PHP 7词法与语法分析
了解了 PHP 7 的 Token 和相关的数据结构,下面分析一下 PHP 7 词法和语法分析得到 AST 的具体过程。
整体过程
PHP 7 词法和语法分析的入口函数在 zend_language_scanner.c 的 zend_compile 中,具体步骤如下。
-
申请 1024×32 字节大小的空间,赋值给
compiler_globals的ast_arena,用以存放AST。 -
调用
zendparse(yyparse)进行词法与语法分析,生成AST。 -
将
AST赋值给CG(ast)。
词法与语法分析阶段
该阶段的入口函数为 zendparse,使用 Re2c 生成的词法分析文件和 Bison 生成的语法分析文件。PHP 7 源码中编写了 zend_language_scanner.l 文件,这个是符合 Re2c 规范的,根据 10.2.2 节介绍的 Re2c,对照 PHP 7 的 MakeFile,我们可以看到使用 Re2c 编译这个文件的语句:
@(cd $(top_srcdir); $(RE2C) $(RE2C_FLAGS) --no-generation-date --case-inverted
-cbdFt Zend/zend_language_scanner_defs.h -oZend/zend_language_scanner.c Zend/
zend_language_scanner.l)读者可以执行下面的命令,体会一下生成 zend_language_scanner.c 的过程:
re2c --no-generation-date --case-inverted -cbdFt Zend/zend_language_scanner_defs.
h -otest/zend_language_scanner.c Zend/zend_language_scanner.lzend_language_scanner.l 文件中的正则表达式如下:
