进阶
通过前面几小节,相信读者已经对用于 PHP 普通字符串存储的 zend_string 结构体及用于频繁拼接字符串的 smart_str 结构体有了一定的了解。本节会结合 PHP 代码示例,介绍 PHP 字符串的主要特性。
字符串的赋值与写时分离
PHP 7 提供了比较节省内存的赋值操作,字符串在赋值时并不直接拷贝一份数据,而是进行 zend_string 中的 refcount++,字符串销毁时再进行 zend_string 中的 refcount--。这一节主要讲解字符串在赋值操作时 refcount 的变化,介绍字符串变量 写时分离 的概念。
讲解之前,先定义两个概念。
-
常量字符串:PHP 代码中硬编码的字符串,是在编译阶段初始化,最初存储在
CG(active_op_array).Literals中(添加的同时也往CG(interned_strings)hash表写入),在执行阶段,经过oparray传递到execute_data.literals中存储。 -
临时字符串:计算出来的临时字符串,是执行阶段经
zend虚拟机执行opcode对应方法计算所得到的字符串,存储在execute_data结构体中的临时变量区。详见示例:
<?PHP
$a = 'hello'; /*“hello” 为常量字符串*/
$b = 'time:'.time(); /*“time:” 为常量字符串,'time:'.time() 计算返回的字符串为临时字符串*/
?>字符串赋值操作中 refcount 的变化
一般认为,当字符串进行赋值操作时,对应字符串会 refcount++,但实际情况却并不总是如此,这里一一举例罗列出来了每种情况。
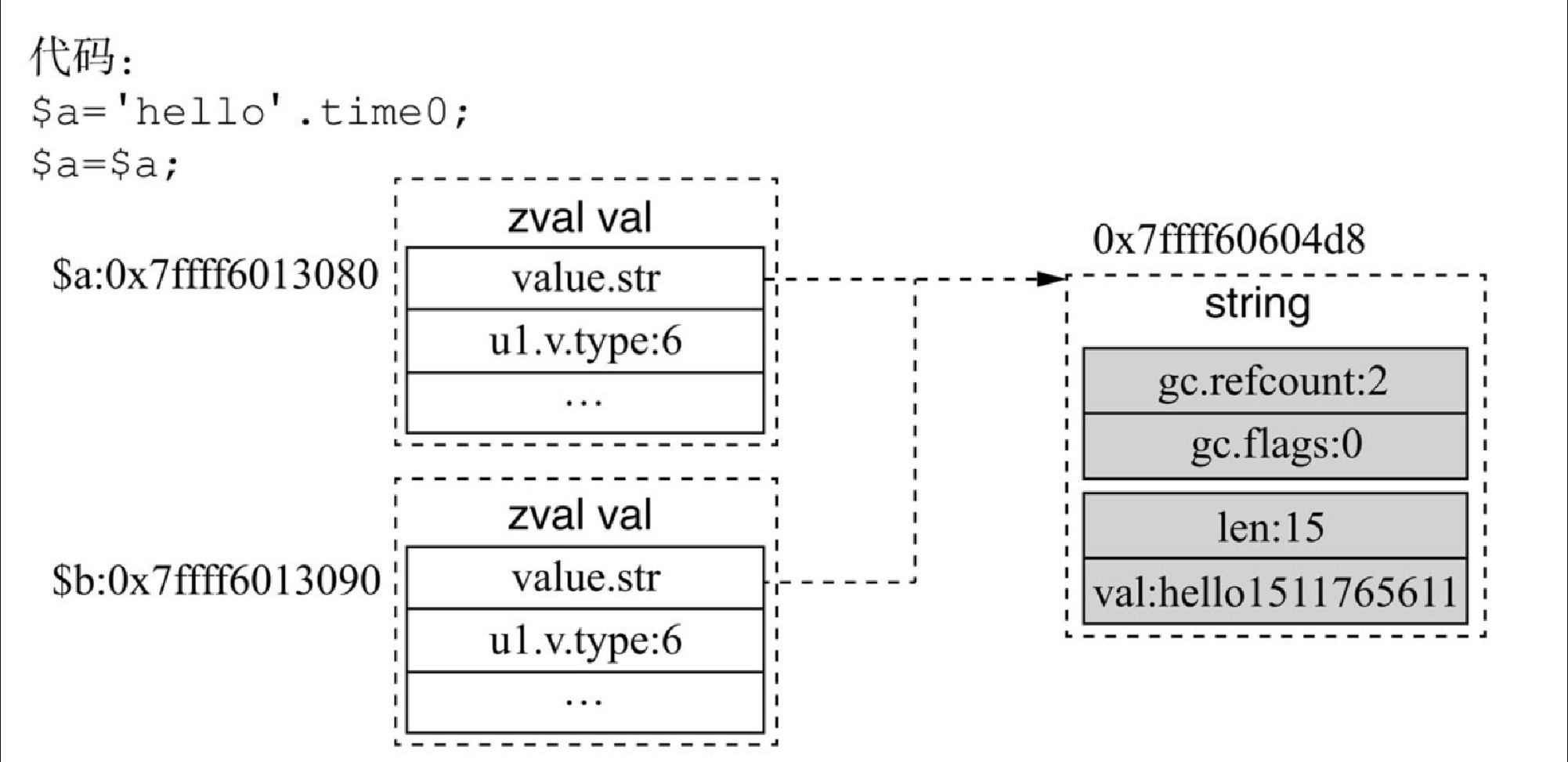
(1)临时字符串的赋值
$a = 'hello'.time(); /*$a的gc.refcount=1*/
$b = $a; /*$a、$b指向同一块地址,gc.refcount=2*/当字符串的值不是一个常量字符串时,每次赋值会执行字符串的 refcount++,示例代码 'hello'.time() 实际包含两部分:一部分是常量字符串 'hello',而 time() 可以理解为函数调用返回的临时值,两者相连后就是临时字符串。临时字符串的 gc.flags 被标识成 0,此类字符串在请求结束后或 refcount=0 时会被销毁。
上述示例代码完成赋值后 $a 与 $b 的关系如图 4-6 所示。
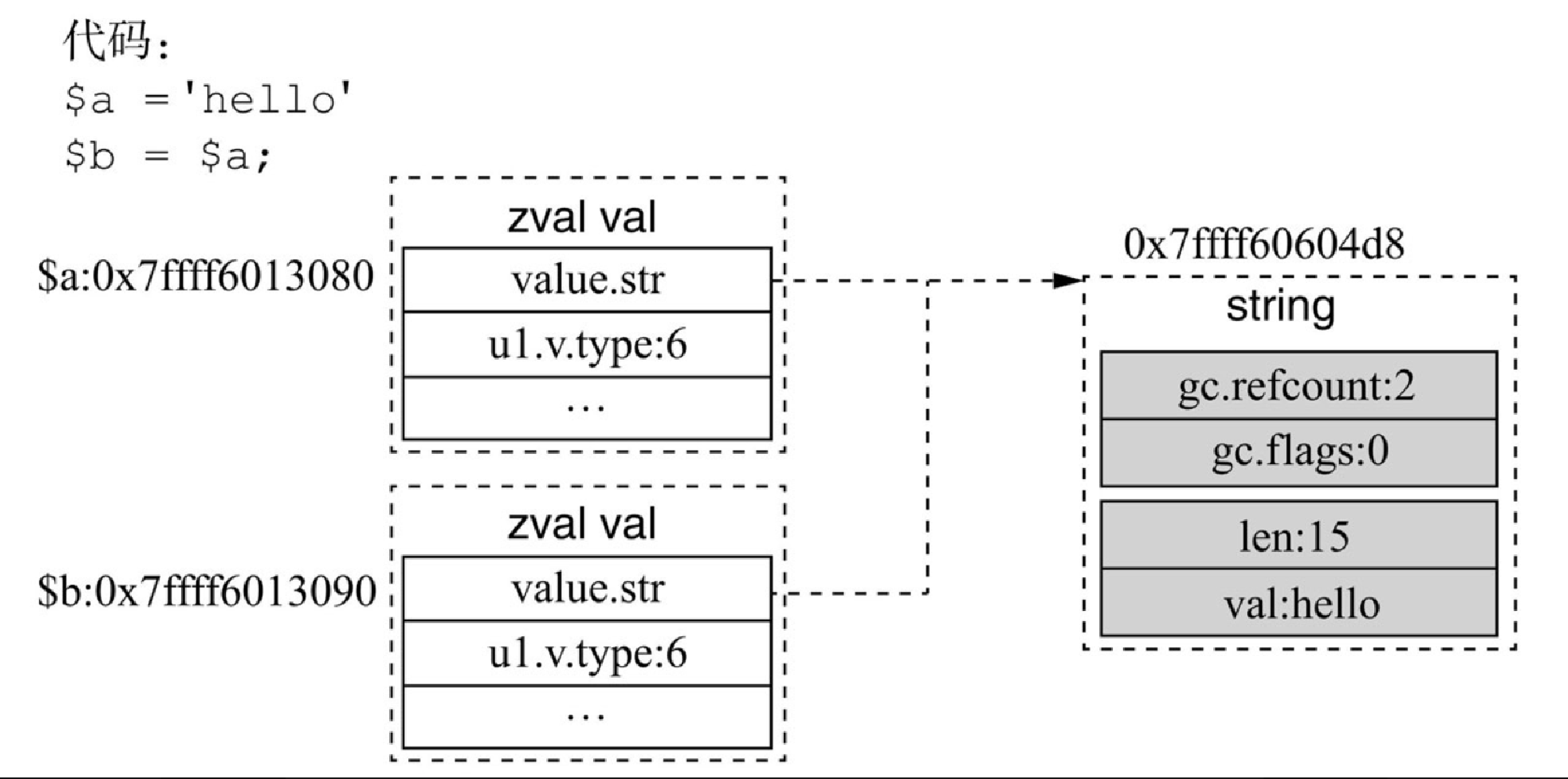
(2)字符串常量的赋值
$a = 'hello'; /* $a的gc.refcount=0 */
$b = $a; /* $b的gc.refcount=0 */当字符串是常量字符串时,赋值只修改 zval 中 str 的指针地址,两个字符串指向同一个 str 地址,但是 refcount 的值始终都是 0。上述示例执行完后,$a 与 $b 指向的是同一个常量字符串 'hello',字符串的 gc.flags 会被标识成 2。此类字符串只有在请求结束后才会被销毁(开启了 opcache 的例外,字符串存储在共享内存,不会被销毁)。
上述示例代码完成赋值后 $a 与 $b 的关系如图4-7所示。
(3)整型常量的赋值
$a = 1; /* 或者$a = time(); */
$b = $a; /* zval是int类型,无refcount,会复制$a的值 */|
上述代码中常量 1 存储在 |
上述示例代码完成赋值后 $a 与 $b 的关系如图4-8所示。
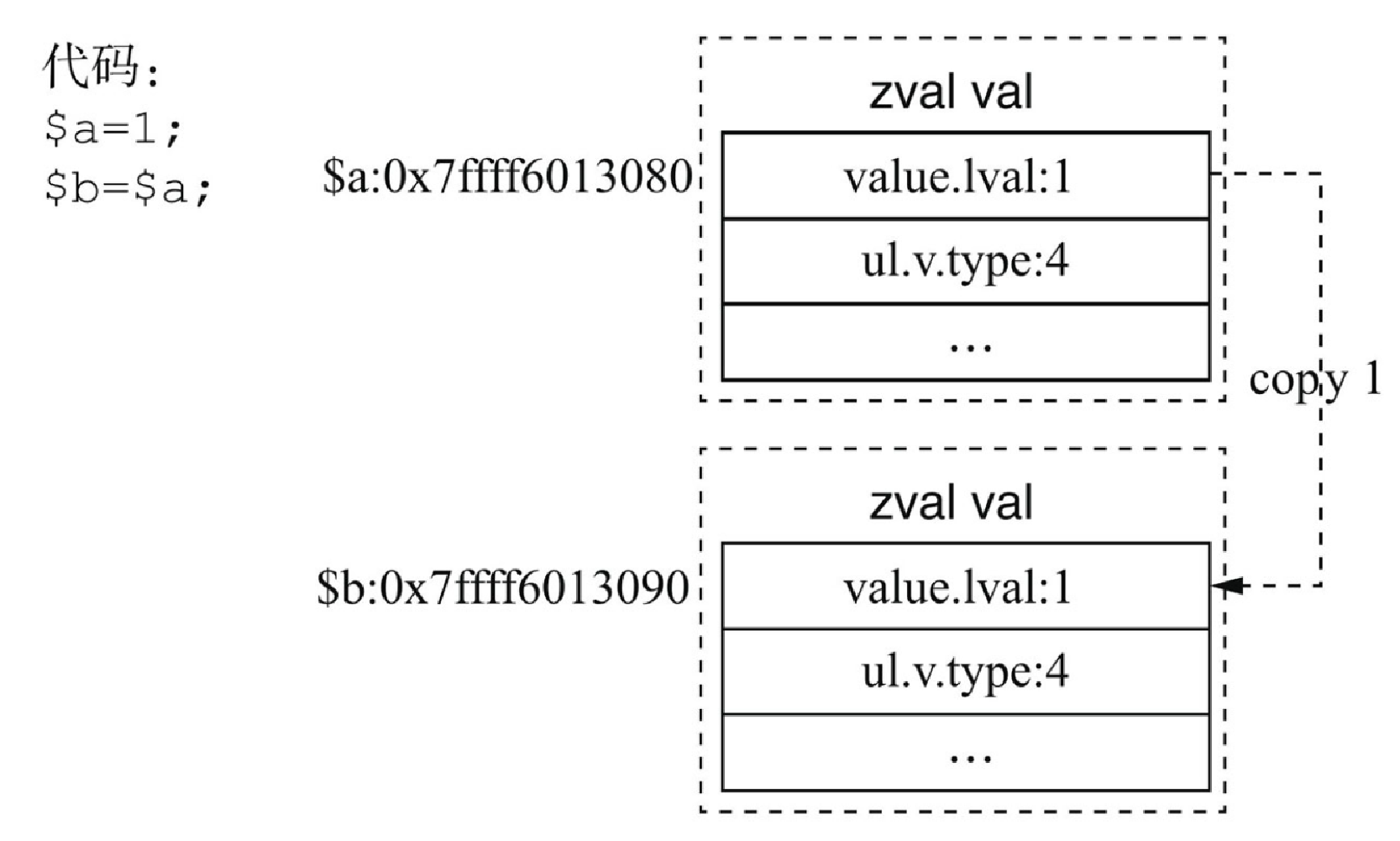
对比字符串赋值(见图4-7)后 $a 与 $b 的关系,可以发现当 $a 为整型数据时,值直接存储在 zval 结构体中,并无引用计数的变更,赋值操作是直接把 $a 的值拷贝到了 $b 的 zval.lval 字段中,因值存储少了一个 zend_string 结构体,相比字符串更省内存。因为有这样一个误区——字符串的赋值用了引用,实际上只有一份数据,而整型数据赋值直接拷贝,有多份数据,所以后者更占内存。这样的说法其实是错误的,所以笔者在这特意举例说明。
(4)字符串引用赋值
$a = 'hello';
$b = &$a; /*强制引用类型;*/当赋值为引用类型时 $a 与 $b 的关系会如何呢?演变过程如图4-9所示。
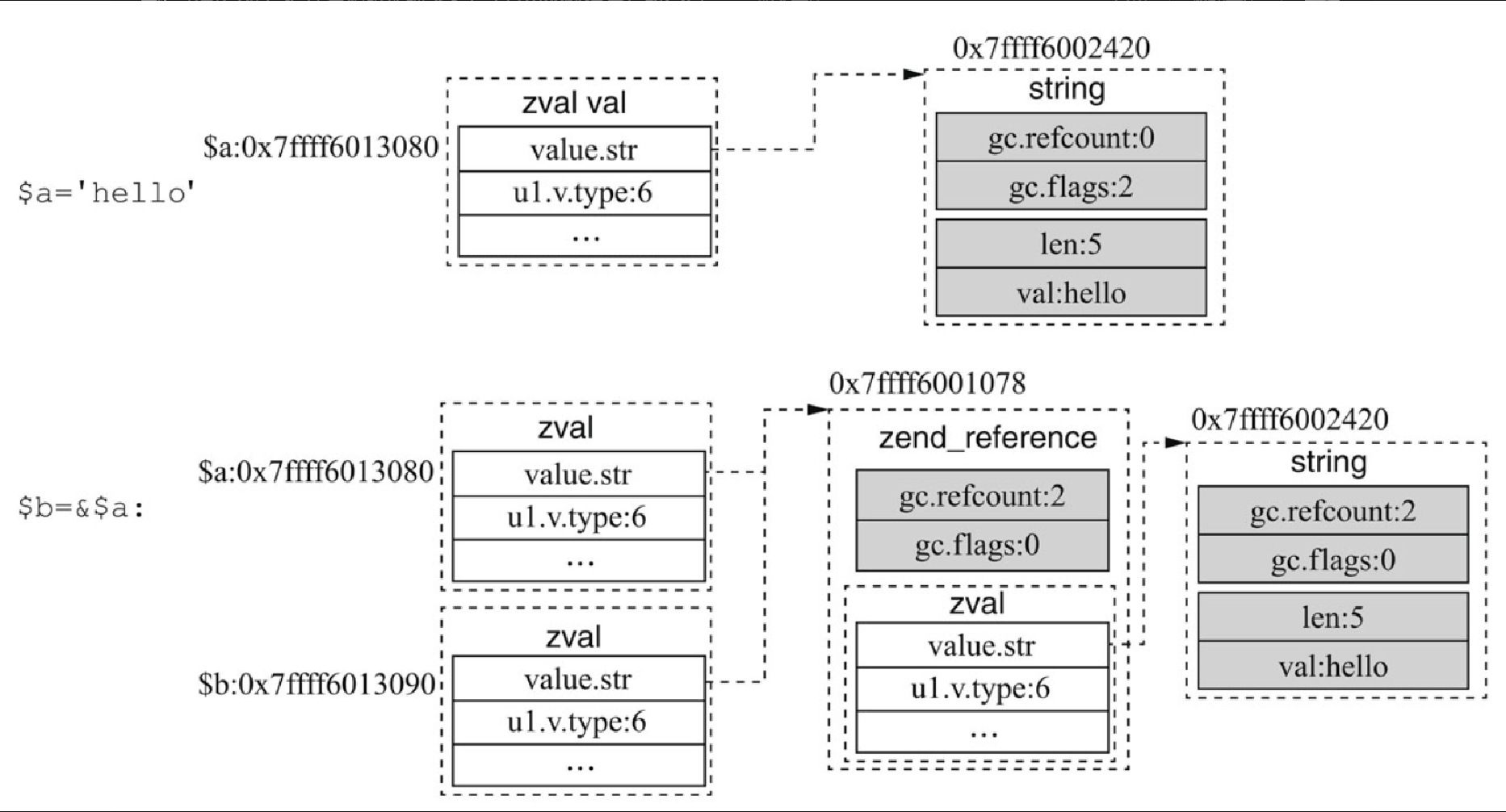
