词法与语法分析器
基于 10.1 节中词法和语法分析,我们了解了词法和语法的基本知识,词法和语法可以使用正则表达式和 BNF 范式表达,而最终描述文法含义的是状态转换图,那么在做词法分析和语法分析时,我们需要维护复杂的状态转换图吗?答案是否定的,很多开源软件已经把这个工作做了,开发者只需要编写正则或者 BNF 范式来维护词法和语法分析代码即可,生成状态转换图的工作交给这些开源软件即可,本节会详细介绍一下词法分析器 Lex、Re2c,以及语法分析器 YACC 和 Bison 的使用方法。
Lex与YACC
词法分析器Lex
词法分析器 Lex,是一种生成词法分析的工具,扫描器是识别文本中词汇模式的程序,这些词汇模式是在特殊的句子结构中定义的。Lex 接收到文件或文本形式的输入时,会将文本与常规表达式进行匹配:一次读入一个输入字符,直到找到一个匹配的模式。如果能够找到一个匹配的模式,Lex 就执行相关的动作(比如返回一个标记 Token)。另外,如果没有可以匹配的常规表达式,将会停止进一步的处理,Lex 将显示一个错误消息。Lex 和 C 语言是强耦合的,一个 .lex 文件(Lex 文件的扩展名为 .lex)通过 Lex 解析并生成 C 的输出文件,这些文件被编译为词法分析器的可执行版本。
lex 或者 .l 文件在格式上分为以下 3 段。
-
全局变量声明部分。
-
词法规则部分。
-
函数定义部分。
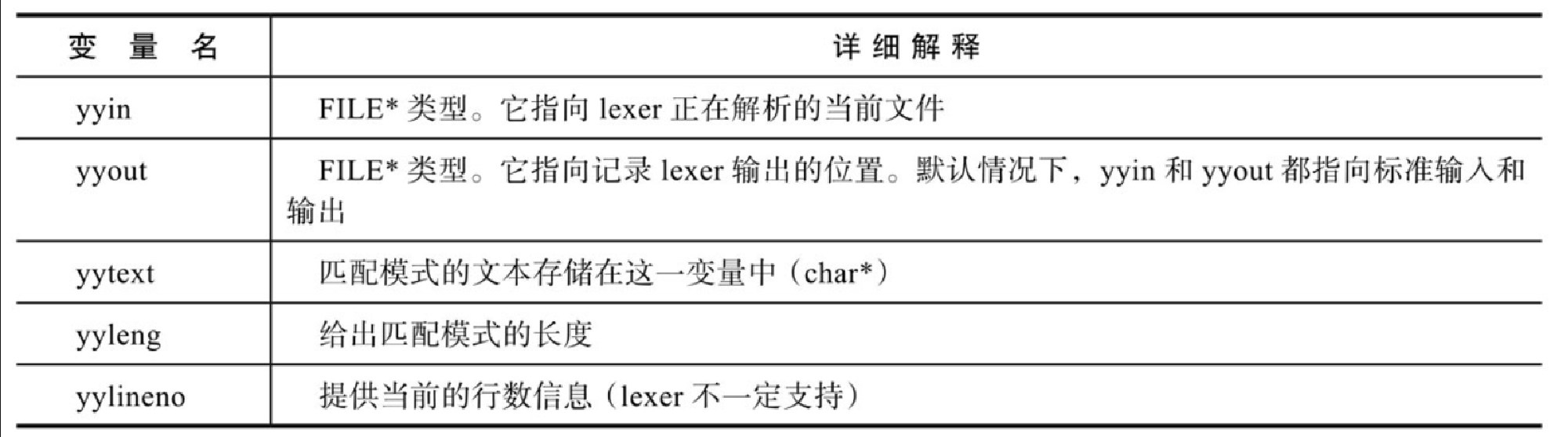
Lex 语法提供了 5 个变量,如表10-3所示。
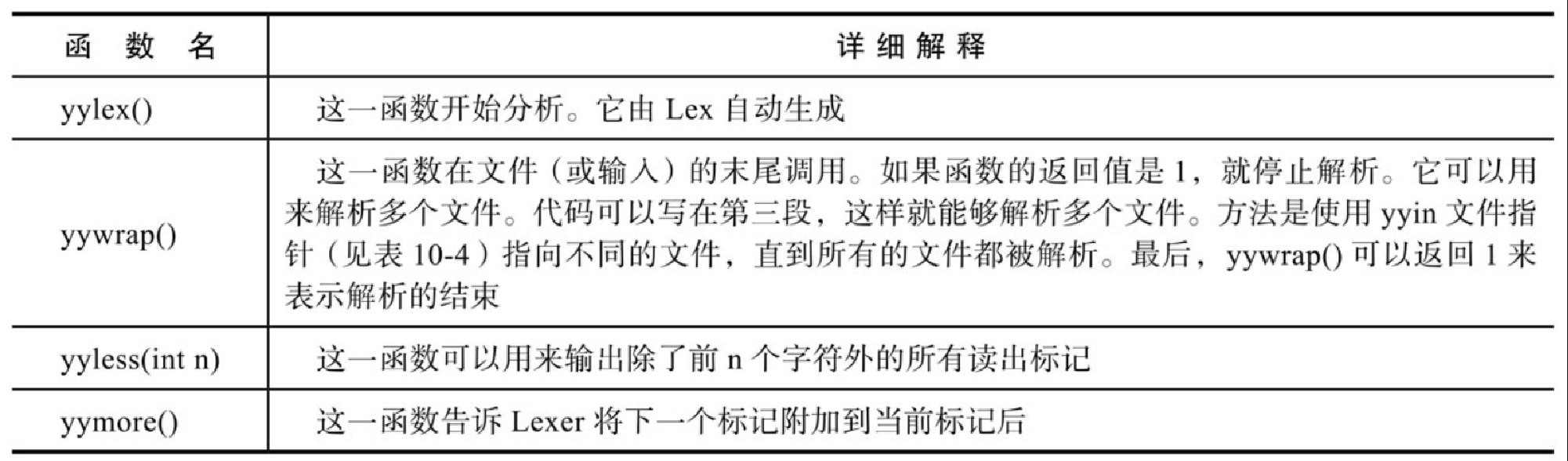
Lex 语法还提供了几个函数,如表10-4所示。
根据 Lex 文件的格式、Lex 提供的变量和函数,我们可以编写一个简单的示例文件 test.l 来体会一下 Lex 的使用,代码如下:
%{
#include <stdio.h>
extern char *yytext;
extern FILE *yyin;
int count = 0;
%}
%%//两个百分号标记指出了Lex程序中这一段的结束和第二段的开始。
\$[a-zA-Z][a-zA-Z0-9]* {count++; printf(" 变量%s", yytext); }
