搭建Zipkin Server实现链路追踪的可视化管理
Zipkin 是 Twitter 公司开源的一套分布式链路追踪系统,可以采集时序数据来协助定位延迟等问题。使用时需要独立部署 Zipkin 服务器,同时在微服务内部安装 Zipkin 客户端才能够自动实现日志的推送与展示。
部署 Zipkin 服务端后,一旦微服务产生链路追踪日志,Zipkin 客户端便会自动以异步形式将日志数据推送至 Zipkin 服务端,Zipkin 服务端会对数据进行组织和整理。之后,通过 Zipkin 内置的 UI 界面可以看到每个调用链路的链路信息、所花费的时间等内容。接下来笔者将讲解 Zipkin 服务端搭建及客户端整合的过程。
搭建Zipkin Server的详细过程
Zipkin Server 的搭建操作非常简单,可以通过官网提供的教程快速完成。快速上手的教程见网址16。
这里提供了三种方式来搭建 Zipkin Server。笔者选择的是直接下载 Zipkin Server 的可执行 Jar 包并启动的方式,与 Sentinel 控制台的搭建方式类似。Zipkin Server 的下载网址见网址17。
打开这个网址能够获取最新版本的 Zipkin Server 可执行 Jar 包,笔者下载的版本是 2.23.16。如果觉得使用这个网址下载很慢,可以直接使用本书配套资料中的 Jar 包。下载成功后会得到一个名为 zipkin-server-2.23.16-exec.jar 的文件,直接使用下方的命令即可启动 Zipkin Server。
