服务链路追踪及技术选型
本节笔者将介绍链路追踪的相关概念,以及本书中所选择的微服务链路追踪组件——Spring Cloud Sleuth。介绍完相关概念后,将实际地进行编码实现和组件搭建,让读者能够掌握这个知识点。
什么是链路追踪
在微服务架构下,系统的功能是由大量的微服务协调组成的,大量的服务实例构成了复杂的分布式网络。在服务能力提升的同时,众多服务中肯定存在一些复杂而深度的调用链路,这也使得一旦出现 Bug 或异常就会让问题定位变得更加困难。当一个请求在经过诸多服务过程中出现了某一个调用失败的情况,想要查询具体的异常由哪一个服务引起的就变得十分困难,处理效率也会非常低。
如图12-1所示,微服务架构中难免出现一些链路复杂的请求调用。当出现问题的时候,就需要一种能够对故障点快速定位的方案,让开发人员可以尽快确认问题出现在哪个链路节点上,链路追踪技术由此而生。链路追踪就是将一次分布式请求(多个服务请求)变成一条清晰的调用链路,将一次分布式请求的调用情况集中展示,如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等。
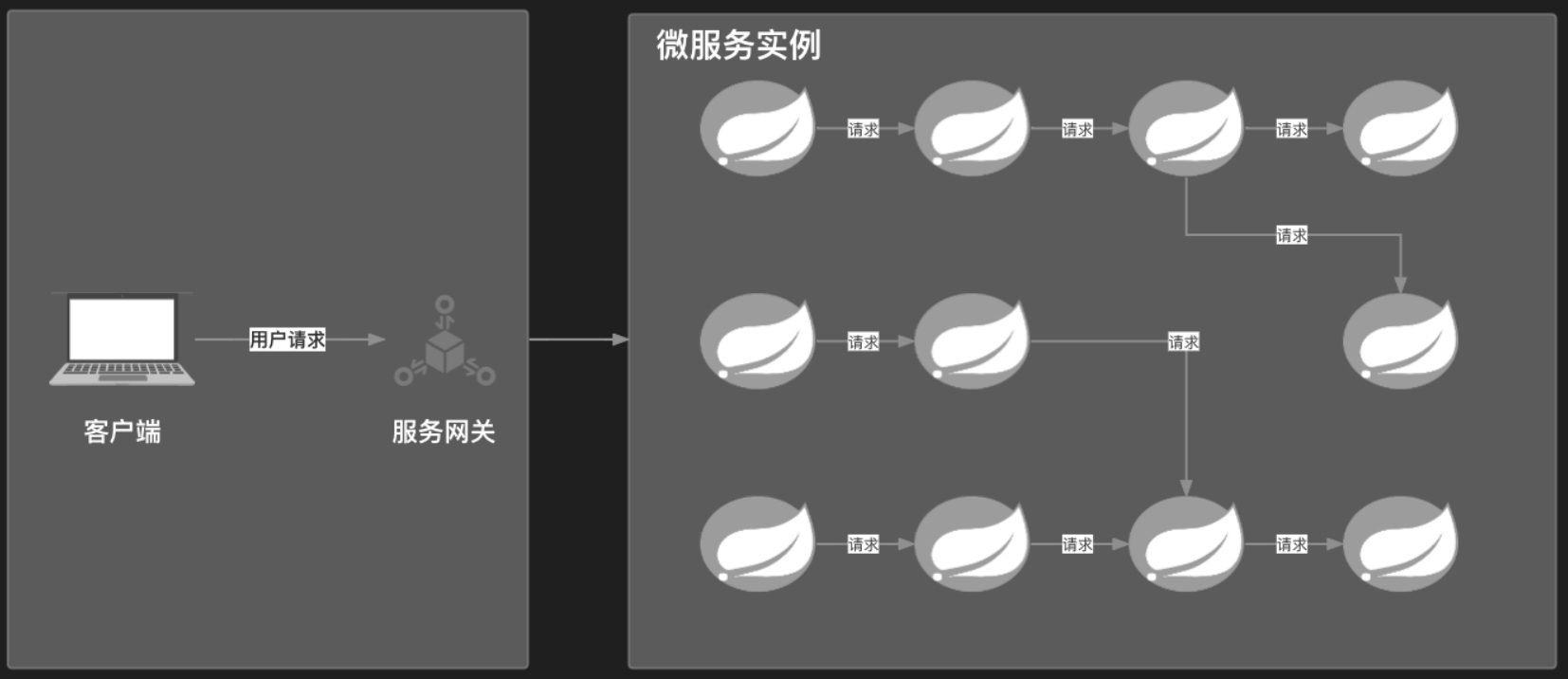
链路追踪其实是系统运行时通过某种方式记录服务之间的调用过程,并且将这个调用过程进行强关联的一个过程。可视化的 UI 界面或日志查询系统能够帮助开发人员快速定位出错点。链路追踪是微服务架构运维的重要组件,引入之后,即使再复杂的调用链路也会变得井井有条,能够让人非常清晰地看到服务之间的通信过程。
Spring Cloud Sleuth简介
Spring Cloud Sleuth 的主要功能是在分布式系统中提供追踪解决方案。在 Spring Cloud 微服务生态下,Sleuth 组件通过扩展日志的方式实现微服务的链路追踪。
简单来说,Spring Cloud Sleuth 为每次服务调用生成几个标识字段,从服务调用的起点到终点,这个过程中的所有日志信息都会额外输出这些字段,如此就可以根据日志中的 ID 字段清晰地梳理出一次服务请求都经过了哪些微服务节点。当然,一句话概括起来比较笼统,笔者通过一个示例来讲解就会清晰一些。