[0-9\/.-]+ printf("数字%s", yytext);
= printf("被赋值为");
\n printf("\n");
[ \t]+ /* 忽略空格 */;
%%
//函数定义部分
int main(int avgs, char *avgr[])
{
yyin = fopen(avgr[1], "r");
if (! yyin)
{
return 0;
}
yylex();
printf("变量总数为: %d\n", count);
fclose(yyin);
return 1;
}对于这段代码,解释如下。
-
全局变量声明部分:声明了一个
int型全局变量count,用来记录变量的个数。 -
规则部分:第 1 个规则是找
$符号开头的、第 2 个字符为字母且后面为字符或数字的变量,类似于$a,并计数加 1,同时,将满足条件的yytext输出;第 2 个规则是找数字;第 3 个规则是找 “=” 号;第 4 个规则是输出 “\n”;第 5 个规则是忽略空格。 -
函数定义部分:打开一个文件,然后调用
yylex函数进行词法解析,输出变量的计数,最后调用fclose关闭文件。
代码非常简单,我们执行以下命令,将其编译成可执行文件:
lex a.l
gcc lex.yy.c -o test -ll编写一个测试文件 file 如下:
$a = 1
$b =2执行如下命令:
./test file
变量$a被赋值为数字1
变量$b被赋值为数字2
变量总数为: 2可以看出,我们只需要写正则表达式,Lex 就可以帮我们按照需要找出对应规则的 Token。比如变量 $a、$b,数字 1 和 2,以及 “=”。Lex 给词法分析工作带来了极大的解放。PHP 7 并没有直接使用 Lex 做词法解析,而是用了升级版本 Re2c。
语法分析器YACC
PHP 7 除了词法解析之外,另外的工作就是语法分析,这里介绍一下 YACC。YACC (Yet Another Compiler-Compiler) 是 UNIX/Linux 上一个用来生成编译器的编译器(编译器代码生成器)。YACC 使用 BNF 范式定义语法,能处理上下文无关文法。
YACC 语法包括 3 部分,即定义段、规则段和用户代码段。
...定义段...
