PHP 7数组的实现
如何基于 HashTable 实现高效优雅的数组呢?有些读者可能会想,既然是 HashTable,如果通过链地址法解决哈希冲突,那么链表是必然需要的。同时为了保证顺序性,的确需要再维护一个全局链表,看起来 PHP 5 的实现已经是无懈可击了。难道 PHP 7 数组采用了其他哈希冲突解决方案(比如开放地址法)?
实际上,PHP 7 的思路依然是通过链地址法解决哈希冲突。不过此 “链” 非彼 “链”。PHP 5 的链表是物理上的链表,链表中 bucket 之间的上下游关系通过真实存在的指针来维护。而 PHP 7 的链表是一种逻辑上的链表,所有 bucket 都分配在连续的数组内存中,不再通过指针维护上下游关系,每一个 bucket 只维护下一个 bucket 在数组中的索引(因为是连续内存,通过索引可以快速定位到 bucket),即可完成链表上 bucket 的遍历。
下面来逐步揭开 PHP 7 数组的神奇面纱。
基本结构
在 PHP 7 中,数组的核心结构是 struct _zend_array 和 bucket,并且为 struct _zend_array 起了两个别名:HashTable 和 zend_array。之所以存在两个别名,根据鸟哥惠新宸的描述,是为了保持兼容。在 PHP 5 中,使用的是 HashTable,但在 PHP 7 的设计中,大部分 zend 数据类型都是以 “zend_” 开头,所以 PHP 7 中推荐使用的是 zend_array。笔者这里为了阐述连贯性,仍然使用 HashTable 这个别名。
为了理解 PHP 7 数组的实现,首先看看核心结构的源码:
typedef struct _zend_array zend_array;
typedef struct _zend_array HashTable;
typedef struct _Bucket {
zval val; /* 存储的值 */
zend_ulong h; /* 哈希值或整数索引 */
zend_string *key; /* 字符串键 */
} Bucket;
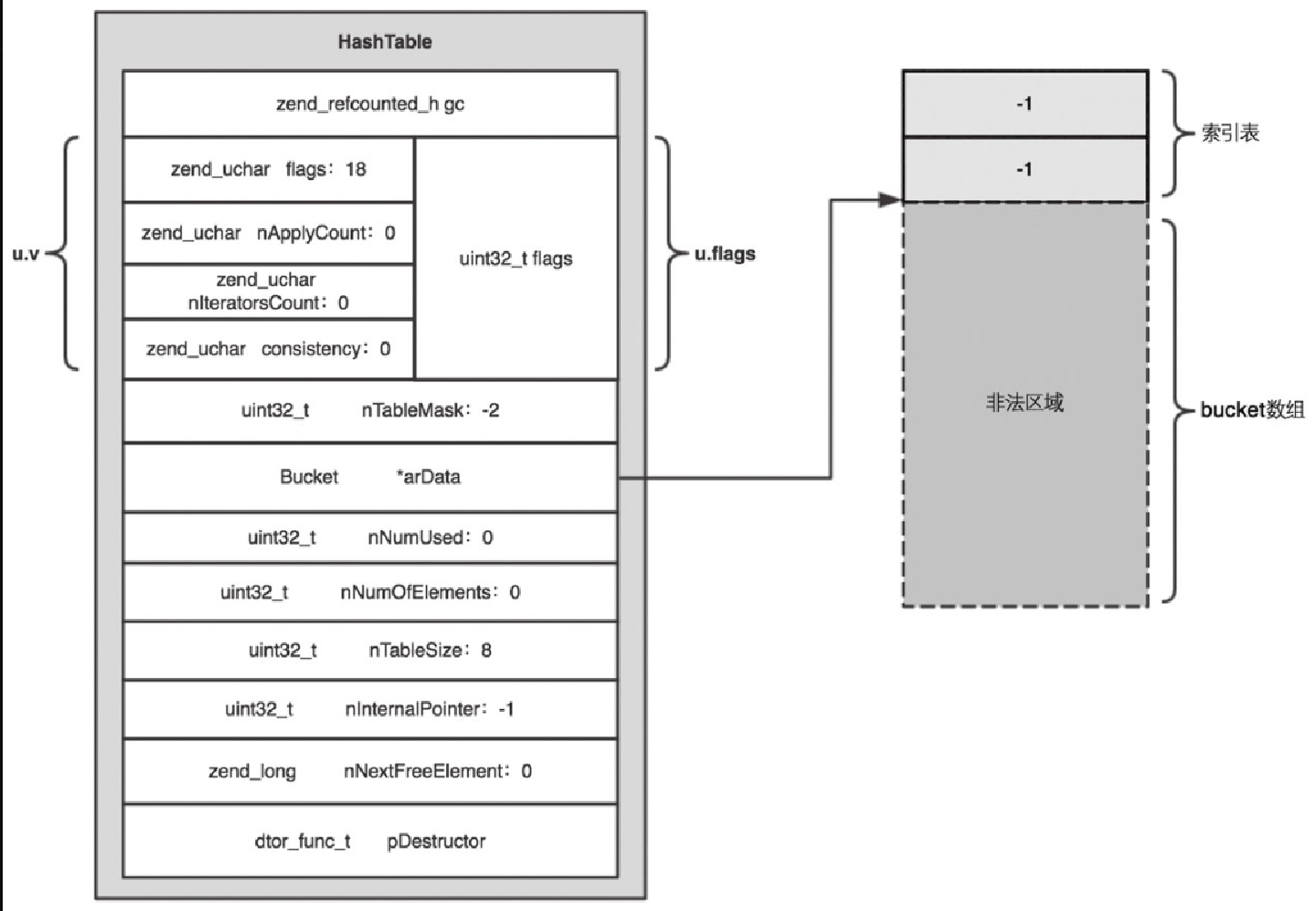
struct _zend_array {
zend_refcounted_h gc; /* 用于垃圾回收(GC)和引用计数 */
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount, /* 应用计数器,通常用于防止递归调用 */
zend_uchar nIteratorsCount, /* 迭代器计数器,跟踪当前数组上有多少迭代器 */
zend_uchar consistency) /* 一致性标志,用于检查数组的一致性 */
} v;
uint32_t flags; /* 直接访问联合体中的 32 位标志 */
} u; /* 这是一个匿名联合体,用于存储数组的标志 */
uint32_t nTableMask; /* 哈希表的掩码,用于计算哈希表索引 */
Bucket *arData; /* 指向哈希表存储数据的数组。Bucket 是存储键值对的结构体 */
uint32_t nNumUsed; /* 当前使用的哈希表槽位的数量 */
uint32_t nNumOfElements; /* 数组中实际存储的元素数量 */
uint32_t nTableSize; /* 哈希表的大小,即哈希表槽位的数量 */
uint32_t nInternalPointer; /* 内部指针,通常用于迭代数组 */
zend_long nNextFreeElement; /* 下一个可用的整数键,通常用于自动增长的整数索引 */
dtor_func_t pDestructor; /* 指向元素析构函数的指针,用于释放数组元素的内存 */
};bucket结构分析
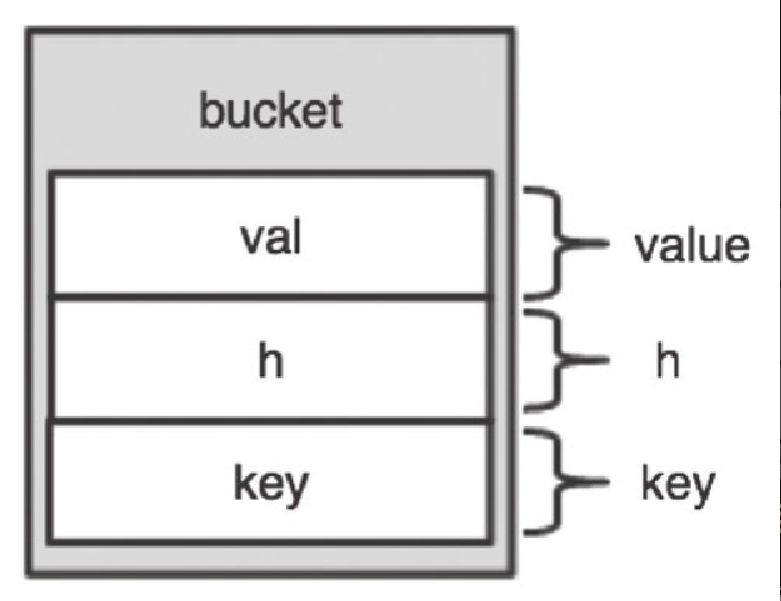
先分析一下 bucket,由于不再依赖于物理指针,整个 bucket 变得清爽了很多,只有 val、h、key 3 个字段,如图5-5所示。
-
val:对应HashTable设计中的value,始终是zval类型。PHP 7 将zval嵌入到bucket中,每一个zval只有 16 个字节。相比于 PHP 5 的pData和pDataPtr,所占的字节数并没有增加。而且不用再额外申请保存zval的内存。有同学可能会有疑问,之前的pData和pDataPtr是void *类型的,也就是说,可以指向任何类型的数据,而zval可以这样吗?答案是肯定的,PHP 7 对zval进行了重大改造,当zval是IS_PTR类型时,可以通过zval.value.ptr指向任何类型的数据。对于zval的具体阐述见第 3 章。 -
h:对应HashTable设计中的h,表示数字key或者字符串key的h值。 -
key:对应HashTable设计中的key,表示字符串key。区别于 PHP 5,这里不再是char *类型的指针,而是一个指向zend_string的指针。zend_string是一种带有字符串长度、h值、gc信息的字符数组的包装,提升了性能和空间效率。对于zend_string的阐述见第 4 章。
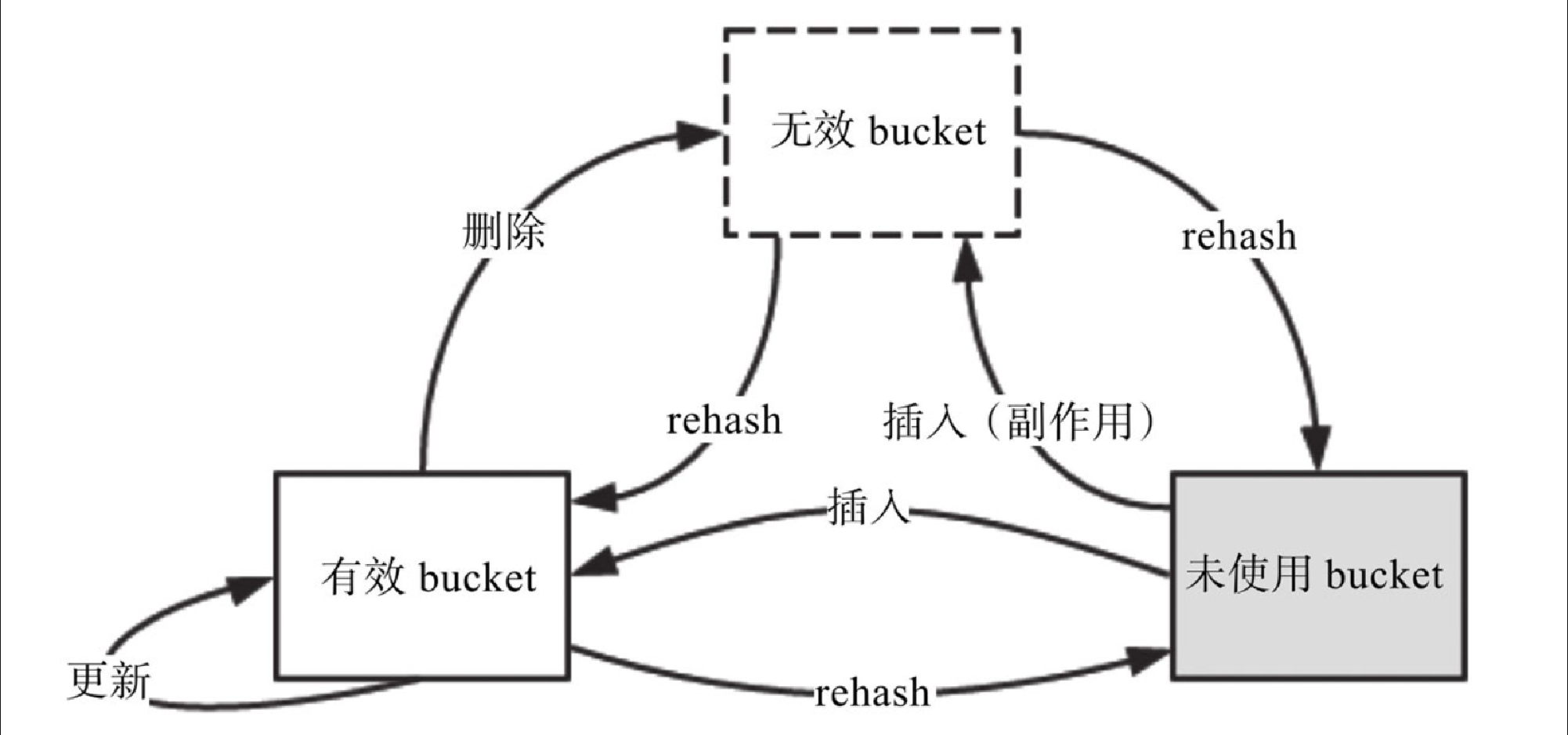
bucket 从使用角度可以分为 3 种:未使用 bucket、有效 bucket、无效 bucket,如图5-6所示。

-
未使用
bucket:最初所有的bucket都是未使用的状态。 -
有效
bucket:存储着有效的数据(key、val、h),当进行插入时,会选择一个未使用bucket,这样该bucket就变成了有效bucket。更新操作只能发生在有效bucket上,更新之后,仍然是有效bucket。 -
无效
bucket:当bucket上存储的数据被删除时,有效bucket就会变为无效bucket。同时,对于某些场景的插入(packed array的插入,5.3.3 节会提到),除了会生成一个有效bucket外,还会有副作用,生成多个无效bucket。
在内存分布上,有效 bucket 和无效 bucket 会交替分布,但都在未使用 bucket 的前面。插入的时候永远在未使用 bucket 上进行。当由于删除等操作,导致无效 bucket 非常多,而有效 bucket 很少时,会对整个 bucket 数组进行 rehash 操作。这样,稀疏的有效 bucket 就会变得连续而紧密,部分无效 bucket 会被重新利用而变为有效 bucket。还有一部分有效 bucket 和无效 bucket 会被释放出来,重新变为未使用 bucket。
这 3 种 bucket 的状态转换如图5-7所示。
HashTable结构分析
接下来看看 HashTable,如图5-8所示。
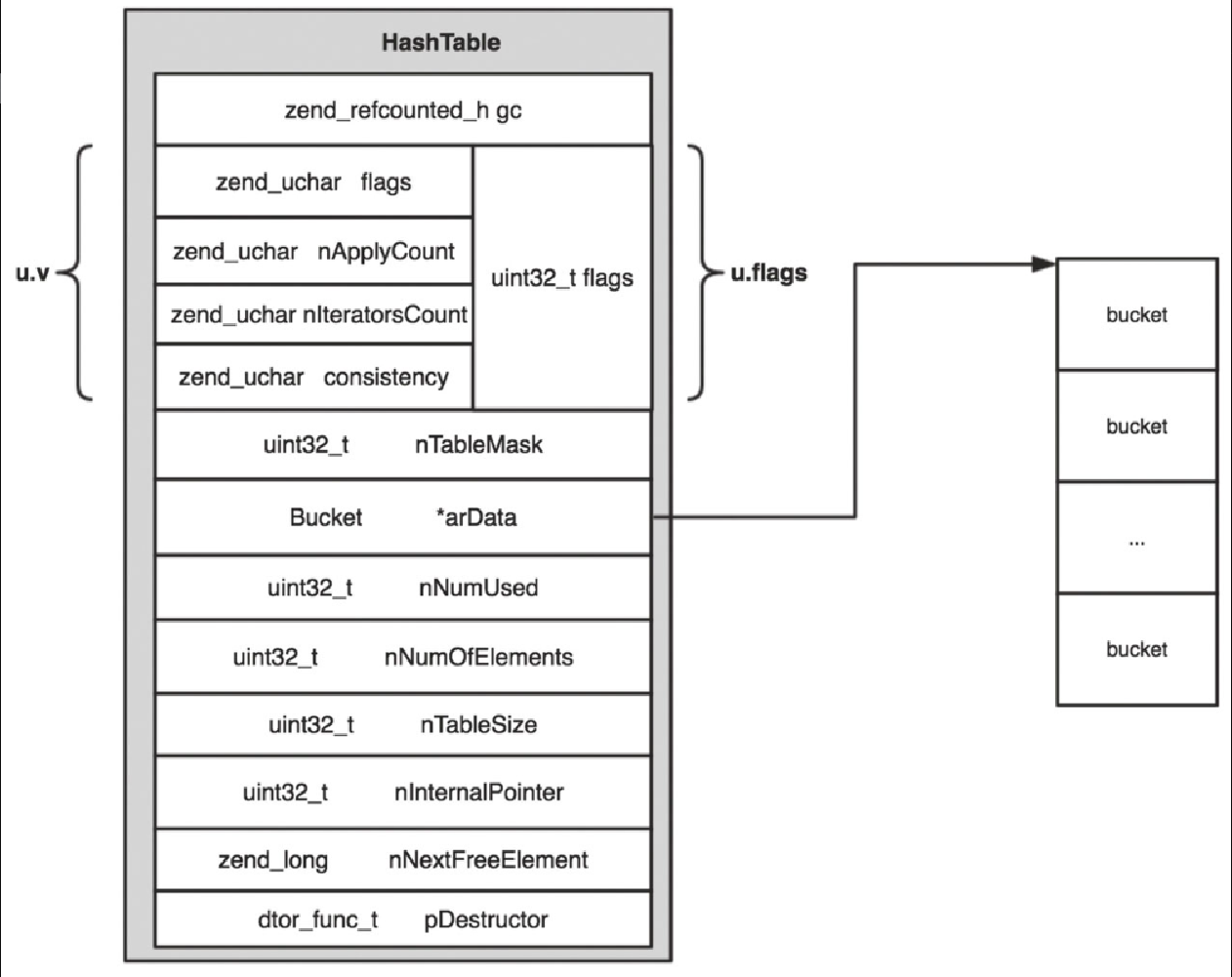
-
gc:引用计数相关,在 PHP 7 中,引用计数不再是zval的字段,而是被设计在zval的value字段所指向的结构体中。 -
arData:实际的存储容器。通过指针指向一段连续的内存,存储着bucket数组。nTableSize、nNumUsed、nNumOfElements这三个字段都和数量相关,如图5-9所示。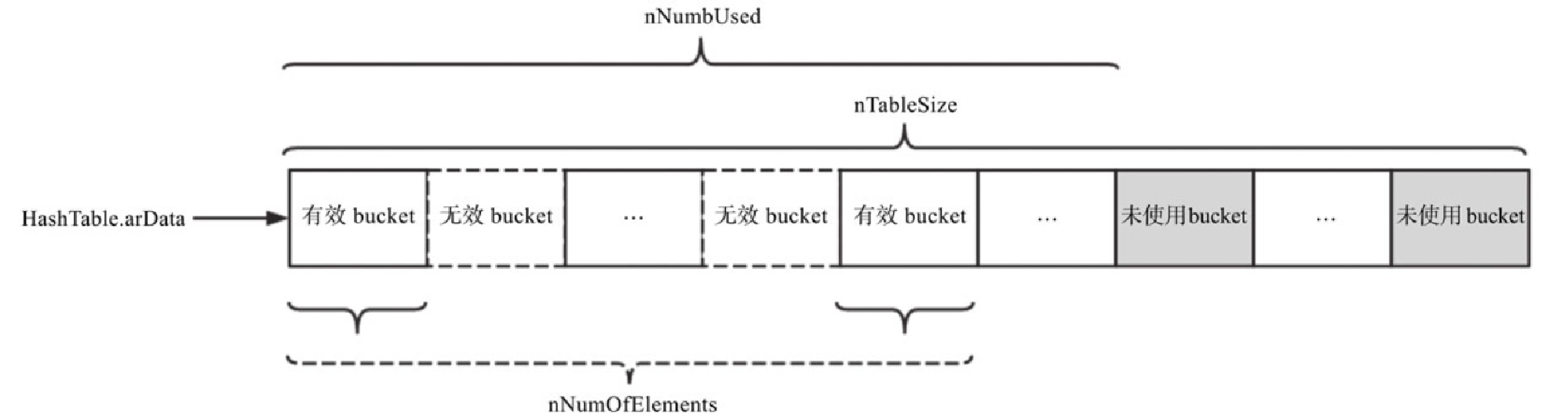 Figure 5. 图5-9 PHP 7 HashTable中的各种计数示例
Figure 5. 图5-9 PHP 7 HashTable中的各种计数示例 -
nTableSize:HashTable的大小。表示arData指向的bucket数组的大小,即所有bucket的数量。该字段取值始终是2n,最小值是 8,最大值在 32 位系统中是0x40000000(230),在 64 位系统中是0x80000000(231)。 -
nNumUsed:指所有已使用bucket的数量,包括有效bucket和无效bucket的数量。在bucket数组中,下标从0~(nNumUsed-1)的bucket都属于已使用bucket,而下标为nNumUsed~(nTableSize-1)的bucket都属于未使用bucket。 -
nNumOfElements:有效bucket的数量。该值总是小于或等于nNumUsed。 -
nTableMask:掩码。一般为-nTableSize。区别于 PHP 5, PHP 7 的掩码始终是负数,为什么是负数呢?这里先卖个关子,下文会给出明确的答案。 -
nInternalPointer:HashTable的全局默认游标。在 PHP 7 中reset/key/current/next/prev等函数和该字段有紧密的关系。该值是一个有符号整型,区别于 PHP 5,由于所有bucket分配在连续的内存,不再需要根据指针维护正在遍历的bucket,而是只维护正在遍历的bucket在数组中的下标即可。 -
nNextFreeElement:HashTable的自然key。自然key是指HashTable的应用语义是纯数组时,插入元素无须指定key,key会以nNextFreeElement的值为准。该字段初始值是 0。比如$a[] = 1,实际上是插入到key等于 0 的bucket上,然后nNextFreeElement会递增变为 1,代表下一个自然插入的元素的key是 1。 -
pDestructor:析构函数。当bucket元素被更新或者被删除时,会对bucket的value调用该函数,如果value是引用计数的类型,那么会对value引用计数减 1,进而引发可能的gc。 -
u:是一个联合体。占用 4 个字节。可以存储一个uint32_t类型的flags,也可以存储由 4 个unsigned char组成的结构体v,这里的宏ZEND_ENDIAN_LOHI_4是为了兼容不同操作系统的大小端,可以忽略。v中的每一个char都有特殊的意义。 -
u.v.flags:用各个bit来表达HashTable的各种标记。共有下面 6 种flag,分别对应u.v.flags的第 1 位至第 6 位。#define HASH_FLAG_PERSISTENT (1<<0) //是否使用持久化内存(不使用内存池) #define HASH_FLAG_APPLY_PROTECTION (1<<1) //是否开启递归遍历保护 #define HASH_FLAG_PACKED (1<<2) //是否是packed array #define HASH_FLAG_INITIALIZED (1<<3) //是否已经初始化 #define HASH_FLAG_STATIC_KEYS (1<<4) /*标记HashTable的Key是否为long key或者内部字符串key*/ #define HASH_FLAG_HAS_EMPTY_IND (1<<5) //是否存在空的间接val -