如果不引入 Sleuth 组件,那么服务实例日志输出的标准格式如下:
2023-06-01 20:54:42.108 DEBUG 6860 --- [nio-8114-exec-2]
l.s.c.n.o.NewBeeGoodsDemoService :
[NewBeeGoodsDemoService#getGoodsDetail2] 商品 2025,当前服务的端口号为 8201引入 Sleuth 链路追踪组件后的日志格式如下:
2023-06-01 23:51:46.370 DEBUG [newbee-cloud-shopcart-service, 1db532812a930a69, 6147c466cbcbdb3e] 5416 --- [nio-8114-exec-3] l.s.c.n.o.NewBeeGoodsDemoService : [NewBeeGoodsDemoService#getGoodsDetail2] 商品 2025, 当前服务的端口号为 8201将两份日志进行比对后会发现,在原有日志中额外附加了下面的文本:
[newbee-cloud-shopcart-service,1db532812a930a69,61474f66c0ada3e]这段文本被逗号分成三个字段,分别是服务名称、Trace ID、Span ID。
-
服务名称:说明日志是由哪个微服务产生的。
-
Trace ID:标记请求链路的全局唯一ID,用于标记整个请求链路。 -
Span ID:请求链路中的每个微服务都会生成一个不同的Span ID。一个Trace ID拥有多个Span ID,而Span ID只属于某一个Trace ID。
除以上三个字段外,还有 Parent Span ID 字段和 Annotation。Parent Span ID 指向当前微服务的父级应用,即上游调用方。Annotation 是用于记录各个调用环节的时间字段。如此一来,就能够通过这些信息将一个完整的调用链路有顺序地整理出来了。