/*! re2c
re2c:yyfill:check = 0;
LNUM [0-9]+
DNUM ([0-9]*"."[0-9]+)|([0-9]+"."[0-9]*)
EXPONENT_DNUM (({LNUM}|{DNUM})[eE][+-]? {LNUM})
HNUM "0x"[0-9a-fA-F]+
BNUM "0b"[01]+
LABEL [a-zA-Z_\x80-\xff][a-zA-Z0-9_\x80-\xff]*
WHITESPACE [ \n\r\t]+
TABS_AND_SPACES [ \t]*
TOKENS [; :, .\[\]()|^&+-/*=%! ~$<>? @]
ANY_CHAR [^]
NEWLINE ("\r"|"\n"|"\r\n")通过对 10.2.2 节的学习,我们知道 Re2c 会将其转换为有穷状态机,我们以 PHP 的入口 Tag(<? php) 为例,看一下判断的过程。状态机起始位置为 yyc_INITIAL,对应的入口 Tag 有 “<? =”、“<? php” 和 “<? ”, .l 文件中对应的代码如下:
<INITIAL>"<? =" {
BEGIN(ST_IN_SCRIPTING);
RETURN_TOKEN(T_OPEN_TAG_WITH_ECHO);
}
<INITIAL>"<? php"([ \t]|{NEWLINE}) {
HANDLE_NEWLINE(yytext[yyleng-1]);
BEGIN(ST_IN_SCRIPTING);
RETURN_TOKEN(T_OPEN_TAG);
}
<INITIAL>"<? " {
if (CG(short_tags)) {
BEGIN(ST_IN_SCRIPTING);
RETURN_TOKEN(T_OPEN_TAG);