u.v.nApplyCount:递归遍历计数。为了解决循环引用导致的死循环问题,当对某数组进行某种递归操作时(比如递归count),在递归调用入栈之前将nApplyCount加 1,递归调用出栈之后将nApplyCount减 1。当循环引用出现时,递归调用会不断入栈,当nApplyCount增加到一定阈值时,不再继续递归下去,返回一个合法的值,并打印“recursion detected”之类的warning或者error日志。这个阈值一般不大于 3。 -
u.v.nIteratorsCount:迭代器计数。PHP 中每一个foreach语句都会在全局变量EG中创建一个迭代器,迭代器包含正在遍历的HashTable和游标信息。该字段记录了当前runtime正在迭代当前HashTable的迭代器的数量。u.flags和u.v.flags有什么区别呢?u.flags是 32 位的无符号整型,取值范围是 0~232-1,而u.v.flags是 8 位的无符号字符,取值范围是 0~255。C 语言中联合体很巧妙,既可以通过u.flags一次性操作 32 位的整型,也可以根据u.v.[flags|nAppl yCount|nItertorsCount|consistency]只操作其中某一个具体的 8 位的char,即一段内存,多种意义。 -
u.v.consistency:成员用于调试目的,只在 PHP 编译成调试版本时有效,表示HashTable的状态,状态有 4 种。#define HT_OK 0x00 //正常状态,各种数据完全一致 #define HT_IS_DESTROYING 0x40 //正在删除所有的内容,包括 arBuckets 本身 #define HT_DESTROYED 0x80 //已删除,包括 arBuckets 本身 #define HT_CLEANING 0xc0 //正在清除所有的 arBuckets 指向的内容,但不包括 arBuckets 本身
看到这里,有没有发现一个问题,HashTable 的 slot 和链表去哪了?arData 指向的是 bucket 数组,并没有像 PHP 5 的 arBuckets 一样,指向的是 bucket * 指针数组。那么如何基于一个 bucket 数组实现多个 slot 以及链表呢?
为什么 HashTable 的掩码是负数
实际上 PHP 7 在分配 bucket 数组内存的时候,在 bucket 数组的前面额外多申请了一些内存,这段内存是一个索引数组(也叫索引表),数组里面的每个元素代表一个 slot,存放着每个 slot 链表的第一个 bucket 在 bucket 数组中的下标。如果当前 slot 没有任何 bucket 元素,那么索引值为 -1。而为了实现逻辑链表,由于 bucket 元素的 val 是 zval,PHP 7 通过 bucket.val.u2.next 表达链表中下一个元素在数组中的下标,如图5-10(n 等于 nTableSize)所示。
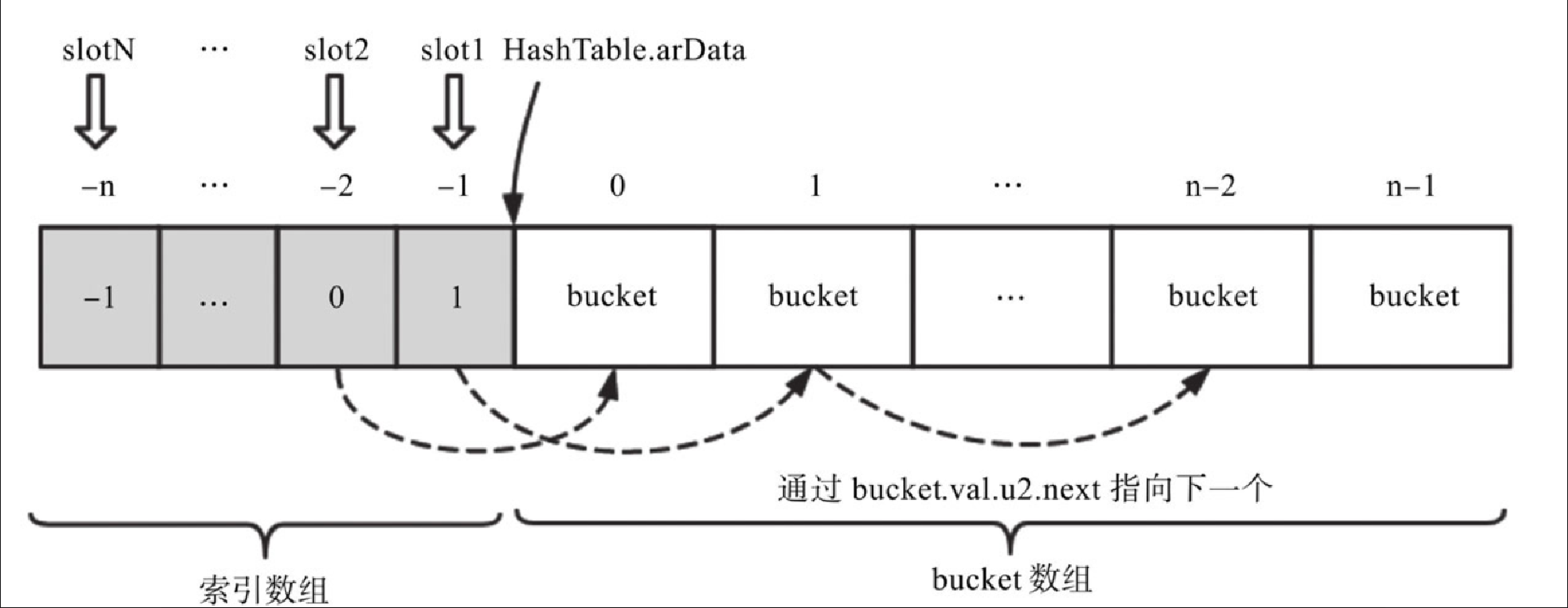
这里一个非常巧妙的设计是索引数组仍然通过 HashTable.arData 来引用。由于索引数组和 bucket 数组是连续的内存,因此 arData[0…n-1] 表示 bucket 数组元素,((uint32_t*) (arData))[-1...-n] 表示索引数组元素。因此在计算 bucket 属于哪个 slot 时,要做的就是确定它在索引数组中的下标,而这个下标是从 -n~-1 的负数,分别代表 slot1 到 slotN。
这回是否可以理解为什么 HashTable 的掩码 nTableMask 是负数了呢?为了得到介于 [-n, -1] 之间的负数的下标,PHP 7 的 HashTable 设计中的 hash2 函数(根据 h 值取得 slot 值)是这样的(其中 nIndex 就是 slot 值):
nIndex = h | ht->nTableMask;以 nTableSize=8 为例,nTableMask=-8,二进制表示是:
11111111111111111111111111111000
任何整数和它进行按位或之后的结果只有以下 8 种,这恰好满足 [-n, -1] 的取值范围:
11111111111111111111111111111000 //-8
11111111111111111111111111111001 //-7
11111111111111111111111111111010 //-6
11111111111111111111111111111011 //-5
11111111111111111111111111111100 //-4
11111111111111111111111111111101 //-3
11111111111111111111111111111110 //-2
11111111111111111111111111111111 //-1上面概况地讲解了 PHP 7 中 HashTable 和 bucket 的结构及各个字段的意义,有很多细节并没有详细展开。这里读者不理解也没有关系,接下来会继续深入展开讨论。
初始化
前文介绍了 PHP 7 数组的两个核心结构 HashTable 和 bucket。那么 HashTable 和 bucket 是什么时候分配内存并初始化的呢?初始化之后的内存布局是什么样的?本节就这些问题展开讲述。考虑下面这段代码:
<?PHP
$a = array();代码很简单,只有一行,将一个空数组赋值给 $a 这个变量。现看看执行的 opcodes:
./phpdbg -p* array.php
function name: (null)
L1-4 {main}() /root/php7array.php -0x7f1b55c79000 + 2 ops
L2 #0 ASSIGN $a array(0)
L4 #1 RETURN 1
[Script ended normally]通过 phpdbg 看到有两个 opcode:ASSIGN 和 RETURN。RETURN 是程序结束时执行的,而上面的赋值语句对应的 opcode 只有一个:ASSIGN。从 operands 列可以看到它有两个操作数:第一个操作数 !0 表示变量 $a,第二个操作数 <array> 表示一个数组常量。
有没有和笔者一样很奇怪为什么没有数组创建、数组初始化之类的 opcode?其实对于 array() 这种写法,PHP 7 会在编译阶段(将 AST 抽象语法树编译成 opcode 时,具体内容会在第 12 章具体阐述)就创建一个数组常量。这个数组常量和数字常量、字符串常量一样,是在编译阶段就确定并分配内存的。因此对于上面的代码,数组的初始化发生在 编译阶段。初始化的过程如下。
第 1 步:申请一块内存。
(ht) = (HashTable *) emalloc(sizeof(HashTable))
//注:HashTable 就是 _zend_array 结构体,typedef struct _zend_array HashTable;第 2 步:调用 _zend_hash_init 方法。
GC_REFCOUNT(ht) = 1; //设置引用计数
GC_TYPE_INFO(ht) = IS_ARRAY; //7 类别设置成数组
//persistent 是否经过内存池分配内存
ht->u.flags = (persistent ? HASH_FLAG_PERSISTENT : 0) | HASH_FLAG_APPLY_PROTECTION |
HASH_FLAG_STATIC_KEYS;
ht->nTableSize = zend_hash_check_size(nSize); //能包含nSize的最小2n的数字最小值 8
ht->nTableMask = HT_MIN_MASK; //-2, 默认是packed array
HT_SET_DATA_ADDR(ht, &uninitialized_bucket); //prt 偏移到 arrData 地址
ht->nNumUsed = 0;
ht->nNumOfElements = 0;
ht->nInternalPointer = HT_INVALID_IDX; //-1
ht->nNextFreeElement = 0;
ht->pDestructor = pDestructor;初始化结束后,这个数组常量如图5-11所示。
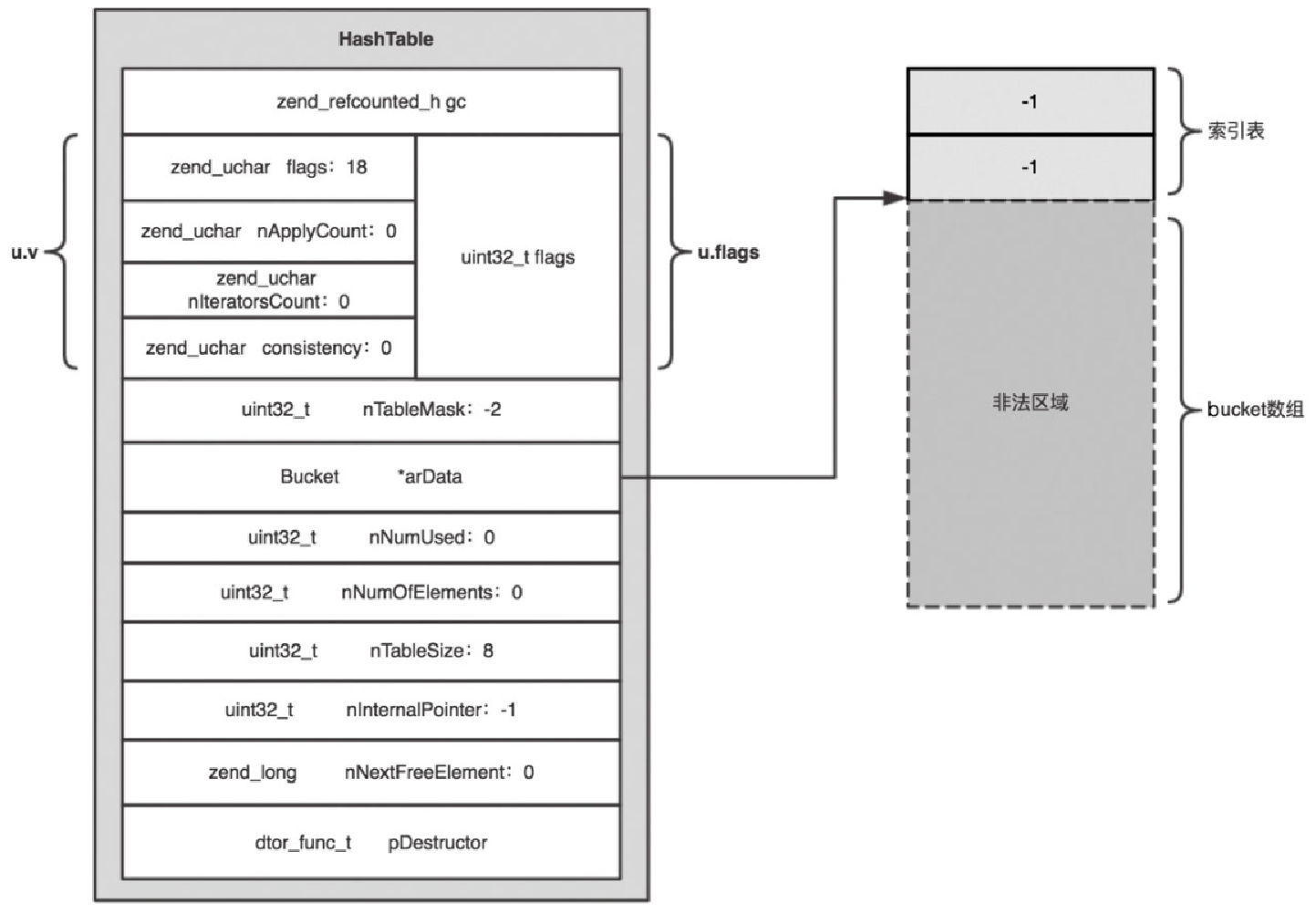
nTableSize=8,因为 HashTable 内部的 arBuckets 的大小是 2 的 n 次方,并且最小值是 8,最大值为 0x80000000。
u.v.flags=18。在 PHP 7 中,定义了 6 个 flag,如下:
#define HASH_FLAG_PERSISTENT (1<<0)
#define HASH_FLAG_APPLY_PROTECTION (1<<1)
#define HASH_FLAG_PACKED (1<<2)
#define HASH_FLAG_INITIALIZED (1<<3)
#define HASH_FLAG_STATIC_KEYS (1<<4) /* long and interned strings */
#define HASH_FLAG_HAS_EMPTY_IND (1<<5)flags = 18 = HASH_FLAG_STATIC_KEYS | HASH_FLAG_APPLY_PROTECTION。
而 flag & HASH_FLAG_INITIALIZED 等于 0 说明,该数组尚未完成真正的初始化,即尚未为 arData 分配内存。
nTableMask=-2,表示索引表的大小为 2。packed array 的索引表未使用到,即 nTableMask 永远等于 -2。
nInternalPointer=-1,由于尚未初始化 arData, nInternalPointer 等于 -1,表示无效的遍历下标。
以上了解了初始化一个空数组的过程,那么如果 不是空数组,数组的初始化是否仍然发生在 编译阶段 呢?