引用赋值时,会多出 zend_reference 结构体,里面包含 gc 及 zval 字段,赋值时 gc 进行 refcount++,字符串的引用赋值和其他类型引用赋值的实现方式都是一样的。结合前面 4 个示例,可以知道不是所有的 PHP 变量赋值都会用到引用计数,对于一个能否使用引用计数的变量也分以下几个类别:
-
变量是简单类型(
true/false/double/long/null)时直接拷贝值,不需要引用计数; -
变量是临时的字符串,在赋值时会用到引用计数,但如果变量是字符常量,则不会用到;
-
变量是对象(
zval.v.type=IS_OBJECT)、资源(zval.v.type=IS_RESOURCE)、引用(zval.v.type=IS_REFERENCE,即$a=&$b)类型时,赋值一定会用到引用计数; -
变量是普通的数组,赋值时也会用到引用计数,变量是
IS_ARRAY_IMMUTABLE时,赋值不使用引用计数。
一个 zval 是否支持引用计数,是通过 zval.u1.type_flag 来标识的,当 type_flag 的第三位被标识成 1(IS_TYPE_REFCOUNTED 标识),则代表可以引用计数。当然 type_flag 除了标识 zval 是否支持引用计数外,剩下的几位还可做其他标识,按位分割使用。
字符串的写时分离
当字符串的 refcount>1 时,也就是有多个变量引用同一块内存值,对其中一个变量的值进行修改,会触发写时分离,此机制的好处就是,保证了各变量间的独立性。
结合 PHP 代码来看:
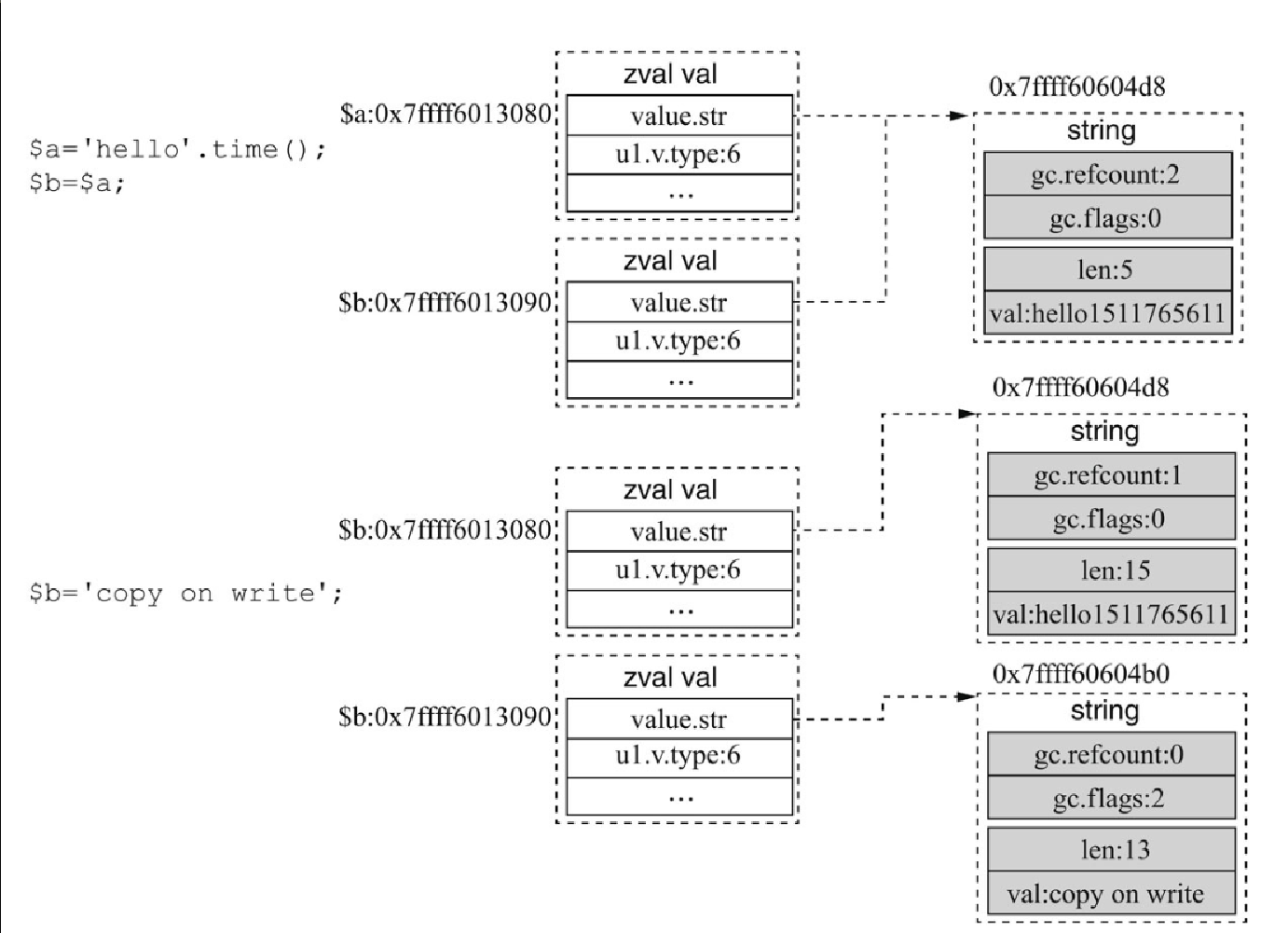
$a = 'hello'.time(); /*$a的string.gc.refcount=1*/
$b = $a; /*$a、$b指向同一块地址,refcount=2*/
$b = 'copy on write'; /*写时分离,$b的refcount=0, $a的refcount=1*/变量 $a 和 $b 的值会指向同一个字符串,$b 的值改变,并不影响 $a 的值,这是通过写时分离实现的,变量 $a 和 $b 的内存演变过程如图4-10所示。(图片中 $b 应该为 $a,而且 $b 现在指向新的字符串空间值,引用计数为 1。)
|
只有 |
字符串的类别(内部字符串)
PHP 源码为了实现对特殊字符串的管理,会给字符串分类,实现方式就是利用 zend_string 结构体里面的 gc.u.flags 字段,gc.u.flags 总共有 8 位,每个类别占一位,可以重复打标签,理论上最多打 8 种标签。目前 PHP 7 源码主要涉及以下几种:
-
对于临时的普通字符串,
flags字段被标识为 0。 -
对于内部字符串,用于存储 PHP 代码中的字面量、标识符等,
flags字段被标识成IS_STR_PERSISTENT | IS_STR_INTERNED。 -
对于 PHP 已知字符串,
flags字段会被标识成IS_STR_PERSISTENT | IS_STR_INTERNED | IS_STR_PERMANENT。
|
几个概念的定义。
|
其中宏 IS_STR_PERSISTENT、IS_STR_INTERNED、IS_STR_PERMANENT 的定义如下:
#define IS_STR_PERSISTENT (1<<0) /* 通过malloc分配的固定内存*/
/* PHP代码里写的一些字符串,比如函数名、变量值、变量名、类名等*/
#define IS_STR_INTERNED (1<<1)
/* 永久值,生命周期大于请求,比如PHP的关键字:class、function等*/
#define IS_STR_PERMANENT (1<<2)
#define IS_STR_CONSTANT (1<<3)
#define IS_STR_CONSTANT_UNQUALIFIED(1<<4)需要将特殊字符串区分出来的原因,不妨先从现有的字符串类别说起,下面是所有的字符串类别的解释。
IS_STR_PERSISTENT 字符串
PHP 已知字符串、PHP 代码中的字面量、标识符等字符串,在初始化这些字符串时会调用 zend_string_alloc 函数,此时,第二个参数 persistent 传入 1,最终会调用 malloc 函数分配内存,不会走 PHP 的内存池函数。初始化完后该字符串也会被打上 IS_STR_PERSISTENT 标签。如果想释放这类字符串,就得通过调用 free 函数释放内存,一般这样申请的字符串都是常驻内存的(未开启 opcache 时例外,详见注释),不会随着请求的结束而被回收。
|
未开启 |
IS_STR_INTERNED 内部字符串
(1)含义