} else {
goto inline_char_handler;
}
}生成的 .c 文件中,状态对应 yyc_INITIAL:
yyc_INITIAL:
YYDEBUG(0, *YYCURSOR);
YYFILL(7);
yych = *YYCURSOR;
if (yych ! = '<') goto yy4;
YYDEBUG(2, *YYCURSOR);
++YYCURSOR;
if ((yych = *YYCURSOR) == '? ') goto yy5;
//代码省略//-
从起始状态开始,到状态
0,如果不是“<”,则跳到状态yy4,最终到状态,yy3,RETURN_TOKEN(END); -
对于状态
0,如果是“<? ”,则跳转到状态yy5; -
对于状态
yy5,如果是“=”,则跳到状态yy7,RETURN_TOKEN(T_OPEN_TAG_WITH_ECHO); -
对于状态
yy5,如果是“p”或者“P”,则跳到状态yy9,并最终跳到状态yy6,RETURN_TOKEN(T_OPEN_TAG)。
该部分对应的状态机转换图如图10-12所示。
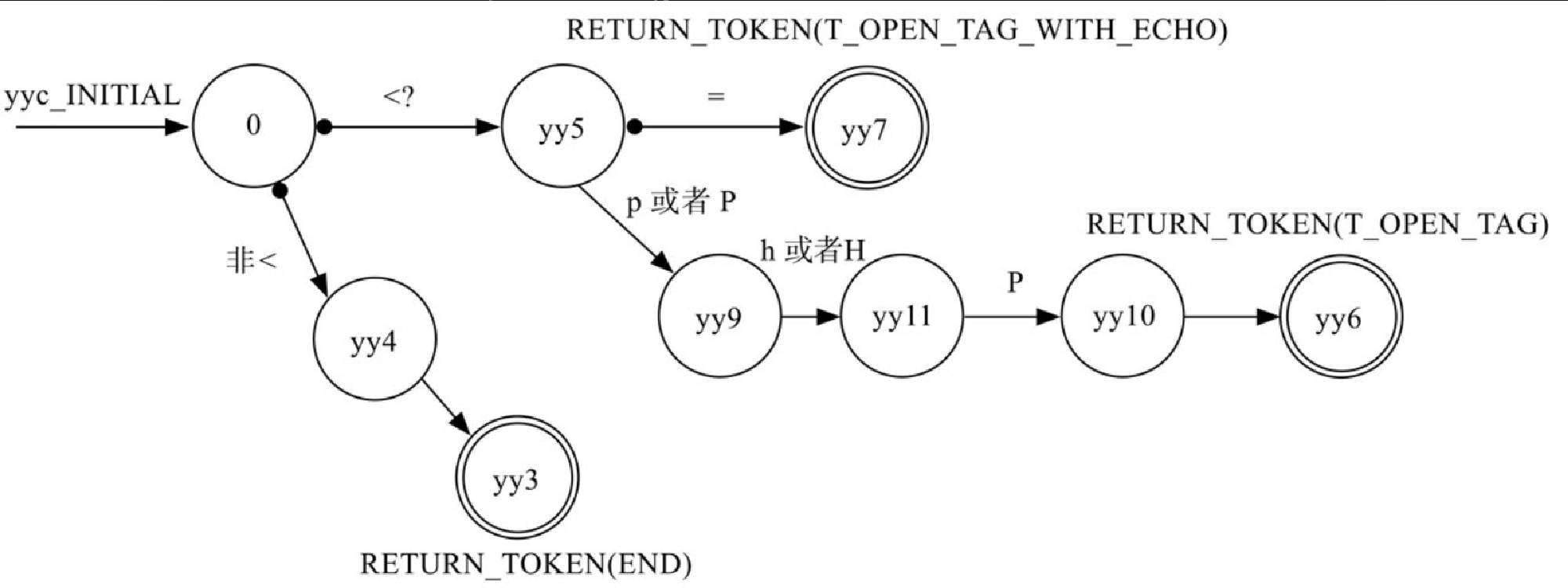
图10-12展示了对 PHP 代码入口 “<? =” 和 “<? php” 的识别过程。通过这个过程,相信大家很容易理解词法分析做了什么工作。接下来详细阐述一下语法分析工作。
准备工作
PHP 7 的语法分析使用 Bison 对 zend_language_parser.y 进行编辑,生成了 zend_language.parse.c 文件。整个词法和语法分析的入口为 Zend/zend_language_parser.c 的 zendparse 函数,下面我们以一段简单的 PHP 代码为例来分析一下整个词法和语法分析的过程。PHP 代码如下:
<?php
$a = 1;代码非常简单,我们可以在 zendparse 函数打个断点,然后运行这段代码:
(gdb) b zendparse在 zendparse 中,首先初始化一个 200 大小的栈 yyvsa 和一个 200 大小的状态数组 yyssa,并初始化指针 yyvs 和 yyvsp 指向 yyvsa 的第 0 个位置,yyval 指向 yyvsa 的 -2 位置,同样初始化指针 yyss 和 yyssp 指向 yyssa 的第 0 个位置,如图10-13所示。
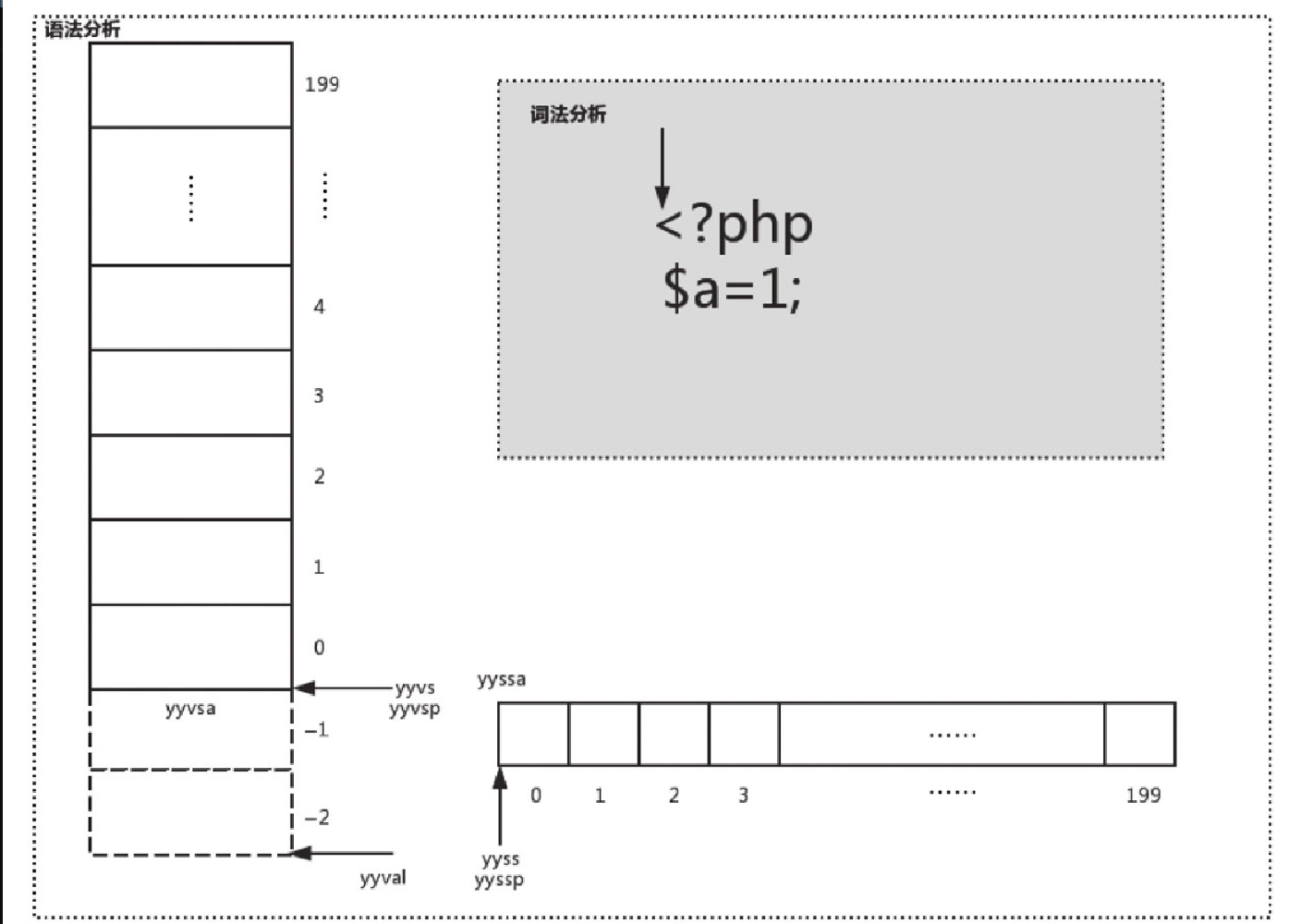
初始状态
在初始状态,语法分析会在 yyvsa 的第 1 个位置创建一个 kind 为 ZEND_AST_STMT_LIST 的 AST,代码如下:
{ (yyval.ast) = zend_ast_create_list(0, ZEND_AST_STMT_LIST); }生成 AST 后的结构如图10-14所示。
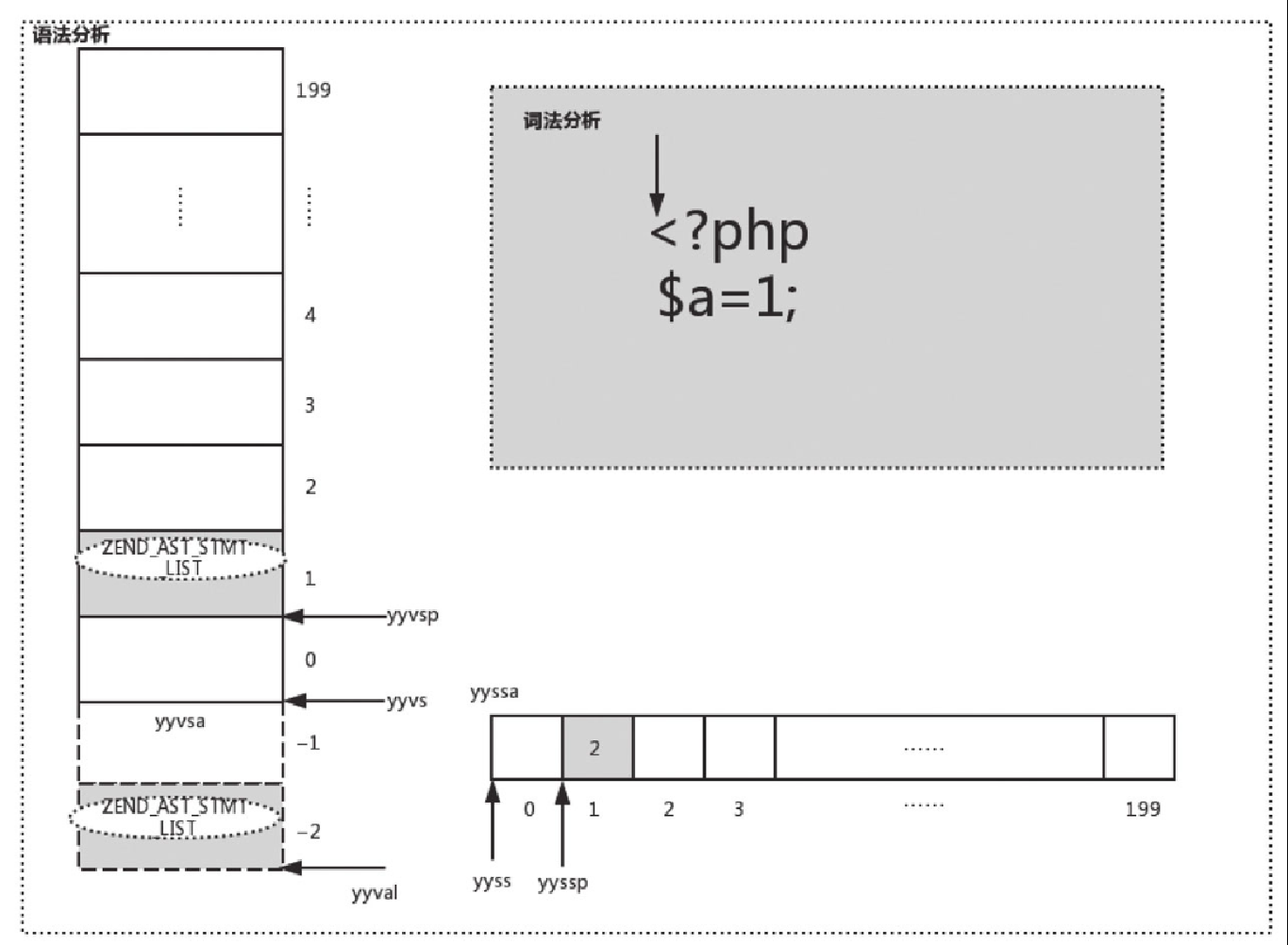
从图10-14可以看出,初始状态会生成一个 kind 为 ZEND_AST_STMT_LIST 的 AST,并把其地址赋值给 yyvsa[1] 以及 yyval。其中,yyval 为 yyvsa[-2];同时 yyparse 将 yyssa[1] 置为 2,用来判断栈的步长。
|
|
kind 为 ZEND_AST_STMT_LIST 是整棵抽象语法树的根节点,下面的过程会基于这个根节点扩展整棵抽象语法树。
分析过程
接下来进入词法分析过程,根据获取 “<? php” 的状态转换图,词法分析首先找到的是 “<? php” 对应的 Token 为 T_OPEN_TAG,对于返回的 Token 处理代码如下:
int zendlex(zend_parser_stack_elem *elem) /* {{{ */
{
zval zv; //声明一个zval,用来存储PHP代码中的变量和常量
int retval; //返回的Token值
//…省略代码…//
again:
ZVAL_UNDEF(&zv); //将zv置为IS_UNDEF
retval = lex_scan(&zv); //进行词法分析
if (EG(exception)) {//异常
return T_ERROR;
}
switch (retval) {
case T_COMMENT: // 注释,比如//或者#
case T_DOC_COMMENT: //注释,比如/* */或者 /** */
case T_OPEN_TAG:// "<? php"
case T_WHITESPACE: //空格
goto again; //继续进行词法分析
//…省略代码…//
}
if (Z_TYPE(zv) ! = IS_UNDEF) {
elem->ast = zend_ast_create_zval(&zv); //如果是非IS_UNDEF的zval,生成zend_ast_zval
}
return retval;
}对于 T_OPEN_TAG,会跳转到 again 继续进行词法分析,分析出 “$a”,生成 zend_string,赋值给 zv 的 value.str, zv 的 u1.v.type 设置为 IS_STRING,并通过 zend_ast_create_zval 转换为 zend_ast,具体示意图如图 10-15 所示。这样就生成了 $a 对应的 AST 节点,其中 kind 为 ZEND_AST_ZVAL,类型为 zend_ast_zval,其 zval 存的就是 “a”。“$a” 对应的 AST 会插入到 yyvsa[2],同时 yyssa[2] 置为 35,如图10-16所示。