实际上如果数组的元素都是 常量表达式,那么这个数组的初始化仍然会在 编译阶段 完成,初始化之后的数组在执行阶段作为数组常量被赋值给其他的变量。例如下面的代码,将一个非空数组赋值给 $a 这个变量。
<?PHP
$a[] = 'foo';查看执行的 opcodes:
./phpdbg -p* array.php
function name: (null)
L1-4 {main}() /root/php7/array.php -0x7f6f9e07a000 + 3 ops
L2 #0 ASSIGN_DIM $a NEXT
L2 #1 OP_DATA "foo"
L4 #2 RETURN 1
[Script ended normally]赋值语句对应的那行代码经过编译之后,也会生成两个 opcode 指令:ASSIGN_DIM 和 OP_DATA。执行到 opcode 的 ASSIGN_DIM 时候,才会真正初始化哈希表,具体步骤如下。
-
第 1 步:调用
ZEND_ASSIGN_DIM_SPEC_CV_CONST_OP_DATA_CONST_HANDLER(具体内容会在第 11 章中阐述)。 -
第 2 步:调用
zend_hash_next_index_insert函数。variable_ptr = zend_hash_next_index_insert(Z_ARRVAL_P(object_ptr), &EG(uninitialized_zval)); -
第 3 步:调用
zend_hash_real_init_ex初始化arData,具体代码如下。static zend_always_inline void zend_hash_real_init_ex(HashTable *ht, int packed){ /* packed:h < ht->nTableSize , h=0 , ht->nTableSize默认为8*/ if (packed) {//packed array初始化 /*为arData申请分配内存,并把arData的指针偏移指向buckets数组的首地址*/ HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_ PERSISTENT)); /*修改flags为 已经初始化并且为packed array*/ (ht)->u.flags |= HASH_FLAG_INITIALIZED | HASH_FLAG_PACKED; / /*nIndex置为无效标识-1, arData[-1]=-1 , arData[-2]=-1*/ HT_HASH_RESET_PACKED(ht); //-1-2 置为-1 } else {//普通哈希表的初始化 /*掩码nTableMask为nTableSize的负数,即nTableMask = -nTableSize,因为 nTableSize等于2n,所以nTableMask二进制位右侧全部为0,也就保证了nIndex落在数组索 引的范围之内(|nIndex| <= nTableSize):*/ (ht)->nTableMask = -(ht)->nTableSize; HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_ PERSISTENT)); (ht)->u.flags |= HASH_FLAG_INITIALIZED; if (EXPECTED(ht->nTableMask == (uint32_t)-8)) { Bucket *arData = ht->arData; HT_HASH_EX(arData, -8) = -1; ... HT_HASH_EX(arData, -1) = -1; } else { HT_HASH_RESET(ht); //调用memset函数把所有内存设置成无符号整型的-1 } } }
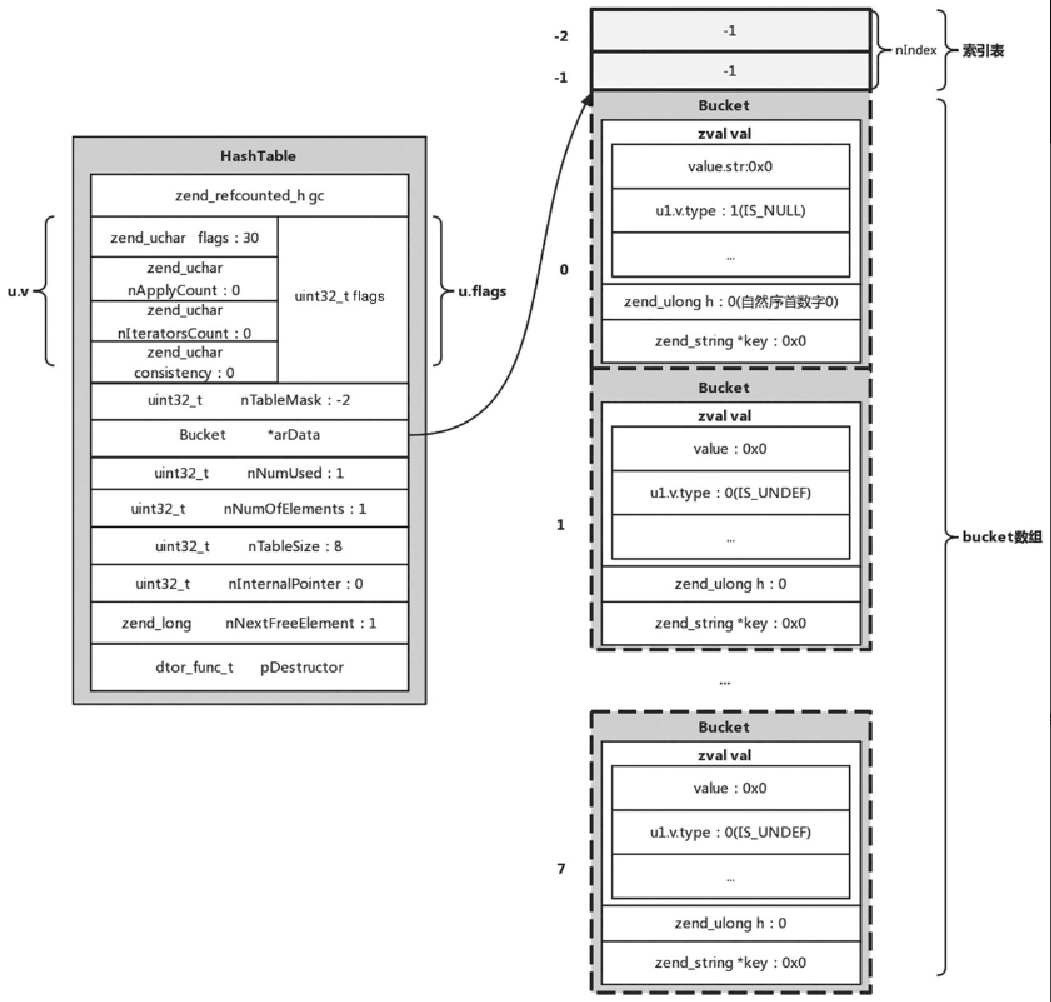
ASSIGN_DIM:对数组或者对象的某一个元素或者字段进行赋值。如果是数组,第一个操作数 op1 表示数组,第二个操作数 op2 表示 index。op2 可以省略,代表按自然顺序来赋值,执行完这一句之后,HashTable 才真正地被初始化完毕,还默认会把第一个 bucket 的 val 设置成空(也就是值 &EG(uninitialized_zval)), key=null, h=0(自然序增长的第一个值 0),这时候的 HashTable 的结构如图 5-12 所示。
OP_DATA:被赋值的数据,其实存储在这条 opcode 中。该 opcode 紧跟着 ASSIGN_DIM 出现,并且不会单独执行,而是在 ASSIGN_DIM 执行的时候,一块执行。执行的代码如下:
value = EX_CONSTANT((opline+1)->op1); // 从zend_execute_data的*literals去获取临时变量的值,op1存的是偏移量,这里取到的value实际值为 "foo"
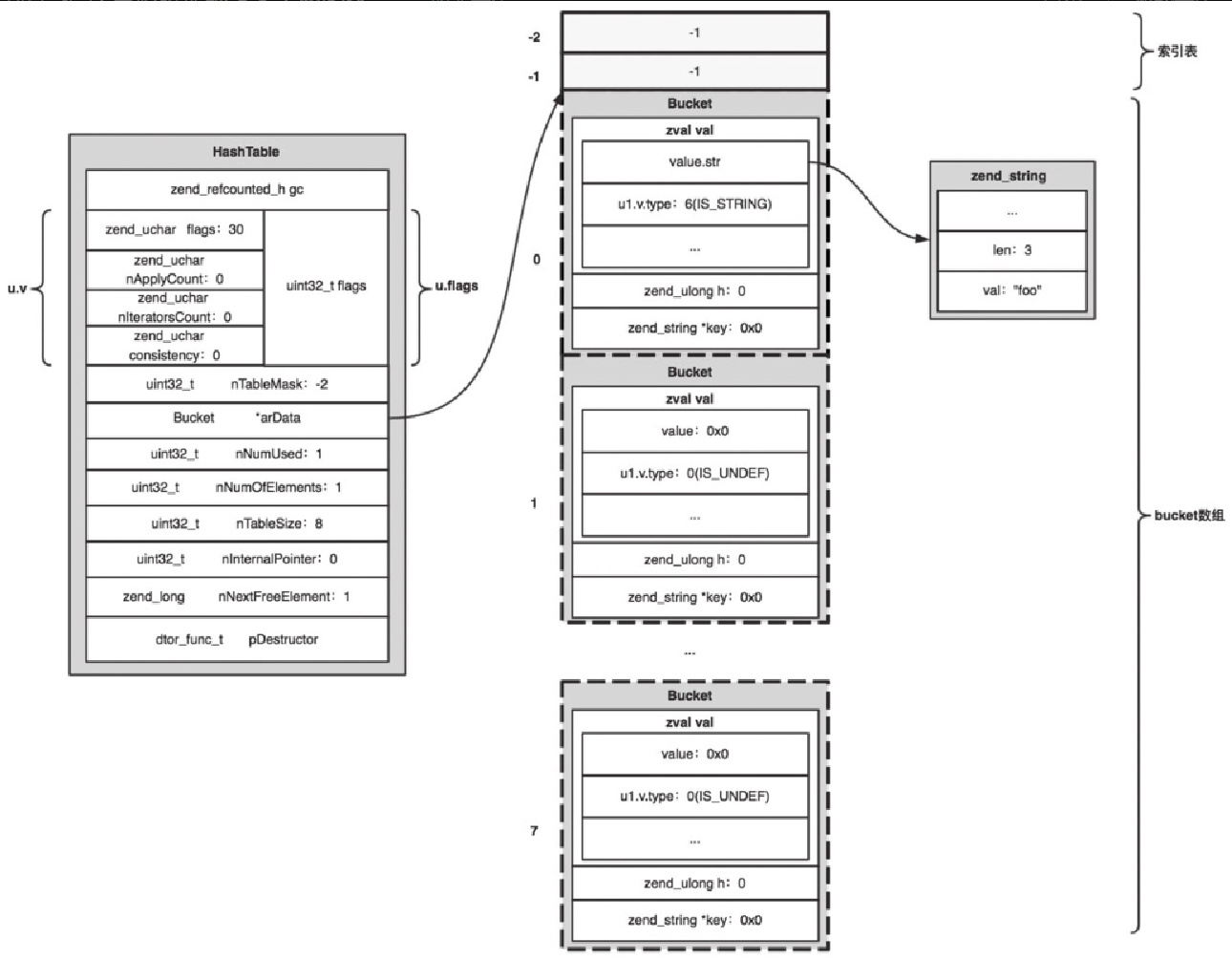
value = zend_assign_to_variable(variable_ptr, value, IS_CONST); //赋值给前一个bucket的val执行之后,内存中的 HashTable 变成了什么样呢?如图5-13所示。
-
HashTable的arData被真正地分配内存,并且按最小值 8 分配了 8 个bucket的存储空间。 -
flags=30=HASH_FLAG_STATIC_KEYS |HASH_FLAG_APPLY_PROTECTION|HASH_FLAG_PACKED|HASH_FLAG_INITIALIZED说明当前HashTable.arData已经被初始化完毕,并且当前HashTable是packed array。 -
nTableMask仍然是-2,因为是packed array。 -
$a[]对于首次插入,h值等于 0。对于packed array插入到了bucket数组的第一个位置(下标为 0)。 -
bucket里面内嵌了zval。 -
nNumUsed=1,由于bucket数组是连续分配的内存,nNumUsed=1代表已经使用了 1 个bucket,那就是arData[0]这个bucket。 -
nNumOfElements=1,表示当前HashTable中有一个有效元素arData[0]。 -
nInternalPointer=0,遍历下标,表示遍历HashTable时从arData[0]开始。 -
nNextFreeElement=1,自然下标,下次自然序插入时,h值为 1。
如果数组的元素不是常量表达式呢?例如下面的代码,将变量 $b 作为数组的元素:
<?PHP
$b = 1;
$a = array($b);查看执行的 opcodes:
./phpdbg -p* array.php
function name: (null)
L1-5 {main}() /root/php7/array.php -0x7f512b879000 + 4 ops
L2 #0 ASSIGN $b 1
L3 #1 INIT_ARRAY $b NEXT ~1
L3 #2 ASSIGN $a ~1
L5 #3 RETURN 1
[Script ended normally]第一个 opcode 是 ASSIGN,将 1 赋值给 $b,对应第一行代码。第二行代码被解析成了两个 opcode:INIT_ARRAY 和 ASSIGN。INIT_ARRAY,顾名思义,该 opcode 表示数组的初始化,它的操作数是 !0,即 $b,并返回 ~1 这个临时变量。紧接着通过 ASSIGN 这个 opcode,将 ~1 赋值给 !1,即 $a。对于数组元素不是常量的数组,数组的初始化是在 执行阶段 (执行 INIT_ARRAY 时)才进行的。
了解了数组初始化的时机后,数组初始化时都做了哪些事情呢?让我们先自己思考一下,初始化要做的事情无非就是两件:分配内存 和 设定初始值。分配内存首先肯定要申请 HashTable 这个结构体的内存,但是存储 bucket 的连续内存是否也要一块申请呢?在此,PHP 7 使用了懒惰(lazy)的思想,按需分配 bucket 数组内存。也就是说,只有当真正需要使用 bucket 时才去申请。
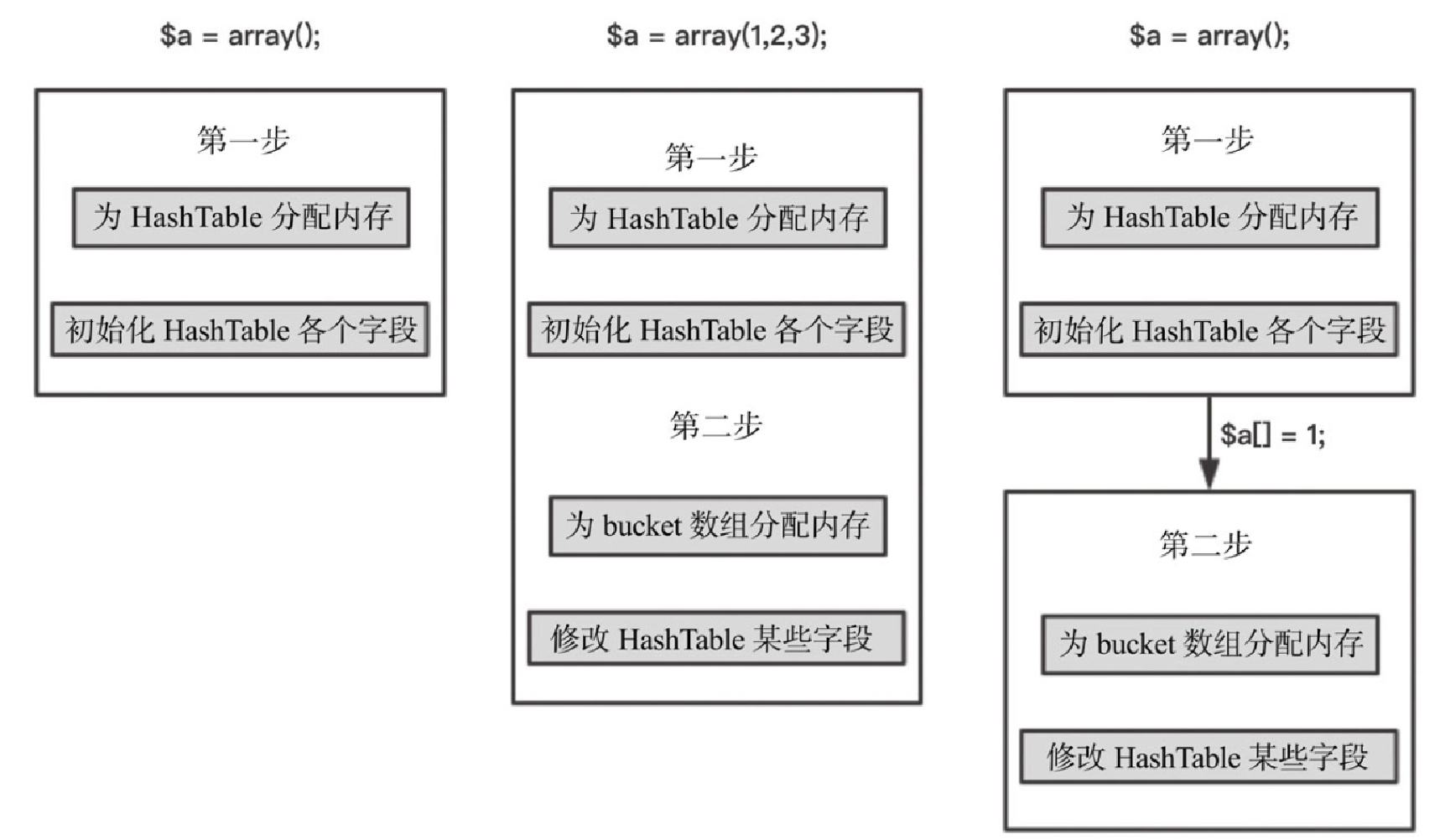
因此,在 PHP 7 中,数组的初始化其实是分两步的。
-
第 1 步:分配
HashTable结构体内存,并初始化各个字段。 -
第 2 步:分配
bucket数组内存,修改一些字段值。
