ZREMRANGEBYLEX:移除位于字典序指定范围内的成员
对于按照字典序排列的有序集合,用户可以使用 ZREMRANGEBYLEX 命令去移除有序集合中位于字典序指定范围内的成员:
ZREMRANGEBYLEX sorted_set min max这个命令的 min 参数和 max 参数的格式与 ZRANGEBYLEX 命令以及 ZLEXCOUNT 命令接受的 min 参数和 max 参数的格式完全相同。
ZREMRANGEBYLEX 命令在移除用户指定的成员之后,将返回被移除成员的数量作为命令的返回值。
作为例子,以下代码展示了如何移除 words 有序集合中所有以字母 "b" 开头的成员:
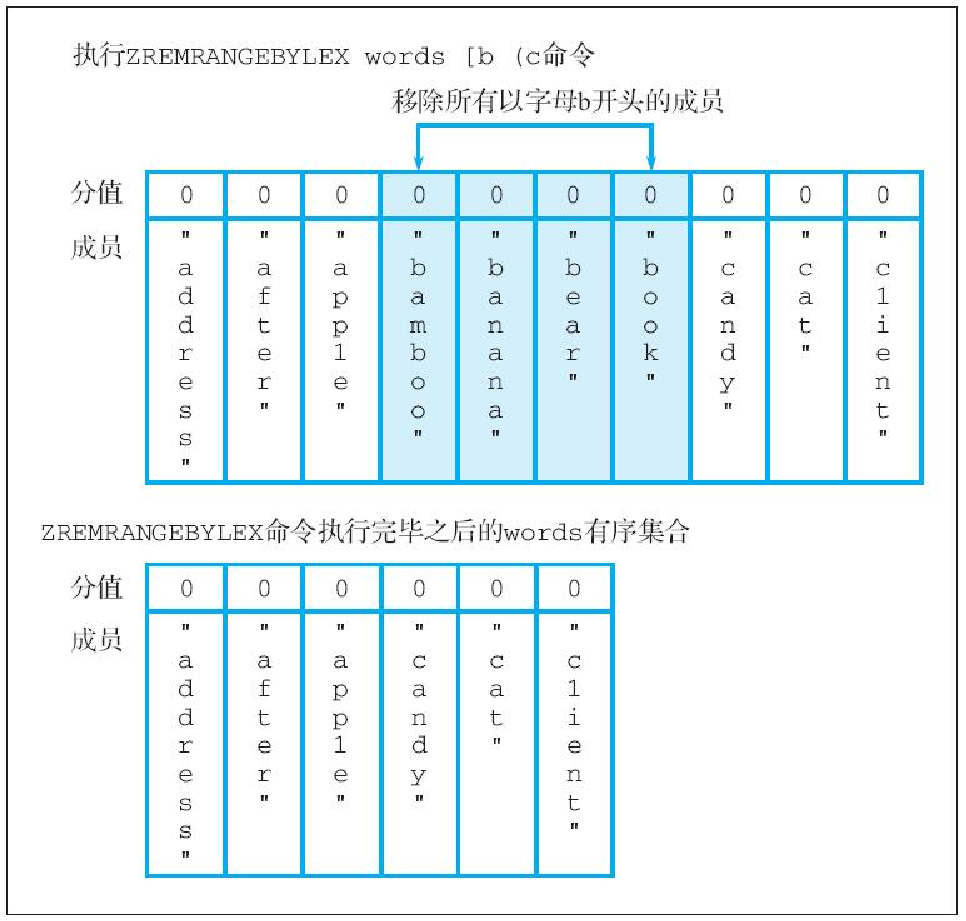
redis> ZREMRANGEBYLEX words [b (c
(integer) 4 -- 有4个成员被移除了图6-38 展示了 words 有序集合在 ZREMRANGEBYLEX 命令执行前后发生的变化。
其他信息
-
复杂度:O(log(N)+M),其中 N 为有序集合包含的成员数量,M 为被移除成员的数量。
-
版本要求:ZREMRANGEBYLEX 命令从 Redis 2.8.9 版本开始可用。
示例:自动补全
包含大量信息的网站常常会在搜索或者查找功能上提供自动补全特性,这一特性可以帮助用户更快速地找到他们想要的信息。比如,当我们在搜索引擎中输入 “黄” 字的时候,搜索引擎的自动补全特性就会列出一些比较著名的以 “黄” 字开头的人或者物,以便用户可以更快速地找到相关信息,如图6-39 所示。

代码清单6-4 展示了一个使用有序集合实现的自动补全程序,这个程序可以提供类似图6-39所示的自动补全效果。
class AutoComplete:
def __init__(self, client):
self.client = client
def feed(self, content, weight=1):
"""
根据用户输入的内容构建自动补全结果,
其中 content 参数为内容本身,而可选的 weight 参数则用于指定内容的权重值。
"""
for i in range(1, len(content)):
key = "auto_complete::" + content[:i]
self.client.zincrby(key, weight, content)
def hint(self, prefix, count):
"""
根据给定的前缀 prefix ,获取 count 个自动补全结果。
"""
key = "auto_complete::" + prefix
return self.client.zrevrange(key, 0, count-1)这个自动补全程序的 feed() 方法接受给定的内容和权重值作为参数,并以此来构建自动补全结果。比如,如果我们调用 feed("黄晓朋",5000),那么程序将拼接出以下 3 个键:
auto_complete::黄
auto_complete::黄晓
auto_complete::黄晓朋然后通过执行以下这 3 个命令,将自动补全结果 “黄晓朋” 及其权重 5000 添加到相应的有序集合里面:
ZINCRBY auto_complete::黄 5000 "黄晓朋"
ZINCRBY auto_complete::黄晓 5000 "黄晓朋"
ZINCRBY auto_complete::黄晓朋 5000 "黄晓朋"这样做的结果是,程序会把所有 “黄” 字开头的名字按权重大小有序地存储到 auto_complete::黄 这个有序集合里面,而以 “黄晓” 开头的名字则会按照权重大小有序地存储在 auto_complete::黄晓 这个有序集合里面,诸如此类。
相对地,当我们想要找出所有以 “黄” 字开头的名字时,只需要调用 hint() 方法,程序就会使用 ZREVRANGE 命令从 auto_complete::黄 有序集合中取出相应的自动补全结果。
作为例子,现在让我们载入这个自动补全程序:
>>> from redis import Redis
>>> from auto_complete import AutoComplete
>>> client = Redis(decode_responses=True)
>>> ac = AutoComplete(client)然后向程序输入一些名字以及这些名字的权重:
>>> ac.feed("黄健宏", 30)
>>> ac.feed("黄健强", 3000)
>>> ac.feed("黄晓朋", 5000)
>>> ac.feed("张三", 2500)
>>> ac.feed("李四", 1700)在此之后,如果我们以 “黄” 字为前缀调用 hint() 方法,程序就会列出所有以 “黄” 字开头的名字:
>>> for name in ac.hint("黄", 10):
... print(name)
...
黄晓朋
黄健强
黄健宏接着,如果我们以 “黄健” 二字为前缀调用 hint() 方法,那么程序将列出两个以 “黄健” 二字为开头的名字:
>>> for name in ac.hint("黄健", 10):
... print(name)
...
黄健强
黄健宏再次提醒一下,因为 hint() 方法是按照权重的大小有序地返回结果的,所以权重较高的 “黄健强” 会排在前面,而权重较低的 “黄健宏” 则会排在后面。