%%
...规则段...
%%
...用户代码段...各部分由以两个百分号开头的行分开,前两部分是必需的,第三部分和前面的百分号可以省略。
举个例子,我们编写一个简单的计算器,YACC 代码 calc.y 如下:
%{
#include <string.h>
#include <math.h>
%}
%union {
double dval;
}
%token <dval> NUMBER
%left '-' '+'
%left '*' '/'
%nonassoc UMINUS
%type <dval> expression
%%
statement_list: statement '\n'
| statement_list statement '\n'
;
statement: expression { printf("= %g\n", $1); }
;
expression: expression '+' expression { $$ = $1 + $3; }
| expression '-' expression { $$ = $1- $3; }
| expression '*' expression { $$ = $1 * $3; }
| expression '/' expression
{ if($3 == 0.0)
yyerror("divide by zero");
else
$$ = $1 / $3;
}
| '-' expression %prec UMINUS { $$ = -$2; }
| '(' expression ')' { $$ = $2; }
| NUMBER { $$ = $1; }
;
%%从代码中可以看出,规则部分使用 BNF 范式。
-
expression最终是NUMBER,以及使用+、-、*、/和()的组合,对加、减、乘、除、括号、负号进行表达。 -
statement是由expression组合而成的,可以输出计算结果。 -
statement_list是statement的组合。
然后配合 Lex 进行 Token 的获取,Lex 的代码 calc.l 如下:
%{
#include "y.tab.h"
#include <math.h>
%}
%%
([0-9]+|([0-9]*\.[0-9]+)([eE][-+]? [0-9]+)? ) {
yylval.dval = atof(yytext);
return NUMBER;
}
[ \t] ;
\n |
. return yytext[0];
%%接下来执行如下命令,使用 Lex 对 calc.l 进行处理:
lex cal.l会生成 lex.yy.c,里面维护了获取 NUMBER 这个 Token 的有穷自动机。
使用 YACC 对 calc.y 进行处理:
yacc -d calc.y生成的文件为 y.tab.c、y.tab.h,可以查看其中的内容,语法分析的入口如下:
int
yyparse(void)
{
//代码省略//
switch (yyn)
{
case 1:
#line 14 "calc.y"
{ printf("= %g\n", yyvsp[0].dval); }
break;
case 2:
#line 16 "calc.y"
{ yyval.dval = yyvsp[-2].dval + yyvsp[0].dval; }
break;
case 3:
#line 17 "calc.y"
{ yyval.dval = yyvsp[-2].dval - yyvsp[0].dval; }
break;
case 4:
#line 18 "calc.y"
{ yyval.dval = yyvsp[-2].dval * yyvsp[0].dval; }
break;
case 5:
#line 20 "calc.y"