内部字符串主要指的是 PHP 已知字符串、PHP 代码中的字面量、标识符等字符串。内部字符串的 flags 都会被打上 IS_STR_INTERNED 标签,也就是说,PHP 代码中你所写的及所看到的任何字符串在底层存储时都会被打上 IS_STR_INTERNED 标签。
(2)存储
全部的内部字符串存储在 CG(interned_strings) 哈希表中,初始化是在 php_module_startup 阶段进行,并且在该阶段会把 PHP 已知字符串写入 interned_strings 数组,具体初始化及写入过程如下。
-
调用
zend_interned_strings_init方法初始化CG(interned_strings)数组,大小为 1024。 -
zend_interned_strings_init初始化的同时也会把PHP的保留字写入到CG(interned_strings)哈希表。//保留字主要包含以下这些 "file", "line", "function", "class", "object", "type", "->", "::", "args", "unknown", "eval", "include", "require", "include_once", "require_once", "scalar", "error_ reporting", "static", "this", "value", "key", "__autoload", "__invoke", "previous", "code", "message", "severity", "string", "trace"; -
调用
php_startup_auto_globals,把全局变量名写入进去。例如,_GET、_POST、_COOKIE、_SERVER、_REQUEST、_FILES、_ENV等。 -
调用
php_register_internal_extensions_func,把内部函数名写入进去。例如,strncasecmp、interface_exists、class_exists等。 -
调用
php_register_extensions,把扩展函数写入进去。例如,date、strtotime等。 -
调用
zend_register_default_classes,把内部类名写入进去。例如,stdClass、Iterator-Aggregate等。 -
上述步骤执行完后还会继续调用
zend_interned_strings_snapshot_int方法,给所有的字符串打上IS_STR_PERMANENT标签。也就是,这些是永久存储的字符串,请求结束时并不会去销毁这些字符串,只有当进程结束时才会销毁它们(例如,cli模式,每次执行完都会执行销毁操作,php-fpm则不会)。
除了在 php_module_startup 阶段会写入字符串到 CG(interned_strings) 数组中,在编译阶段也会写入,具体过程如下。
调用 zend_compile_top_stmt 方法,深度遍历 AST 生成 oparray 时,当遇到 PHP 代码中的字面量、标识符等,都会将这一类字符串写入到 CG(interned_strings) 数组中,它们只会被标识成 IS_STR_INTERNED。如果未开启 opcache,它们会随着请求结束而销毁。
为了让读者更好地理解内部字符串的作用,现结合 PHP 代码举例说明:
<?PHP
$a = 'hello';
$c = 'hello';
$b = 'word';上述 PHP 代码中的变量名 “a”、“b”、“c” 及变量值 “hello”、“word” 在经过 zend_compile_top_stmt 方法编译解析成 oparray 后,都会被标识成 IS_STR_INTERNED 类型,同时写入到 CG(interned_strings) 数组中,关键点在于 $a 和 $c 的值 “hello” 指向的字符串内存地址是相同的,为什么呢?在生成 oparray 之前,变量名 “a”、“b”、“c” 及变量值 “hello”、“word” 存储在 CG(AST) 中,此时它们并不是一个内部字符串,在解析 AST 生成 oparray 的过程中,会检测当前取到的字符串是否已存在于 CG(interned_strings) 数组中。若存在,则释放字符串本身内存,并把存在的字符串地址返回;若不存在,字符串则插入 CG(interned_strings) 数组中,并打上 IS_STR_INTERNED 标签。这也是变量 “a” 和 “c” 的值 “hello” 复用一块内存地址的原因,所以内部字符串都写入 CG(interned_strings) 数组中的一大作用是,避免了重复存储,可以节省内存。
