基础知识
在学习 PHP 7 词法和语法分析之前,我们需要掌握一些编译原理的基本知识,本节会从编译器、语言处理系统、词法分析、语法分析等方面做一些知识准备工作,为后面详细分析 PHP 7 的词法和语法分析做一个铺垫。
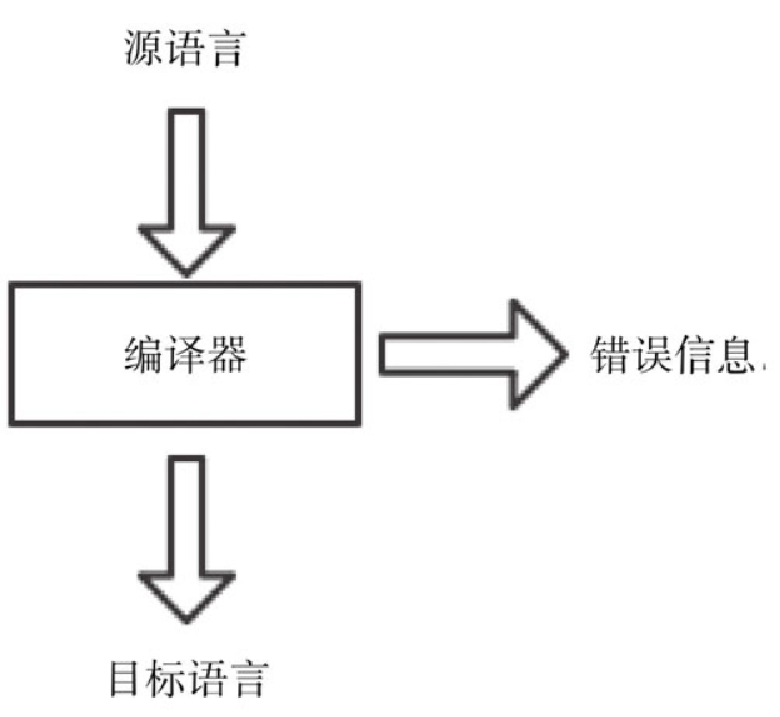
源程序分析
整个语言处理过程需要几个程序,分别是预处理器、编译器、汇编器以及装载器/连接器。其中,
预处理器程序会把存储在不同文件中的程序模块集成为一个完整的源程序;编译器会把源程序编译为目标汇编程序;而汇编器会继续将目标汇编程序转换为可重定位的机器码;然后经过装载器和连接器转为绝对的机器代码。源程序分析的 3 个阶段如下。
-
词法分析:又叫线性分析,从左到右读取源程序的字符,并将字符转换为一个又一个的记号,称作
Token。Token是具有整体含义的字符序列。 -
语法分析:这个过程会把字符串或者
Token在层次上划分为有一定层次的组,每个组有整体的含义。
词法分析
在编译器中,词法分析称为线性分析,举个例子,对于如下代码:
a = b + c * 2词法分析会将其分成如下几部分:
-
Token a; -
赋值符号
=; -
Token b; -
加号
+; -
Token c; -
乘号
*; -
数字
2。
对于表达式里面的空格,词法分析器会将其删除。
