APPEND:追加新内容到值的末尾
通过调用 APPEND 命令,用户可以将给定的内容追加到字符串键已有值的末尾:
APPEND key suffixAPPEND 命令在执行追加操作之后,会返回字符串值当前的长度作为命令的返回值。
举个例子,对于以下这个名为 description 的键来说:
redis> GET description
"Redis"我们可以通过执行以下命令,将字符串 "is a database" 追加到 description 键已有值的末尾:
redis> APPEND description " is a database"
(integer) 19 -- 追加操作执行完毕之后,值的长度以下是 description 键在执行完追加操作之后的值:
redis> GET description
"Redis is a database"在此之后,我们可以继续执行以下 APPEND 命令,将字符串 "with many different data structure." 追加到 description 键已有值的末尾:
redis> APPEND description " with many different data structure."
(integer) 55现在,description 键的值又变成了以下形式:
redis> GET description
"Redis is a database with many different data structure."图 2-10 展示了 description 键的值是如何随着 APPEND 命令的执行而变化的。

处理不存在的键
如果用户给定的键并不存在,那么 APPEND 命令会先将键的值初始化为空字符串 "",然后再执行追加操作,最终效果与使用 SET 命令为键设置值的情况类似:
redis> GET append_msg -- 键不存在
(nil)
redis> APPEND append_msg "hello" -- 效果相当于执行SET append_msg "hello"
(integer) 5
redis> GET append_msg
"hello"当键有了值之后,APPEND 又会像平时一样,将用户给定的值追加到已有值的末尾:
redis> APPEND append_msg ", how are you?"
(integer) 19
redis> GET append_msg
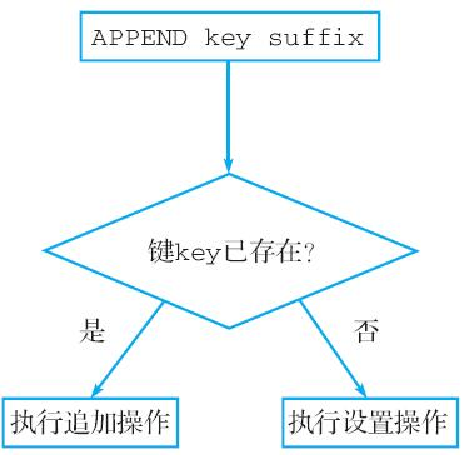
"hello, how are you?"图 2-11 展示了 APPEND 命令是如何根据键是否存在来判断应该执行哪种操作的。
示例:存储日志
很多程序在运行的时候都会生成一些日志,这些日志记录了程序的运行状态以及执行过的重要操作。
例如,以下展示的就是 Redis 服务器运行时输出的一些日志,这些日志记录了 Redis 开始运行的时间,载入数据库所耗费的时长,接收客户端连接所使用的端口号,以及进行数据持久化操作的时间点等信息:
6066:M 06 Jul 17:40:49.611 # Server started, Redis version 3.1.999
6066:M 06 Jul 17:40:49.627 * DB loaded from disk: 0.016 seconds
6066:M 06 Jul 17:40:49.627 * The server is now ready to accept connections on port 6379
6066:M 06 Jul 18:29:20.009 * DB saved on disk为了记录程序运行的状态,或者为了对日志进行分析,我们有时需要把程序生成的日志存储起来。
例如,我们可以使用 SET 命令将日志的生成时间作为键,日志的内容作为值,把上面展示的日志存储到多个字符串键里面:
redis> SET "06 Jul 17:40:49.611" "# Server started, Redis version 3.1.999"
OK
redis> SET "06 Jul 17:40:49.627" "* DB loaded from disk: 0.016 seconds"
OK
redis> SET "06 Jul 17:40:49.627" "* The server is now ready to accept connections on port 6379"
OK
redis> SET "06 Jul 18:29:20.009" "* DB saved on disk"
OK遗憾的是,这种日志存储方式并不理想,主要问题有两个:
-
使用这种方法需要在数据库中创建很多键。因为 Redis 每创建一个键就需要消耗一定的额外资源(overhead)来对键进行维护,所以键的数量越多,消耗的额外资源就会越多。
-
这种方法将全部日志分散地存储在不同的键里面,当程序想要对特定的日志进行分析的时候,就需要花费额外的时间和资源去查找指定的日志,这给分析操作带来了麻烦和额外的资源消耗。
代码清单2-5展示了另一种更为方便和高效的日志存储方式,这个程序会把同一天之内产生的所有日志都存储在同一个字符串键里面,从而使用户可以非常高效地取得指定日期内产生的所有日志。
LOG_SEPARATOR = "\n"
class Log:
def __init__(self, client, key):
self.client = client
self.key = key
def add(self, new_log):
"""
将给定的日志储存起来。
"""