# 默认端口号 9411
java -jar zipkin-server-2.23.16-exec.jar
# 如果想使用其他端口启动可以使用 --server.port 参数
java -jar zipkin-server-2.23.16-exec.jar --server.port=9333这里有一点需要注意,Zipkin Server 的默认监听端口号是 9411。启动成功后,可以在命令行中看到 Zipkin 的特色 Logo,以及一行 Serving HTTP 的运行日志,如下所示:
访问 Zipkin Server 的 UI 页面,网址如下:
http://localhost:9411/zipkin/显示效果如图 12-5 所示。
这就是 Zipkin Server 内置的分析 UI 页面,当前因为没有接入服务实例,所以页面中是空数据。接下来将讲解如何将服务实例中的链路数据传输到 Zipkin Server 中。
整合 Zipkin Client 编码实践
先在每个微服务模块的 pom.xml 中添加 Zipkin 依赖。依次打开 order-service-demo、goods-service-demo、shopcart-service-demo 项目中的 pom.xml 文件,在 dependencies 标签下引入 Zipkin 的依赖文件,新增代码如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>然后在服务实例中配置 Zipkin 的通信地址及采样率。依次打开 order-service-demo、goods-service-demo、shopcart-service-demo 项目中的 application.properties 配置文件,分别新增如下配置项:
# Sleuth 采样率,取值范围为[0.1,1.0],值越大采集越多,但性能影响也越大
spring.sleuth.sampler.probability=1.0
# 每秒数据采集量,最多 n 条 / 秒 Trace
spring.sleuth.sampler.rate=500
spring.zipkin.base-url=http://localhost:9411spring.zipkin.base-url 配置项只要设置一个可用的 Zipkin Server 的 IP 和端口号即可。
下面对两个配置项进行重点说明。
-
spring.sleuth.sampler.probability指采样率,它是一个Float类型的数字,取值范围为[0.1,1.0]。假设在过去的 1 秒order-service实例产生了 100 个Trace,如果采样率为 0.1,则表示只有 10 条记录会被发送到Zipkin服务端进行分析和整理;如果采样率为 1.0,则表示 100 条Trace都会被发送到Zipkin服务端进行分析和整理。当然,这个值越大表示收集越及时,但性能影响也越大。 -