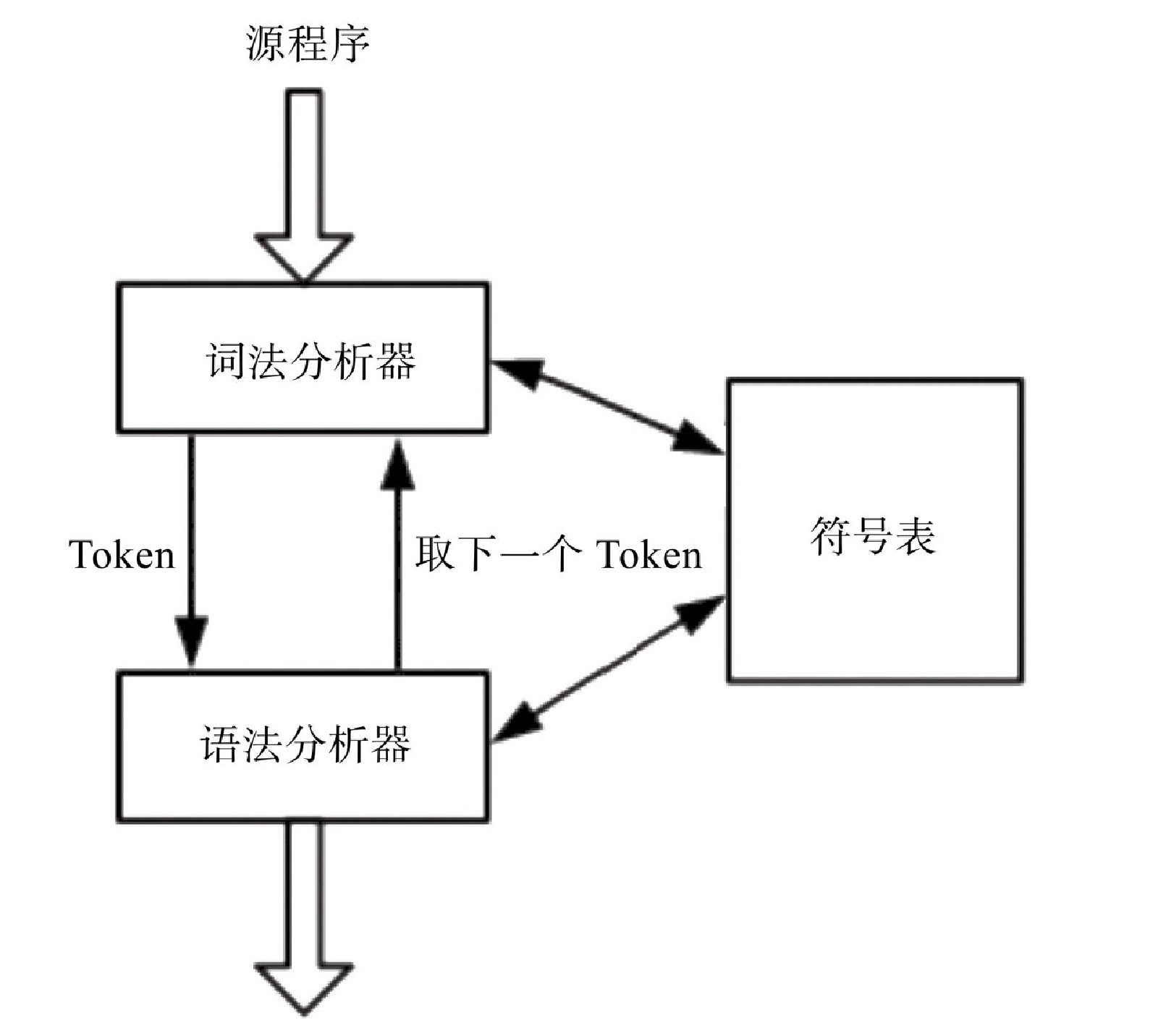
词法分析是编译的第一个阶段,主要任务是读取源程序,生成 Token(其中 Token 可以理解为特殊的标识),提交给语法分析器使用。词法分析器收到语法分析器发出的 “取下一个 Token” 的命令时,词法分析器继续读入源程序的字符,直到识别出下一个 Token。示例如图10-2所示。
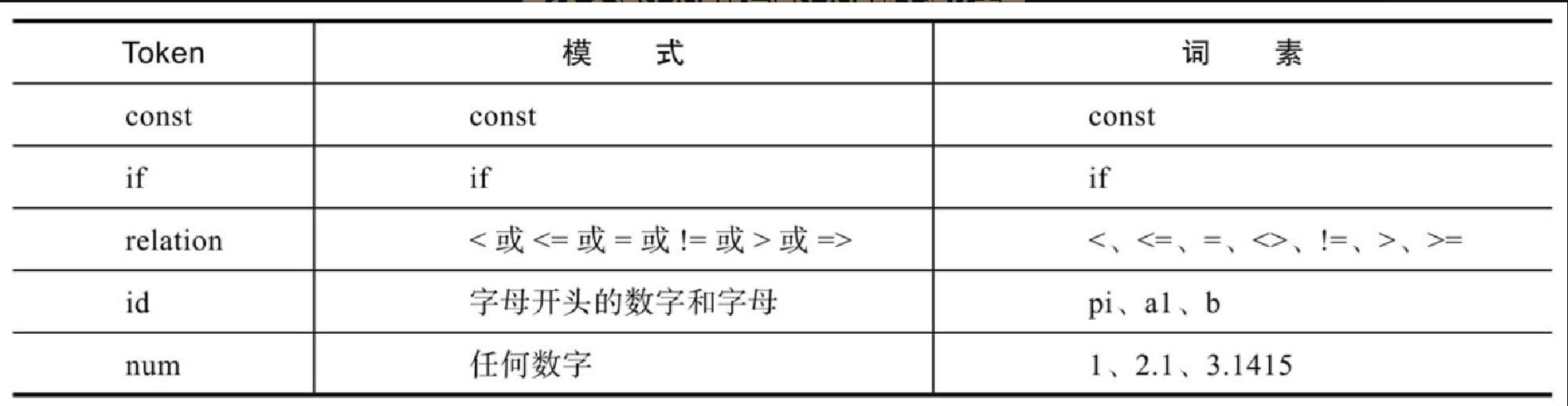
在词法分析中,经常会使用术语 “记号”(Token)、“模式” 和 “词素” 表示特定的含义,通过表 10-1 可以比较清楚地理解这三者的关系。
那么如何快速识别一个记号呢?词法分析是用正则表达式来表达和识别记号的,比如 PHP 7 词法分析中的正则表示如下:
LNUM [0-9]+ //十进制整型
DNUM ([0-9]*"."[0-9]+)|([0-9]+"."[0-9]*) //浮点型
EXPONENT_DNUM (({LNUM}|{DNUM})[eE][+-]? {LNUM}) //e的幂
HNUM "0x"[0-9a-fA-F]+ //十六进制
BNUM "0b"[01]+ //二进制
LABEL [a-zA-Z_\x80-\xff][a-zA-Z0-9_\x80-\xff]*
WHITESPACE [ \n\r\t]+ //空格