new_log += LOG_SEPARATOR
self.client.append(self.key, new_log)
def get_all(self):
"""
以列表形式返回所有日志。
"""
all_logs = self.client.get(self.key)
if all_logs is not None:
log_list = all_logs.split(LOG_SEPARATOR)
log_list.remove("")
return log_list
else:
return []日志存储程序的 add() 方法负责将新日志存储起来。这个方法首先会将分隔符追加到新日志的末尾:
new_log += LOG_SEPARATOR然后调用 APPEND 命令,将新日志追加到已有日志的末尾:
self.client.append(self.key, new_log)举个例子,如果用户输入的日志是:
"this is log1"那么 add() 方法首先会把分隔符 "\n" 追加到这行日志的末尾,使之变成:
"this is log1\n"然后调用以下命令,将新日志追到已有日志的末尾:
APPEND key "this is log1\n"负责获取所有日志的 get_all() 方法比较复杂,因为它不仅需要从字符串键里面取出包含了所有日志的字符串值,还需要从这个字符串值里面分割出每一条日志。首先,这个方法使用 GET 命令从字符串键里面取出包含了所有日志的字符串值:
all_logs = self.client.get(self.key)接着,程序会检查 all_logs 这个值是否为空。如果为空则表示没有日志被存储,程序直接返回空列表 “[]” 作为 get_all() 方法的执行结果;如果值不为空,那么程序将调用 Python 的 split() 方法对字符串值进行分割,并将分割结果存储到 log_list 列表里面:
log_list = all_logs.split(LOG_SEPARATOR)因为 split() 方法会在结果中包含一个空字符串,而我们并不需要这个空字符串,所以程序还会调用 remove() 方法,将空字符串从分割结果中移除,使得 log_list 列表中只保留被分割的日志:
log_list.remove("")在此之后,程序只需要将包含了多条日志的 log_list 列表返回给调用者就可以了:
return log_list举个例子,假设我们使用 add() 方法,在一个字符串键里面存储了 "this is log1"、"this is log2"、"this is log3" 这 3 条日志,那么 get_all() 方法在使用 GET 命令获取字符串键的值时,将得到以下结果:
"this is log1\nthis is log2\nthis is log3"在使用 split(LOG_SEPARATOR)方法对这个结果进行分割之后,程序将得到一个包含 4 个元素的列表,其中列表最后的元素为空字符串:
["this is log1", "this is log2", "this is log3", ""]在调用 remove("") 方法移除列表中的空字符串之后,列表里面就只会包含被存储的日志:
["this is log1", "this is log2", "this is log3"]这时 get_all() 方法只需要把这个列表返回给调用者就可以了。
以下代码展示了这个日志存储程序的使用方法:
>>> from redis import Redis
>>> from log import Log
>>> client = Redis(decode_responses=True)
>>> # 按日期归类日志
>>> log = Log(client, "06 Jul")
>>> # 存储日志
>>> log.add("17:40:49.611 # Server started, Redis version 3.1.999")
>>> log.add("17:40:49.627 * DB loaded from disk: 0.016 seconds")
>>> log.add("17:40:49.627 * The server is now ready to accept connections on port 6379")
>>> log.add("18:29:20.009 * DB saved on disk")
>>> # 以列表形式返回所有日志
>>> log.get_all()
['17:40:49.611 # Server started, Redis version 3.1.999', '17:40:49.627 * DB loaded from disk: 0.
016 seconds', '17:40:49.627 * The server is now ready to accept connections on port 6379', '18:2
9:20.009 * DB saved on disk']
>>> # 单独打印每条日志
>>> for i in log.get_all():
... print(i)
...
17:40:49.611 # Server started, Redis version 3.1.999
17:40:49.627 * DB loaded from disk: 0.016 seconds
17:40:49.627 * The server is now ready to accept connections on port 6379
18:29:20.009 * DB saved on disk