出前两位
stream = stream.limit(2);
// 将流对象重新封装成一个List集合
List<Employee> result = stream.collect(Collectors.toList());
for (Employee emp : result) { // 遍历结果集
System.out.println(emp); // 输出员工对象信息
}
}
}运行结果如下:
name=小刘, age=24, salary=5000.0, sex=女, dept=开发部
name=翠花, age=28, salary=5500.0, sex=女, dept=销售部公司一共有 4 位女员工,但这个结果只输出了公司前两位女员工,“老王” 和 “小王” 没有被输出。
skip()方法
skip() 方法是 Stream 接口提供的方法,该方法可以忽略流中的前 n 个元素。
【例14.20】取出所有男员工,并忽略前两位男员工(实例位置:资源包\TM\sl\14\20)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,取出所有男员工,并忽略前两位男员工。
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class SkipDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 将所有男员工过滤出来
stream = stream.filter(people -> "男".equals(people.getSex()));
// 跳过前两位
stream = stream.skip(2);
// 将流对象重新封装成一个List集合
List<Employee> result = stream.collect(Collectors.toList());
for (Employee emp : result) { // 遍历结果集
System.out.println(emp); // 输出员工对象信息
}
}
}运行结果如下:
name=小马, age=21, salary=3000.0, sex=男, dept=开发部公司一共有3位男员工,这个结果只输出了 “小马”,“老张” 和 “大刚” 都没有被输出。
数据映射
数据的映射和过滤概念不同:过滤是在流中找到符合条件的元素,映射是在流中获得具体的数据。
Stream 接口提供了 map() 方法用来实现数据映射,map() 方法会按照参数中的函数逻辑获取新的流对象,新的流对象中元素类型可能与旧流对象元素类型不相同。
【例14.21】获取开发部所有员工的名单(实例位置:资源包\TM\sl\14\21)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,先过滤出开发部的员工,再引用员工类的 getName() 方法作为 map() 方法的映射参数,这样就获取到开发部员工名单。
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class MapDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 将所有开发部的员工过滤出来
stream = stream.filter(people -> "开发部".equals(people.getDept()));
// 将所有员工的名字映射成一个新的流对象
Stream<String> names = stream.map(Employee::getName);
// 将流对象重新封装成一个List集合
List<String> result = names.collect(Collectors.toList());
for (String emp : result) { // 遍历结果集
System.out.println(emp); // 输出所有姓名
}
}
}运行结果如下:
小刘
小马结果输出了开发部两位员工的名字,但没有输出这两位员工的其他信息,这个就是映射的结果。
除了可以映射出员工名单,还可以对映射数据进行加工处理。例如,统计销售部一个月的薪资总额。因为涉及数字计算,所以需要让 Stream 对象转为可以进行数学运算的数字流。因为薪资类型是 double 类型,所以应该调用 mapToDouble() 方法进行转换。
【例14.22】计算销售部一个月的薪资总额(实例位置:资源包\TM\sl\14\22)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,先过滤出销售部的员工,再引用员工类的 getSalary() 方法作为 mapToDouble() 的映射参数,获取到 DoubleStream 对象后,调用该对象的 sum() 方法,就可以计算出销售部的薪资总和。具体代码如下:
import java.util.List;
import java.util.stream.DoubleStream;
import java.util.stream.Stream;
public class MapToInDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 将所有开发部的员工过滤出来
stream = stream.filter(people -> "销售部".equals(people.getDept()));
// 将所有员工的名字映射成一个新的流对象
DoubleStream salarys = stream.mapToDouble(Employee::getSalary);
// 统计流中元素的数学总和
double sum = salarys.sum();
System.out.println("销售部一个月的薪资总额:"+sum);
}
}运行结果如下:
销售部一个月的薪资总额:13000.0除 DoubleStream 类外,java.util.stream 包还提供了 IntStream 类和 LongStream 类以应对不同的计算场景。
数据查找
本节所讲的数据查找并不是在流中获取数据(这属于数据过滤),而是判断流中是否有符合条件的数据,查找的结果是一个 boolean 值或一个 Optional 类的对象。本节将讲解 allMatch()、anyMatch()、noneMatch() 和 findFirst() 4个方法。
allMatch()方法
allMatch() 方法是 Stream 接口提供的方法,该方法会判断流中的元素是否全部符合某一条件,返回结果是 boolean 值。如果所有元素都符合条件,则返回 true,否则返回 false。
【例14.23】检查所有员工的年龄是否都大于25岁(实例位置:资源包\TM\sl\14\23)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,使用 allMatch() 方法检查公司所有员工的年龄是否都大于25岁,具体代码如下:
import java.util.List;
import java.util.stream.Stream;
public class AllMatchDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 判断所有员工的年龄是否都大于25
boolean result = stream.allMatch(people -> people.getAge() > 25);
System.out.println("所有员工是否都大于25岁:" + result); // 输出结果
}
}运行结果如下:
所有员工的年龄是否都大于25岁:false最后得出的结果是 false,因为公司里的 “小马” 和 “小王” 的年龄都只有 21 岁,而 “小刘” 的年龄只有 24 岁,不满足 “所有员工的年龄都大于25岁” 这个条件。
anyMatch()方法
anyMatch() 方法是 Stream 接口提供的方法,该方法会判断流中的元素是否有符合某一条件,只要有一个元素符合条件就返回 true,如果没有元素符合条件,则会返回 false。
【例14.24】检查是否有年龄大于或等于40岁的员工(实例位置:资源包\TM\sl\14\24)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,使用 anyMatch() 方法检查公司里是否有年龄在40岁或40岁以上的员工,具体代码如下:
import java.util.List;
import java.util.stream.Stream;
public class AnyMatchDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 判断员工是否有的年龄大于等于40
boolean result = stream.anyMatch(people -> people.getAge() >= 40);
System.out.println("员工中有年龄在40或以上的吗?:" + result); // 输出结果
}
}运行结果如下:
员工中有年龄在40岁或以上的吗?:true运行结果为 true,因为公司里的 “老张” 正好 40 岁,符合 “有年龄在40岁或以上的员工” 的条件。
noneMatch()方法
noneMatch() 方法是 Stream 接口提供的方法,该方法会判断流中的所有元素是否都不符合某一条件。这个方法的逻辑和 allMatch() 方法正好相反。
【例14.25】检查公司是否不存在薪资小于2000元的员工(实例位置:资源包\TM\sl\14\25)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,使用 noneMatch() 方法检查公司里是否没有薪资小于2000元的员工,具体代码如下:
import java.util.List;
import java.util.stream.Stream;
public class NoneMathchDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 判断公司中是否不存在薪资小于2000的员工?
boolean result = stream.noneMatch(people -> people.getSalary() <2000 );
System.out.println("公司中是否不存在薪资小于2000元的员工?:" + result);// 输出结果
}
}运行结果如下:
公司中是否不存在薪资小于2000元的员工?:true公司最低薪资是3000元,也就是说没有员工的薪资会小于2000元,因此结果为true。
findFirst()方法
findFirst() 方法是 Stream 接口提供的方法,这个方法会返回符合条件的第一个元素。
【例14.26】找出第一个年龄等于21岁的员工(实例位置:资源包\TM\sl\14\26)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,首先将年龄为21岁的员工过滤出来,然后使用 findFirst() 方法获取第一个员工,具体代码如下:
import java.util.List;
import java.util.Optional;
import java.util.stream.Stream;
public class FindFirstDemo {
public static void main(String[] args) {
// 获取公共类的测试数据
List<Employee> list = Employee.getEmpList();
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 过滤出21岁的员工
stream = stream.filter(people -> people.getAge() == 21);
Optional<Employee> young = stream.findFirst(); // 获取第一个元素
Employee emp = young.get(); // 获取员工对象
System.out.println(emp); // 输出结果
}
}运行结果如下:
name=小马, age=21, salary=3000.0, sex=男, dept=开发部公司里有两个 21 岁的员工,一个是 “小马”,一个是 “小王”。因为 “小马” 在集合中的位置靠前,所以 findFirst() 方法获取的是 “小马”。
|
这个方法的返回值不是 boolean 值,而是一个 Optional 对象。 |
数据收集
数据收集可以理解为高级的 “数据过滤+数据映射”,是对数据的深加工。本节将讲解两种实用场景:数据统计和数据分组。
数据统计
数据统计不仅可以筛选出特殊元素,还可以对元素的属性进行统计计算。这种复杂的统计操作不是由 Stream 实现的,而是由 Collectors 收集器类实现的,收集器提供了非常丰富的 API,有着强大的数据挖掘能力。
【例14.27】统计公司各项数据,并输出报表(实例位置:资源包\TM\sl\14\27)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,不使用 filter() 方法对元素进行过滤,而是直接使用 Stream 接口和 Collectors 类的方法对公司各项数据进行统计,具体代码如下:
import java.util.Comparator; // 比较器接口
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
public class ReducingDemo {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取测试数据
long count = list.stream().count(); // 获取总人数