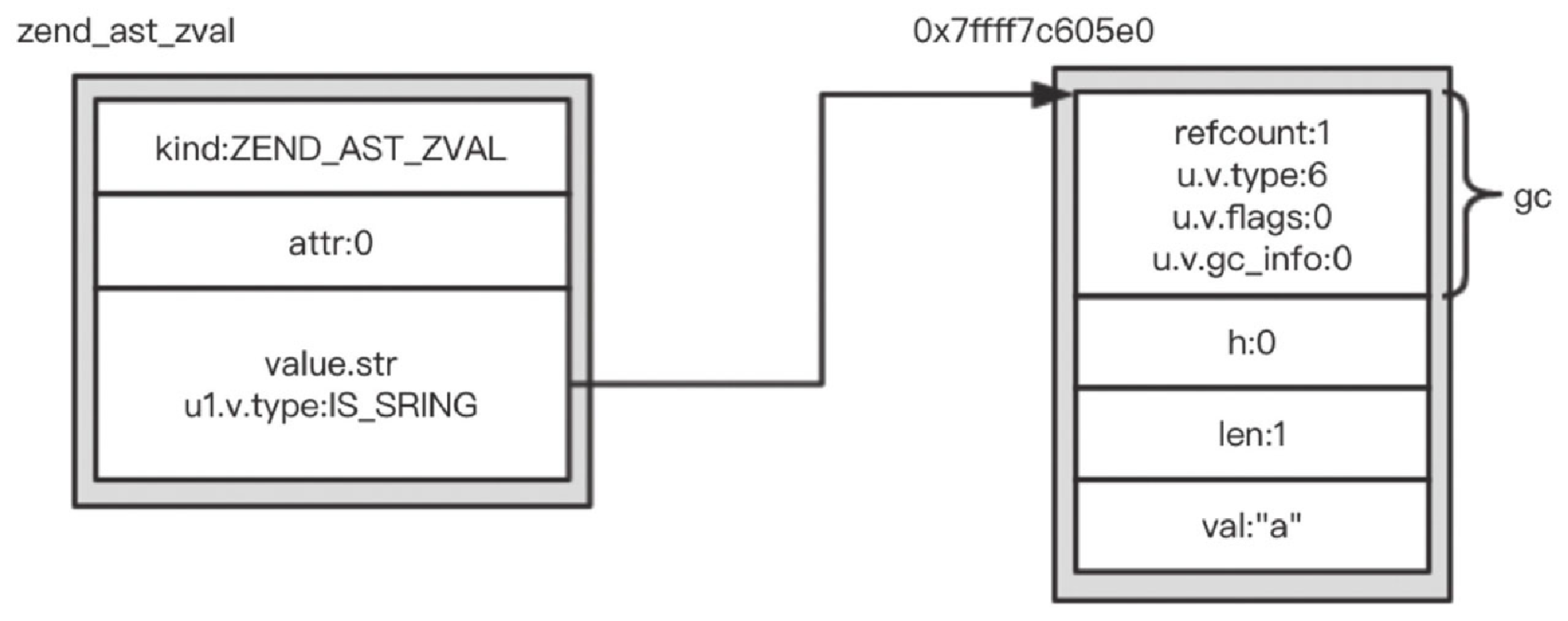
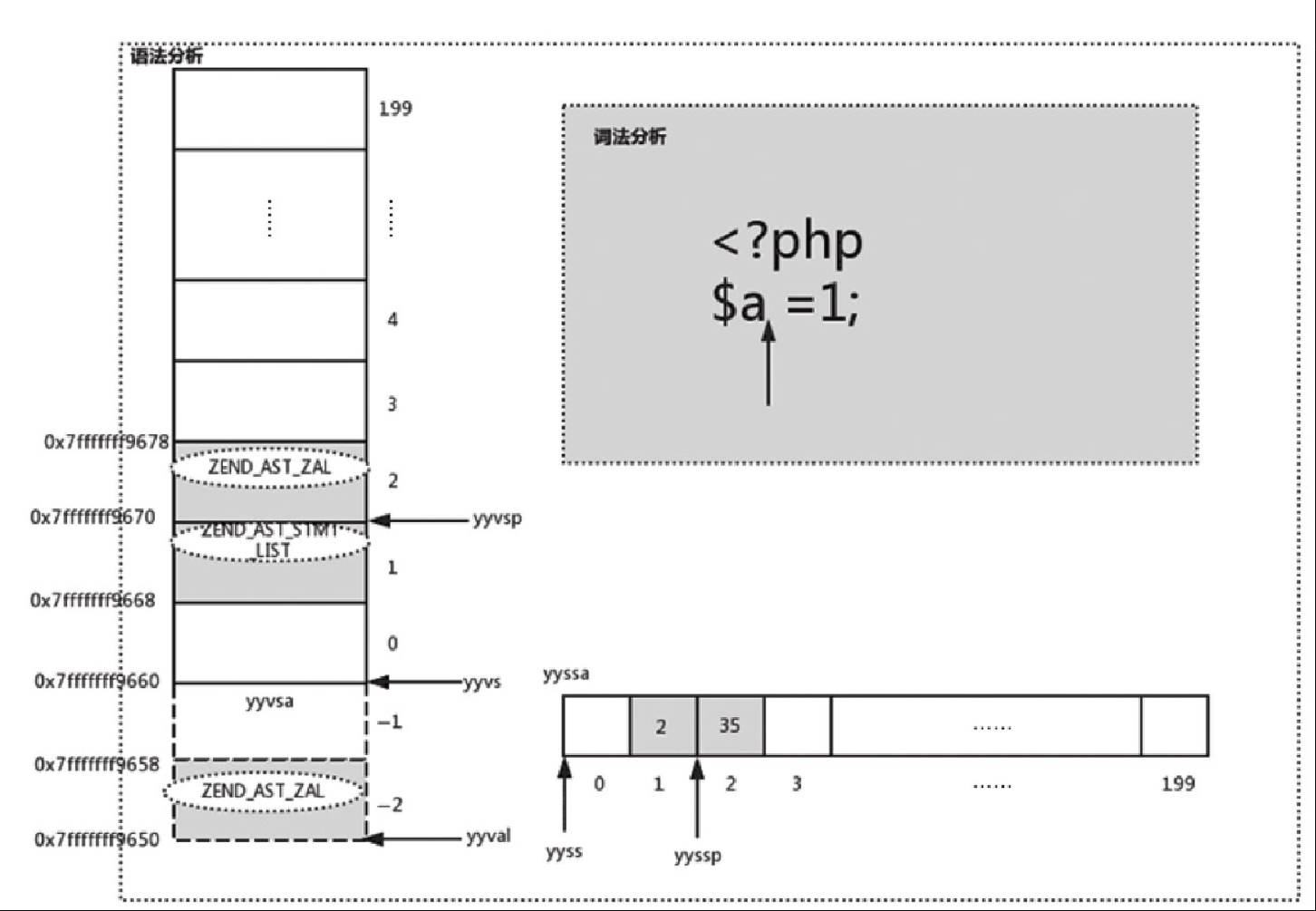
对于图 10-16 中的变量 $a,根据 Bison 生成的 yydefact 和对应的状态 yystate,会生成 kind 为 ZEND_AST_VAR 的节点,代码如下:
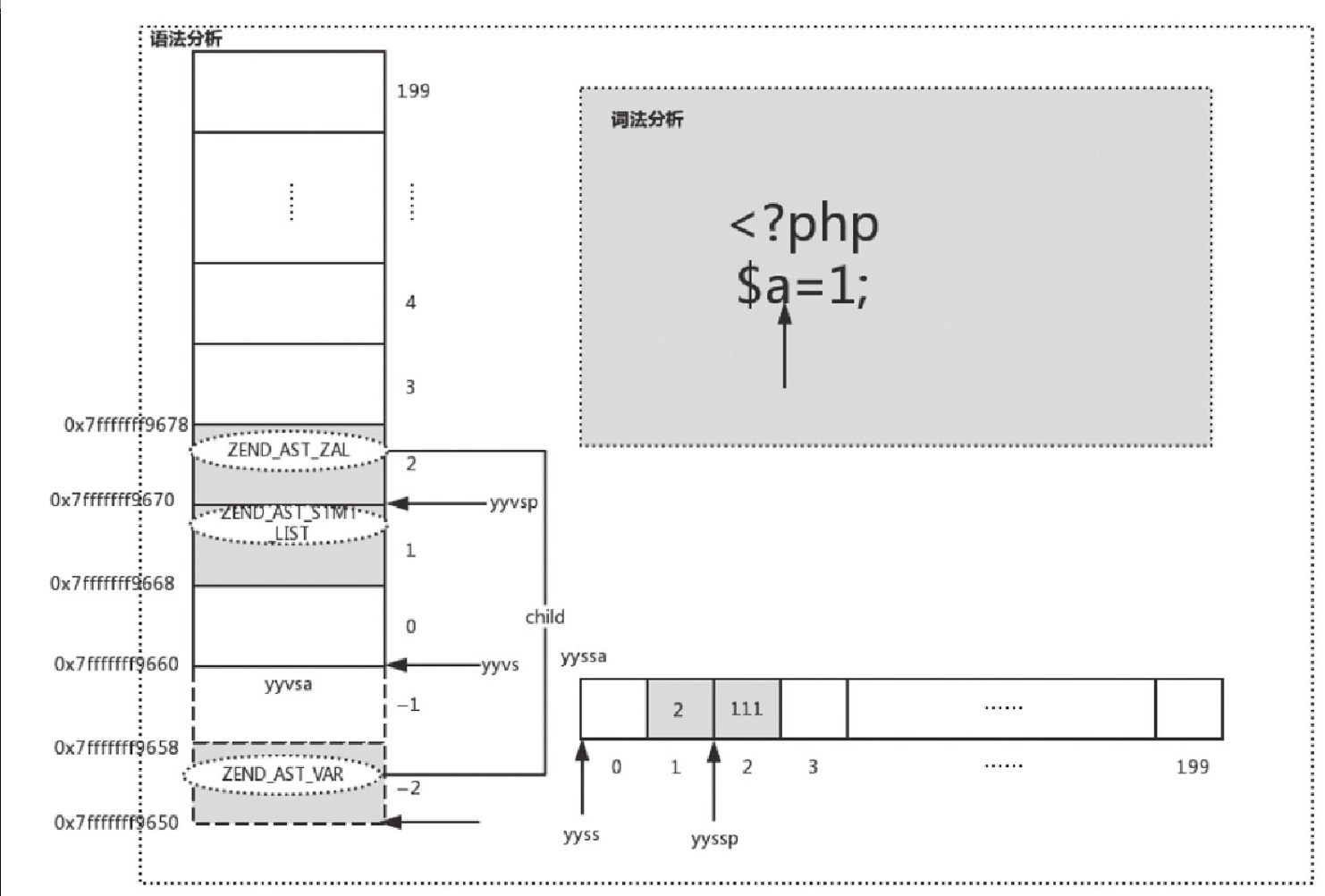
{ (yyval.ast) = zend_ast_create(ZEND_AST_VAR, (yyvsp[0].ast)); }这个节点的 child 为 “a”,对应的 kind 为 ZEND_AST_ZVAL,然后将这个节点存到 yyval 中,同时修改 yyssa[2] 为 101,如图10-17所示。
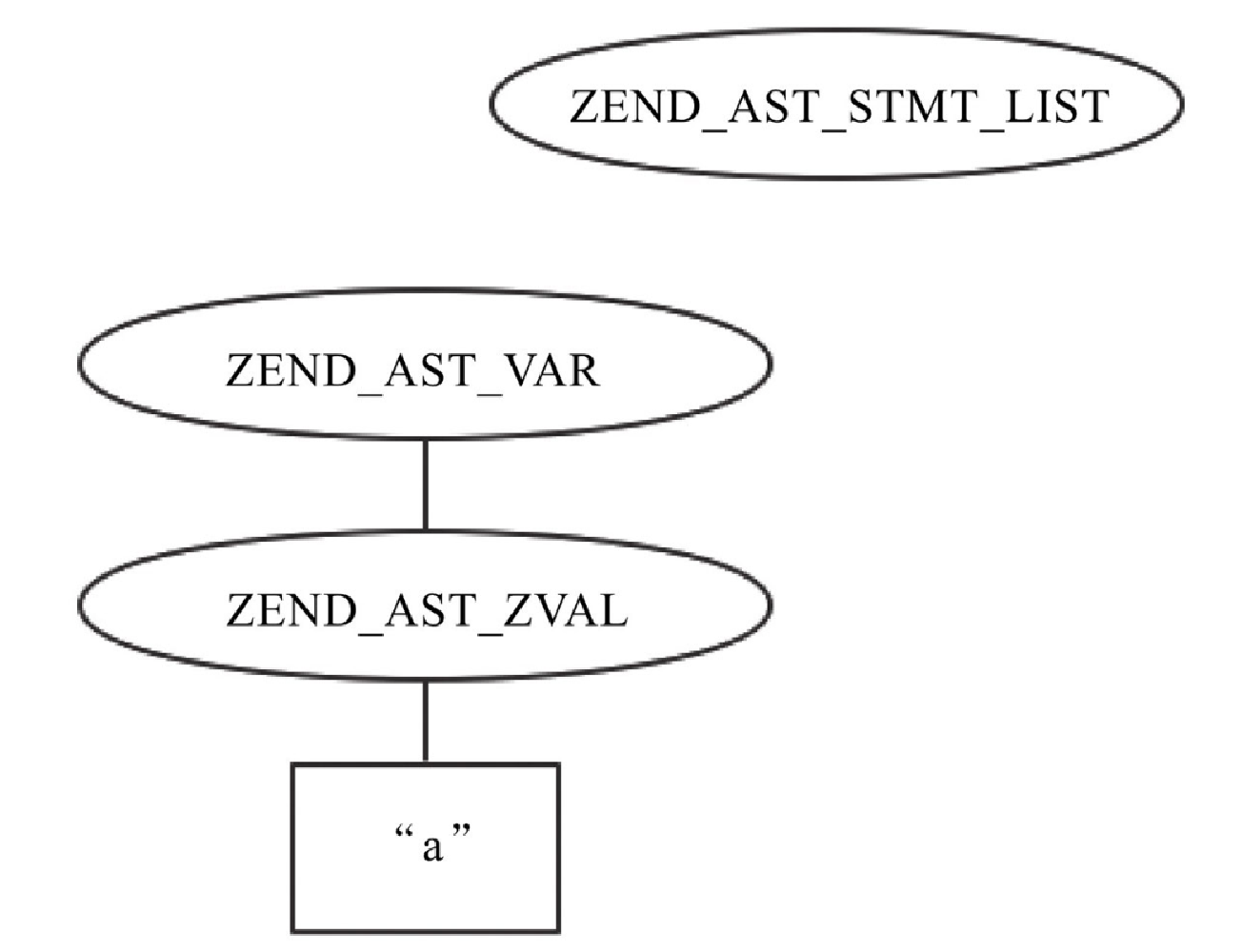
从图10-7可以看出,在 -2 位置上生成的 AST, kind 为 ZEND_AST_VAR,其 child 为之前 “a” 对应的 ZEND_AST_ZVAL,然后将 -2 位置的 AST 赋值给第 2 个位置,此时生成的 AST 如图10-18所示。
将 ZEND_AST_VAR 这棵 AST 存到 yyvsa[2] 中,如图10-19所示。
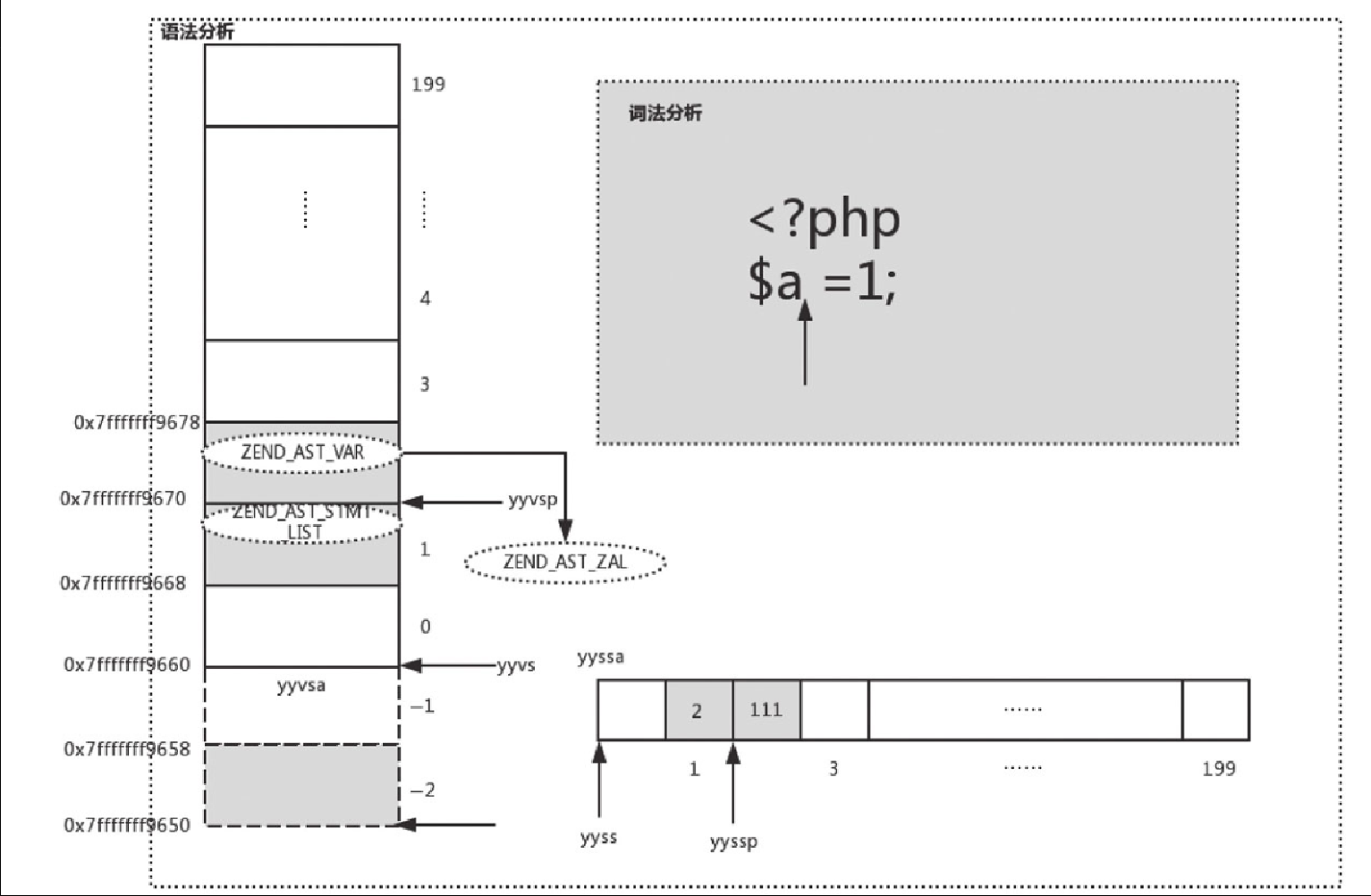
继续解析到 “$a” 和 “=” 之间的空格,词法解析会分析到这个空格,返回的 Token 为 T_WHITESPACE。
|
词法和语法分析会对空格、注释等内容进行分析,会浪费一定的时间,但可以忽略不计,另外因为有 opcache 等内部扩展,这部分词法和语法分析工作不会每次都进行。 |
