XREAD:以阻塞或非阻塞方式获取流元素
除了 XRANGE 命令和 XREVRANGE 命令之外,Redis 还提供了 XREAD 命令用于获取流中元素:
XREAD [BLOCK ms] [COUNT n] STREAMS stream1 stream2 stream3 ... id1 id2 id3 ...与 XRANGE 命令和 XREVRANGE 命令可以从两个方向对流进行迭代不同,XREAD 命令只能从一个方向对流进行迭代,但是它提供了更简单的迭代 API,支持同时对多个流进行迭代,并且能够以阻塞和非阻塞两种方式执行,本节接下来将对这个命令做更详细的介绍。
从多个流中获取大于指定ID的元素
XREAD 命令最基础的用法就是从多个给定流中取出大于指定 ID 的多个元素,其中紧跟在 STREAMS 选项之后的就是流的名字以及与之相对应的元素 ID:
XREAD STREAMS stream1 stream2 stream3 ... id1 id2 id3 ...在调用 XREAD 命令时,用户需要先给定所有想要从中获取元素的流,然后再给出与各个流相对应的 ID。除此之外,用户还可以通过可选的 COUNT 选项限制命令对于每个流最多可以返回多少个元素:
XREAD [COUNT n] STREAMS stream1 stream2 stream3 ... id1 id2 id3 ...注意,我们把 COUNT 选项放在了 STREAMS 选项的前面,这是因为 STREAMS 选项是一个可变参数选项,它接受的参数数量是不固定的,所以它必须是 XREAD 命令的最后一个选项。
作为例子,以下代码展示了如何从流 s1 中取出最多三个 ID 大于 1000000000000 的元素:
redis> XREAD COUNT 3 STREAMS s1 1000000000000
1) 1) "s1" -- 元素的来源流
2) 1) 1) 1100000000000-0 -- 第一个元素及其ID
2) 1) "k1" -- 第一个元素包含的键值对
2) "v1"
2) 1) 1200000000000-0 -- 第二个元素
2) 1) "k2"
2) "v2"
3) 1) 1300000000000-0 -- 第三个元素
2) 1) "k3"
2) "v3"这个命令调用返回了一个只包含单个项的列表,而这个列表项又包含了两个子项,其中:
-
第一个子项 "s1" 表明了这个列表项中的元素都是从流 s1 里面获取的。
-
第二个子项包含了三个列表项,其中每一个列表项都是一个流元素。
与此类似,以下代码展示了如何从流 s1、s2 和 s3 中各取出一个 ID 大于 1000000000000 的元素:
redis> XREAD COUNT 1 STREAMS s1 s2 s3 1000000000000 1000000000000 1000000000000
1) 1) "s1" -- 这个元素来源于流s1
2) 1) 1) 1100000000000-0
2) 1) "k1"
2) "v1"
2) 1) "s2" -- 这个元素来源于流s2
2) 1) 1) 1531743117644-0
2) 1) "k1"
2) "v1"
3) 1) "s3" -- 这个元素来源于流s3
2) 1) 1) 1531748220373-0
2) 1) "k1"