spring.sleuth.sampler.rate指每秒最多采集量,超出部分将直接抛弃。服务请求依然会被正常处理,只是调用链信息不会被Zipkin Server所采集。
链路追踪效果演示
依次启动三个服务实例,之后打开浏览器访问如下地址:
http://localhost:8207/order/saveOrder?cartId=13&goodsId=2025进入 Zipkin 的控制台页面,单击 “RUN QUERY” 按钮,就会出现调用链路的信息,如图 12-6 所示。
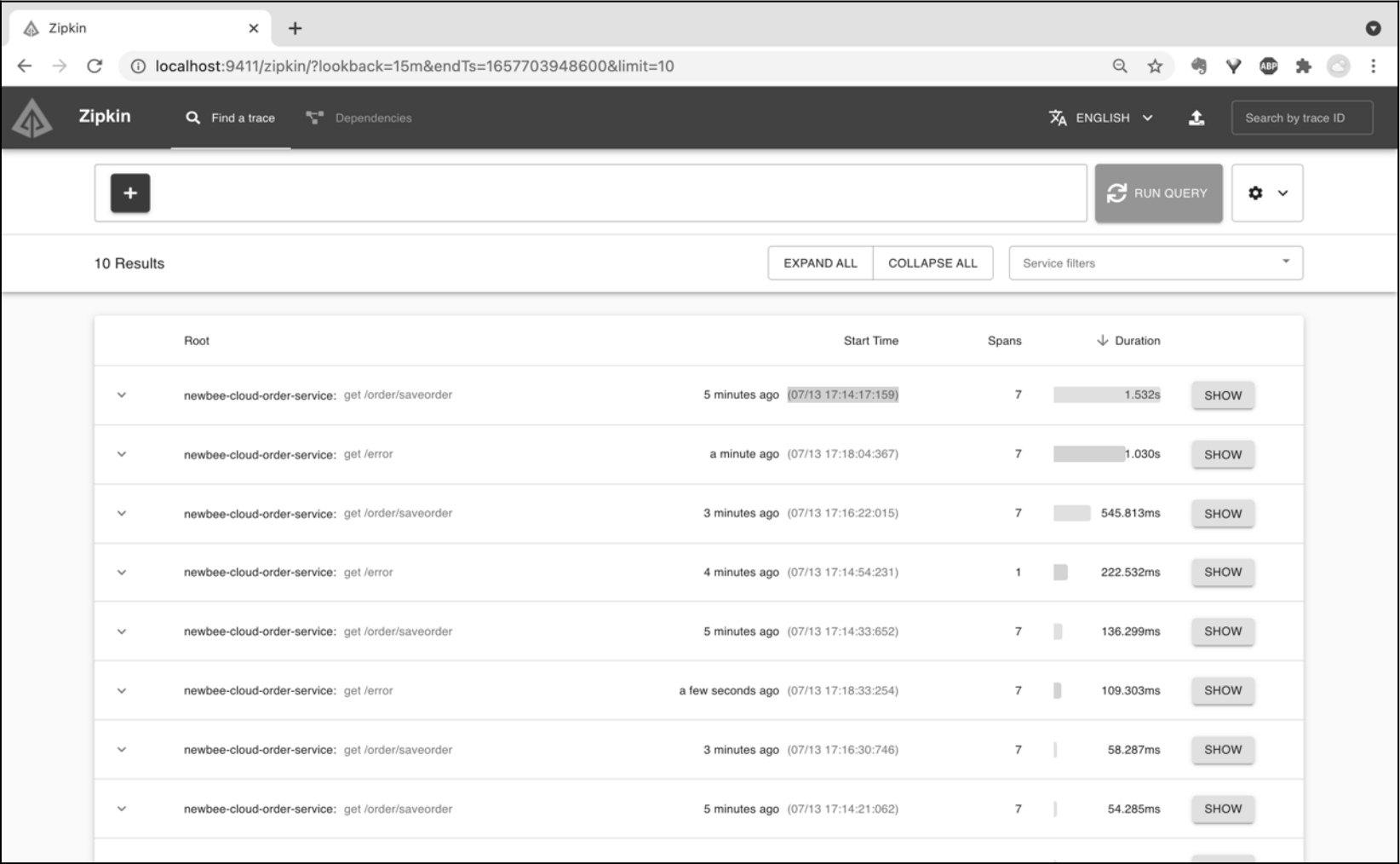
在调用链路信息首页,可以通过各种搜索条件的组合,从服务名称、Span名称、时间等不同维度查询调用链路数据,如图 12-7 所示。

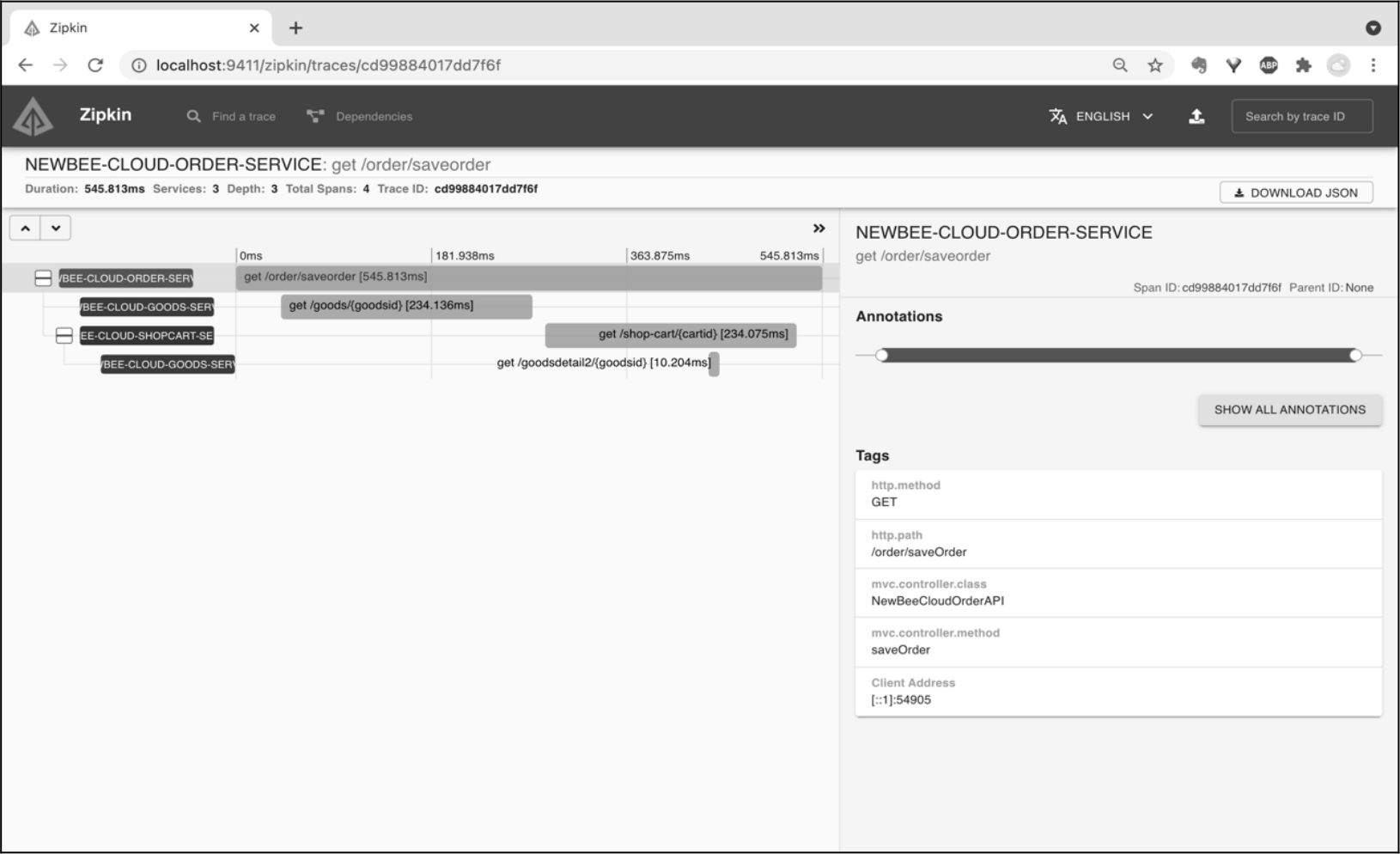
某个调用链路的详情页面如图 12-8 所示。
在调用链路的详情页面中,所有 Span 都以时间序列的先后顺序进行排列,可以清晰地看到链路中每个步骤的开始时间、结束时间及处理用时。
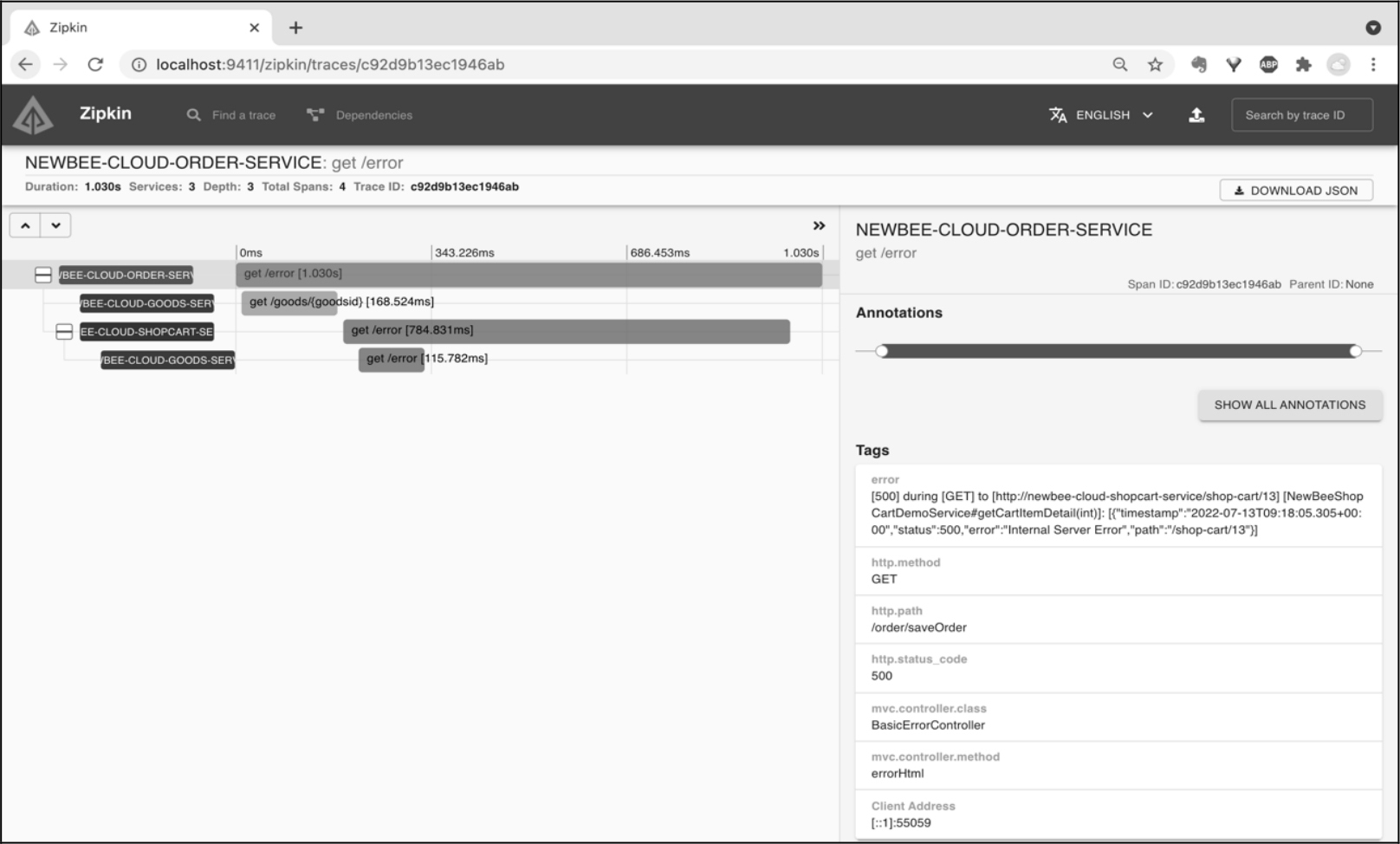