{ if(yyvsp[0].dval == 0.0)
yyerror("divide by zero");
else
yyval.dval = yyvsp[-2].dval / yyvsp[0].dval;
}
break;
//代码省略//通过 YACC 生成的代码,实际上也是状态机,同时维护了状态转换表。感兴趣的读者可以参考《编译原理》一书,里面有对语法解析的详细阐述,这里不再展开。
介绍完 Lex 词法分析器和 YACC 语法分析器,相信读者对词法分析和语法分析的基本原理有了一定了解。词法分析使用正则表达式来描述 Token, Lex 会将正则表达式转换为有穷自动机,对语言进行词法分析,就是根据自动机的流转图找到对应的 Token。语法分析的基本原理是将文法通过 BNF 范式来表达,YACC 会将对应的文法翻译成状态转换表,以及文法对应的状态机,返回对应的 Action。
不过 PHP 7 并没有使用 Lex 和 YACC,而是使用了升级版本 Re2C 和 Bison,下面我们使用一些简单的例子来理解一下 Re2c 和 Bison。
Re2c与Bison
词法分析器Re2c
Re2c 是一个词法编译器,可以将符合 Re2c 规范的代码生成高效的 C/C++ 代码。跟 10.1.2.1 节阐述的词法分析一样,Re2c 会将正则表达式生成对应的有穷状态机。PHP 最开始使用的 Flex,后来改为了 Re2c,本节会通过一段示例代码来让大家对 Re2c 有一个初步的认识。
示例代码 num.l 如下:
#include <stdio.h>
enum num_t { ERR, DEC };
static num_t lex(const char *YYCURSOR)
{
const char *YYMARKER;
/*! re2c
re2c:define:YYCTYPE = char;
re2c:yyfill:enable = 0;
end = "\x00";
dec = [1-9][0-9]*;
* { return ERR; }
dec end { return DEC; }
*/
}
int main(int argc, char **argv)
{
for (int i = 1; i < argc; ++i) {
switch (lex(argv[i])) {
case ERR: printf("error\n"); break;
case DEC: printf("十进制表示\n"); break;
}
}
return 0;
}按照 Re2c 的规范,我们定义了十进制的正则表达式,在代码段 /*! re2c */ 中,运行如下命令:
re2c num.l -o num.c此时 Re2c 将 .l 文件生成了 .c 文件。打开 num.c,我们可以看到,Re2c 其实就是帮我们生成了状态机的流转流程:
/* Generated by re2c 1.0.1 on Sun Nov 26 17:53:532017 */
#line 1 "num.l"
#include <stdio.h>
enum num_t { ERR, DEC };
static num_t lex(const char *YYCURSOR)
{
const char *YYMARKER;
#line 10 "num.c"
{
char yych;
yych = *YYCURSOR;
switch (yych) {
case '1': case '2': case '3':case '4':
case '5': case '6': case '7': case '8':
case '9': goto yy4;
default: goto yy2;
}
yy2:
++YYCURSOR;
yy3:
#line 14 "num.l"
{ return ERR; }