对于第 2 步,不是每次初始化都会进行。比如像 “$a = array()” 这种写法,由于数组为空,PHP 7 不会额外申请 bucket 数组内存。而对于 “$a = array(1, 2, 3)” 这种写法,由于数组非空,因此 PHP 7 需要执行第 2 步的初始化,分配 bucket 数组内存。
只完成了第 1 步的初始化,数组是没法直接使用的,这时候如果需要对数组进行插入、更新操作,会首先进行第 2 步的初始化,再做后续的操作。不同场景初始化流程如图5-14所示。
接下来看看具体的源码细节。在 PHP 7 中,数组可以依赖于 zval 而存在,也可以单独存在。对应 HashTable 内存分配的宏分别是 ZVAL_NEW_ARR 和 ALLOC_HASHTABLE,源代码如下:
#define ZVAL_NEW_ARR(z) do { \
zval *__z = (z); \
zend_array *_arr = \
(zend_array *) emalloc(sizeof(zend_array)); \
Z_ARR_P(__z) = _arr; \
Z_TYPE_INFO_P(__z) = IS_ARRAY_EX; \
} while (0)
#define ALLOC_HASHTABLE(ht) \
(ht) = (HashTable *) emalloc(sizeof(HashTable))我们看到,核心调用都是一样的,都是通过 emalloc 从内存池申请 sizeof(zend_array) 大小的内存空间(假设环境变量 USE_ZEND_ALLOC 不等于 0)。为 HashTable 分配内存之后,会调用 _zend_hash_init 函数初始化 HashTable 的各个字段:
ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_
func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC)
{
GC_REFCOUNT(ht) = 1;
GC_TYPE_INFO(ht) = IS_ARRAY;
ht->u.flags = (persistent ? HASH_FLAG_PERSISTENT : 0) | HASH_FLAG_APPLY_
PROTECTION | HASH_FLAG_STATIC_KEYS;
ht->nTableMask = HT_MIN_MASK;
HT_SET_DATA_ADDR(ht, &uninitialized_bucket);
ht->nNumUsed = 0;
ht->nNumOfElements = 0;
ht->nInternalPointer = HT_INVALID_IDX;
ht->nNextFreeElement = 0;
ht->pDestructor = pDestructor;
ht->nTableSize = zend_hash_check_size(nSize);
}_zend_hash_init 函数的入参有 4 个(ZEND_FILE_LINE_DC 记录文件名字和行号,在 debug 开启的时候才有效,可以忽略)。其中 ht 正是上一步分配内存之后返回的指针,nSize 表示希望申请的 HashTable 的大小。pDestructor 是析构函数指针,对于使用 ZVAL_NEW_ARR 宏分配内存的场景,一般传过来的 pDestructor 是 ZVAL_PTR_DTOR 宏。最后一个参数 persistent 表示分配 bucket 数组的内存时是否使用永久内存(不使用内存池)。
再看看 _zend_hash_init 都干了些什么。
-
设置
ht的引用计数为 1,引用计数类型为IS_ARRAY(数组类型)。 -
设置
ht->u.flags为HASH_FLAG_APPLY_PROTECTION|HASH_FLAG_STATIC_KEYS(18 = 2 | 16),即HashTable默认是递归遍历保护的和静态key的(关于这两个flag后面会详细介绍)。如果入参persistent不为 0,那么再增加一个flag:HASH_FLAG_PERSISTENT,即在永久内存上分配bucket。 -
设置
nNumUsed、nNumOfElements为 0,因为现在还没有使用任何数组元素。 -
设置
nInternalPointer为-1,表示尚未设置全局遍历游标。 -
设置
nNextFreeElement为0,表示数组的自然key从0开始。 -
设置析构函数指针为
pDestructor。 -
设置
nTableSize,如果传递的nSize不是2n,会通过zend_hash_check_size函数计算大于等于nSize的最小的2n,例如nSize=10,那么最终ht->nTableSize取值为 16。 -
设置
ht->arData指向uninitialized_bucket的尾部。 -
设置
nTableMask是HT_MIN_MASK,即-2(uninitialized_bucket数组的大小)。
uninitialized_bucket 是一个全局索引数组,size 为 2,默认索引值都是 -1,源码如下:
static const uint32_t uninitialized_bucket[-HT_MIN_MASK] =
{HT_INVALID_IDX, HT_INVALID_IDX};其中,HT_MIN_MASK 为 -2, HT_INVALID_IDX 为 -1。前文提到过 ht->arData 指向 bucket 数组的起始位置,而在它前面还有一个索引数组。ht->arData 指向 uninitialized_bucket 的尾部,反过来想 uninitialized_bucket 正是 ht 的索引数组,实际上,作为一个全局数组,所有的未进行第 2 步初始化的 HashTable 的索引数组都是它(注意:这时 ht->arData 所引用的 bucket 数组是无效的、非法的)。
另外,这个数组的大小为什么是 2 呢?我们知道 nTableSize 的最小值是 8,如果按 nTableMask = -nTableSize 的算法,这个索引数组的大小应该是 8 才对。笔者认为这样设计有两方面原因:一方面由于 lazy 初始化,能节省点空间就节省点空间,所以这里取 2 更加合适。另一方面,则是下一节要讨论的主题,对于某些场景(packed array),索引数组是多余的,nTableMask 并不总是等于 -nTableSize,因此这里在尚未确定数组的使用方式时,为了节省内存,使用了大小为 2 的数组作为默认索引数组。
经过上面的初始化之后,HashTable 在内存中的示意如图5-15所示。
关于第 2 步初始化,不同的场景执行的逻辑略有不同。这种差异化源自 PHP 7 对数组的分类 packed array 和 hash array 之间的差别。为了更顺畅地说明问题,下一节将为大家讲解 packed array 和 hash array,并继续阐述第 2 步初始化的细节。
packed array 和 hash array 的区别
本章在开始的时候提到过 PHP 数组的两种用法,一种是纯数组,另一种是基于 key-value 的 map。例如下面的代码:
$a = array(1,2,3); //纯数组
$b = array('x'=>1, 'y'=>2, 'z'=>3); //map对于这两种用法,PHP 7 引申出了 packed array 和 hash array 的概念。当 HashTable 的 u.v.flags & HASH_FLAG_PACKED > 0 时,表示当前数组是 packed array,否则当前数组是 hash array。
-
内存的本质区别
packed array和hash array的区别在哪里呢?先看一段曾经令笔者奇怪的代码://文件一:a.PHP <?PHP $memory_start = memory_get_usage(); $test = array(); for($i=0; $i<=200000 ; $i++){ $test[$i] = 1; } echo memory_get_usage() - $memory_start, " bytes\n"; //文件二:b.PHP <?PHP $memory_start = memory_get_usage(); $test = array(); for($i=200000; $i>=0; $i--){ $test[$i] = 1; } echo memory_get_usage() - $memory_start, " bytes\n";这两个脚本都是使用数组存放 20 万个相同的元素,第一个 PHP 文件是从小到大进行插入,第二个 PHP 文件则相反,是从大到小进行插入。最终执行的结果如下:
[root@docker100327~]# PHP a.PHP 8392784 bytes [root@docker100327~]# PHP b.PHP 9437264 bytes我们看到,两个脚本使用的内存并不一样,
b脚本会比a脚本大概多使用 1MB 左右的内存。这是为什么呢?原因就在于这两种写法,test数组的内存结构是有区别的,一种是packed array,另一种是hash array。是不是很神奇? -
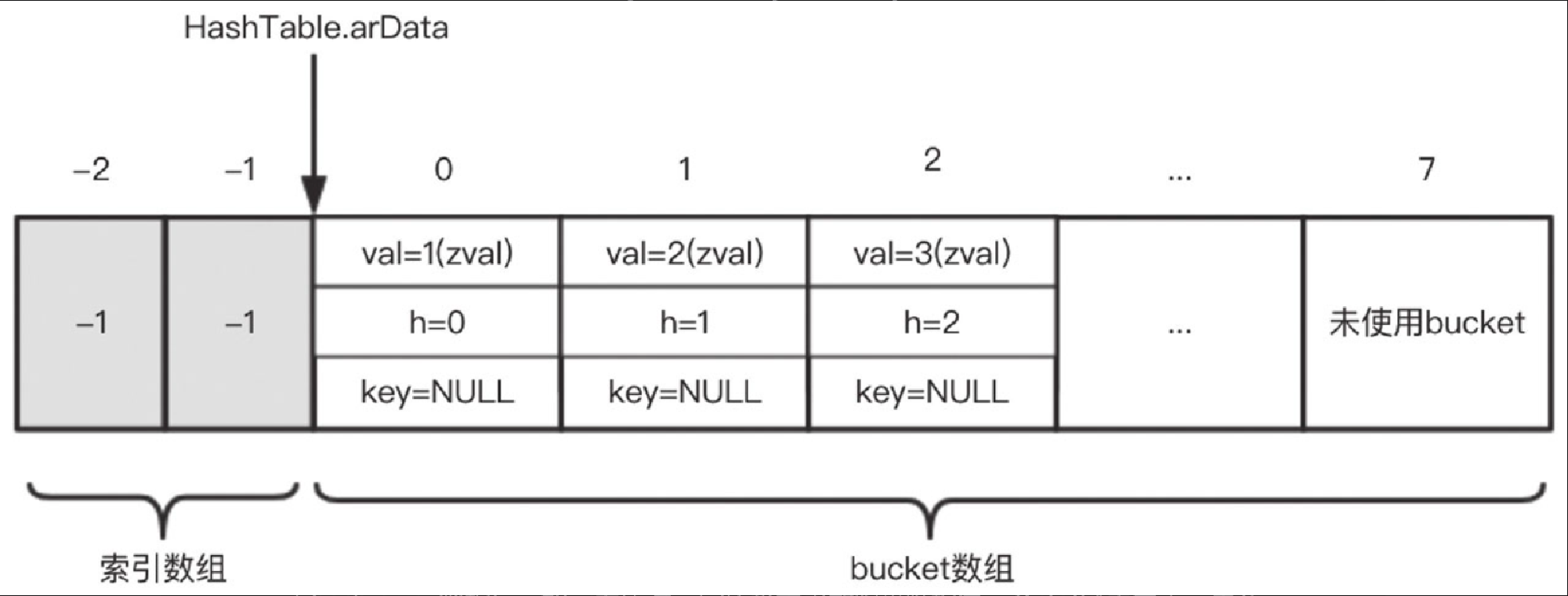
packed array
packed array具有以下约束和特性。-
key全是数字key。 -
key按插入顺序排列,仍然是递增的。 -
每一个 key-value 对的存储位置都是确定的,都存储在 bucket 数组的第
key个元素上。 -
packed array不需要索引数组。
-
它实际上利用了 bucket 数组的连续性特点,对于某些只有数字 key 的场景进行的优化。由于不再需要索引数组,从内存空间上节省了 (nTableSize-2 )* sizeof(uint32_t) 个字节。另外,由于存取 bucket 是直接操作 bucket 数组,在性能上也有所提升。
对于本节开始的例子,$a 的 key 都是数字 key,并且 key 插入的顺序分别是 0、1、2,满足递增的特性,所以 $a 是 packed array。
PHP 7 中 packed array 的实现示意图如图5-16所示。
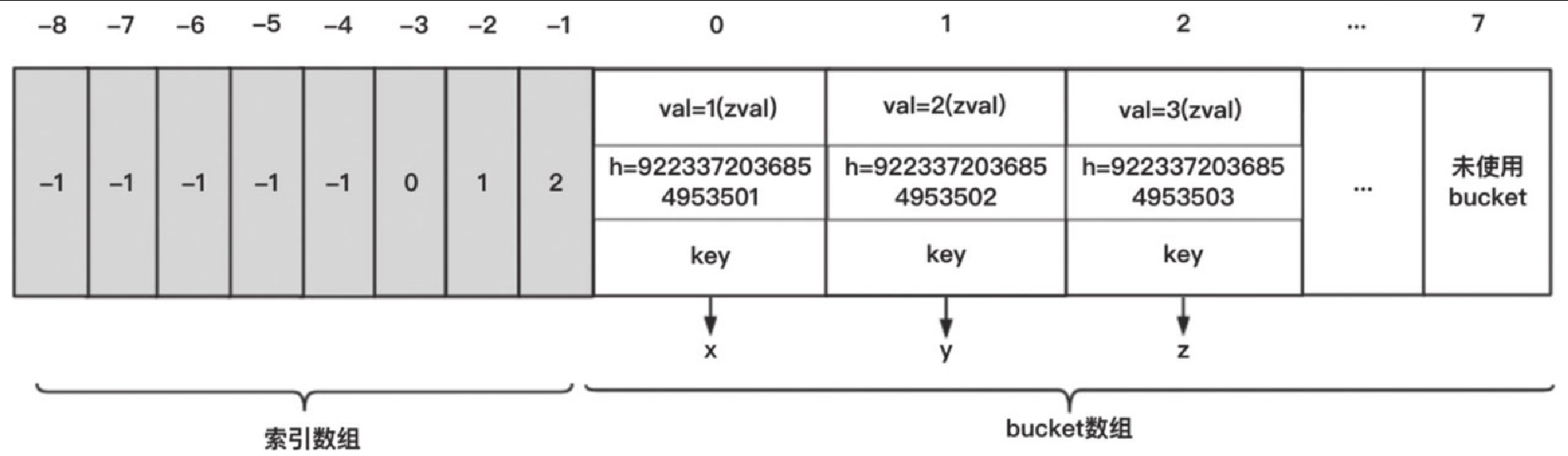
而 hash array 则相反,如前面所讲,它依赖 索引数组来维护每一个 slot 链表中首元素在 bucket 数组中的下标。对于本节开始的例子,$b 的 key 都是字符串,因此 $b 不是 packed array,而是 hash array。
显然无法像 packed array 一样,直接根据 key 定位到在 bucket 数组的下标,这时索引数组就派上用场了。拿 key 为 x 举例,字符串 x 的 h 值是 9223372036854953501,它与 nTableMask(-8) 做位或运算之后,结果是 -3,然后我们索引数组去查询 -3 这个 slot 的值,得出该 slot 链表首元素在 bucekt 数组的下标为 0。因此按照这个下标找下去,肯定会找到 key 为 x 的元素,目前看,其实正是 bucket 数组的第 0 个元素。同理,key 为 y 和 z 的元素挂在了 slot 值为 -2 和 -1 这两个逻辑链表上,如图5-17所示。
关于 packed array,读者可能还有一些误区,看下面几个例子:
$a = array(1=>'a',3=>'b',5=>'c'); //例子1,仍然是packed array
$b = array(1=>'a',5=>'c',3=>'b'); //例子2,不再是packed array,而是hash array
$c = array(1=>'a',8=>'b'); //例子3,不再是packed array,而是hash array例子1, packed array 并不是说数组的 key 一定要连续递增,因此 $a 是 packed array。
例子2, key 按插入顺序排列是 1、5、3,非递增,因此 $b 不是 packed array。为什么 packed array 要求 key 的顺序是递增的呢?假设仍然按 packed array 的方式,将 $b 数组中的各个元素放入 bucket 数组中,看看插入后的结果,如图5-18所示。
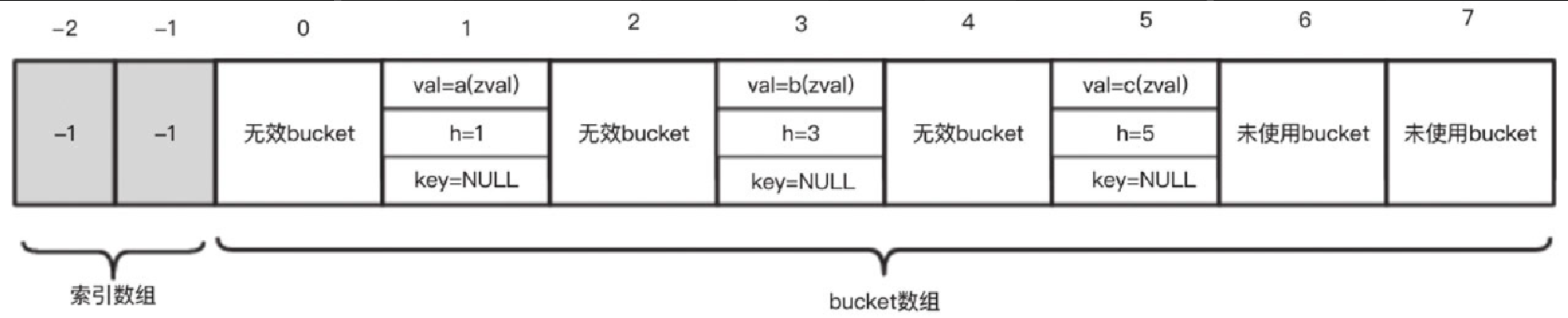
$b 数组相应的 3 个元素分别被插入到了 bucket 数组中的第 1、5、3 这 3 个下标中。我们发现,这和 $a 数组的内存是一模一样的。但 $a 和 $b 在 PHP 中是两个不同意义的数组,因为它们拥有不同的插入顺序,所以 $b 是 packed array 则不成立了。
还记得 5.1.1 节提到的数组的语义吗?第二个语义提到 PHP 数组是有序的,那么 PHP 7 中是如何实现这个语义的呢?实际上,PHP 7 通过 bucket 数组本身就实现了有序性,它保证在插入元素的时候,始终在 bucket 数组的最后一个有效元素的后面插入。因此从头开始遍历 bucket 数组,遍历的结果正是插入的顺序(关于元素的插入后面会详细讲解)。
例子3, key 按插入顺序排列是 1、8,是递增有序的,但 $c 为什么不是 packed array 呢?其实理论上是可以的,但如果按 packed array 插入的话,会比较浪费空间,如图5-19所示。
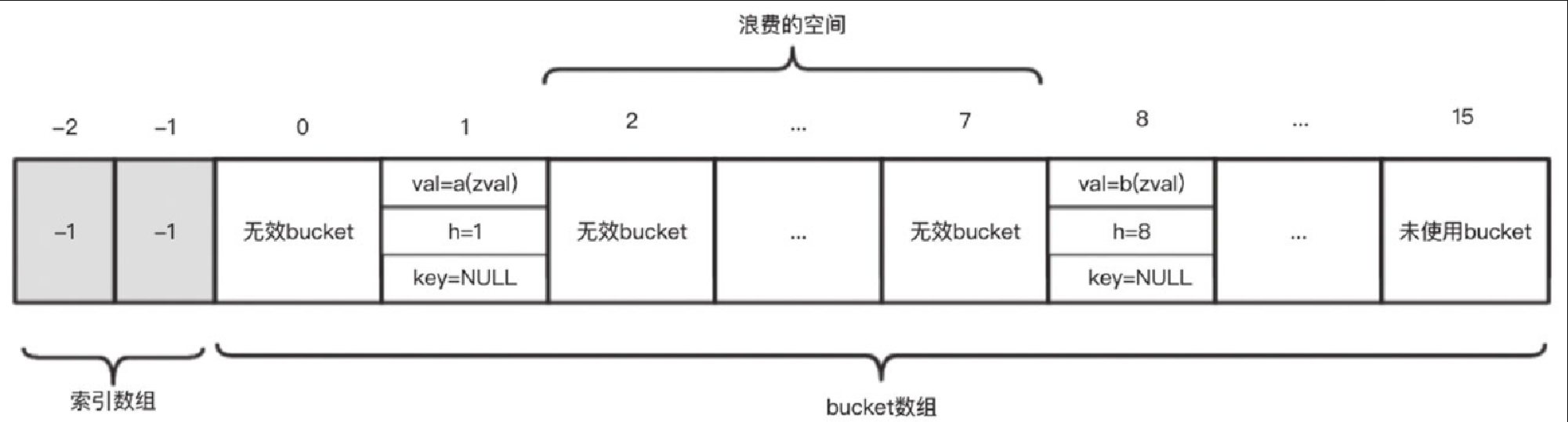
bucket 数组中下标为 2~7 的 6 个 bucket 为了保持 packed array 特性,无法再插入元素,成为浪费的空间。因此,PHP 7 会在 packed array 的空间效率以及时间效率优化与空间浪费之间做一个平衡,当空间浪费比较多的时候,空间效率反而不如 hash array,这时 PHP 7 会将 packed array 转化为 hash array,而变成下面的样子,可看到 bucket 数组的大小仍然维持在 8,如图5-20所示。
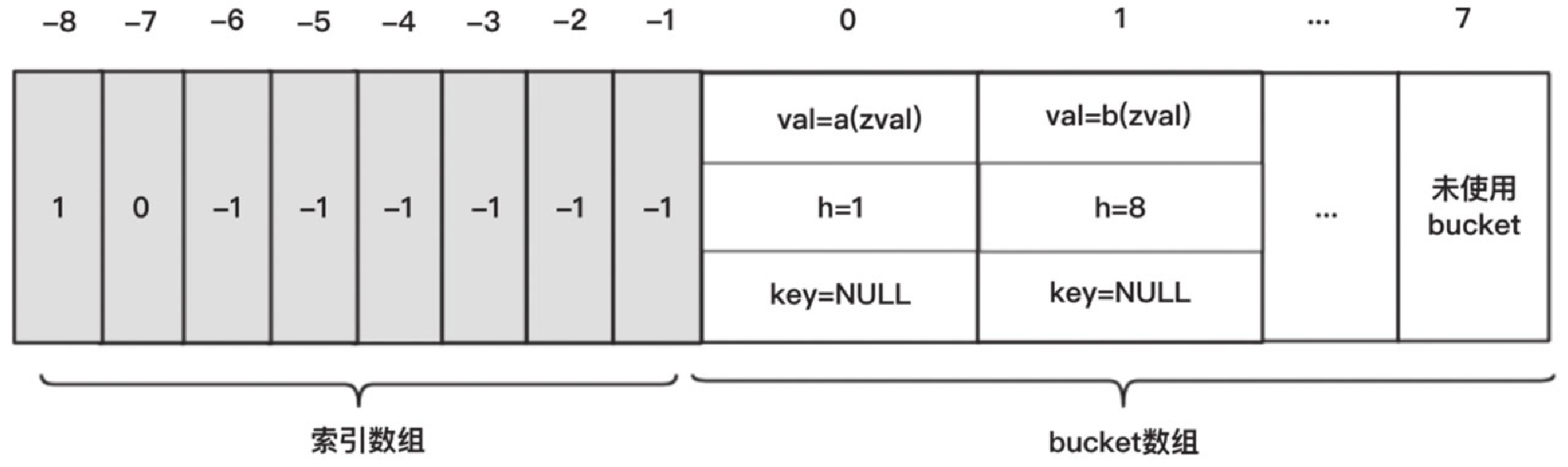
清楚了 packed array 和 hash array 之间的区别后,再回过头来继续看看数组的初始化。
上一节讲到数组的初始化分两步,第 2 步的初始化只有在真正需要使用 bucket 数组的时候,才会进行。它会调用 zend_hash_real_init 函数,该函数有两个入参,ht 指向要初始化的 HashTable, packed 表示是否将 HashTable 初始化为 packed array。在内部,它会调用 zend_hash_real_init_ex 函数,执行真正的初始化逻辑,源码如下:
ZEND_API void ZEND_FASTCALL zend_hash_real_init(HashTable *ht, zend_bool packed)
{
IS_CONSISTENT(ht);
HT_ASSERT(GC_REFCOUNT(ht) == 1);
zend_hash_real_init_ex(ht, packed);
}
static zend_always_inline void zend_hash_real_init_ex(HashTable *ht, int packed)
{
HT_ASSERT(GC_REFCOUNT(ht) == 1);
ZEND_ASSERT(! ((ht)->u.flags & HASH_FLAG_INITIALIZED));
if (packed) {
HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_
PERSISTENT));
(ht)->u.flags |= HASH_FLAG_INITIALIZED | HASH_FLAG_PACKED;
HT_HASH_RESET_PACKED(ht);
} else {
(ht)->nTableMask = -(ht)->nTableSize;
HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_
PERSISTENT));
(ht)->u.flags |= HASH_FLAG_INITIALIZED;
if (EXPECTED(ht->nTableMask == (uint32_t)-8)) {
Bucket *arData = ht->arData;
HT_HASH_EX(arData, -8) = -1;
HT_HASH_EX(arData, -7) = -1;
HT_HASH_EX(arData, -6) = -1;
HT_HASH_EX(arData, -5) = -1;
HT_HASH_EX(arData, -4) = -1;
HT_HASH_EX(arData, -3) = -1;
HT_HASH_EX(arData, -2) = -1;
HT_HASH_EX(arData, -1) = -1;
} else {
HT_HASH_RESET(ht);
}
}