如果某个调用链路出现了异常,就可以从调用链路的详情页面轻松地看出异常发生在哪个阶段。比如,图12-9 中的调用链路在 OpenFeign 远程调用 goods-service 服务的时候抛出了 RuntimeException,在调用链路的详情页面上已被标红。单击对应的红色 Span,就可以看到具体的异常提示信息。
这里是笔者故意在 goods-service 的接口中写了会报错的代码模拟这种情况。
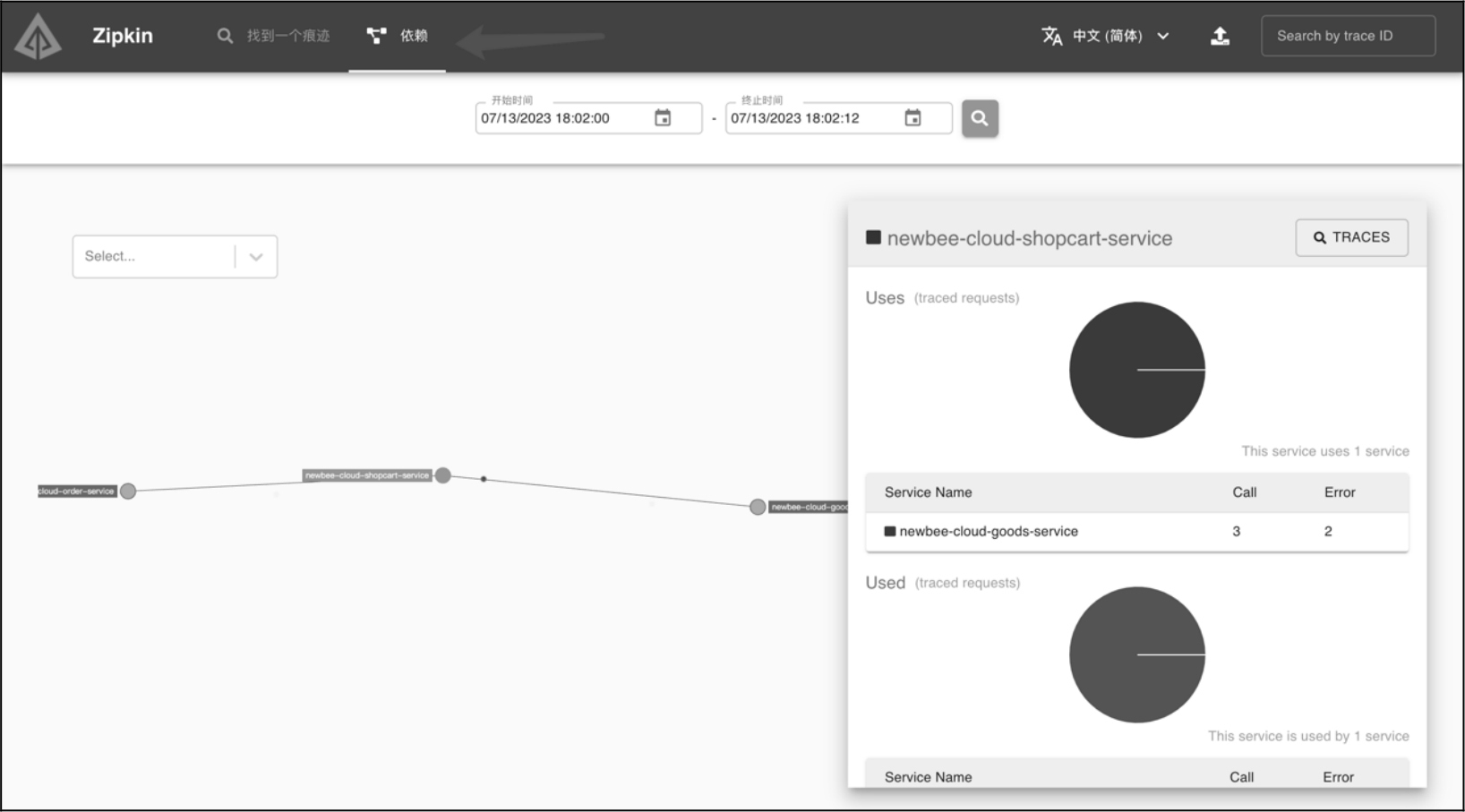
单击页面中的 “Dependencies”(依赖)会跳转到链路依赖关系页面,在这里会以图形化的方式显示某段时间内微服务之间的相互调用情况,如果两个微服务之间有调用关系,就会用一条实线将两者连接起来。实线上流动的小圆点表示调用量的多少,圆点越多表示这条链路的流量越多。而且,小圆点还有红、蓝两种颜色,其中红色表示调用失败,蓝色表示调用成功。单击某个服务,会显示对应的统计信息,如图 12-10 所示。
本章主要讲解链路追踪的概念和作用,并介绍 Spring Cloud Sleuth 组件是怎样通过几个特殊的标记来完成 “打标” 和链路串联的,之后结合实际的编码讲解整合 Spring Cloud Sleuth 组件的过程及整合前后日志信息的对比,最后介绍如何引入 Zipkin 实现可视化链路追踪,并简单地模拟了异常情况。到这里,相信读者已经对调用链路追踪系统的搭建和使用有了一定的认识,自己动手实践一下会理解得更为深刻。