#line 32 "num.c"
yy4:
yych = *(YYMARKER = ++YYCURSOR);
switch (yych) {
case 0x00: goto yy5;
case '0': case '1': case '2': case '3':
case '4': case '5': case '6': case '7':
case '8': case '9': goto yy7;
default: goto yy3;
}
yy5:
++YYCURSOR;
#line 15 "num.l"
{ return DEC; }
#line 53 "num.c"
yy7:
yych = *++YYCURSOR;
switch (yych) {
case 0x00: goto yy5;
case '0': case '1': case '2': case '3':
case '4': case '5': case '6': case '7':
case '8': case '9': goto yy7;
default: goto yy9;
yy9:
YYCURSOR = YYMARKER;
goto yy3;
}
#line 16 "num.l"
}
int main(int argc, char **argv)
{
for (int i = 1; i < argc; ++i) {
switch (lex(argv[i])) {
case ERR: printf("error\n"); break;
case DEC: printf("十进制表示\n"); break;
}
}
return 0;
}从上面代码中可以看出,这个状态机一共有 8 种状态,分别是开始状态、yy3 至 yy9 状态,其中 yy3 状态是错误输出状态,返回 ERR, yy5 状态是对应的正则匹配状态,返回 DEC,状态图如图10-6所示。
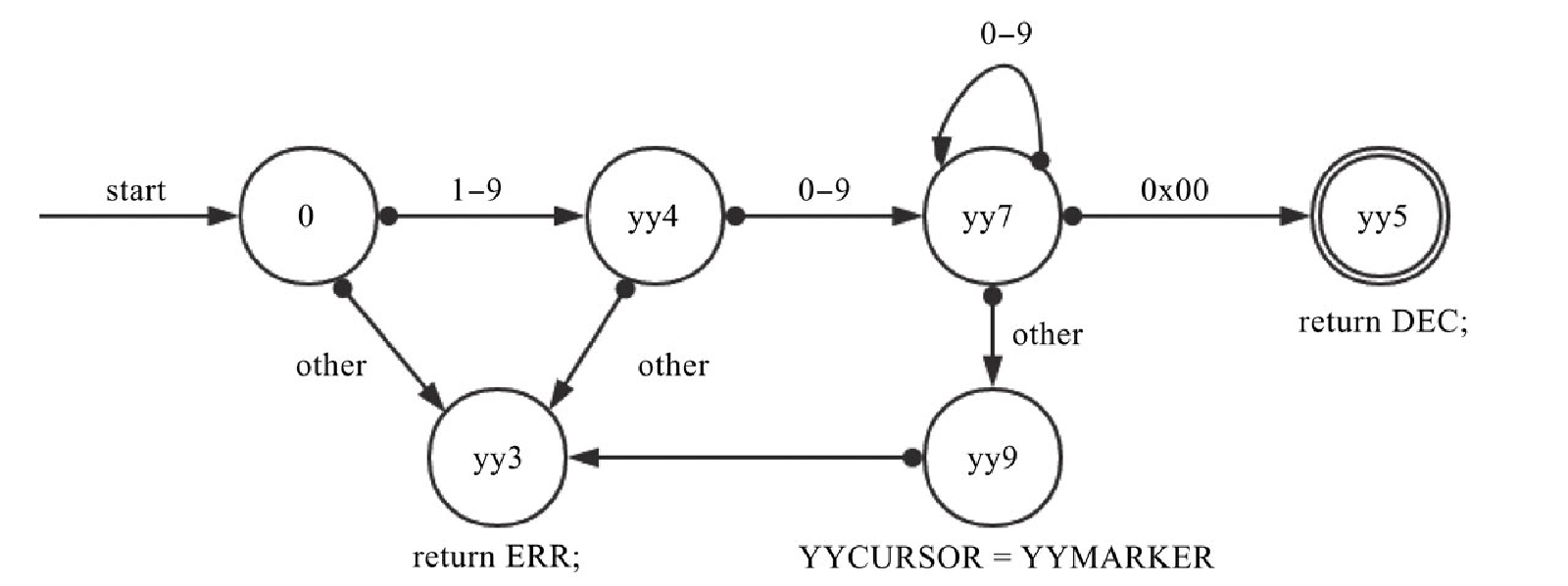
从图10-6可以看出,YYCURSOR 是指向输入的指针,根据状态的流转,指针加 1。Re2c 的主要功能是将复杂的正则表达式转换为清晰的状态机,而这个状态机的执行速度是非常快的。PHP 7 的词法分析状态机,同样由符合 Re2c 的代码,经过 Re2c 编译后生成,这个状态机包含了 800 多个状态,可以参见 Zend/zend_language_scanner.c 文件。到此,我们可以理解 Re2c 都做了什么工作,其核心是使用状态机来描述正则表达式,提高分析速度。
介绍完 Re2c,接下来我们介绍 Bison,我们依然使用 Re2c 来生成词法分析器。Re2c 可以识别正则表达式,而 Bison 可以识别语法;Re2c 可以把源程序分解为若干个片段(Token),而 Bison 进一步分析这些 Token 并基于逻辑进行组合。
语法编译器Bison
利用10.1.3节介绍的 BNF 写出的文法规则,可以对输入的文本进行文法分析。对于一条 BNF 文法规则,其左边是一个非终结符(symbol 或者 non-terminal),其右边则定义该非终结符是如何构成的,也称为产生式(production)。产生式可能包含非终结符,也可能包含终结符(terminal),还可能二者都有。利用 BNF 文法来分析目标文本,比较流行的算法有 LL 分析(自顶向下的分析,top-down parsing)、LR 分析(自底向上的分析,bottom-up parsing;或者叫移进-归约分析,shift-reduce parsing)。其中 LR 算法有很多不同的变种,按照复杂度和能力递增的顺序依次是 LR(0)、SLR、LALR 和 LR(1)。感兴趣的读者可以参考编译原理相关书籍,这里不再展开。