TABS_AND_SPACES [ \t]* //Tab和空格
TOKENS [; :, .\[\]()|^&+-/*=%! ~$<>? @]
ANY_CHAR [^]
NEWLINE ("\r"|"\n"|"\r\n") //新的行那么如何快速地判断一段文本是不是满足正则表达呢?下面我们引出编译原理中的状态转换图的概念,举个例子,对于下面的正则表达式:
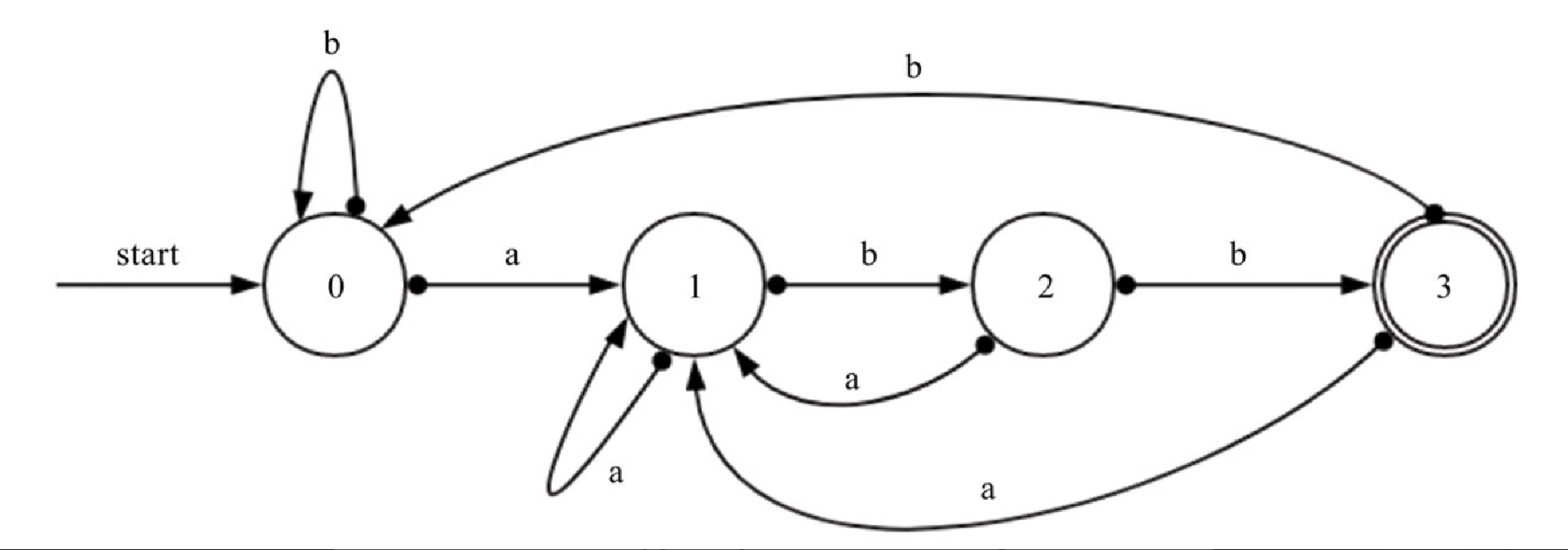
(a|b)*abb我们可以建立一个不确定的有穷自动机(NFA),如图10-3所示。
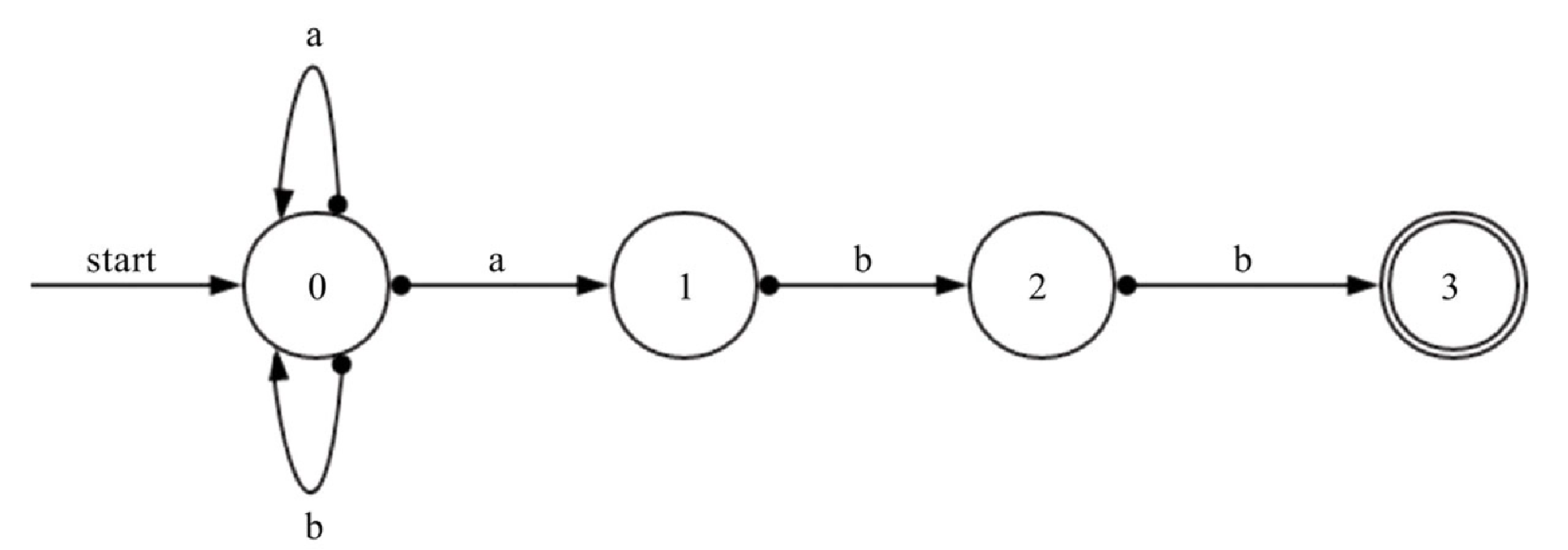
在图10-3 所示的不确定有穷自动机中,start 表示开始,有两个圈的 3 表示结束,状态 0、1、2 表示中间状态,箭头表示根据输入得到的状态流转。比如对于状态 0,输入 a 的时候,可以流转到状态 0,也可以流转到状态 1。因此,对于状态 0,输入 a,可以流转的集合为 {0,1},为了方便理解,举个例子如下。
-
比如输入
ababb,对于a,start可以到状态 0 ,对于b继续到状态 0,对于a到状态 1,对于b到状态 2,对于b到状态 3,3 是结束状态,因此,ababb字符串满足正则表达式(a|b)*abb。 -
比如输入