// 下行代码也能实现获取总人数效果
// count = stream.collect(Collectors.counting());
System.out.println("公司总人数为:" + count);
// 通过Comparator比较接口,比较员工年龄,再通过Collectors的maxBy()方法取出年龄最大的员工的Optional对象
Optional<Employee> ageMax = list.stream().collect(Collectors.maxBy(Comparator.comparing(Employee::getAge)));
Employee older = ageMax.get();// 获取员工对象
System.out.println("公司年龄最大的员工是:\n " + older);
// 通过Comparator比较接口,比较员工年龄,再通过Collectors的minBy()方法取出年龄最小的员工的Optional对象
Optional<Employee> ageMin = list.stream().collect(Collectors.minBy(Comparator.comparing(Employee::getAge)));
Employee younger = ageMin.get();// 获取员工对象
System.out.println("公司年龄最小的员工是:\n " + younger);
// 统计公司员工薪资总和
double salarySum = list.stream().collect(Collectors.summingDouble(Employee::getSalary));
System.out.println("公司的薪资总和为:" + salarySum); // 输出结果
// 统计公司薪资平均数
double salaryAvg = list.stream().collect(Collectors.averagingDouble(Employee::getSalary));
// 使用格式化输出,保留2位小数
System.out.printf("公司的平均薪资为:%.2f\n", salaryAvg);
// 创建统计对象,利用summarizingDouble()方法获取员工薪资各方面的统计数据
java.util.DoubleSummaryStatistics s = list.stream().collect(Collectors.summarizingDouble(Employee::getSalary));
System.out.print("统计:拿薪资的人数=" + s.getCount() + ", ");
System.out.print("薪资总数=" + s.getSum() + ", ");
System.out.print("平均薪资=" + s.getAverage() + ", ");
System.out.print("最大薪资=" + s.getMax() + ", ");
System.out.print("最小薪资=" + s.getMin() + "\n");
// 将公司员工姓名拼成一个字符串,用逗号分隔
String nameList = list.stream().map(Employee::getName).collect(Collectors.joining(", "));
System.out.println("公司员工名单如下:\n " + nameList);
}
}运行结果如下:

这是一个复杂的例子,里面涉及人数统计、比较年龄取最大年龄和最小年龄员工、统计薪资总和、求平均薪资等。最后两项比较特殊:一个是获取统计数字的类,即 DoubleSummaryStatistics,这个类本身就包含了个数、总和、均值、最大值、最小值 5 个属性;另一个是在获取员工映射名单时又进行了加工,即将所有名字拼接成了一个字符串,并在名字之间用逗号分隔。
数据分组
数据分组就是将流中元素按照指定的条件分开进行保存,类似 SQL 语言中的 “GROUP BY” 关键字。分组之后的数据会被按照不同的标签分别保存成一个集合,然后按照 “键-值” 关系封装在 Map 对象中。
数据分组有一级分组和多级分组两种场景,首先先来介绍一级分组。
一级分组,就是将所有数据按照一个条件进行归类。例如,学校有100名学生,这些学生分布在3个年级中。学生被按照年级分成了3组,然后就不再细分了,这就属于一级分组。
Collectors 类提供的 groupingBy() 方法就是用来进行分组的方法,方法参数是一个 Function 接口对象,收集器会按照指定的函数规则对数据进行分组。
【例14.28】将所有员工按照部门进行分组(实例位置:资源包\TM\sl\14\28)
本例使用了例14.14定义的 Employee 类,在获取员工集合后,创建 Function 接口对象 f,f 引用 Employee 员工类的 getDept() 方法获取部门名称。然后,流的收集器类按照 f 的规则进行分组,Stream 对象将分组结果赋值给一个 Map 对象,Map 对象将会以 “key:部门,value:员工List” 的方式保存数据。具体代码如下:
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class GroupingDemo1 {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 分组规则方法,按照员工部门进行分级
Function<Employee, String> f = Employee::getDept;
// 按照部门分成若干List集合,集合中保存员工对象,返回成Map
Map<String, List<Employee>> map = stream.collect(Collectors.groupingBy(f));
Set<String> keySet = map.keySet(); // 获取Map的中的所有部门名称
for (String deptName : keySet) { // 遍历部门名称集合
// 输出部门名称
System.out.println("【" + deptName + "】 部门的员工列表如下:");
List<Employee> deptList = map.get(deptName); // 获取部门名称对应的员工集合
for (Employee emp : deptList) { // 遍历员工集合
System.out.println(" " + emp); // 输出员工信息
}
}
}
}运行结果如下:
【销售部】 部门的员工列表如下:
name=大刚, age=32, salary=7500.0, sex=男, dept=销售部
name=翠花, age=28, salary=5500.0, sex=女, dept=销售部
【人事部】 部门的员工列表如下:
name=老王, age=35, salary=6000.0, sex=女, dept=人事部
name=小王, age=21, salary=3000.0, sex=女, dept=人事部
【开发部】 部门的员工列表如下:
name=小刘, age=24, salary=5000.0, sex=女, dept=开发部
name=小马, age=21, salary=3000.0, sex=男, dept=开发部
【运营部】 部门的员工列表如下:
name=老张, age=40, salary=9000.0, sex=男, dept=运营部本例有两个难点:
-
分组规则是一个函数,这个函数是由 Collectors 收集器类调用的,而不是 Stream 流对象。
-
Map<K,List<T>> 有两个泛型,第一个泛型是组的类型,第二个泛型是组内的元素集合类型。本例是将所有员工按照部门名称进行分组的,因此 K 的类型是 String 类型;部门内的元素是员工集合,因此 List 集合泛型T的类型就应该是 Employee 类型。
介绍完一级分组后,再介绍复杂的多级分组。
一级分组是按照一个条件进行分组的,那么多级分组就是按照多个条件进行分组的。还是用学校举例,学校有 100 名学生,这些学生分布在 3 个年级中,这是一级分组,但每个年级还有若干个班级,学生被分到不同年级之后又被分到不同的班里,这就是二级分组。如果学生再被按男女分组,就变成了三级分组。元素按照两个以上的条件进行分组,就是多级分组。
Collectors 类提供的 groupingBy() 方法还提供了一个重载形式:
groupingBy(Function<? super T,? extends K> classifier, Collector<? super T,A,D> downstream)这个重载方法的第二个参数也是一个收集器,当分组前数据包含其他分组的结果,这就构成了多级分组功能。
【例14.29】将所有员工先按照部门分组,再按照性别分组(实例位置:资源包\TM\sl\14\29)
在一级分组实例的基础上,首先创建 Function 接口对象 deptFunc 以用于引用获取部门的方法,再创建 Function 接口对象 sexFunc 以用于引用获取性别的方法(这两个对象将作为一级分组和二级分组的函数规则),最后将按照性别分组的 Collectors.groupingBy(sexFunc) 方法作为另一个 groupingBy() 方法的参数,按照部门进行分组,这样就实现了二级分组,具体代码如下:
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class GroupingDemo2 {
public static void main(String[] args) {
List<Employee> list = Employee.getEmpList(); // 获取公共类的测试数据
Stream<Employee> stream = list.stream(); // 获取集合流对象
// 一级分组规则方法,按照员工部门进行分级
Function<Employee, String> deptFunc = Employee::getDept;
// 二级分组规则方法,按照员工部门进行分级
Function<Employee, String> sexFunc = Employee::getSex;
// 将流中的数据进行二级分组,先对员工部分进行分组,在对员工性别进行分组
Map<String, Map<String, List<Employee>>> map = stream
.collect(Collectors.groupingBy(deptFunc, Collectors.groupingBy(sexFunc)));
// 获取Map的中的一级分组键集合,也就是部门名称集合
Set<String> deptSet = map.keySet();
for (String deptName : deptSet) { // 遍历部门名称集合
// 输出部门名称
System.out.println("【" + deptName + "】 部门的员工列表如下:");
// 获取部门对应的二级分组的Map对象
Map<String, List<Employee>> sexMap = map.get(deptName);
// 获得二级分组的键集合,也就是性别集合
Set<String> sexSet = sexMap.keySet();
for (String sexName : sexSet) { // 遍历部门性别集合
// 获取性别对应的员工集合
List<Employee> emplist = sexMap.get(sexName);
System.out.println(" 【" + sexName + "】 员工:"); // 输出性别种类
for (Employee emp : emplist) {// 遍历员工集合
System.out.println(" " + emp); // 输出对应员工信息
}
}
}
}
}运行结果如下:
【销售部】 部门的员工列表如下:
【女】 员工:
name=翠花, age=28, salary=5500.0, sex=女, dept=销售部
【男】 员工:
name=大刚, age=32, salary=7500.0, sex=男, dept=销售部
【人事部】 部门的员工列表如下:
【女】 员工:
name=老王, age=35, salary=6000.0, sex=女, dept=人事部
name=小王, age=21, salary=3000.0, sex=女, dept=人事部
【开发部】 部门的员工列表如下:
【女】 员工:
name=小刘, age=24, salary=5000.0, sex=女, dept=开发部
【男】 员工:
name=小马, age=21, salary=3000.0, sex=男, dept=开发部
【运营部】 部门的员工列表如下:
【男】 员工:
name=老张, age=40, salary=9000.0, sex=男, dept=运营部这个结果先按照部门进行了分组,然后又对部门中的男女进行了二级分组。这个实例也有两个难点。
-
实例中两个 groupingBy() 方法的参数不一样,一个是 groupingBy (性别分组规则),另一个是 groupingBy (部门分组规则, groupingBy(性别分组规则) )。
-
在获得的 Map 对象中,还嵌套了 Map 对象,它的结构是这样的:
Map<部门, Map<性别, List<员工>>>
从左数,第一个 Map 对象做了一级分组,第二个 Map 对象做了二级分组。
编程训练(答案位置:资源包\TM\sl\14\编程训练)
【训练4】统计男员工的总人数 结合本节的内容,统计男员工的总人数。
【训练5】找出所有薪资高于5000元的女员工 结合本节的内容,找出所有薪资高于5000元的女员工。