开启了 opcache 的内部字符串存储。
以 php-fpm 为例,当 PHP 未开启 opcache 时,interned_strings 数组是在 fork 子进程开始之前就被初始化了(php_module_startup 阶段,这时候主要包含 PHP 已知字符串), fork 子进程开始后相当于每个进程都拷贝存储了一份数据,而开启了 opcache 则不一样,内部字符串存储在共享内存中,即存储在 ZCSG(interned_strings) 数组中,所存储的数据基本和未开启 opcache 进程的内容一致,但也有区别,在于 ZCSG(interned_strings) 中的字符串除了 PHP 已知字符串被标识成永久字符串外,PHP 代码中的字面量、标识符等也会被标识成永久字符串,不会随着请求结束而销毁。
(3)作用
前面讲了,所有的内部字符串需插入到 CG(interned_strings) 哈希表中,主要的作用如下。
-
省内存,针对 PHP 代码重复出现的字符串会合并成一个字符串,任凭代码中写了一万个
“hello”,一万个变量“a”,都只存一份,节省内存。 -
内部字符串不会被
zend_string_release函数回收,放在interned_strings中的字符串可以在多次请求间重复使用(未开启opcache时,PHP 代码中的字面量、标识符等字符串除外)。 -
方便销毁管理,正因为调用
zend_string_release等方法不会释放内部字符串的内存,而将它们又放在一起,方便销毁管理。
(4)释放
因为有了 interned_strings 哈希表,释放内部字符串比较简单,直接循环遍历 interned_strings 数组就可以销毁全部的内部字符串,但真正地释放内部字符串也分如下几种情况。
-
cli模式下的PHP进程:每次执行完都会调用php_module_shutdow,而这个阶段则会调用zend_interned_strings_dtor函数去销毁整个interned_strings数组。 -
未开启
opcache下的 PHP-fpm 进程:这类进程不会执行到php_module_shutdown阶段,但是在php_request_shutdown阶段会调用zend_interned_strings_restore_int方法销毁内部字符串。这个时候销毁的是 PHP 字面量及标识符等字符串,也就是 PHP 代码中的方法名、类名、字符常量、变量名等,随着请求的结束,这些内部字符串都要被销毁。
-
开启了
opcache下的 PHP 进程:进程开启了opcache,则interned_strings数组中的 PHP 代码里的字面量、标识符也会被标识成永久字符串。在php_request_shotdown阶段,永久字符串不会被销毁。代码中的方法名、类名、字符常量、变量名等可常驻内存,可在多次请求间复用。真正销毁阶段为opcache的zend_accel_fast_shutdown阶段,这时候才会销毁内部字符串的ZCSG(interned_strings)数组。
IS_STR_PERMANENT 永久字符串及其他
对于永久字符串(本身是内部字符串),flags 都会被打上 IS_STR_INTERNED 标签,它们在 php_module_startup 阶段初始化,属于永久值,常驻内存,生命周期不随着请求结束而结束,在进程结束时才会被销毁。
除了永久字符串,还有两个类别—— IS_STR_CONSTANT(常量)和 IS_STR_CONSTANT_UNQUALIFIED(并不常用),在这并不做过多的阐述。
看完字符串类别的介绍,此时应该可以较好地回答前面的问题,为什么需要区分出特殊字符串呢?是因为并不是所有的字符串都能被回收,特殊字符串很多都是进程级的,需要常驻内存,被标识出来后,便能较好地保护它们。
字符串的类型转换
介绍完字符串主要类型,这一节看一下经常用到的字符串转换函数。PHP 代码中,在一个值前面加上(string)、strval() 函数或在使用表达式时需要字符串,就会自动把数值转换为字符串,比如表达式 echo 输出时,就会发生这种转换成字符串的操作,那么是如何转换成字符串的呢?一起分析一下字符串转换函数——zval_get_string_func 函数,源码如下:
_zval_get_string_func(zval *op){
try_again:
switch (Z_TYPE_P(op)) {
case IS_UNDEF:
case IS_NULL:
case IS_FALSE:
return ZSTR_EMPTY_ALLOC(); /*返回空,CG(empty_string),该字段被初始化为空
字符串*/
case IS_TRUE:
return zend_string_init("1", 1, 0); /*返回一个值为1、长度为1,内存池申
请的字符串*/
case IS_RESOURCE: {
char buf[sizeof("Resource id #") + MAX_LENGTH_OF_LONG];
len = snprintf(buf, sizeof(buf), "Resource id #" ZEND_LONG_FMT, (zend_
long)Z_RES_HANDLE_P(op));
/*返回Resource id # + 资源类型的编号*/
return zend_string_init(buf, len, 0);
}
case IS_LONG: {
/*通过zend_long_to_str方法把int转换成字符串*/
return zend_long_to_str(Z_LVAL_P(op));
}
case IS_DOUBLE: {
return zend_strpprintf(0, "%.*G", (int) EG(precision), Z_DVAL_P(op));
/*格式化成字符串返回*/
}
case IS_ARRAY:
zend_error(E_NOTICE, "Array to string conversion");
/*返回值为Array的字符串*/
return zend_string_init("Array", sizeof("Array")-1, 0);
case IS_OBJECT: {
"Object of class %s could not be converted to string", ZSTR_VAL(Z_
OBJCE_P(op)->name)); /*直接报错*/
}
case IS_REFERENCE:
op = Z_REFVAL_P(op); /*引用,直接取出真正的zval再重新转换*/
goto try_again;
case IS_STRING:
return zend_string_copy(Z_STR_P(op));
}
}说明如下。
-
变量类型为未定义(
IS_UNDEF)、空(IS_NULL)、布尔值的FALSE时,会被转换成 “”(空字符串)返回。 -
变量类型为一个布尔值的
TRUE时,会被转换成字符串 “1” 返回。 -
变量类型为
IS_RESOURCE时,则被转成 “Resource id #” + 资源类型的编号的字符串返回。 -
变量类型为一个整数
IS_LONG,将通过zend_long_to_str函数转换成这一串数字的字符串。正负整数转换成字符串都调用此函数。
-
变量类型为
IS_DOUBLE,将通过zend_strpprintf方法转换为这一串数字的字符串。float类型的数据、指数计数数据,在 PHP 源码中都会被标识成IS_DOUBLE。例如,3.14、4.1E+2 都属于IS_DOUBLE。 -
变量类型为
IS_ARRAY,会转换成字符串“Array”,并写入一个“Array to string conversion”的通知,因此,echo和print无法打印出数组的内容。要打印某个单元,可以通过echo $arr['foo']这种结构。 -
变量类型为
IS_OBJECT时,将直接输出不可转换,且直接 PHP-error 报错——Object of class %s could not be converted to string。 -
变量类型为引用类似(
IS_REFERENCE),则取出里面关联的zval,再去转换。 -
变量类型为字符串
IS_STRING,将调用zend_string_copy函数,直接进行 refcount++ ,为什么需要 refcount++ 呢?假设是echo触发的类型转换,此时转换只是echo执行中的一个环节,变量还未使用完,不进行 refcount++,变量则有可能被其他环节释放,造成变量真正输出时不可用。
其他复杂的数值类型转换成字符串在理论上是无法实现的,所以基本上都是写死返回的字符串,这并不是真正意义上的转换,只有 double 转换成字符串及 int 转换成字符串是经过计算后返回的。这里,笔者主要分析 int 转换成字符串的算法,以 PHP 代码为例:
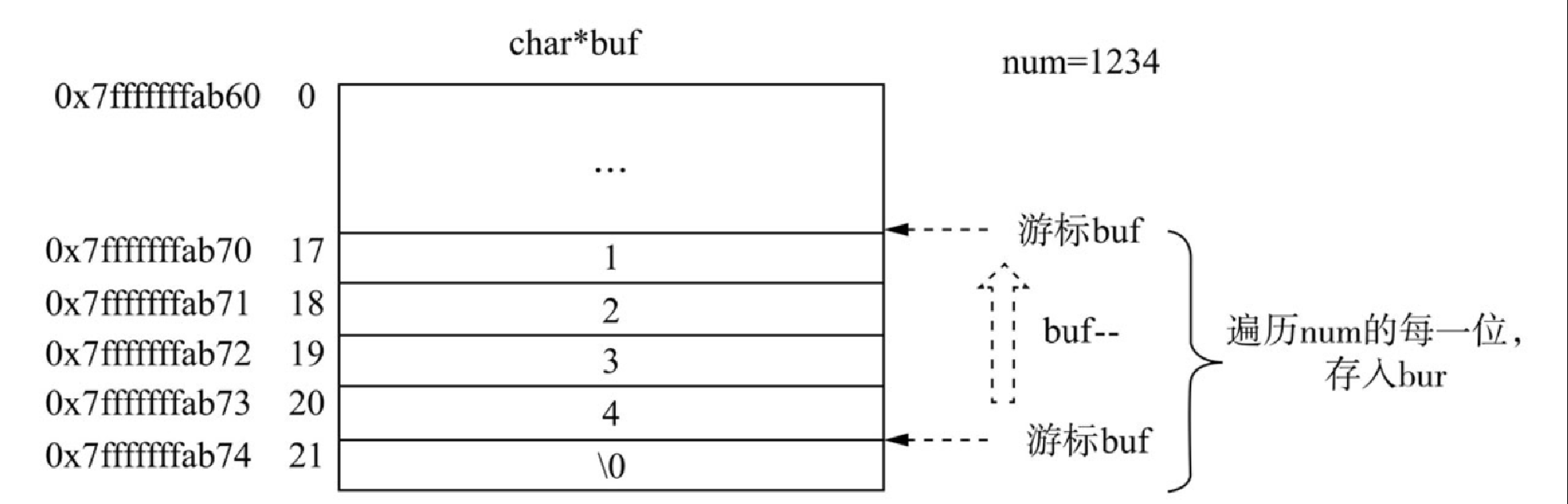
$a = 1234; /*num=1234*/
$b = (string)$a;
$c = strval($a);
$d = "$a"; /*双引号会转换成字符串*/