aba,对于a到状态 0,对于b到状态 0,对于a到状态 1,结束时不是最终状态,因此aba不满足正则表达式(a|b)*abb。
根据转换图,我们可以建立对应的转换表,如表10-2所示。
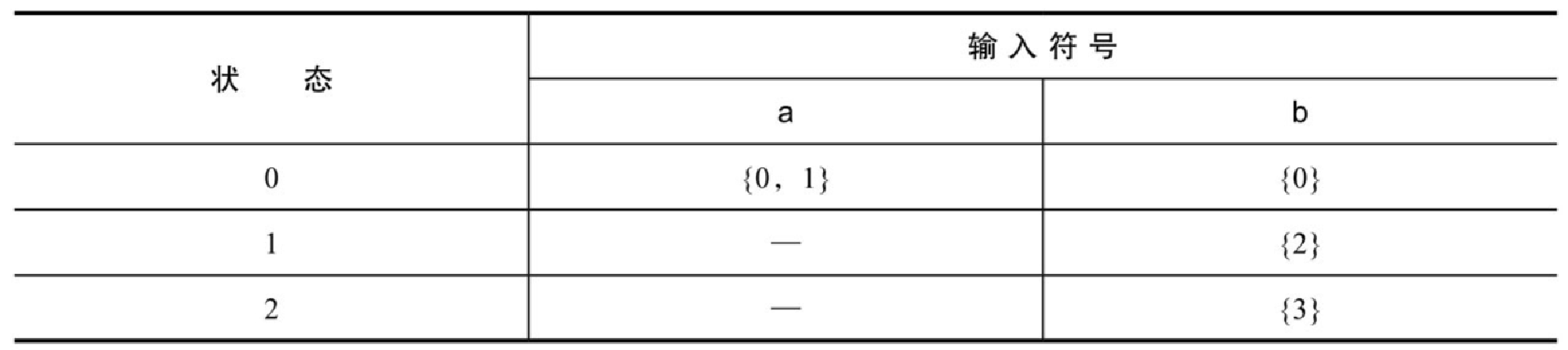
如表10-2所示,对于状态 0,如果输入 a,则可以流转到 0 或者 1,记为 {0,1};如果输入 b,则可以流转到 0,记为 {0}。
-
对于状态 1,如果输入 a,则无法进行流转;如果输入 b,则可以流转到 2,记为
{2}。 -
对于状态 2,如果输入 a,则无法进行流转;如果输入 b,则可以流转到 3,记为
{3}。
NFA 为什么叫不确定有穷自动机呢?比如对于状态 0,在输入 a 的时候流转的状态是不确定的,有可能流转到状态 0,也有可能流转到状态 1,所以对于 ababb,有可能一直在状态 0 中循环而达不到最终状态。因此,编译原理中有对应的算法可以将不确定的有穷自动机(NFA)转换为确定有穷自动机(DFA),具体算法可以参考编译原理相关的书籍,这里不再展开,转换后的 DFA 如图10-4所示。
这个将正则转换为 NFA/DFA 的工作是复杂的,但又是有规律和算法可遵循的,因此可以由转换工具,比如像 Re2c 这种词法分析器来完成。感兴趣的读者可以阅读一下 Re2c 的源码。词法分析器的核心工作就是将编写好的正则表达式转换为有穷自动机,将这部分工作解放出来,后面我们会在 10.2.2 节中对 Re2c 展开阐述。
