整合Seata解决分布式事务编码实践
前文介绍了分布式解决方案和 Seata Server 的搭建,本节通过实际的编码把 Seata 中间件整合到项目中,并通过实际的编码来讲解 Seata 分布式事务的落地技巧。演示代码是在 spring-cloud-alibaba-distribution-demo 模板项目的基础上修改的,主要包括三个服务:商品服务、购物车服务 和 订单服务。本节将整合 Seata 对当时存在分布式事务问题的代码进行改造,解决数据不一致的问题。
创建undo_log表
在搭建 Seata Server 时,新建了一个数据库并导入了三张表,这是 Seata Server 运行时所需要的数据。如果想整合 Seata 来解决分布式问题,就需要在每个微服务实例所依赖的数据库中创建一张名称为 undo_log 的表。比如,本节将介绍三个微服务实例,需要在商品服务的数据库、购物车服务的数据库和订单服务的数据库中各自新建一张 undo_log 表。具体的建表语句 Seata 官方已经提供了,见网址10。
在该目录下有多个文件夹,分别是 at/db、saga/db、tcc/db。因为 Seata 为开发人员提供了多种分布式事务的处理方式,如 AT、TCC、SAGA 等模式,在选择不同的处理方案时,需要引入不同的建表语句。
本节编码中使用的 Seata 处理方式是 AT 模式。AT 模式是 Seata 官方比较推荐的一套分布式事务解决方案,这种方式比较简单,对业务侵入低,不需要改动具体的业务代码,添加一个注解再添加几行配置项即可整合 Seata 来解决分布式事务,非常方便。需要引入的 undo_log 表的文件见网址11。
最终的建表 SQL 语句如下:
-- for AT mode you must to init this sql for you business database. the seata
-- server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such
as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal
status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT = 'AT transaction mode undo table';通过 undo_log 表的建表字段可知,该表会存储全局事务和分支事务的 id、回滚数据、执行状态等信息,如果全局事务失败,就需要依次回滚所有分支事务,需要执行的内容就保存在这个表里。所以,undo_log 这个表需要创建在各个微服务实例下的数据库中。比如,本节实战中的示例,就要在 test_distribution_cart_db 数据库、test_distribution_goods_db 数据库和 test_distribution_order_db 数据库中依次创建这个表,建表成功后的目录结构如图 10-20 所示。
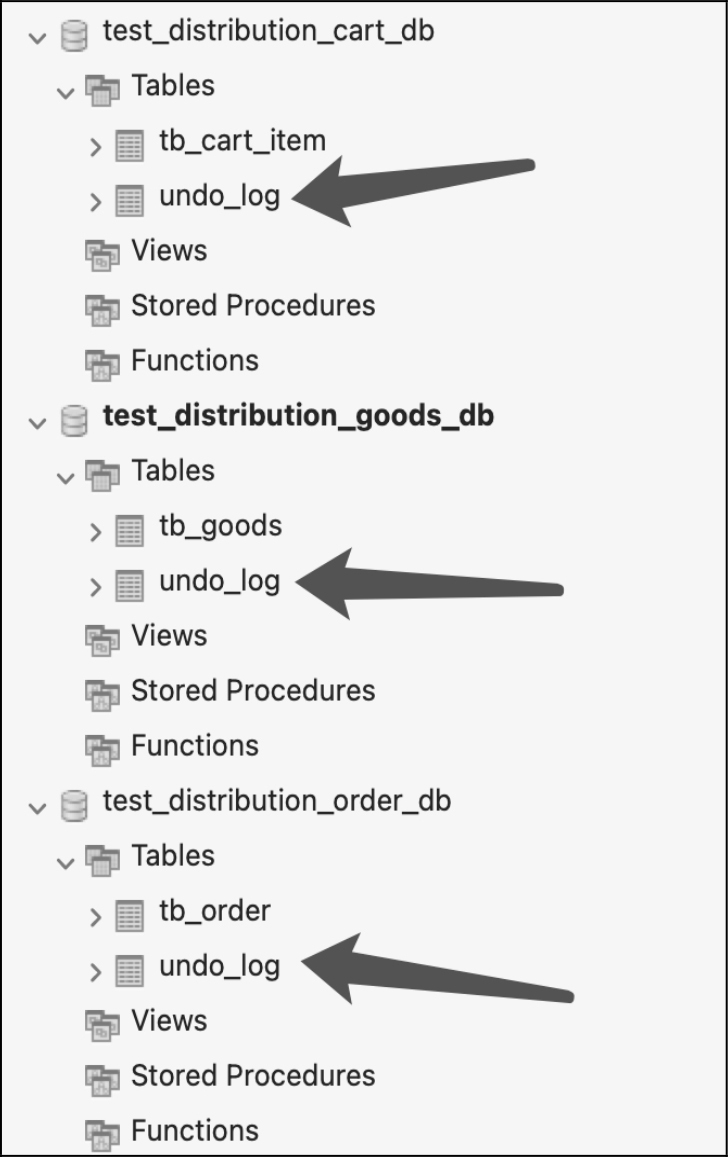
另外,只有微服务实例需要被纳入分布式事务中时才会添加 undo_log 表,如果服务并不涉及分布式事务,就不需要在数据库中添加这个表。比如,服务架构下的 服务A、服务B 涉及分布式事务的问题,就在这两个服务所依赖的数据库中添加 undo_log 表,而服务E 和服务F 中都没有相关的依赖链路使得它们出现分布式事务的问题,就无须添加 undo_log 表。
整合Seata解决分布式事务
在实际编码前,先修改项目名称为 spring-cloud-alibaba-seata-demo,再把各个模块中 pom.xml 文件的 artifactId 修改为 spring-cloud-alibaba-seata-demo,然后依次修改三个服务代码,具体操作步骤如下。
添加Seata依赖
依次打开 goods-service-demo、order-service-demo 和 shopcart-service-demo 三个项目中的 pom.xml 文件,在 dependencies 节点下新增 Seata 的依赖项,配置如下:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>添加Seata配置项
依次打开 goods-service-demo、order-service-demo 和 shopcart-service-demo 三个项目中的 application.properties 配置文件进行修改。为了做章节区分,先把项目中的端口号分别修改为 8161、8164 和 8167,然后添加与 Seata 相关的配置项。官方提供的配置文件可供参考,见网址12。
这里有 .properties 和 .yml 两个格式的配置文件,根据自身项目配置文件的格式选择即可。主要增加的配置项如下:
seata.enabled: 是否开启自动配置
seata.application-id: 当前 Seata 客户端的应用名称
seata.tx-service-group: 事务分组
seata.registry.type: 服务中心的类型 (本书选择的是 Nacos)
seata.registry.nacos.*: 与 Nacos 相关的配置信息最终增加的配置项如下:
# seata config
seata.enabled=true
# 将三个不同的服务命名为不同的名称,如 goods-server、order-server、shopcart-server
seata.application-id=goods-server