}这里使用到了两个宏 HT_SIZE 和 HT_SET_DATA_ADDR。
HT_SIZE 宏用来计算 ht 索引数组和 bucket 数组的大小总和。索引数组的大小等于 -nTableMask * sizeof(uint32_t), bucket 数组的大小等于 nTableSize *sizeof(Bucket)。
#define HT_HASH_SIZE(nTableMask) \
(((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t))
#define HT_DATA_SIZE(nTableSize) \
((size_t)(nTableSize) * sizeof(Bucket))
#define HT_SIZE_EX(nTableSize, nTableMask) \
(HT_DATA_SIZE((nTableSize)) + HT_HASH_SIZE((nTableMask)))
#define HT_SIZE(ht) \
HT_SIZE_EX((ht)->nTableSize, (ht)->nTableMask)申请 bucket 相关内存时,会通过 pemalloc 一次性申请 HT_SIZE 大小的内存,并返回这段内存的指针 ptr,当作 HT_SET_DATA_ADDR 宏的第二个参数。
HT_SET_DATA_ADDR 宏将 ht->arData 指向 ptr 这段内存中 bucket 数组的起始位置。从宏代码可以看到,就是将 ptr 之后 -nTableMask * sizeof(uint32_t) 个字节的位置指针赋值给 ht->arData,即让 arData 指向 bucket 数组的起始位置。
#define HT_SET_DATA_ADDR(ht, ptr) do { \
(ht)->arData = (Bucket*)(((char*)(ptr)) + HT_HASH_SIZE((ht)-> nTableMask)); \
} while (0)整个 zend_hash_real_init_ex 函数做的事情比较简单,分为 4 小步。
-
申请
bucket内存。如果是
packed array,由于这时nTableMask等于-2,所以会通过pemalloc申请大小为2 * sizeof(uint32_t) + nTableSize * sizeof(Bucket)的内存。如果是
hash array,会先将nTableMask置为-nTableSize,然后通过pemalloc申请大小为nTableSize * sizeof(uint32_t) + nTableSize * sizeof(Bucket)的内存。内存申请时,如果
ht->u.flags & HASH_FLAG_PERSISTENT > 0,那么不会在内存池上申请内存,而是直接通过malloc申请系统内存。一般情况下,ht->u.flags &HASH_FLAG_PERSISTENT都为 0,即会优先使用内存池来分配bucket相关内存。 -
通过
HT_SET_DATA_ADDR设置ht->arData指向bucket数组内存。 -
修改
ht->u.flags。如果是
packed array,设置ht->u.flags |= HASH_FLAG_INITIALIZED |HASH_FLAG_PACKED,表示该数组已经完成初始化,并且是packed array。如果是
hash array,设置ht->u.flags |= HASH_FLAG_INITIALIZED,表示该数组已经完成初始化,但不是packed array。 -
初始化索引数组。
如果是
packed array,使用HT_HASH_RESET_PACKED宏,设置索引数组中的各索引值为-1。如果是
hash array,若nTableSize等于 8,那么直接修改索引数组中的索引值为-1。否则使用HT_HASH_RESET宏设置索引数组中的各索引值为 -1。最终,经过真正初始化后,
packed array内存结构如图5-21所示。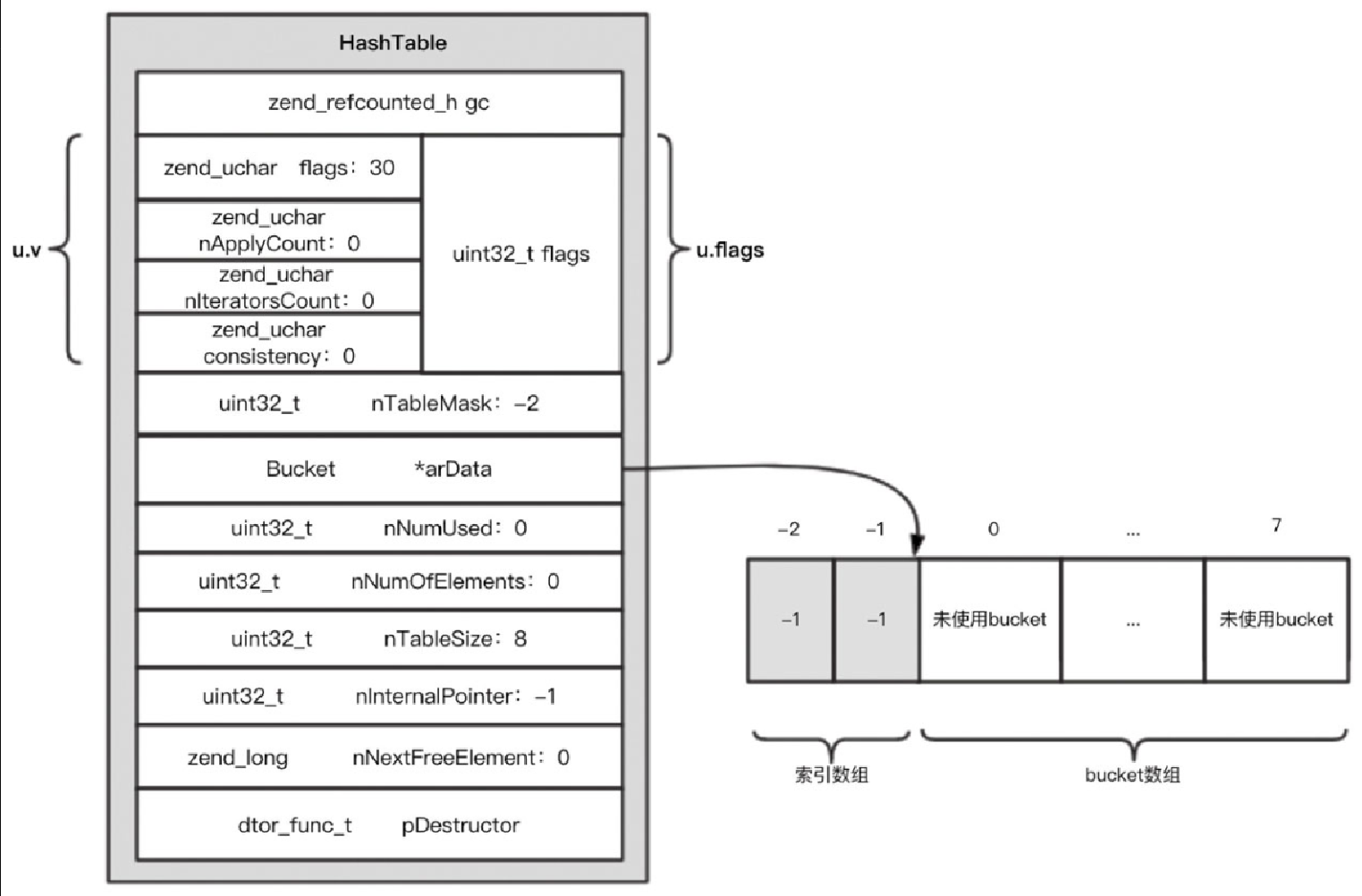 Figure 17. 图5-21 PHP 7中packed array初始化完成后的示意图
Figure 17. 图5-21 PHP 7中packed array初始化完成后的示意图hash array内存结构如图5-22所示。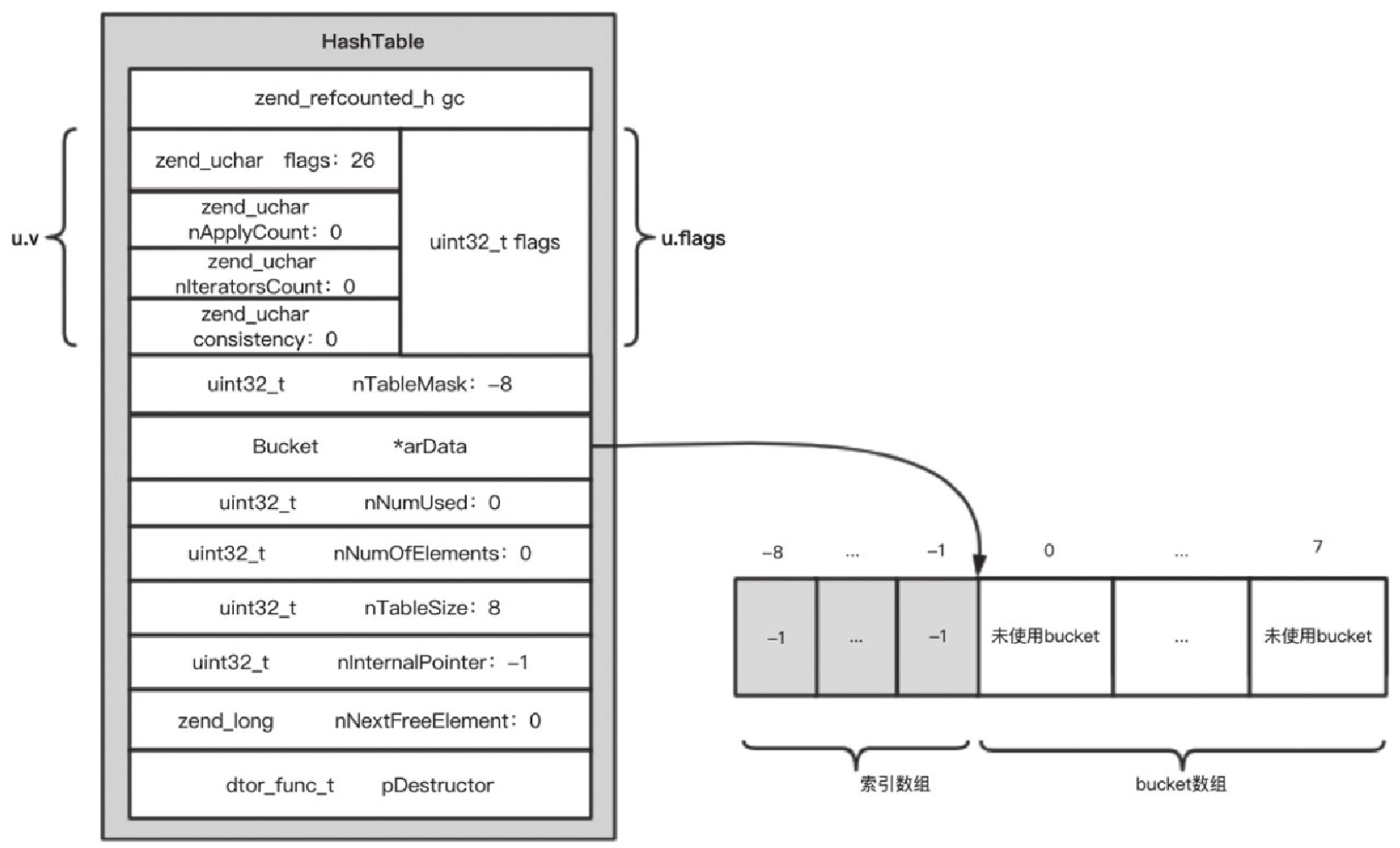 Figure 18. 图5-22 PHP 7中hash array初始化完成后的示意图
Figure 18. 图5-22 PHP 7中hash array初始化完成后的示意图为了让读者能直观地区分
packed array与hash array,下面举个例子,分别画出存储的结构图,对于普通hash array以如下代码为例:for($i=0; $i<=4 ; $i++){ $demo['a'.$i] = 1; //hash array }执行后的数组结构如图5-23所示。
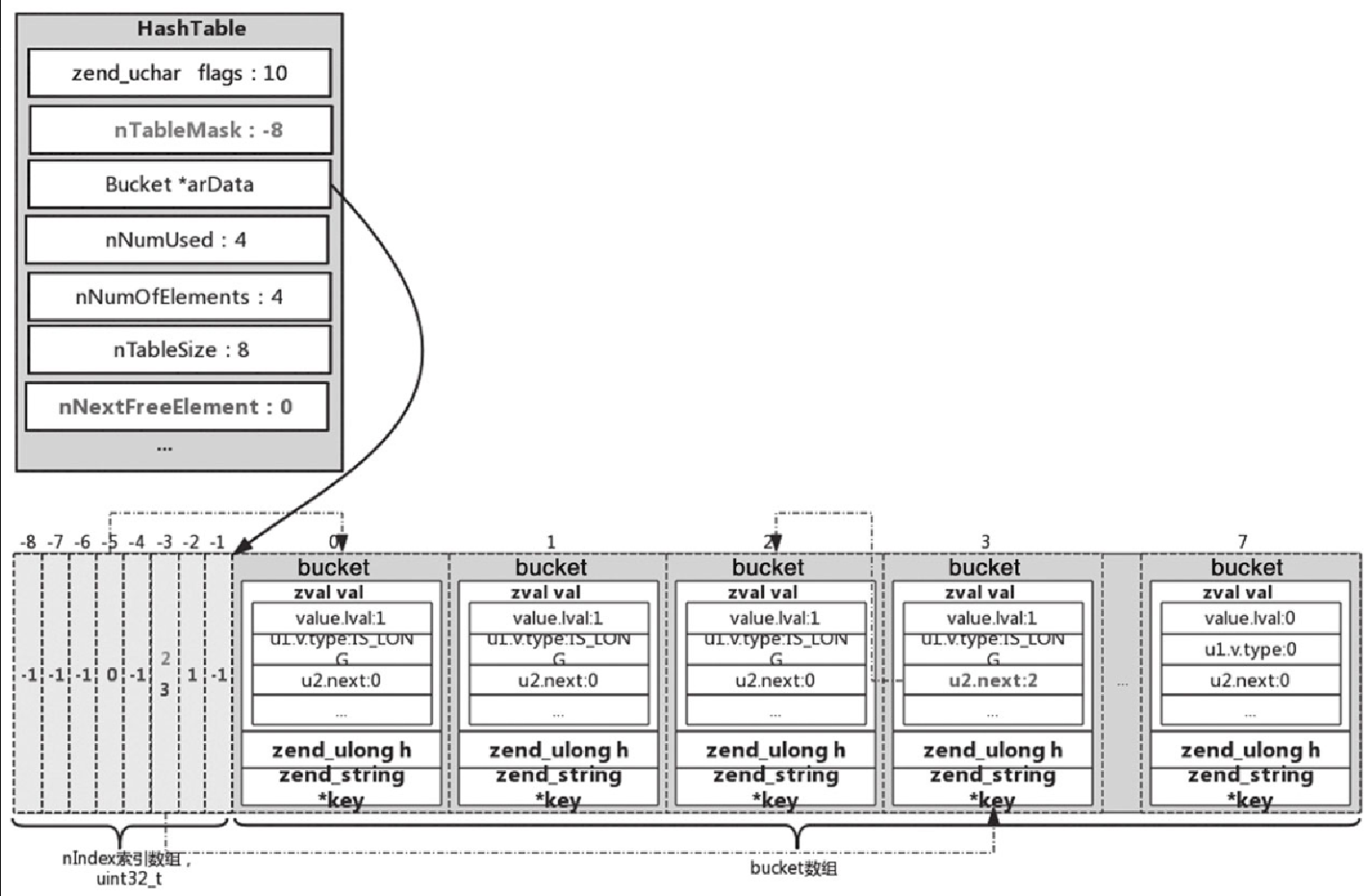 Figure 19. 图5-23 PHP 7中hash array赋值后的示意图
Figure 19. 图5-23 PHP 7中hash array赋值后的示意图说明:
-
hash array的nTableMask(掩码)始终等于-nTableSize。 -
hash array的arData由nIndex数组和bucket数组组成。nIndex数组与bucket数组实际是共享一块连续的内存,两个数组的长度一致,分配内存时nIndex数组与bucket数组一起分配,arData向后移动到了bucket数组的首地址。 -
hash array的哈希索引值存储在nIndex数组中,访问arData[-1]、arData[-2]、arData[-3]……结构是uint32_t。 -
hash array实际的key->value存储在bucket数组中,访问arData[0]、arData[1]、arData[2]……结构是_Bucket。 -
插入操作时,每一个
value具体在bucket数组中的存储位置(也就是arData的idx)idx = ht->nNumUsed++,可理解为就是按顺序递增插入,如第一个元素对应于arData[0]、第二个对应于arData[1]…arData[nNumUsed],插入后再把对应的idx值更新在nIndex索引数组中。 -
PHP 数组的有序性正是通过
arData的顺序插入保证的。每一个idx存储在索引数组中的具体位置则由映射函数根据key的hash值计算来确定。当key为字符串类型时,可以通过“h = zend_string_hash_val(key); ”的算法得到一个hash整型值;当key为数字时,则h直接等于key,然后与数组的掩码取 “|” 得到其在索引数组中的存储位置(nIndex = h | ht→nTableMask),再把idx值更新存储进去,arData[nIndex] = HT_IDX_TO_HASH(idx)。这样就建立了一个索引关系,当要根据一个key去取value的时候,过程一样,先得到key的hash值h,根据h得到nIndex,取出value在arData存储的位置idx,再取出bucket的val值。 -
哈希冲突,指的是不同的
key经过哈希函数得到相同的值,但这些值需要同时插入nIndex数组,当出现冲突时将原有arData[nIndex]存储的位置信息保存到新插入value的zval.u2.next中,图5-23中idx为 3 就是遇到哈希冲突时的存储示意图。 -
当插入的数组容量不够时,会进行扩容操作,新申请的
arData的容量是当前数组容量的两倍,所以nTableSize始终为2n。
对于
packed array,以如下代码为例:for($i=0; $i<=4 ; $i++){ $arr[$i] = 1; //packed array }执行后的数组结构如图5-24所示。
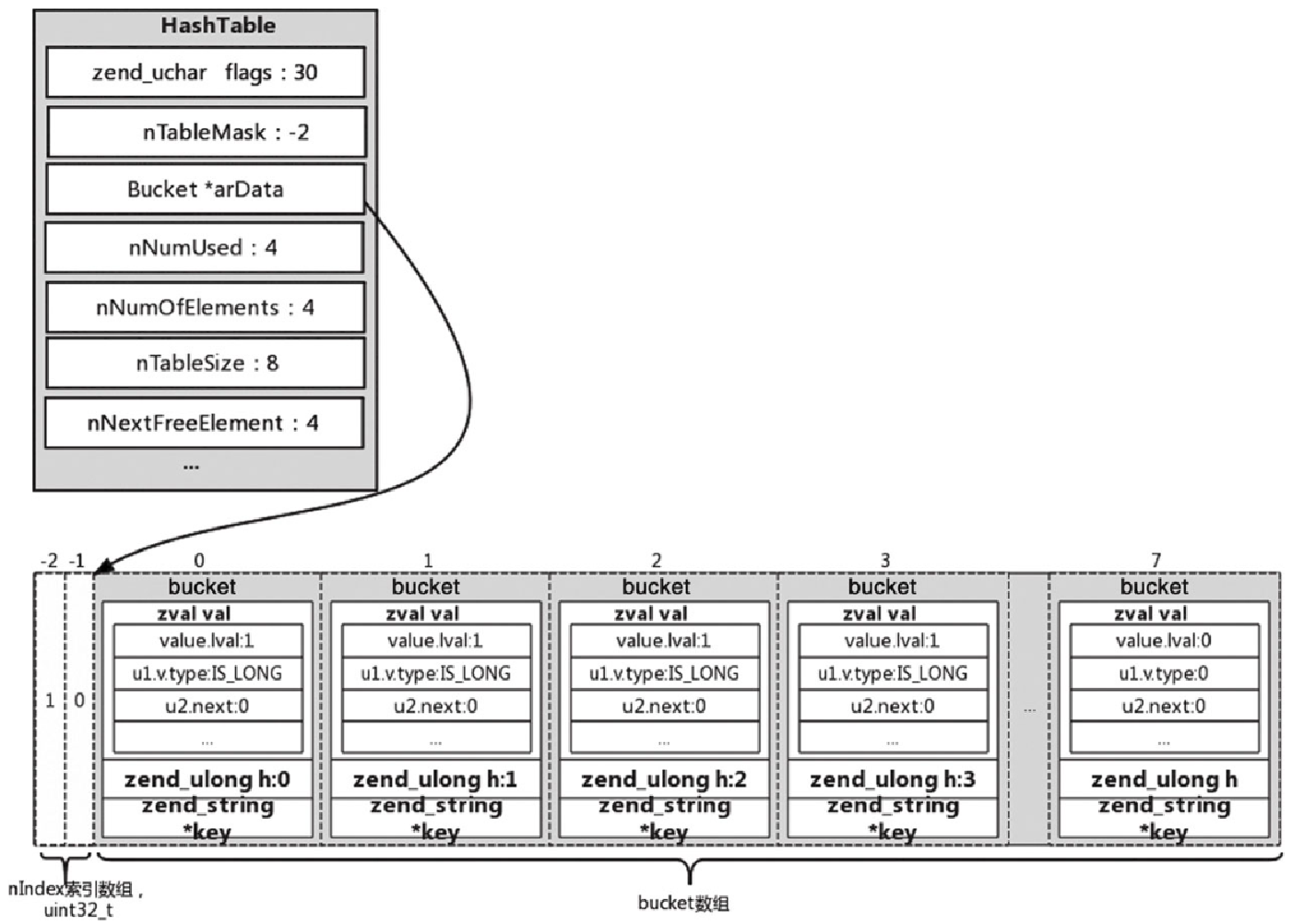 Figure 20. 图5-24 PHP 7中packed array赋值后的示意图
Figure 20. 图5-24 PHP 7中packed array赋值后的示意图说明:
-
packed array的nTableMask默认为-2。 -
packed array不会用到arData索引,因此省去了相关的索引内存。 -
arData和普通HashTable一样,都指向bucket数组的首地址。 -