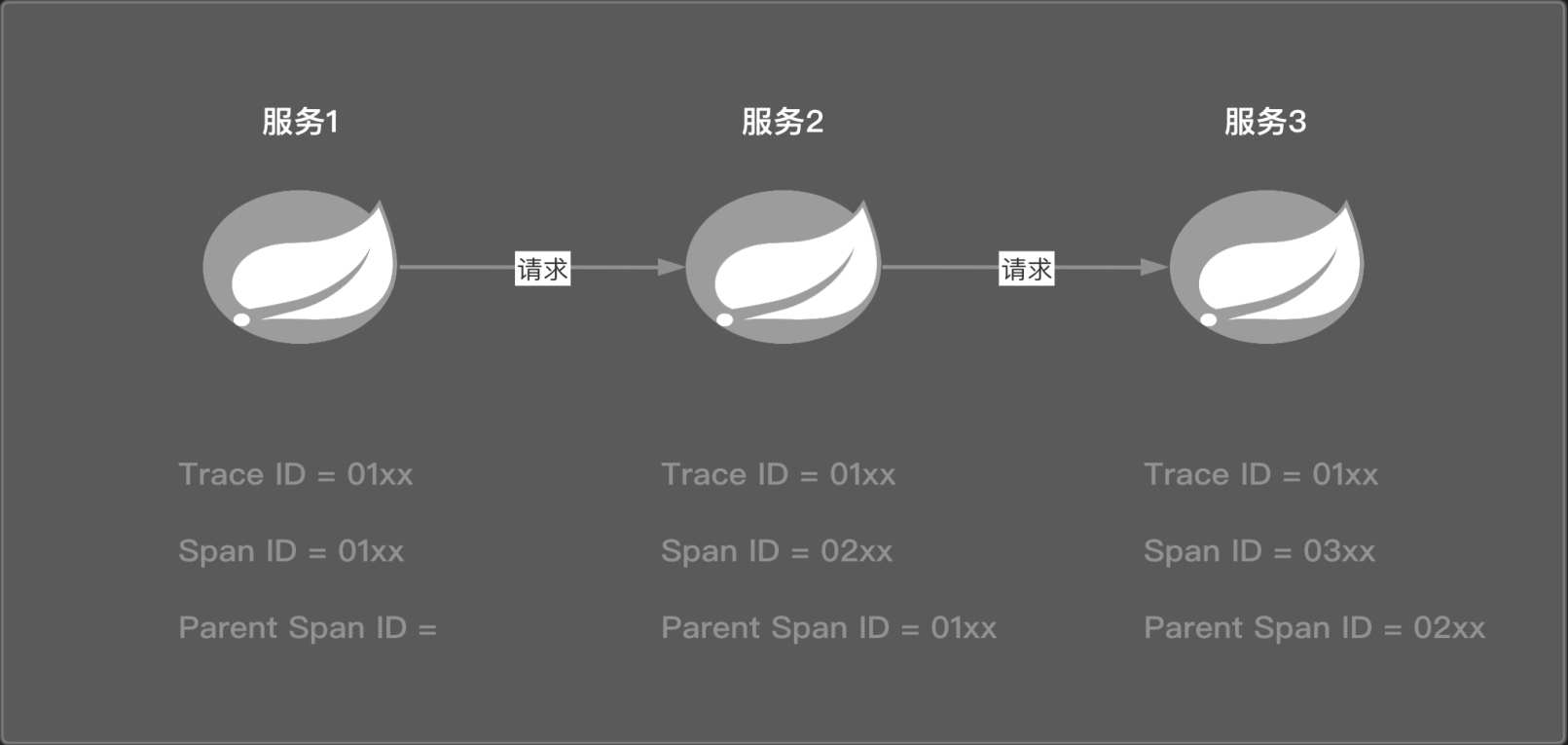
Spring Cloud Sleuth 组件就是根据这几个标识字段来完成链路追踪中的三个重要功能的。其一是标记出一次调用请求中的所有日志(根据 Trace ID),其二是梳理出日志间的前后关系(根据 Span ID 和 Parent Span ID),其三是整理出整个链路及某个单独链路所消耗的时间(根据 Annotation),这样就清晰地整理出一个有序的微服务调用链路。为了能够很好地理解这些字段及调用链路的串联,笔者整理了一张整合 Spring Cloud Sleuth 组件后生成标识字段的示意图,如图 12-2 所示。
该请求涉及三个微服务,分别为服务1、服务2和服务3。在一次完整的调用链路中,不管调用了多少个微服务,Spring Cloud Sleuth 组件都会生成一个 Trace ID 字段贯穿整个链路,图12-2中三个微服务所对应的日志 Trace ID 都是 01xx。服务1是调用链路的起点,它的 Parent Span ID 为空,而起始单元的 Span ID 和 Trace ID 是相同的,其值都是 01xx。对于服务2来说,由于它的父级调用单元是服务1,因此它的 Parent Span ID 指向了服务1的 Span ID,即 01xx。同理,服务3的 Parent Span ID 指向了服务2的 Span ID,即 02xx。当然,图12-2 只是一个简化的流程,在实际项目中可能比这个过程更为复杂,Spring Cloud Sleuth 组件生成的也不止这些字段,主要是让读者理解这个过程。
其底层实现原理就是在调用过程中生成 Trace ID、Span ID 等信息,并且通过请求的 Headers 来传输这些字段。因篇幅有限,这里就不进行拓展讲解了,感兴趣的读者可以查看 Spring Cloud Sleuth 组件的源码。