跟 T_OPEN_TAG 类似,对于 T_WHITESPACE,会跳转到 again 继续进行词法分析。分析到 “=”,此时的 zendlex 中的 zv 对应的类型是 IS_UNDEF,只会修改 yyssa 中的值;继续分析到常量 “1”,同样返回 zend_ast_zval, Token 为 T_LNUMBER,生成的 zend_ast_zval 中的 zval 对应的是常量 1,通过 gdb 查看一下:
(gdb) p ((zend_ast_zval*)yyvsa[4].ast).val
$20 = {value = {lval = 1, dval = 4.9406564584124654e-324, counted = 0x1, str = 0x1,
arr = 0x1,
obj = 0x1, res = 0x1, ref = 0x1, ast = 0x1, zv = 0x1, ptr = 0x1, ce = 0x1,
func = 0x1, ww = {
w1 = 1, w2 = 0}}, u1 = {v = {type = 4 '\004', type_flags = 0 '\000', const_flags =
0 '\000',
reserved = 0 '\000'}, type_info = 4}, u2 = {next = 2, cache_slot = 2, lineno
= 2, num_args = 2,
fe_pos = 2, fe_iter_idx = 2, access_flags = 2, property_guard = 2}}可以看出,常量 1 对应的 zend_ast_zval 的 kind 为 ZEND_AST_ZVAL,值存于 val 中,如图10-20所示。
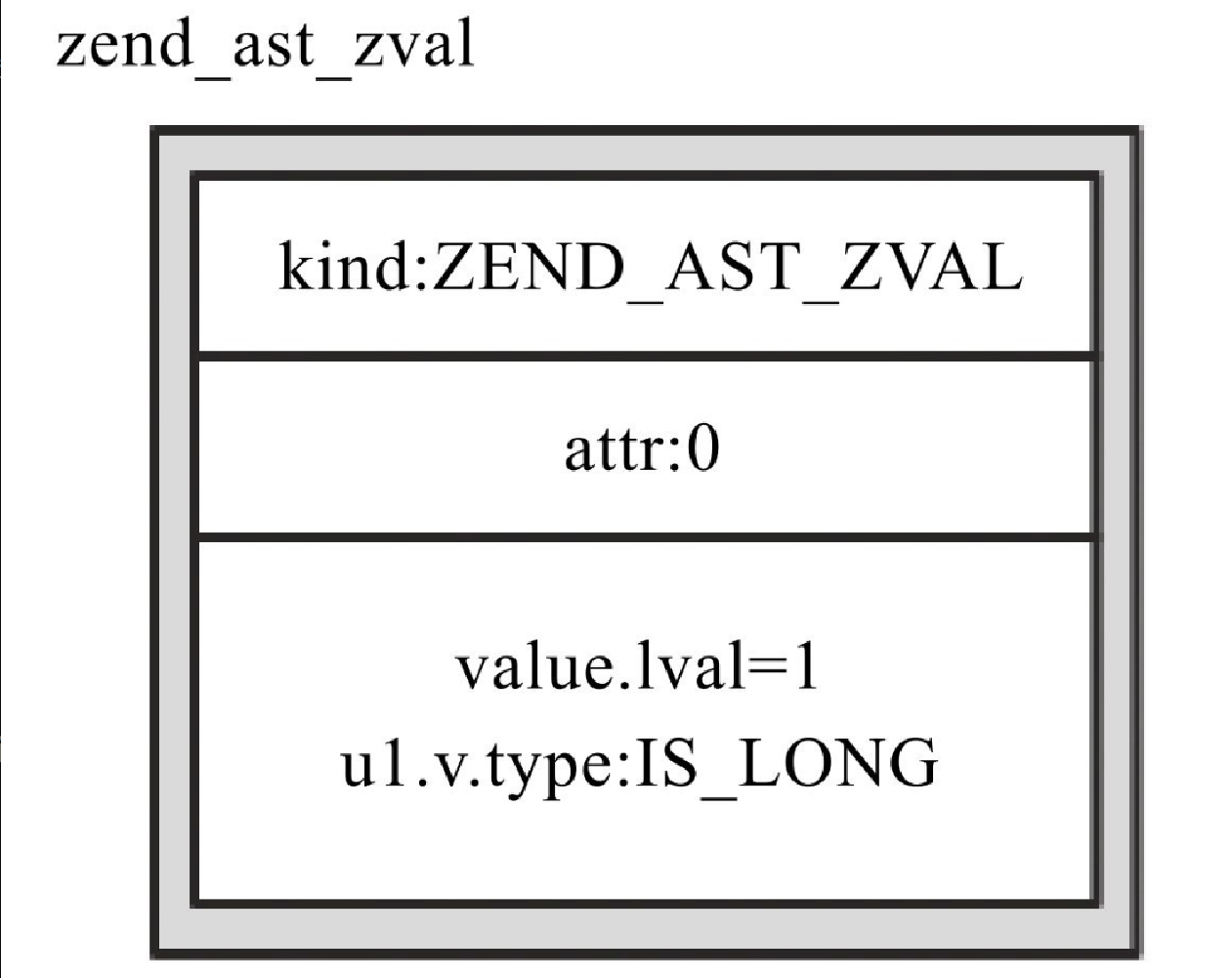
该 AST 会存放在 yyvsa[4] 中,同时 yyssa[4] 置为 277,如图10-21所示。