# 事务分组配置
seata.tx-service-group=test_save_order_group
service.vgroupMapping.test_save_order_group=default
# 连接 Nacos 服务中心的配置信息
seata.registry.type=nacos
seata.registry.nacos.application=seata-server
seata.registry.nacos.server-addr=127.0.0.1:8848
seata.registry.nacos.username=nacos
seata.registry.nacos.password=nacos
seata.registry.nacos.group=DEFAULT_GROUP
seata.registry.nacos.cluster=default在三个项目的配置文件中依次添加上述配置项即可,其他配置项使用 Seata 的默认值即可。更多配置项内容可查看官方文档,见网址13。
数据源对象改造
在 Spring Boot 项目中,只需要在配置文件中添加几行关于数据库连接的配置项,即可获取 DataSource 对象并操作数据库,这是因为 Spring Boot 项目在启动时自动装配了数据源对象,如 HikariDataSource、DruidDataSource(默认是 HikariDataSource)。
在整合 Seata 时,最重要的一个步骤就是让 Seata 创建基于 DataSource 对象的代理来接管项目原有的 DataSource 对象,因此需要配置 DataSourceProxy 数据源代理类。DataSourceProxy 是 Seata 中间件提供的 DataSource 代理类,在分布式事务的处理过程中,用于自动生成 undo_log 回滚数据,以及自动完成分布式事务的提交或回滚操作,这些操作是项目原有的 DataSource 对象无法做到的。
当然,这个配置也不复杂,直接按照 Seata 官方文档中给出的代码进行修改即可。
依次在 goods-service-demo、order-service-demo 和 shopcart-service-demo 三个项目中创建 config 包,并新增 SeataProxyConfiguration 类,代码如下:
import com.alibaba.druid.pool.DruidDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import
org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import javax.sql.DataSource;
@Configuration
public class SeataProxyConfiguration {
//创建 Druid 数据源
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
//创建 DataSource 数据源代理
@Bean("dataSource")
@Primary
public DataSource dataSourceDelegation(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}创建 Druid 数据源并注册到 Spring 的 IoC 容器中,然后使用它来生成 DataSourceProxy 对象并注册到 Spring 的 IoC 容器中。只需简简单单的几行代码,数据源对象改造就成功了。
另外,数据源对象的改造步骤是必需的,但是在这个步骤中,开发人员可以不用编写额外的编码,即不用在项目中单独编写 SeataProxyConfiguration 类。因为创建数据源代理对象是 Seata 组件自动会做的事情(基于 Spring Boot 的自动装配机制)。在本节中,笔者将其作为一个重要步骤讲解,目的是让读者对 Seata 组件的工作原理更了解一些。为什么 Seata 组件可以对数据库做那么多的操作?因为它接管了项目中的数据源。
添加 @GlobalTransactional注解
前期的准备工作基本都完成了,接下来就到了最激动人心的时刻,只需要在代码中添加一个注解就能够开启整个分布式事务的处理过程。
打开 order-service-demo 项目中的 OrderService 类,在 saveOrder() 方法上添加 @GlobalTransactional 注解,代码修改如下:
@Transactional
//加上这个注解,开启 Seata 分布式事务
@GlobalTransactional
public Boolean saveOrder(int cartId) {
//省略部分代码
}saveOrder() 方法是一个涉及分布式事务的方法,在这个方法中会调用其他服务来共同完成 “下单” 的流程,进而会操作三个独立的数据库。在这个方法上添加的 @GlobalTransactional 注解是全局事务注解,作用是开启全局事务。当执行到 saveOrder() 方法时,会自动开启全局事务。如果该方法中的代码逻辑都正常执行,则进行全局事务的 Commit 操作;如果该方法中抛出异常,则进行 RollBack 操作。
只需要在涉及全局事务的方法上添加这个注解即可,如本示例只需要在 saveOrder() 方法上添加,在 goods-service-demo 和 shopcart-service-demo 方法中不需要添加这个注解,因为它们属于分支事务。