echo $a; /*输出时隐式转换成字符串*/看过第 3 章 zval 的实现应该知道,上段 PHP 代码中的 “1234” 实际存储在 zval.value.lval 中,那如何把 zval.value.lval 中的 int 数据转换成 zend_string 呢?核心源码如下:
zend_long_to_str(zend_long num)
{
char buf[MAX_LENGTH_OF_LONG + 1];
/*核心转换方法,对负数做处理,再调用zend_print_ulong_to_buf去转换*/
char res = zend_print_long_to_buf(buf + sizeof(buf) -1, num);
/*调用字符串管理函数,直接初始化一个zend_string并返回*/
return zend_string_init(res, buf + sizeof(buf) -1- res, 0);
}
/*int转成字符串的核心函数*/
zend_print_ulong_to_buf(char *buf, zend_long num) {
*buf = '\0';
do {
*--buf = (char) (num % 10) + '0';
num /= 10;
} while (num > 0);
return buf;
}-
第 1 步:初始化一个字符数组
buf,用于存储转换后的结果,大小为 21,(long int最多为 20 位+1,也就是 21 位的字符数组,+1 的原因是字符串末尾需要为 “\0”)。 -
第 2 步:把这个
buf偏移到末位地址及把int的num(即 1234)传入核心的转换函数。 -
第 3 步:转换函数把 buf 末尾置为 “\0”,代表字符串的结束。
-
第 4 步:循环遍历 num 的每一位,按照 4、3、2、1 等顺序依次从高位到低位地写入 buf 中。
-
第 5 步:遍历完毕,把赋值后的
buf传入zend_string_init,初始化一个新的字符串并返回,转换算法完毕。
核心的转换算法可参照图4-11所示。
转换算法中有一行代码可能比较难理解,需用到 ASCII 码的知识,笔者在这里粗略地讲解一下,代码如下:
*--buf = (char) (num % 10) + '0';num 取模+ '0' 表示相对字符 '0' 偏移多少位,计算完后 1 转换成字符 '1',2 转换成字符 '2',以此类推。
字符串的双引号与单引号
分析完字符串的类型转换后,接下来看字符串的单双引号。我们知道字符串可以用 4 种方式表达:单引号、双引号、heredoc 语法结构、nowdoc 语法结构(自PHP 5.3.0起),笔者在这一小节主要通过 PHP 示例代码并结合源码分析的方式,来讲解常用的单引号、双引号之间的区别及双引号解析变量的过程。
单双引号的转义区别
先看如下 PHP 示例代码。
示例1:
$b = "ab\0cd"; /* 转义后的值为ab\0cd */
$c = 'ab\0cd'; /* 值为ab\\0cd */
strlen($b); /* 长度为5 */
strlen($c); /* 长度为6 */同一个字符串,为什么经过双引号赋值后,其长度为 5,而经单引号赋值后,其长度却为 6 呢?
忽略代码注释,上述 PHP 代码存入文件的实际值如下:
<? PHP\n$b = \"ab\\0cd\"; \n$c = 'ab\\0cd'; \nstrlen($b); \nstrlen($c); \n? >\n
gdb 验证方式如下:
gdb PHP
b zend_stream_fixup /*Zend/zend_stream.c:180行*/
r str.PHP
执行到237行
*buf = mmap(0, size + ZEND_MMAP_AHEAD, PROT_READ, MAP_PRIVATE, fileno(file_
handle->handle.fp), 0); /*读取PHP代码文件
(gdb) p *buf
$36 = 0x7ffff7ff5000 "<? PHP\n$b = \"ab\\0cd\"; \n$c = 'ab\\0cd'; \nstrlen($b); \