Bison 是基于 LALR 分析法实现的,适合上下文无关文法。当 Bison 读入一个终结符 TOKEN 时,会将该终结符及其语意值一起压栈,其中这个栈叫作分析器栈(parser stack)。把一个 TOKEN 压入栈叫作移进。举个例子,对于计算 1+2*3,假设现已经读入了 1+2*,那么下一个准备读入的是 3,这个栈当前就有 4 个元素,即 1、+、2 和 *。当已经移进的后 n 个终结符和组(groupings)与一个文法规则相匹配时,它们会根据该规则结合起来,这叫作归约(reduction)。栈中的那些终结符和组会被单个的组(grouping)替换。同样,以 1+2*3;为例,最后一个输入的字符为分号,表示结束,那么会按照下面的规则进行规约:
expression '*' expression { $$ = $1 * $3; }结果得到 1+6,分析器栈中就只保留 1、+、6 这 3 个元素了。这样比较容易理解语法分析。
Bison 与 YACC 的规则类似,下面我们编写一个 Bison 文件,来体会一下 Bison 的使用方法:
%{
#define YYSTYPE double
#include <math.h>
#include <ctype.h>
#include <stdio.h>
%}
/* 定义部分 */
%token NUM
%left '-' '+'
%left '*' '/'
%left NEG
%right '^'
/* 语法部分 */
%%
input: /* empty string */
| input line
;
line: '\n'
| exp '\n' { printf ("\t%.10g\n", $1); }
;
exp: NUM { $$ = $1; }
| exp '+' exp { $$ = $1 + $3; }
| exp '-' exp { $$ = $1- $3; }
| exp '*' exp { $$ = $1 * $3; }
| exp '/' exp { $$ = $1 / $3; }
| '-' exp %prec NEG { $$ = -$2; }
| exp '^' exp { $$ = pow ($1, $3); }
| '(' exp ')' { $$ = $2; }
;
/*代码部分*/
%%
yylex ()
{
int c;
/* 跳过空格 */
while ((c = getchar ()) == ' ' || c == '\t')
;
if (c == '.' || isdigit (c))
{
ungetc (c, stdin);
scanf ("%lf", &yylval);
return NUM;
}
if (c == EOF)
return 0;
return c;
}
yyerror (s) /* 错误是被yyparse调用*/
char *s;
{
printf ("%s\n", s);
}
main ()
{
yyparse ();
}通过 Bison 对 calc.y 进行编译:
bison -d calc.y会生成 calc.tab.h 和 calc.tab.c,查看 calc.tab.c,入口函数为 yyparse,该函数生成了一个分析器栈:
YYSTYPE yyvsa[YYINITDEPTH];其中,YYINITDEPTH=200,而 YYSTYPE 为 calc.y 里面的定义:
#define YYSTYPE double执行下面的命令可以生成对应的可执行程序 calc:
gcc -o calc calc.tab.c calc.tab.h -lm感兴趣的读者可以看一下 calc.tab.c 的内容,其使用 LALR 分析法维护了对 BNF 的解析。了解了词法和语法分析器的原理和使用后,我们来研究一下 PHP 7 中词法和语法分析的过程,首先先从 Token 和词法、语法相关的数据结构入手。