语法分析
语法分析是进行的层次分析,称为 parsing 或者 syntax analysis,语法分析用于进一步把源程序分组,将源程序语法短语用语法树来表示,以如下代码为例:
a = b + c * 2生成的语法分析树如图 10-5 所示。
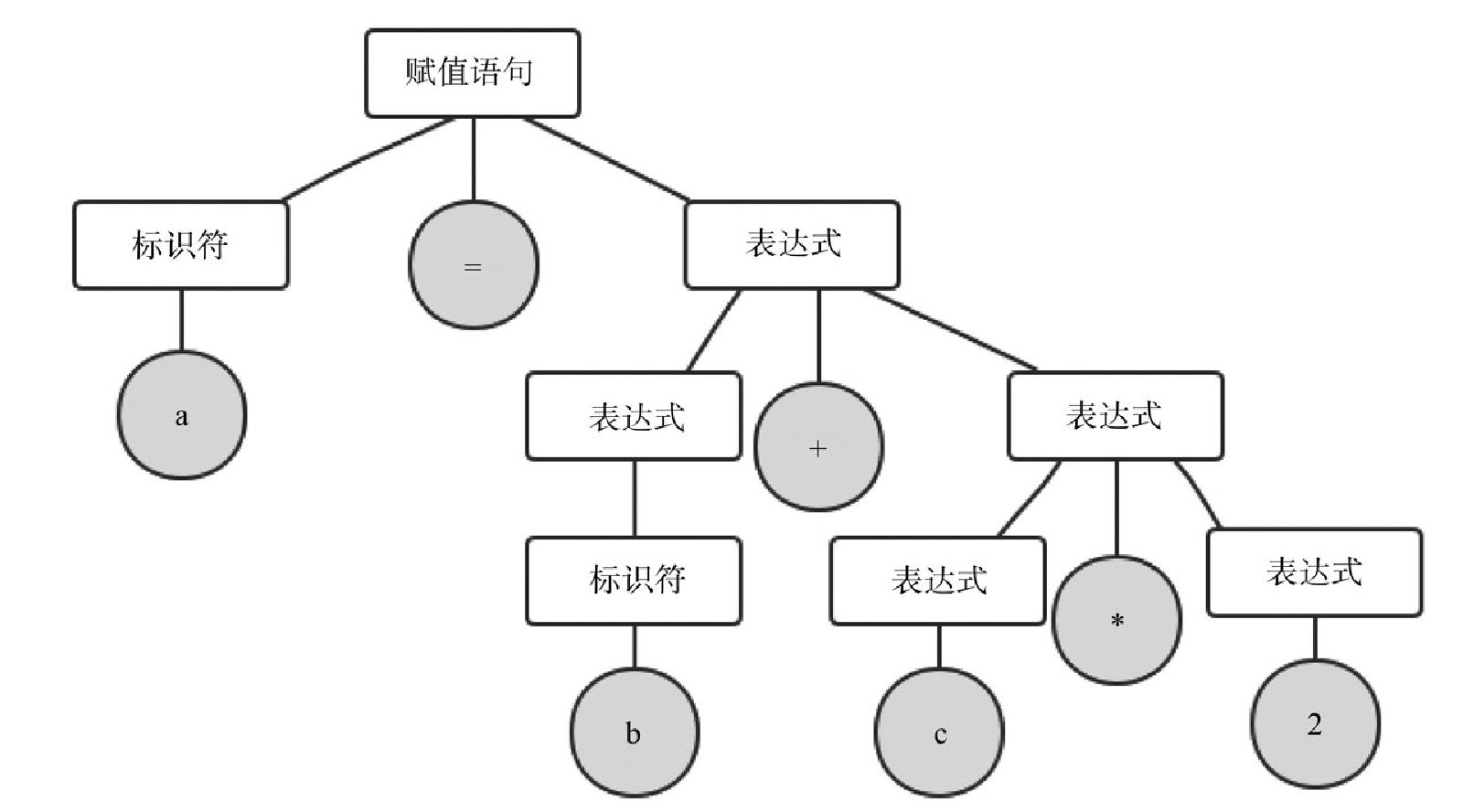
整个代码的层次可以使用递归规则来表达,对于上面的语法树,我们可以定义如下规则:
-
任何一个标识符都是表达式。
-
任何一个数字(包括
a\b\c\2)都是表达式。 -
如果
exp1和exp2是表达式,则exp1+exp2、exp1*exp2、{epx1}也是表达式。规则1 和规则2 是非递归的基本规则,而规则3 使用递归定义了表达式,因此,c*2是表达式,a+c*2也是表达式。
通常情况下,词法分析和语法分析的界限是不确定的,决定词法分析和语法分析界限的因素是源语言是否具有递归结构,词法结构一般不要求递归,语法结构常常需要递归。那么如何规范表达语法呢?那就是 BNF 范式(巴科斯范式)。
BNF范式
BNF 范式是一种用递归的思想来表述计算机语言符号集的定义规范,其法则如下:
-
::=表示定义。 -
“ ”双引号里的内容表示字符。 -
<>尖括号里的内容表示语法单位。 -