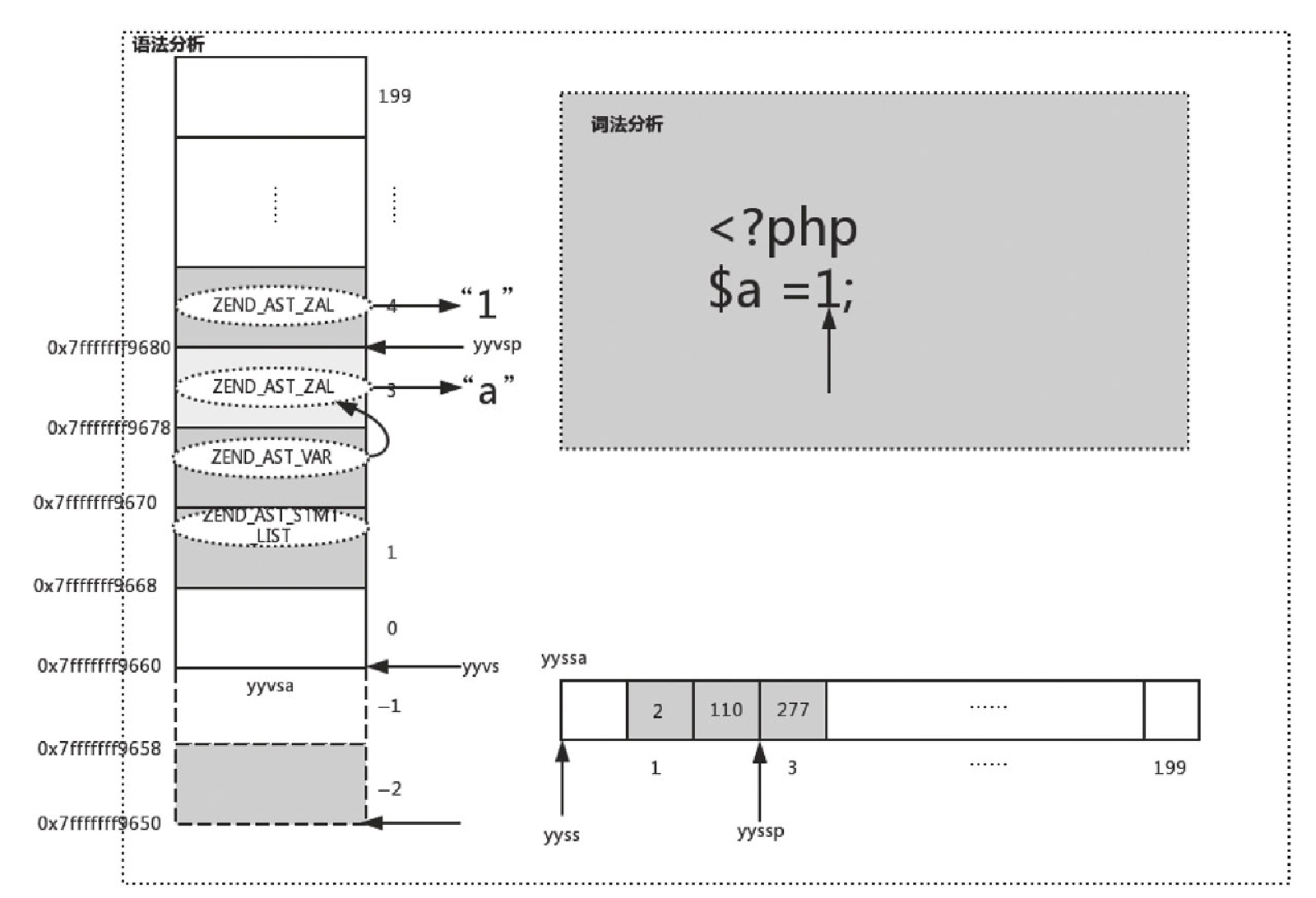
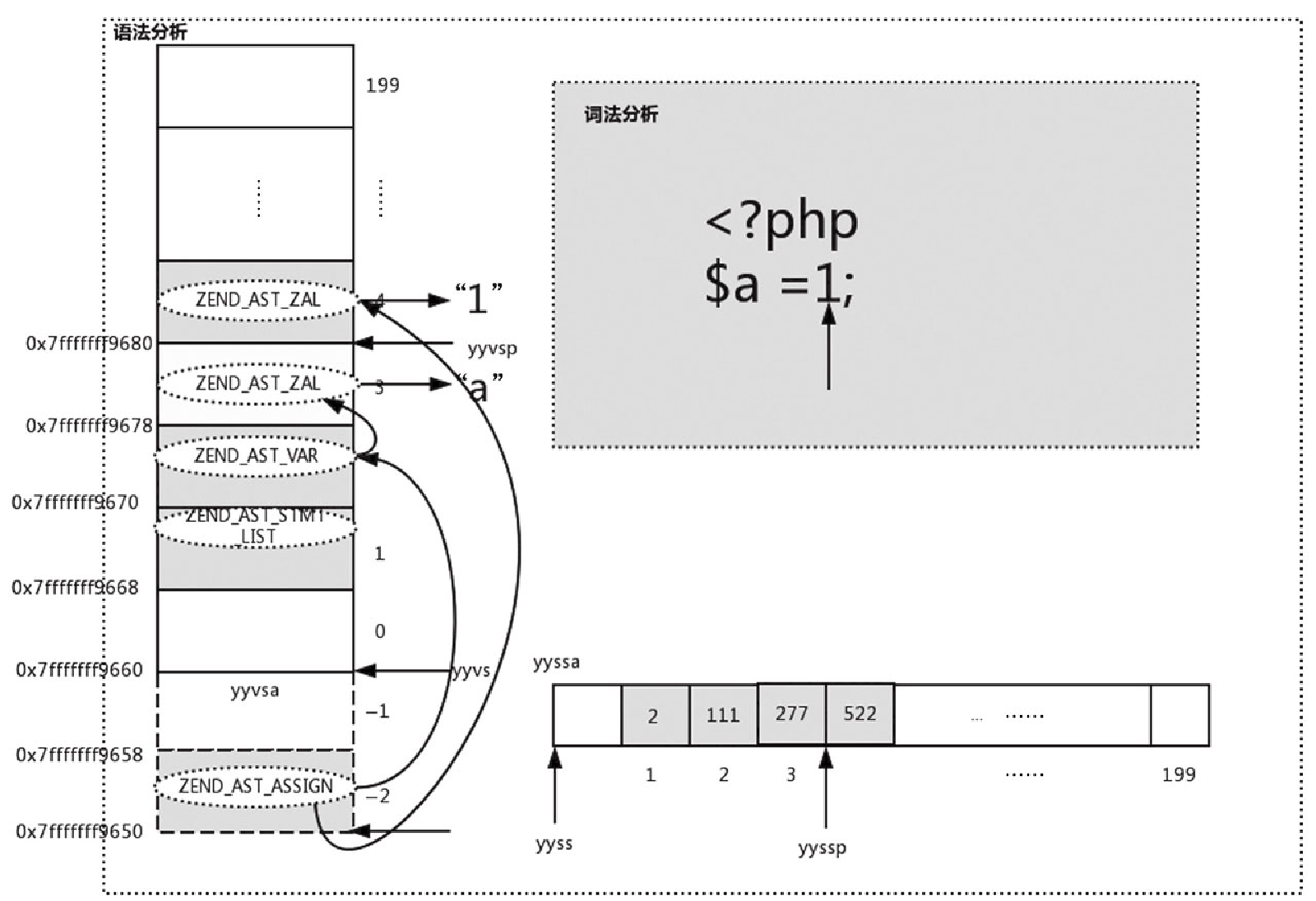
走到分号后,会创建 ZEND_AST_ASSIGN 的节点,并将此 AST 存于 yyval 中,代码如下:
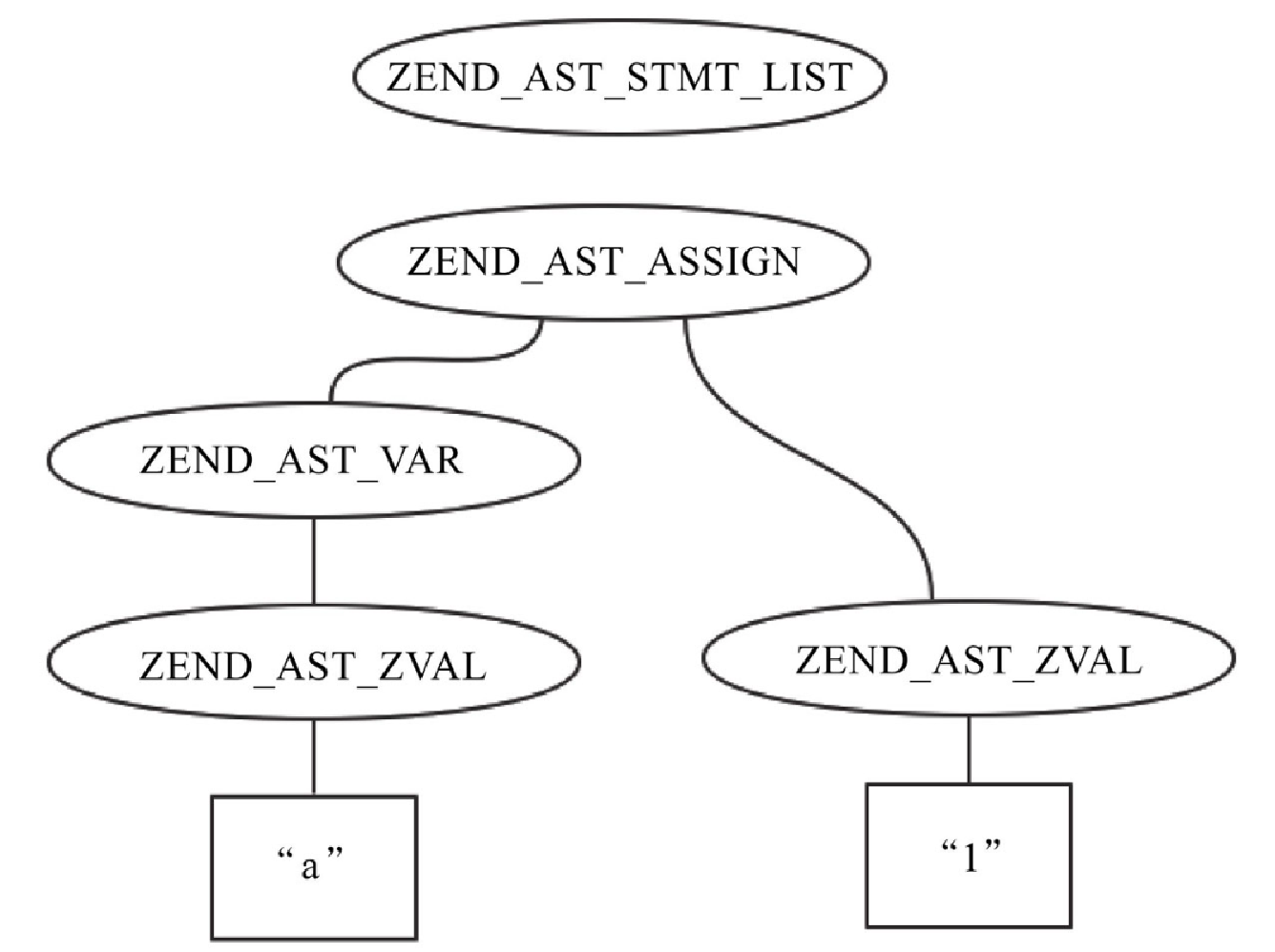
{ (yyval.ast) = zend_ast_create(ZEND_AST_ASSIGN, (yyvsp[-2].ast), (yyvsp[0].ast)); }从代码中可以看出,对于 kind 为 ZEND_AST_ASSIGN 节点的 child 为 $a 对应的 ZEND_AST_VAR,右 chid 为 1 对应的 ZEND_AST_ZVAL,如图10-22所示。此时对应的 AST 如图10-23所示。
结束状态
词法解析到文件结束,返回 RETURN_TOKEN(END),调用代码:
{ (yyval.ast) = zend_ast_list_add((yyvsp[-1].ast), (yyvsp[0].ast)); }将 ZEND_AST_ASSIGN 作为 child 赋值给 ZEND_AST_STMT_LIST,如图10-24所示。
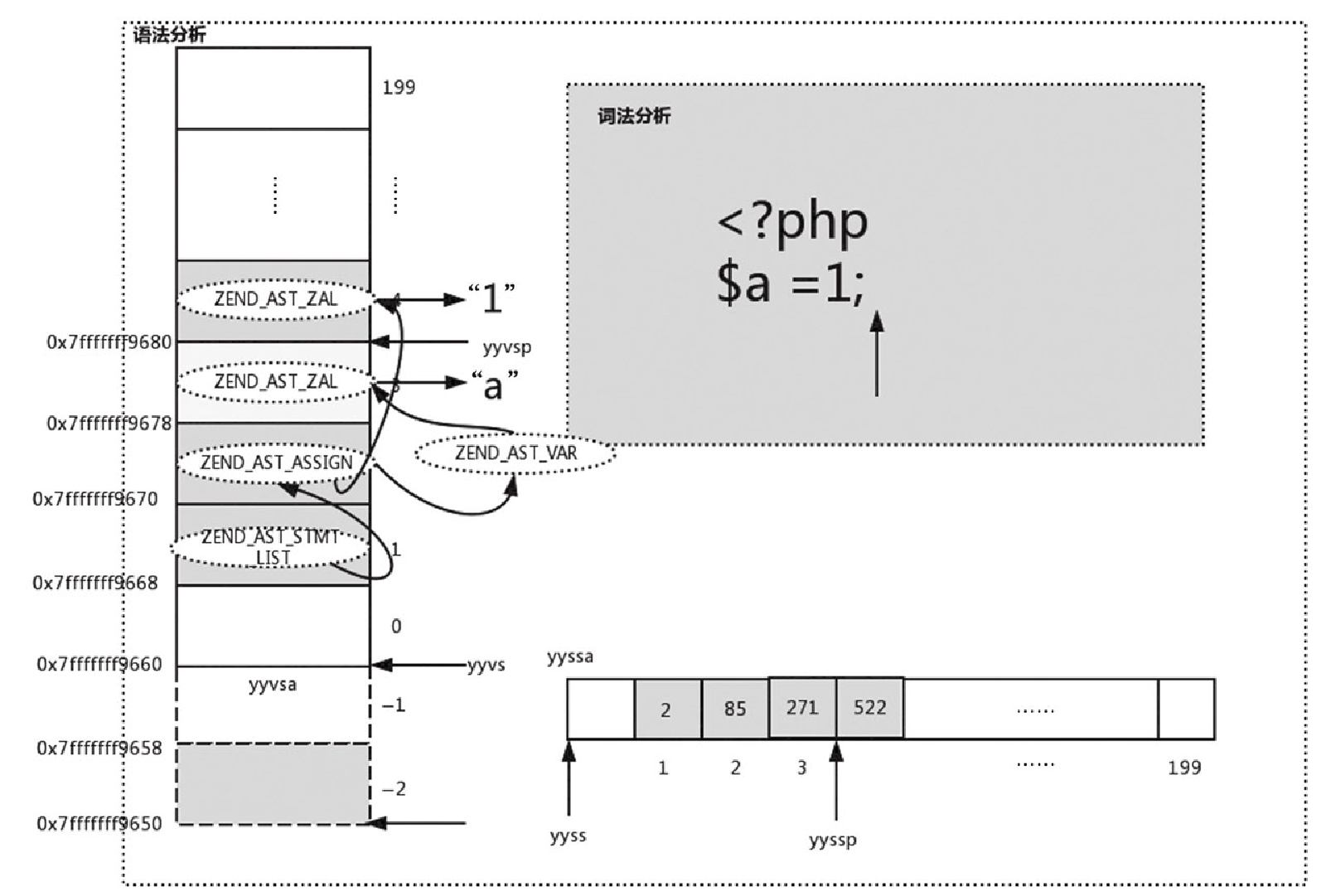
到此,我们生成了最终的 AST,如图10-25所示。
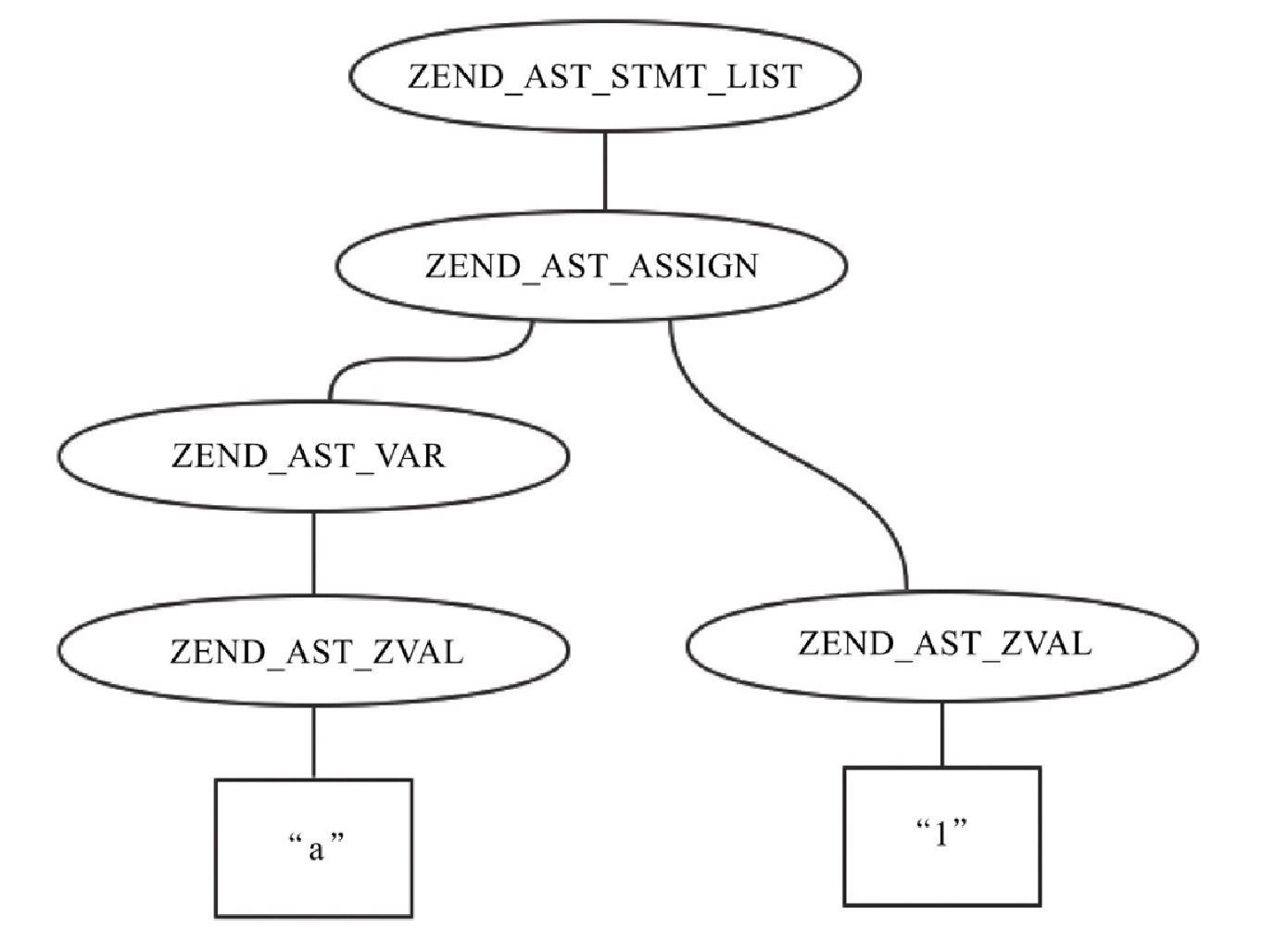
到此,对于简单的 PHP 代码,经过词法和语法分析,到生成 AST 的过程,我们从头到尾走了一遍,感兴趣的读者可以动手使用 gdb 一步步走一下。最后生成的 AST 会赋值给 CG(ast),所以对于任何一段代码,我们都可以在 zendparse() 后,输出对应的 AST。