bucket结构中的key默认为NULL,这主要是因为packed数组$arr索引“$i”的值的类型都是整数,“$i”对应的hash值就是本身,所以arr的“$i”直接存储在bucket.h上,无须冗余再去存储一个key,这点和普通的HashTable一致,bucket.key只存储字符串的key,为整数的时不再冗余存储。 -
插入操作时,无须去计算
hash值,也无须去维护索引数组,直接插入到bucket数组中去,插入的位置为idx=bucket.h=$i,非常简单,查找时也无须根据索引去找对应的存储位置,而是直接根据key值取到对应的bucket数组的val,效率极高。
-
插入、更新、查找和删除
前文已经讲述了数组初始化,普通的 hash array 和 packed array 的概念与区别,本节将讲述数组的插入、更新、删除和查找,其实这几个操作相对来说都比较简单,基本就是定位到元素所在 bucket 中的位置后进行写入、删除、查找。
PHP 7 在 zend_hash.h 中提供了丰富的 API 来操作 HashTable,包括前面提到的初始化以及接下来要讲到的插入、更新、删除、查询、遍历、拷贝、合并、排序、销毁等。本节将对数组元素的插入和更新操作进行详细讲解。
在 zend_hash.h 中,PHP 7 定义了如下 zend api,来对数组进行插入和更新操作。
/* additions/updates/changes */
ZEND_API zval* ZEND_FASTCALL _zend_hash_add_or_update(HashTable *ht, zend_string *key,
zval *pData, uint32_t flag ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_update(HashTable *ht, zend_string *key, zval
*pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_update_ind(HashTable *ht, zend_string *key, zval
*pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_add(HashTable *ht, zend_string *key, zval
*pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_add_new(HashTable *ht, zend_string *key, zval
*pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_str_add_or_update(HashTable *ht, const char
*key, size_t len, zval *pData, uint32_t flag ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_str_update(HashTable *ht, const char *key,
size_t len, zval *pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_str_update_ind(HashTable *ht, const char *key,
size_t len, zval *pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_str_add(HashTable *ht, const char *key,
size_t len, zval *pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_str_add_new(HashTable *ht, const char *key,
size_t len, zval *pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_index_add_or_update(HashTable *ht, zend_
ulong h, zval *pData, uint32_t flag ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_index_add(HashTable *ht, zend_ulong h,
zval *pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_index_add_new(HashTable *ht, zend_ulong h,
zval *pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_index_update(HashTable *ht, zend_ulong h,
zval *pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_next_index_insert(HashTable *ht, zval
* pData ZEND_FILE_LINE_DC);
ZEND_API zval* ZEND_FASTCALL _zend_hash_next_index_insert_new(HashTable *ht, zval
* pData ZEND_FILE_LINE_DC);从命名风格上可以分为 3 种 API。
-
_zend_hash_xxx,用来插入或者更新字符串key,并且字符串key是指向zend_string的指针。 -
_zend_hash_str_xxx,同样用来插入或者更新字符串key,不过字符串key是指向字符的指针,同时还需要一个len表示字符串的长度。 -
_zend_hash_index_xxx,用来插入或者更新数字key。
以如下代码为例:
$arr[] = 'foo'; //packed array,默认为packed array
$arr['a'] = 'bar'; //自定义key, packed_to_hash
$arr[2] = 'abc'; //自定义整数key
$arr[] = 'xyz'; //key取ht->nNextFreeElement
$arr['a'] = 'foo'; //自定义整数key
echo $arr['a']; //查找
unset($arr['a']); //删除上述代码会首先执行 zend_hash_init 函数,对 HashTable 进行初始化,初始化后的结构如图5-25所示。
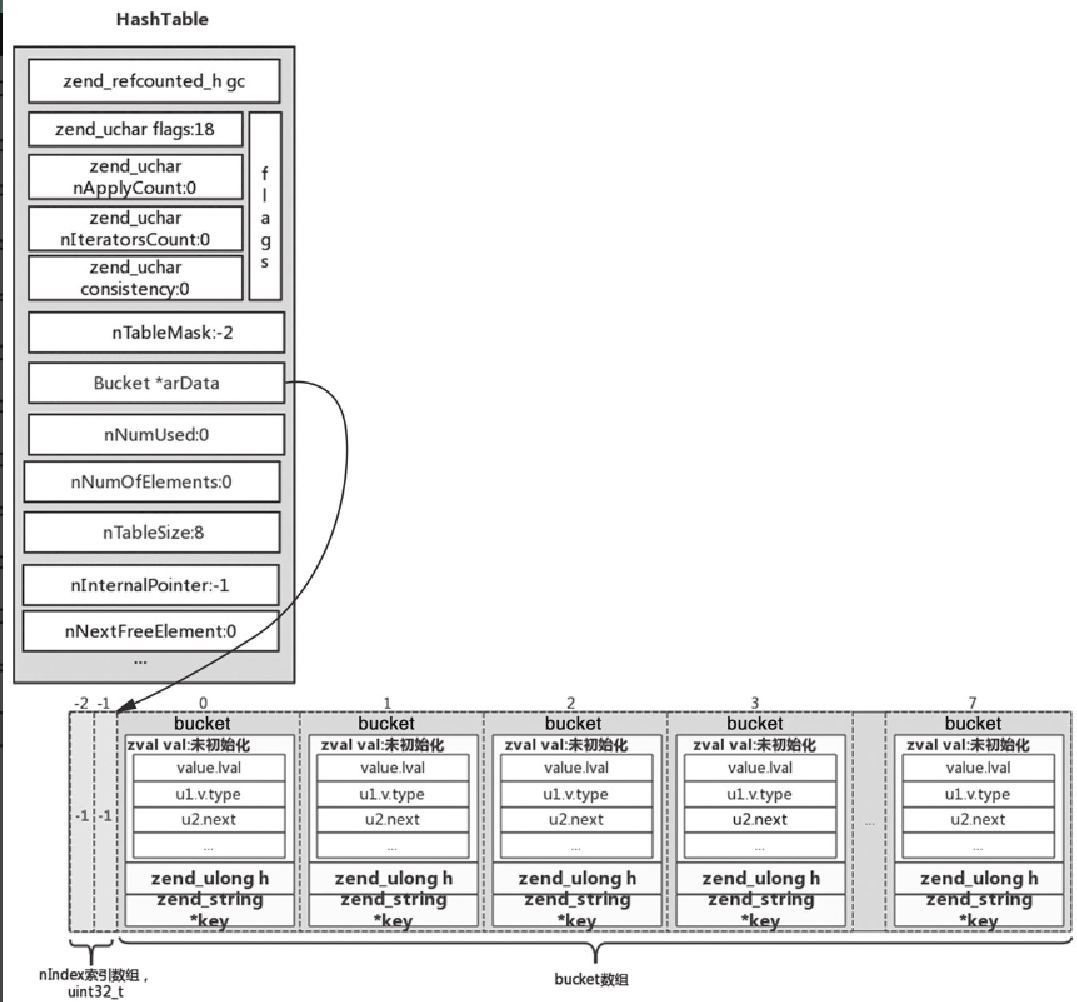
此时,因为是 packed array,所以 nTableMask 为 -2,数组的大小 nTableSize 为 8,nInternalPointer 为 -1, Bucket *arData 对应的是未初始化的 8 个 bucket。调用 _zend_hash_next_index_insert 函数将 uninitialized_zval 插入到 HashTable 中,然后将字符串 foo(zend_string 类型)拷贝到对应的 zval 中,完成以后如图5-26所示。
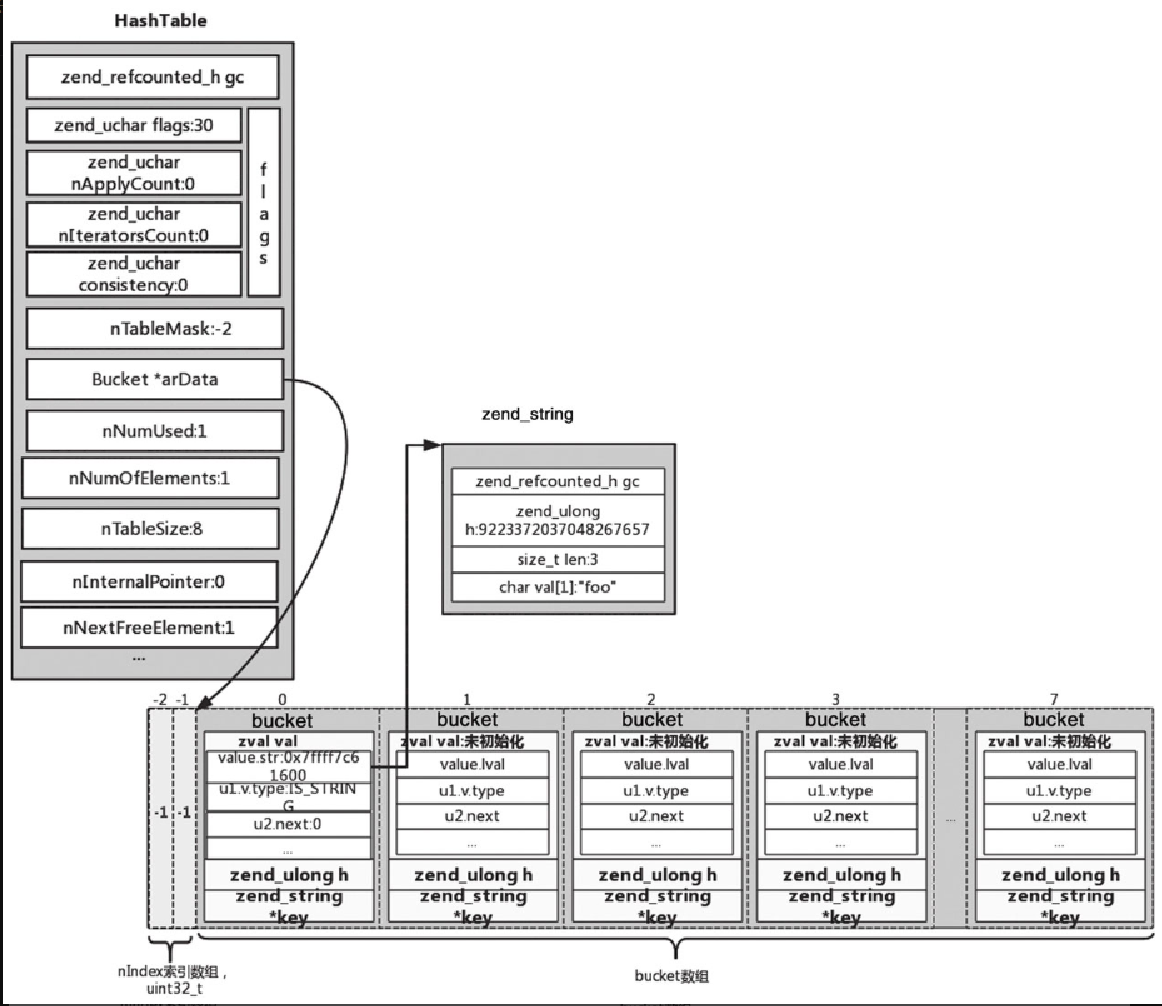
此时 (ht)→u.flags |= HASH_FLAG_INITIALIZED | HASH_FLAG_PACKED 修改为 30,nNumUsed 修改为 1, nNumOfElements 修改为 1,同时 nNextFreeElement 修改为 1,同时将 foo 对应的 zend_string 拷贝到第一个 bucket 中的 zval 中;
对于 $arr['a'] = 'bar',首先调用 zend_hash_find 根据 key='a' 查找,查找不到对应的 key,然后通过 zend_hash_add_new 把 uninitialized_zval 插入到 HashTable 中,此时因为之前是 packed array,所以需要调用 zend_hash_packed_to_hash 进行转换。
-
①
ht->u.flags &= ~HASH_FLAG_PACKED = 26,生成一个新的arData,调用memcpy拷贝过去,然后释放掉老的arData。 -
② 调用
zend_hash_rehash进行rehash操作,生成的新的HashTable,如图5-27所示。