nstrlen($c); \n? >\n"PHP 字符串 "ab\0cd" 实际存储在文件中的值是 \"ab\\0cd\",其中 \" 代表字符串的 ",\\ 代表字符串的 \,在词法解析之前,会先从文件中读取 PHP 代码串,之后词法解析器解析 PHP 代码串,并生成 AST。当解析到单引号的字符串时,从第一个单引号开始读取,到下一个单引号结束,这之间的字符串直接初始化成 zend_string 并返回(代码详见 zend_language_scanner.l:<ST_IN_SCRIPTING>b? [']),不会对里面的任何字符做特殊的解析。而做双引号处理时则不同,前面和单引号一样,但他会从第一个双引号开始读,读取到下一个双引号结束,但是结束时会把读取到的字符串传入 zend_scan_escape_string 方法进行转义(代码详见 zend_language_scanner.l:<ST_IN_SCRIPTING>b? ["])。
根据 zend_scan_escape_string 函数可得出一个转义对照表,如表4-1所示。
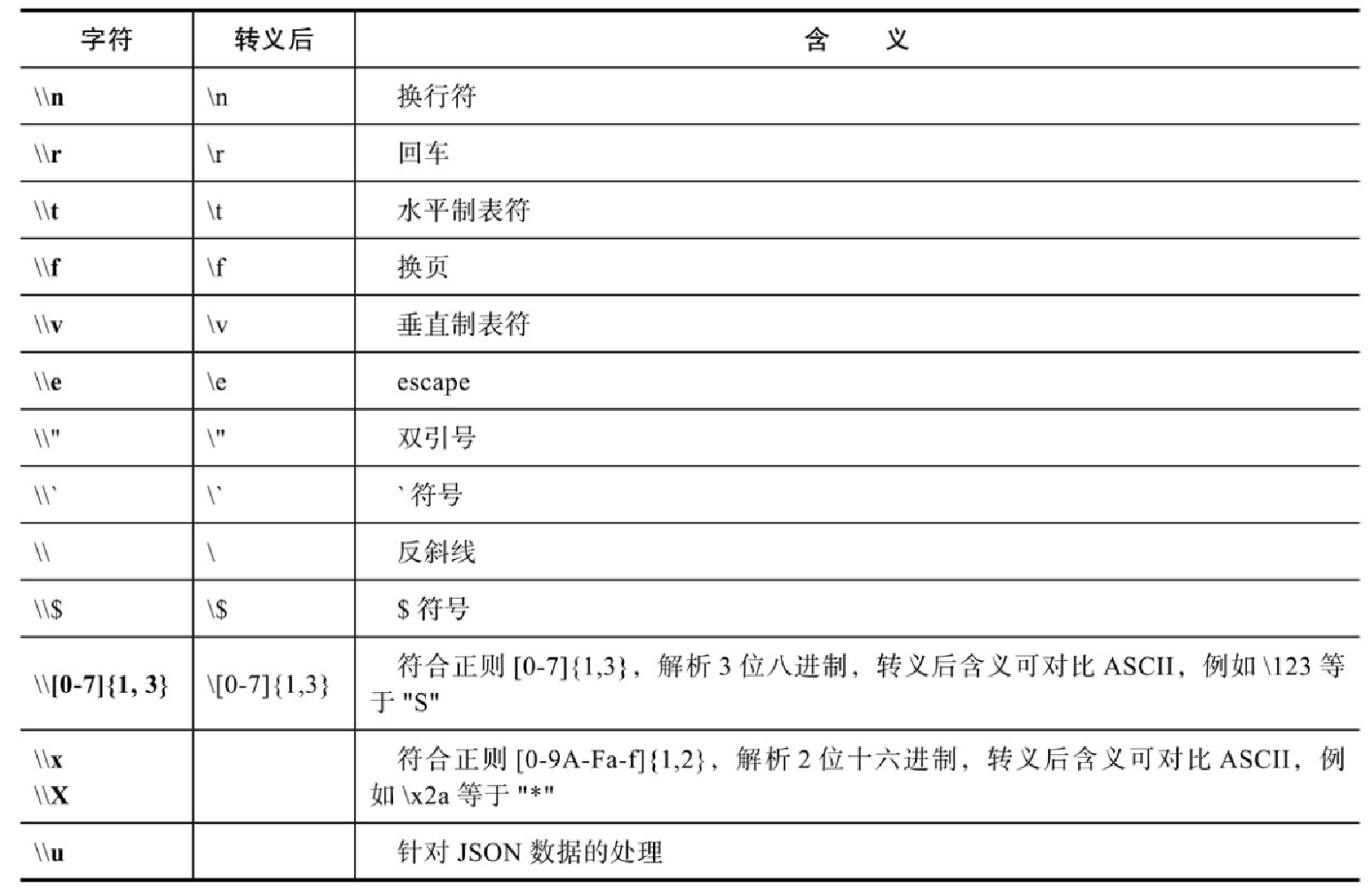
结合转义对照表,再看示例1,“$b = "ab\0cd";” 转义前存储在文件中的格式是 "ab\\0cd",经过转义后变成了 "ab\0cd",其字符串的长度自然就变成了 5,单引号未经过转义,其长度自然为 6。
|
字符串一定是由字符组成的,而 |
双引号对变量的解析
示例2:
$a = '1' ;
$b = ['2'] ;
$c = '3';
$d = "{$a}$b${c}";
echo $d; /*值为1Array3*/熟悉 PHP 的读者基本都知道双引号会解析变量,那么在源码中到底是在哪里做的处理呢?和前面双引号的转义类似,在遇到双引号里面出现变量时,词法解析器会生成一个 ZEND_AST_ENCAPS_LIST 类别的 AST 节点。为了让读者能更好地理解,这里画出了 “$d ="{$a}$b${c}"; ” 代码生成的 AST,如图4-12所示。
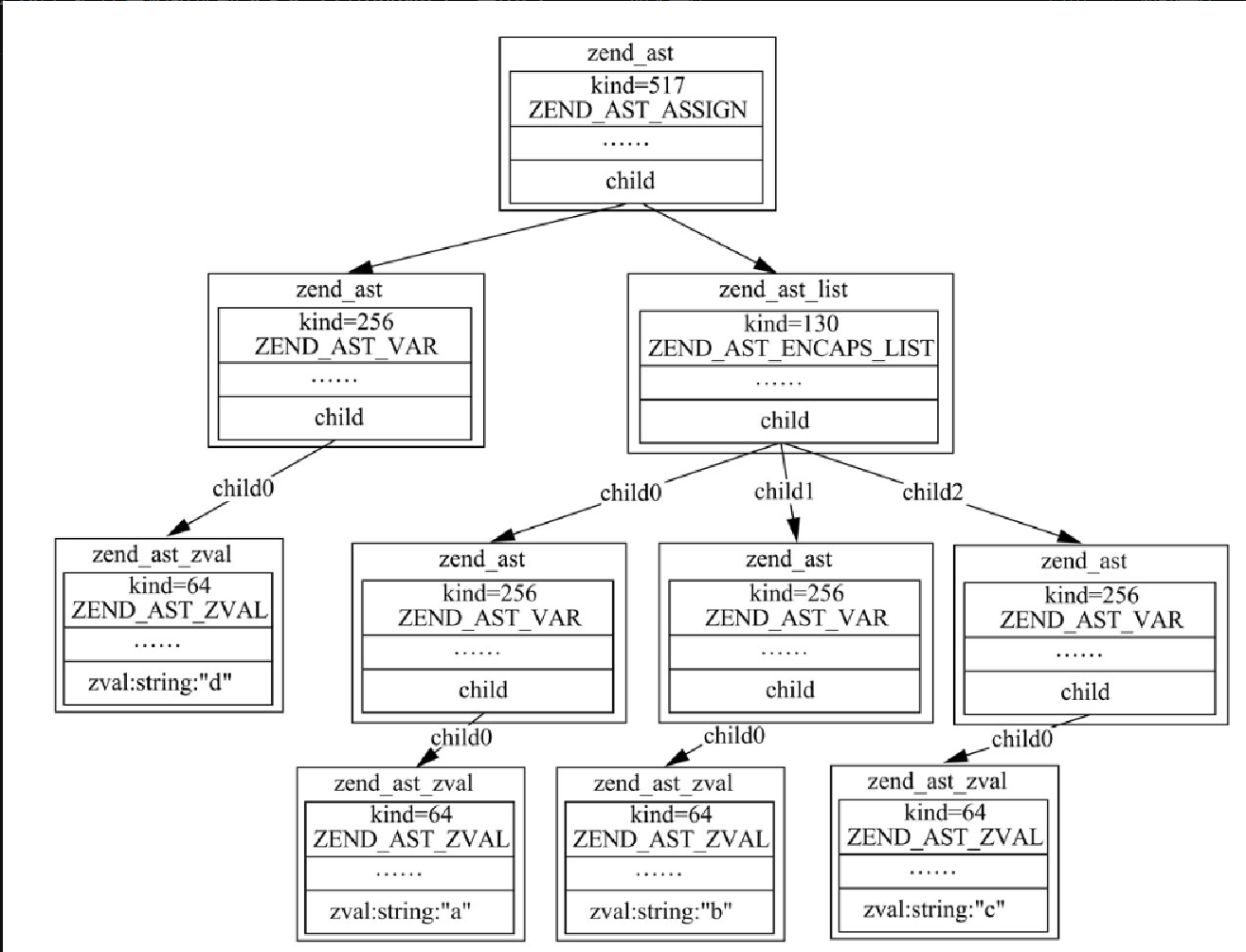
具体编译过程为,词法解析器根据正则匹配从代码中解析出 token,语法解析器根据代码中的不同语法规则生成 AST,其中就会用到 token 值。AST 节点中 kind 标识 AST 类型,第一个节点 kind=517 实际对应的就是 "=", kind=256 对应的是变量的含义,kind=64 对应的是实际字符值,kind=130 对应的是 ZEND_AST_ENCAPS_LIST 节点。解析 AST 调用的是 zend_compile_top_stmt 函数,zend_compile_top_stmt 函数会根据 AST 解析出不同的 opcode,存入 opcodes 数组,而双引号真正解析这些变量并组装成一个字符串的操作是在 zend 虚拟机逐行执行 opcodes 数组的阶段。
上述 AST 生成的 opcodes 为:
5 3 ROPE_INIT 3 ~8 !0
4 ROPE_ADD 1 ~8 ~8, !2
5 ROPE_END 2 ~7 ~8, !1
6 ASSIGN !3, ~7整体的执行及组装过程如图4-13所示。
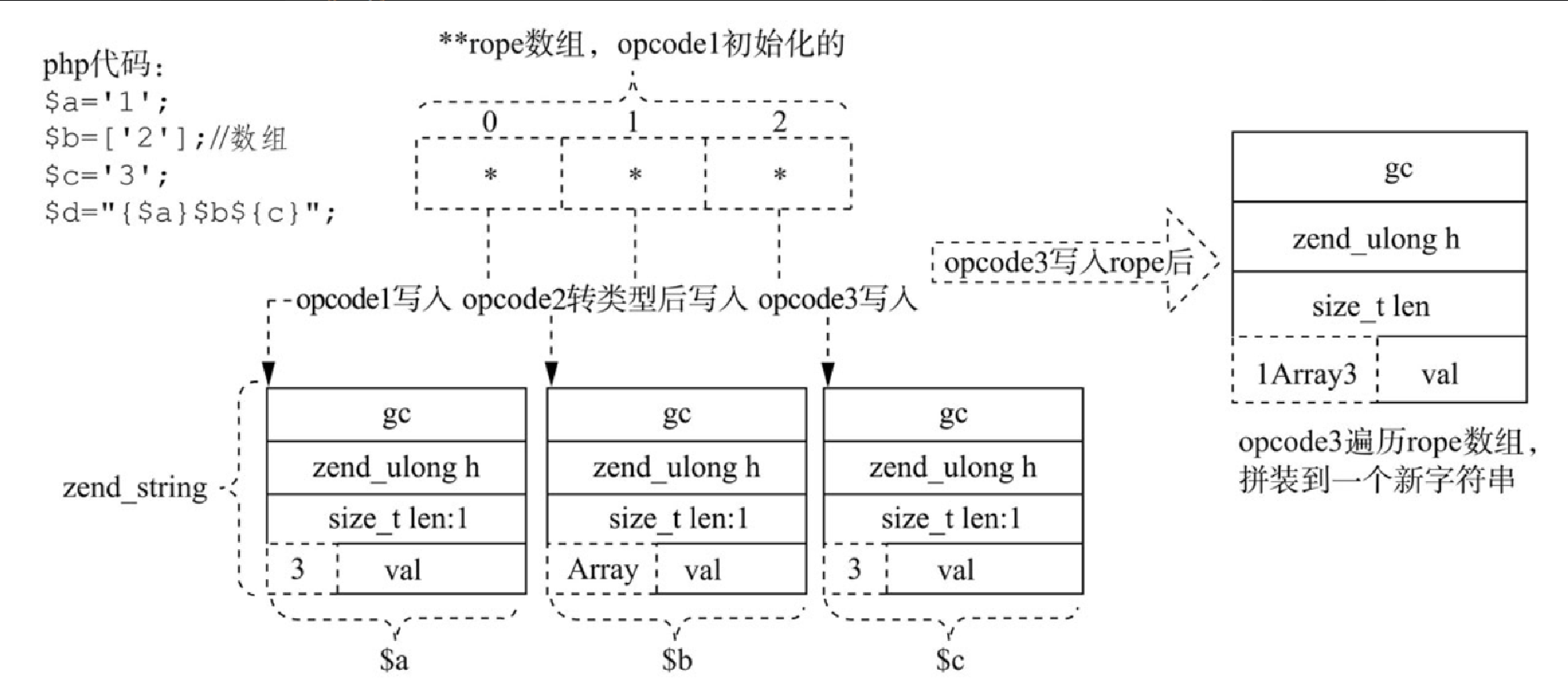
每个 opcode 对应不同的 handle 方法,会执行不同的操作。
-
第一个
opcode1对应的handle方法为ZEND_ROPE_INIT_SPEC_UNUSED_CV_HANDLER,会初始化zend_string类型的指针数组**rope,并把$a的值 1 存入rope[0]。 -
第二个
opcode2对应的handle方法为ZEND_ROPE_ADD_SPEC_TMP_CV_HANDLER,会把$b的类型转换为字符串,即 数组['2'] 转换成字符串'Array',并存入rope[1]。 -
第三个
opcode3对应的handle方法为ZEND_ROPE_END_SPEC_TMP_CV_HANDLER,从函数名称也能看出这代表最后一个需组装的字符,先把$c的值 3 存入rope[2],并遍历整个rope数组,拼接里面的每个字符串成一个新的长字符串,并遍历rope,释放rope[i]。
组装完之后返回并赋值给了变量 “d”,双引号解析变量的过程结束。
|
双引号里面的变量一定会被强制转换成字符串,转换调用的是 |
PHP常用字符串操作函数实现
熟悉 PHP 的读者应该也知道 PHP 有强大的字符串操作函数,这一节将主要围绕常用的 PHP 字符串函数的实现来讲解。
-
explode函数:使用一个字符串分割另一个字符串。函数的参数说明:
delim :分割字符串 str : 输入字符串 return_value :返回值,类型 zval.type=7,数组 limit:如果设置了 limit 参数并且是正数,则返回的数组包含最多 limit 个元素,而最后那个元素将包含 string 的剩余部分源码在