|竖线两边的是可选内容,相当于or。
如何理解 BNF 呢?下面举一个英语语法的例子:
The woman has a cat. (这个妇女有一只猫)上面的<句子>的语法规则可以表达如下:
1. <句子>::=<主语><谓语>
2. <主语>::=<冠词><名词>
3. <冠词>::=the | a
4. <名词>::=woman | cat
5. <谓语>::=<动词><宾语>
6. <动词>::=has
7. <宾语>::=<冠词><名词>通过这个简单的例子,相信读者对 BNF 有了一定的理解,那么我们举一个计算机中的例子,对于包含 +/- 的表达式,我们可以用下面的 BNF 表示:
expr:
NUM { $$ = $1; }
| expr '+' expr { $$ = $1 + $3; }
| expr '-' expr { $$ = $1- $3; }
;对于语句 1+2-3,根据规则 expr->NUM,可以得出 expr+2-3,继续得到 expr+expr-3,因为 expr+expr 又是 expr,因此得出 expr-3,同样的道理得出 expr-expr,最后的结果为 expr。
BNF范式在语法分析器 Bison 中有使用,具体我们会在 10.2.2 节阐述。
|
正则表达式能够表达词法,对于正则的判断可以使用有穷自动机来实现,这是后面词法分析器的基础;而 |