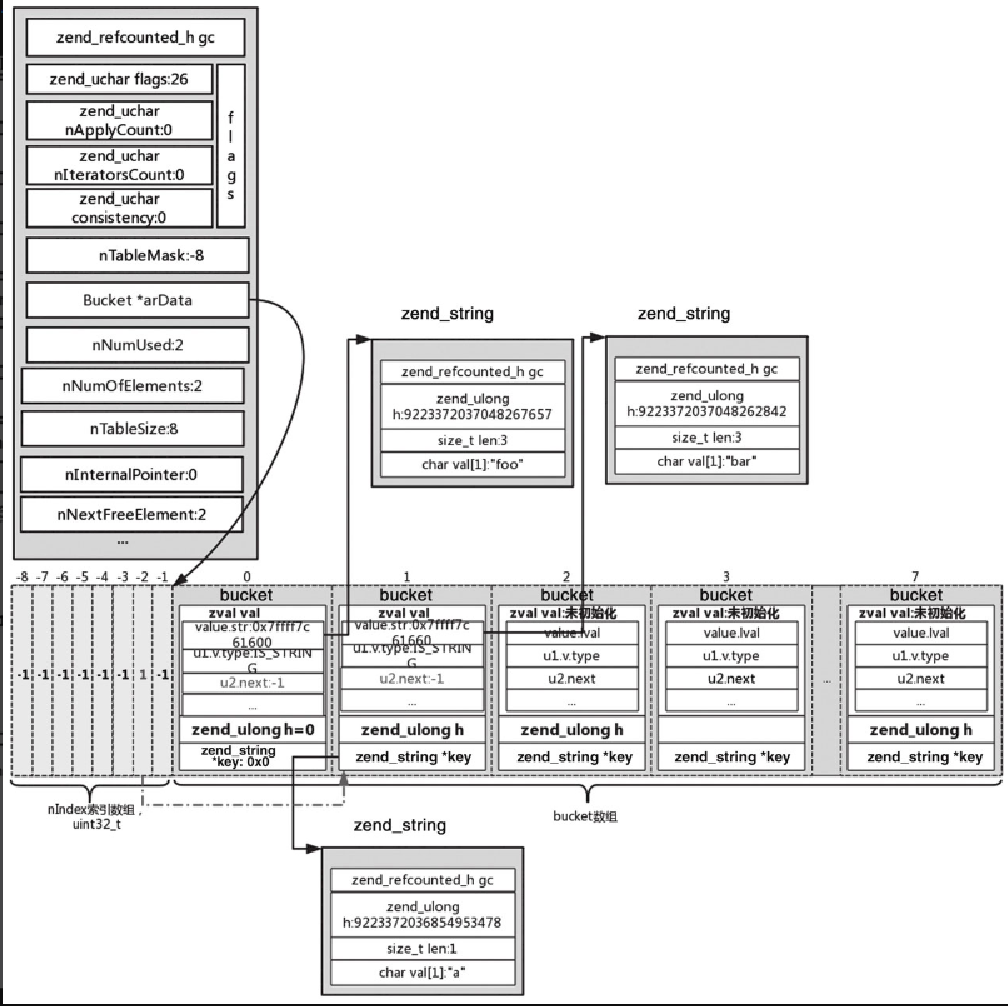
其中,对于第 1 个位置的 h 值为 9223372036854953478,与 nTableMask 按位或以后的值为 -2:
(gdb) p (int)(9223372036854953478 | 4294967288)
$1 = -2nIndex 索引部分 -2 对应的值为 1,计算方法使用:
#define HT_HASH_EX(data, idx) \
((uint32_t*)(data))[(int32_t)(idx)]对于 $arr[2] = 'abc';,首先使用 _zend_hash_index_find 函数根据 h=2 来查找,查找不到的话,调用 zend_hash_index_add_new 将其插入 HashTable 中去,插入后的结果如图5-28所示。
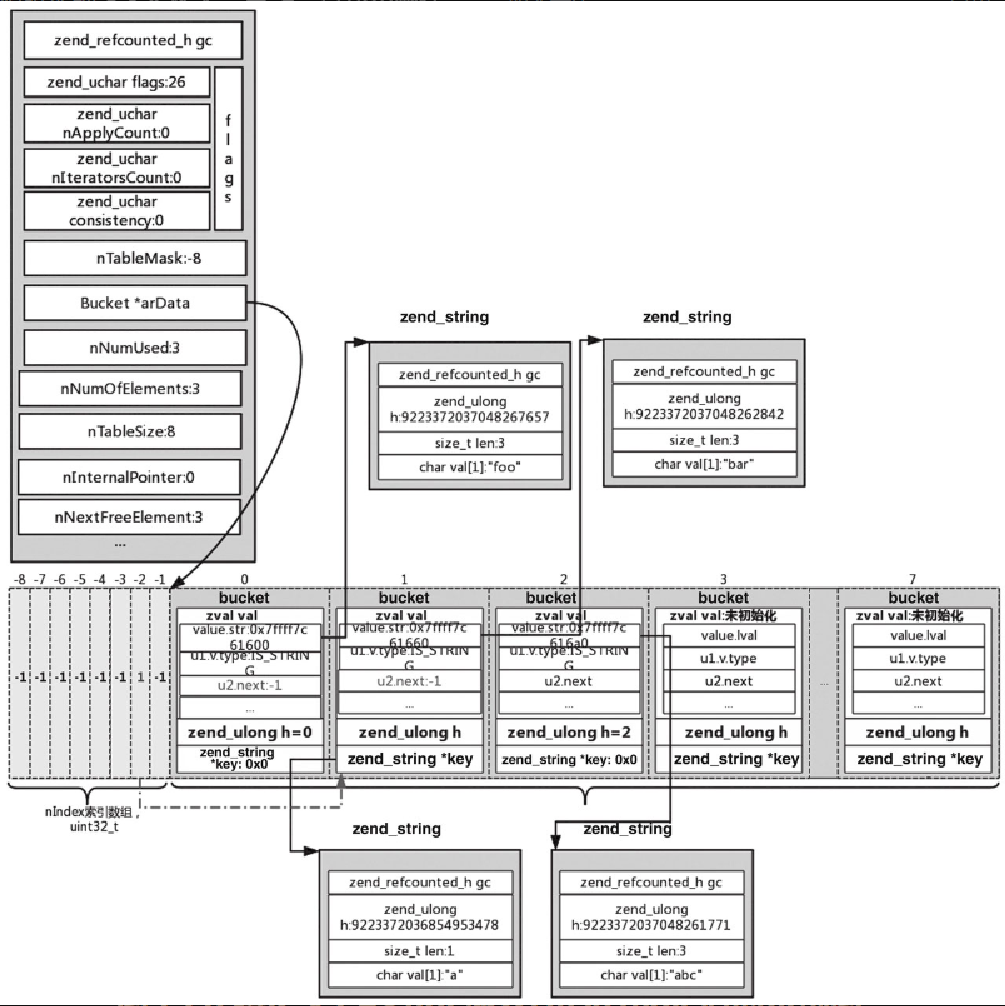
对于 $arr[] = 'xyz',调用 _zend_hash_next_index_insert;对于 h,使用的是 ht->nNext-FreeElement,此 ht->nNextFreeElement==3,同样传入 h=3 调用 zend_hash_index_find_bucket 查找,查找不到的话,进行插入,插入后的结果如图5-29所示。
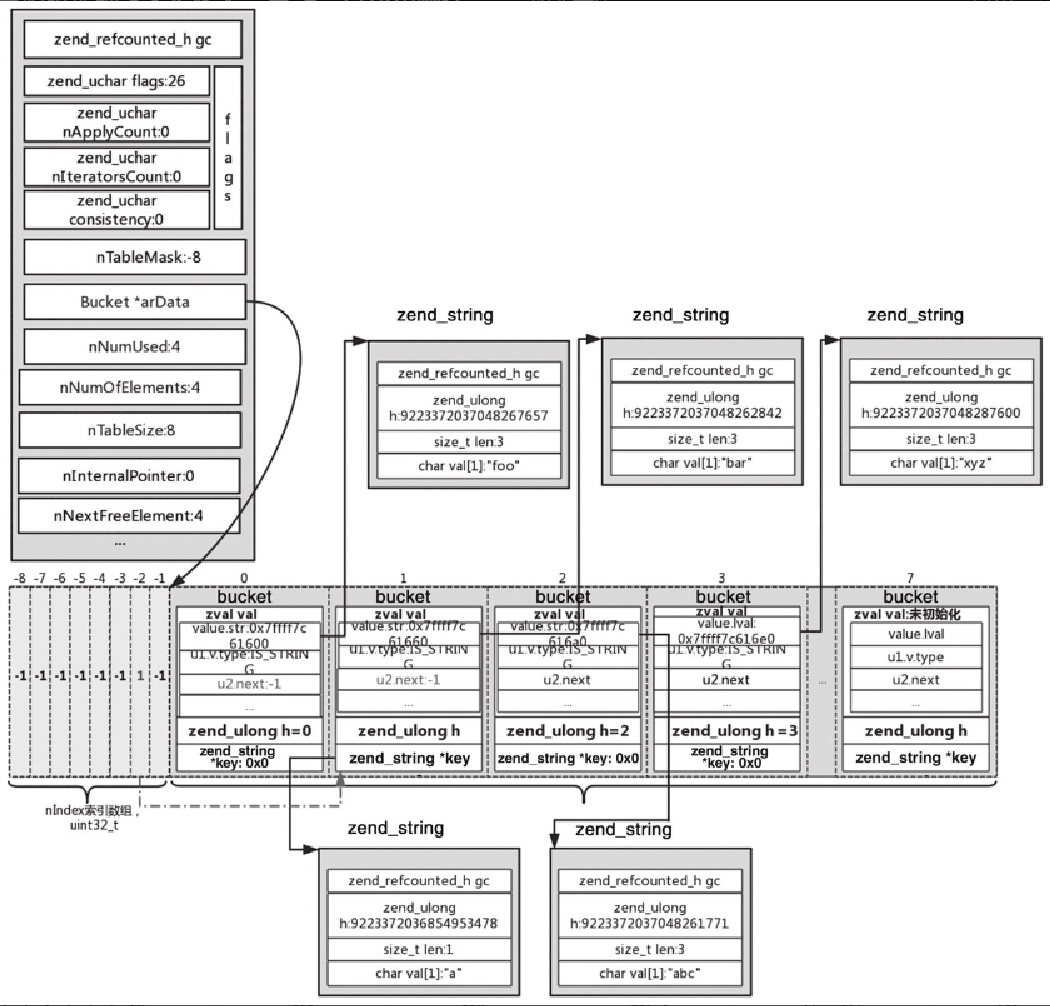
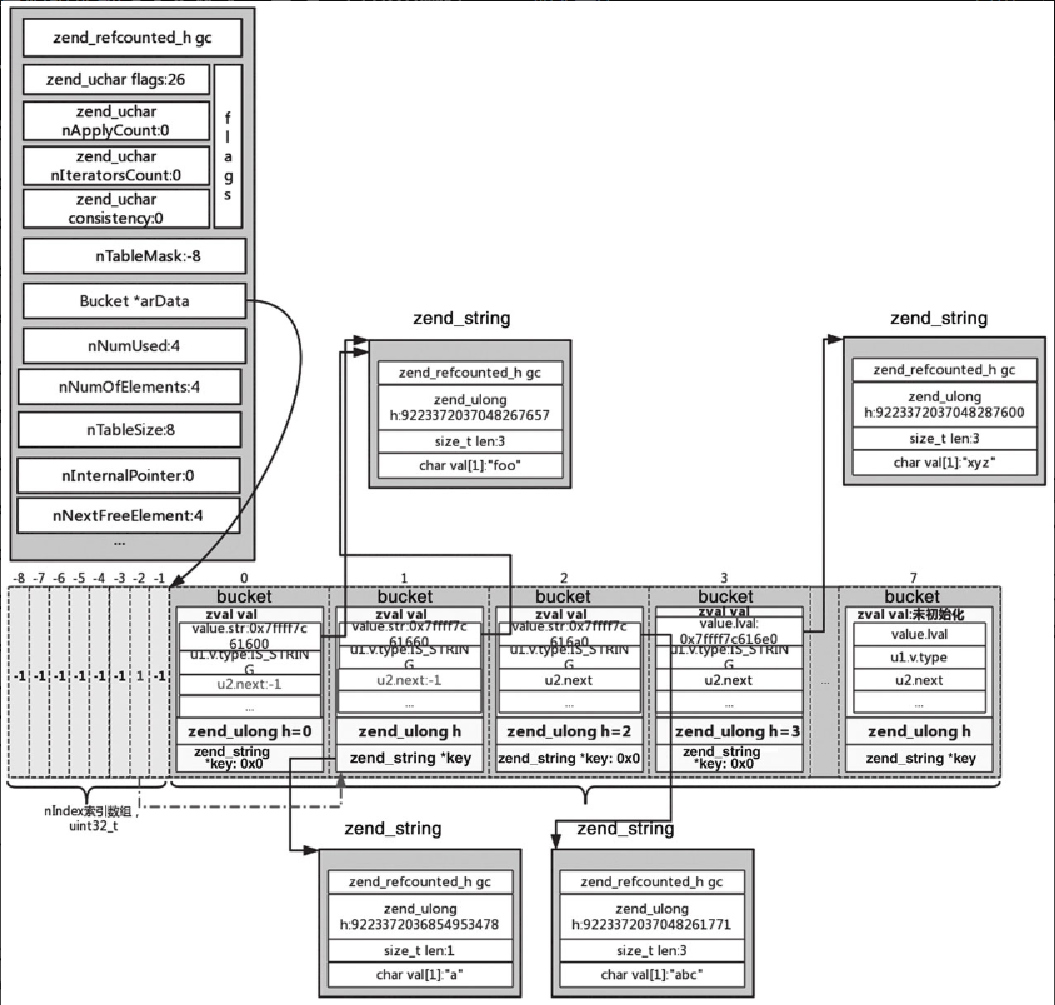
对于 $arr['a'] = 'foo',首先调用 zend_hash_find_bucket,通过 key=a 查找,通过 zend_string_hash_val 可以计算 h= 9223372036854953478,与图5-30中第 1 个 bucket 中的 key=a 的 h 值相同,然后计算出 nIndex=h|ht->nTableMask, nIndex=-2,而 -2 位置对应 1,找到 arData 的第 1 个位置,判断 key 是否等于 'a',然后将对应的值改为 'foo',并做优化,与第 0 个位置指向的 zend_string 是同一个位置,对应的内容是 'foo',如图5-30所示。
-
对于
echo $arr['a'];,与数组查找类似,暂不赘述。 -
对于
unset($arr['a']);,调用zend_hash_del进行删除,首先通过key=a调用zend_string_hash_val(key)查找到结果为第 1 个bucket。
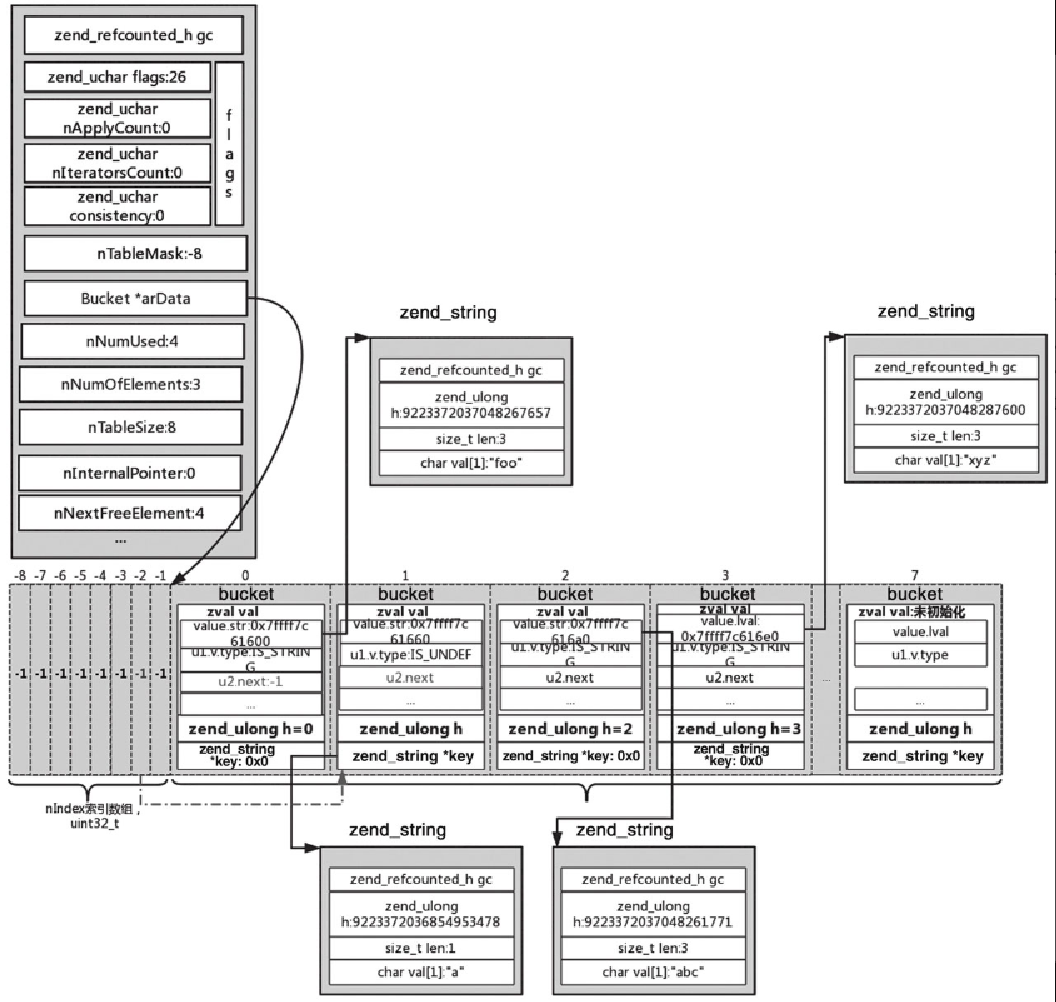
从图5-31中可以看出,arData[-2] 对应值改为 -1, arData[1] 对应的 bucket 的 u1.v.type=IS_UNDF, nNumUsed 并没有修改,还是为 4,但是 nNumOfElements 减 1,改为 3。
到此,从上面的例子中,我们完成了插入、更新、查找,以及删除的操作。
哈希冲突的解决
数据在插入 HashTable 时,不同的 key 经过哈希函数得到的值可能相同,导致插入索引数组冲突,理论上需要在索引数组外再加一个链表把所有冲突的 value 以双链表的形式关联起来,然后读取的时候去遍历这个双链表中的数据,比较对应的 key。
PHP 7 的 hash array 的做法是,不单独维护一个双链表,而是把每个冲突的 idx 存储在 bucket 的 zval.u2.next 中,插入的时候把老的 value 存储的地址(idx)放到新 value 的 next 中,再把新 value 的存储地址更新到索引数组中。
举个例子,假如第 1、2、3 个 bucket 发生哈希冲突,那么解决方法如图5-32所示。
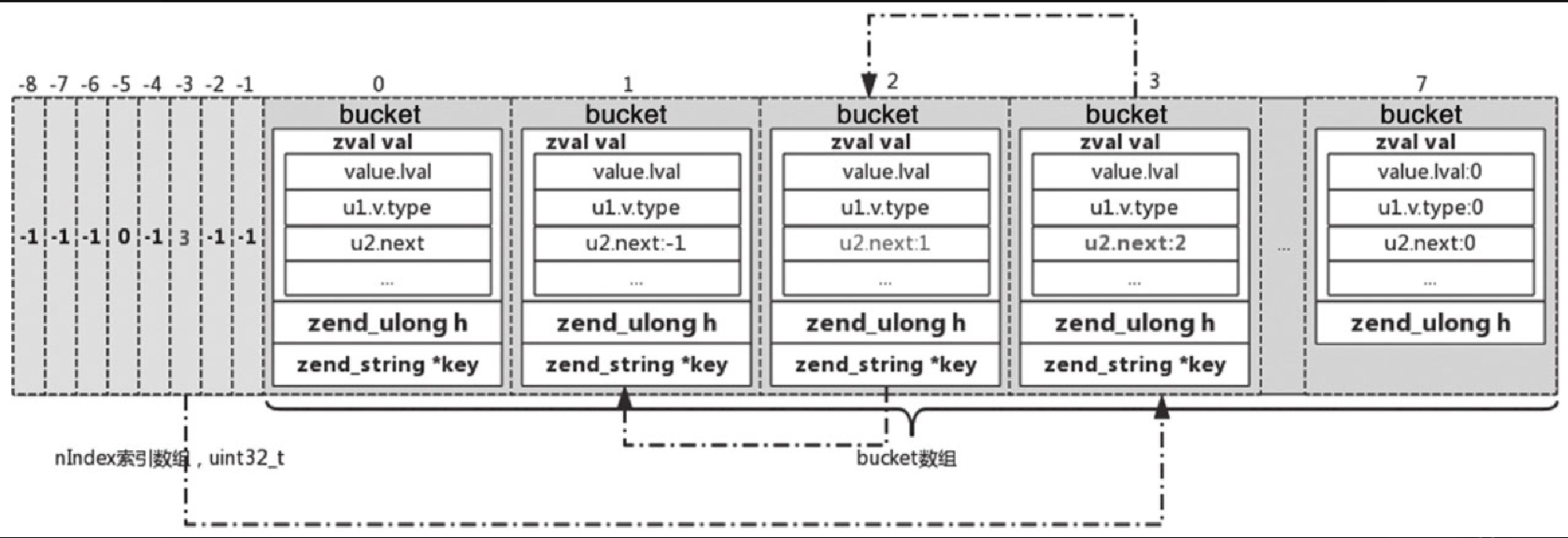
如图5-32所示,假设步骤如下。
-
插入第 1 个
bucket,对应nIndex为-3,那么此时nIndex=-3的位置值为 1。 -
若此时插入第 2 个
bucket,与第 1 个冲突,也就是对应的nIndex也为 -3,那么此时 PHP 7 是怎么做的呢?令nIndex=-3的位置值为 2,同时将第 2 个bucket中zval里面的u2.next值置为 1。这样,在查找第 1 个bucket的key对应的nIndex时,找到第 2 个bucket,校验key值不同,会取u2.next对应的 1,取第 1 个bucket中的内容,与key校验,一致,则返回。 -
若此时插入第 3 个
bucket,与第 1 个和第 2 个冲突,那么用同样的方式,令nIndex=-3的位置值为 3,同时将第 3 个bucket中zval里面的u2.next值置为 2。
通过 1~3 步,其实维护了一个隐形的链表,并用 头插法 插入新值。这样就实现了用链地址法解决哈希冲突。
扩容和rehash操作
前文已经说到,hash array 在重置一个 key 时并不会真正触发删除操作,只做一个标识,删除是在扩容和重建索引时触发,本节将讲解什么时候触发扩容及重建索引,何时把已删除的数据清除掉。下面了解一下扩容和 rehash 的实现。
插入时触发扩容及 rehash 的整体流程如图5-33所示。
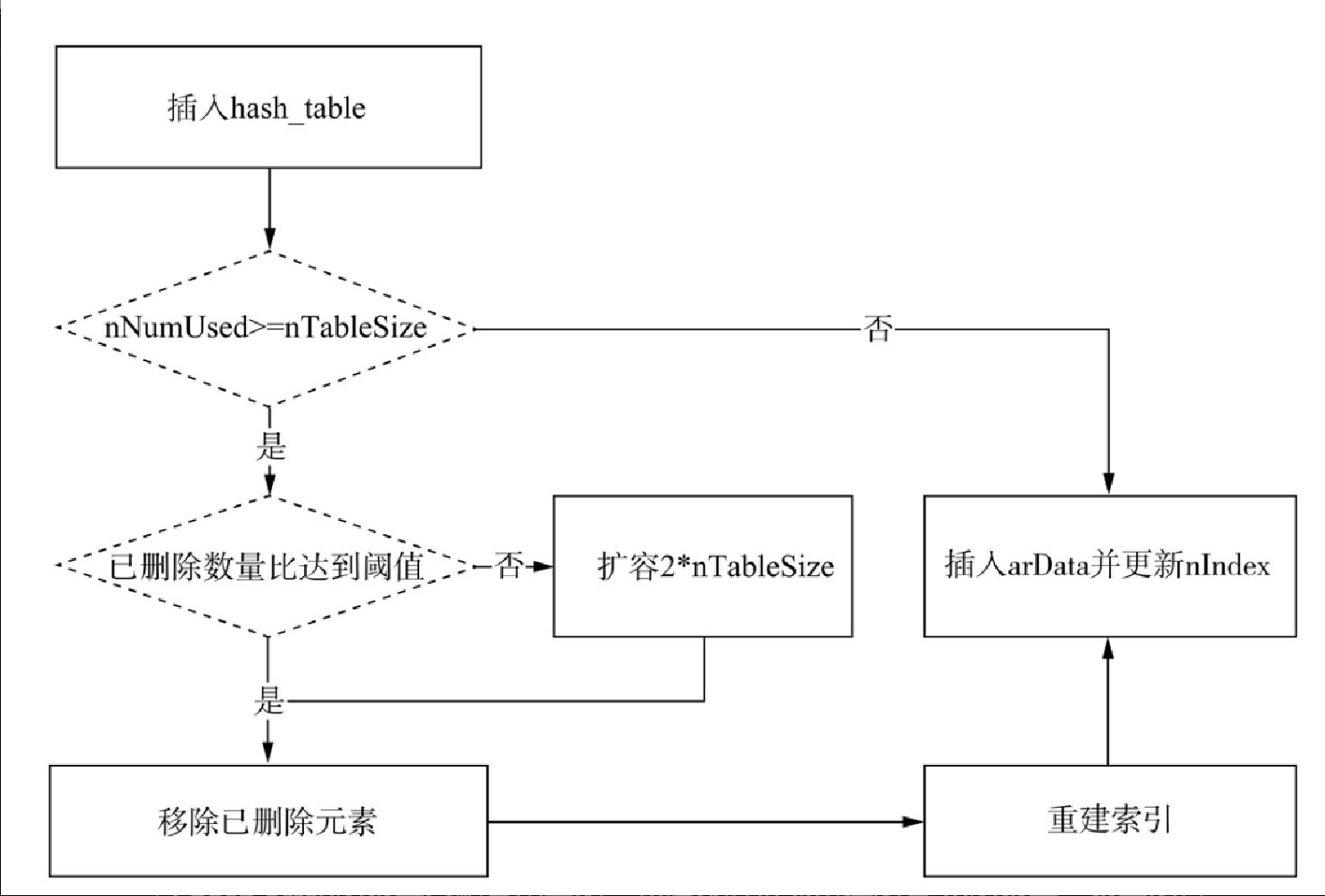
说明:
-
hash array的容量分配是固定的,初始化时每次申请的是2n的容量,容量的最小值为23,最大值为0x80000000。 -
当容量足够时直接执行插入操作。
-
当容量不够时(
nNumUsed >=nTableSize),检查已删除元素所占的比例,假如达到阈值(ht->nNumUsed - ht->nNumOfElements > (ht->nNumOfElements >> 5),则将已删除元素从HashTable中移除,并重建索引。如果未到阈值,则要进行扩容操作(见图 5-34),新的容量扩大到当前大小的2倍(即2*nTableSize),将当前bucket数组复制到新的空间,然后重建索引。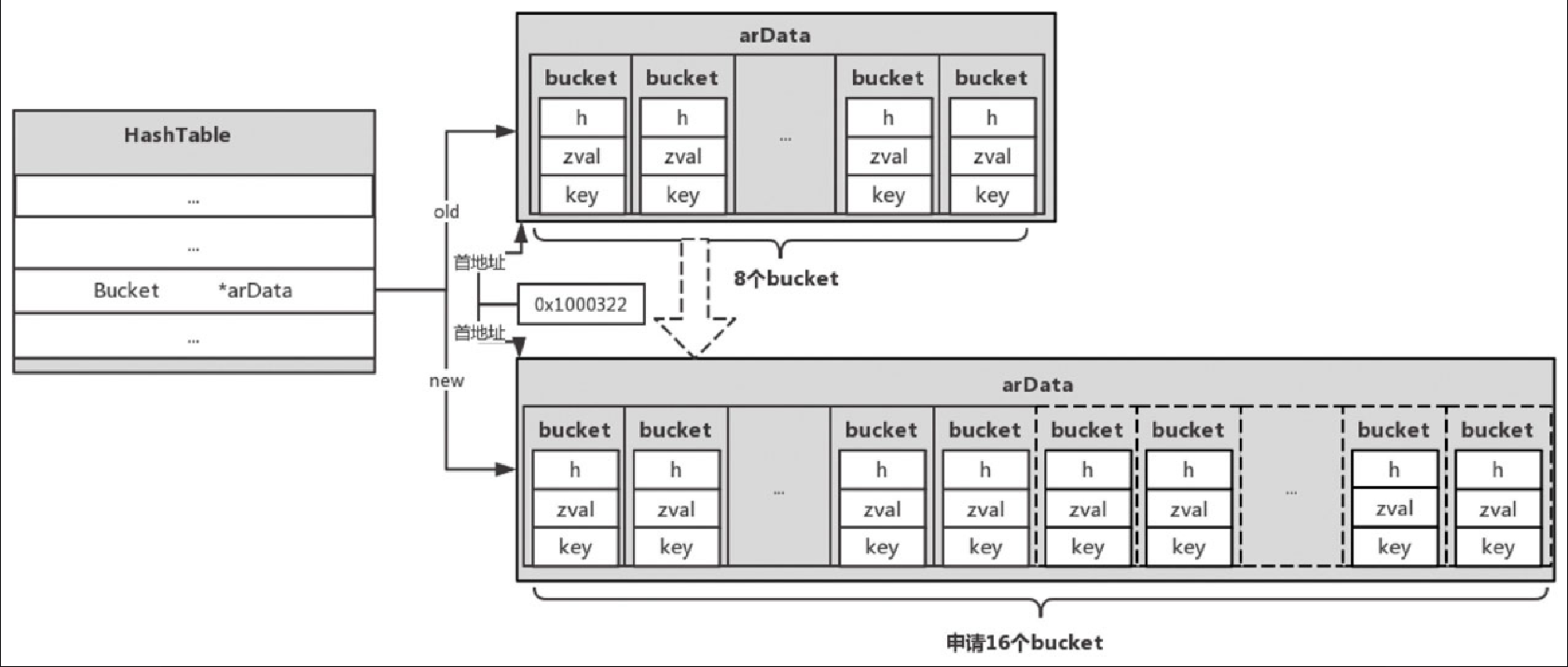 Figure 30. 图5-34 rehash示例图
Figure 30. 图5-34 rehash示例图 -
重建完索引后,有足够的空余空间后再执行插入操作。
重建索引的过程如图 5-35 所示。
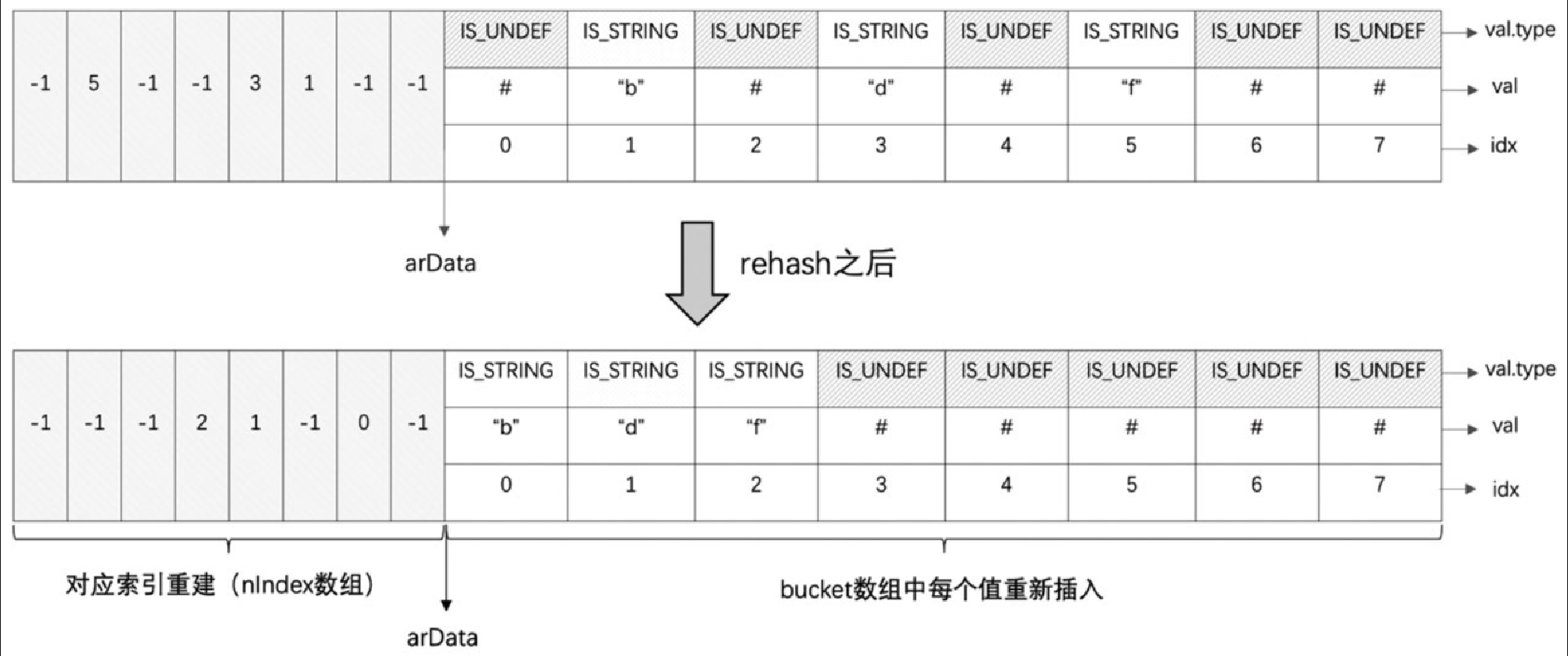
说明:
-
rehash对应源码中的zend_hash_rehash(ht)方法。 -
rehash的主要功能就是把HashTable bucket数组中标识为IS_UNDEF的数据剔除,把有效数据重新聚合到bucket数组并更新插入索引表。 -
rehash不重新申请存内存,整个过程是在原有结构上做聚合调整。
具体实现步骤:
-
重置所有
nIndex数组为-1; -
初始化两个
bucket类型的指针p、q,循环遍历bucket数组; -
每次循环,
p++,遇到第一个IS_UNDEF时,q=p;继续循环数组; -
当再一次遇到一个正常数据时,把正常数据拷贝到
q指向的位置,q++; -
直到遍历完数组,更新
nNumUsed等计数。
数组的递归保护
递归保护就是 PHP 7 在对 HashTable 进行递归操作时,防止引用次数太多而采取的一种保护机制。通过前面了解 HashTable 的基本结构,知道了 u.flags 是一个联合体,并且第 2 位 nApplyCount 用于记录该 HashTable 递归的次数。在需要采用递归保护时,HashTable 会带有 HASH_FLAG_APPLY_PROTECTION 标记,然后会先将 nApplyCount 位加 1,并在处理完成后将该标志减 1,代码如下:
$a = [1,2,3];
$a[] = &$a;对于数组 $a,会通过对 u.v.nApplyCount 进行加 1 判断,如果大于 1,判断代码为:
myht = Z_ARRVAL_P(struc);
if (level > 1 && ZEND_HASH_APPLY_PROTECTION(myht) && ++myht->u.v.nApplyCount > 1)
{
PUTS("*RECURSION*\n");
--myht->u.v.nApplyCount;
return;
}从代码中可以看到,对于 $a,在循环调用时,nApplyCount 会加 1。一旦存在递归,则 nApplyCount 会大于 1,这样就很容易判断递归的存在。