ext/standard/string.c中的PHP_explode方法具体如下:PHPAPI void PHP_explode(const zend_string *delim, zend_string *str, zval *return_value, zend_long limit) { /*str首地址*/ char *p1 = ZSTR_VAL(str); /*指针偏移到末尾*/ char *endp = ZSTR_VAL(str) + ZSTR_LEN(str); /*调用memchr函数从str查找delim字符串出现的位置*/ char *p2 = (char *) PHP_memnstr(ZSTR_VAL(str), ZSTR_VAL(delim), ZSTR_LEN(delim), endp); zval tmp; if (p2 == NULL) {/*没查找到分割字符串*/ ZVAL_STR_COPY(&tmp, str); /*直接把str写入数组返回*/ zend_hash_next_index_insert_new(Z_ARRVAL_P(return_value), &tmp); } else { do { /*初始化zval结构的tmp,并把str的p1至p2的字符串写入zval.value.str中*/ ZVAL_STRINGL(&tmp, p1, p2- p1); /*把tmp写入需返回的数组中*/ zend_hash_next_index_insert_new(Z_ARRVAL_P(return_value), &tmp); /*头指针偏移到切割剩余字符串的首地址*/ p1 = p2 + ZSTR_LEN(delim); /*继续查找切割字符串下一次出现的位置*/ p2 = (char *) PHP_memnstr(p1, ZSTR_VAL(delim), ZSTR_LEN(delim), endp); } while (p2 ! = NULL && --limit > 1); /*循环切割,直到结束或者limit限制<1*/ if (p1 <= endp) { /*还有剩余字符串,则直接把它们写入新的zval结构的tmp中,然后写入需返回的数组*/ ZVAL_STRINGL(&tmp, p1, endp - p1); zend_hash_next_index_insert_new(Z_ARRVAL_P(return_value), &tmp); } } } -
echo:输出一个或多个字符串。echo其实不是方法,是语言结构,因为比较常用,所以也暂列在这。
分析其实现,以输出常量为例,具体代码为:
ZEND_ECHO_SPEC_CONST_HANDLER(ZEND_OPCODE_HANDLER_ARGS)
{
USE_OPLINE
zval *z;
SAVE_OPLINE();
z = EX_CONSTANT(opline->op1); /*从execute_data获取变量*/
if (Z_TYPE_P(z) == IS_STRING) { /*当输出的变量为字符串时,直接输出*/
zend_string str = Z_STR_P(z); /*取出变量中的字符串*/
if (ZSTR_LEN(str) ! = 0) {
/*这里面最终调用的是write(STDOUT_FILENO, str, str_length);,将长度为len的字符
串写入STDOUT_FILENO */
zend_write(ZSTR_VAL(str), ZSTR_LEN(str));
}
} else {
/*输出的变量不是字符串时,强制转换类型*/
zend_string *str = _zval_get_string_func(z);
if (ZSTR_LEN(str) ! = 0) {
/*写入STDOUT_FILENO*/
zend_write(ZSTR_VAL(str), ZSTR_LEN(str));
}
zend_string_release(str);
}
}echo 一个变量时会判断它是否为字符串,若不是,则会强制将其转换成字符串。
不同进程的输出方式不同。
-
cli进程:输出是通过write(STDOUT_FILENO, str, str_length)函数写到标准输出中,直接输出到屏幕,没有缓冲。 -
fpm进程:输出是先组装cgi协议的数据,进行缓冲,然后统一发送给Nginx或其他Web服务器,输出写入函数为fcgi_write,字符缓冲数组存储结构为SG(server_context).out_buf。
很多字符串函数都封装在 ext/standard/string.c 文件中,感兴趣的读者可以自行查看,肯定收益颇多。