2) "v1"这次的 XREAD 命令调用返回了三个列表项,其中每个列表项包含的元素都来自于不同的流。
最后,如果用户尝试使用 XREAD 命令去获取一个不存在的流,或者给定的 ID 超过了流中已有元素的最大 ID,那么命令将返回一个空值作为结果:
redis> XREAD STREAMS not-exists-stream 1000000000000 -- 流不存在
(nil)
redis> XREAD STREAMS s1 2000000000000 -- 给定ID过大
(nil)迭代流
在前面的内容中,我们学习了如何使用 XRANGE 命令和 XREVRANGE 命令去迭代一个流。与此类似,通过 XREAD 命令,我们同样可以对一个或多个流进行迭代,具体方法如下:
-
将表示流起点的特殊 ID 0-0(或者它的简写 0)作为 ID 传入 XREAD 命令,并通过 COUNT 选项读取流最开头的 N 个元素。
-
使用命令返回的最后一个元素的 ID 作为参数,再次调用带有 COUNT 选项的 XREAD 命令。
-
重复执行步骤 2,直到命令返回空值或者命令返回元素的数量少于指定数量为止。
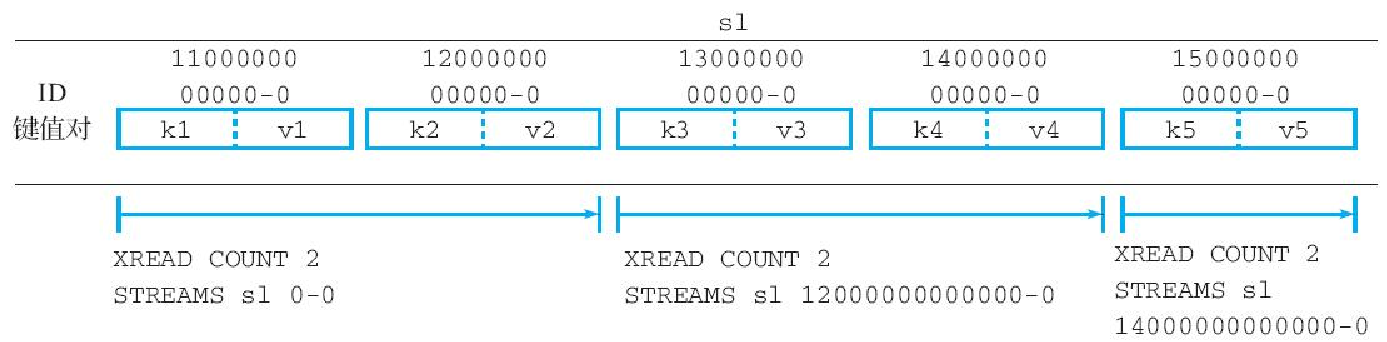
举个例子,假设我们想要以两个元素为步进迭代流 s1,那么首先需要执行以下命令:
redis> XREAD COUNT 2 STREAMS s1 0-0
1) 1) "s1"
2) 1) 1) 1100000000000-0
2) 1) "k1"
2) "v1"
2) 1) 1200000000000-0
2) 1) "k2"
2) "v2"这个命令会从流 s1 里面取出位于流最开始的两个元素,它们的 ID 分别为 1100000000000-0 和 1200000000000-0。为了进行下一次迭代,我们需要将后一个 ID 用作参数,继续调用 XREAD 命令:
redis> XREAD COUNT 2 STREAMS s1 1200000000000-0
1) 1) "s1"
2) 1) 1) 1300000000000-0
2) 1) "k3"
2) "v3"
2) 1) 1400000000000-0
2) 1) "k4"
2) "v4"与之前一样,这次的调用也返回了两个流元素。为了继续进行第三次迭代,我们需要将 ID 1400000000000-0 用作参数继续调用 XREAD 命令:
redis> XREAD COUNT 2 STREAMS s1 1400000000000-0
1) 1) "s1"
2) 1) 1) 150000000000-0
2) 1) "k5"
2) "v5"注意,与之前两次迭代都返回了两个元素不一样,虽然这次迭代也请求获取两个元素,但命令却只返回了一个元素,这表明对整个流的迭代已经完成了。为了证实这一点,我们可以使用 ID 150000000000-0 作为输入,再次调用 XREAD 命令:
redis> XREAD COUNT 2 STREAMS s1 150000000000-0
(nil)从命令返回的结果可以看出,流 s1 中不存在任何 ID 大于 150000000000-0 的元素。
图10-14展示了上述整个迭代过程。
两种迭代方式的区别
使用 XREAD 命令对流进行迭代,与使用 XRANGE 命令、XREVRANGE 命令对流进行迭代,这两种迭代方式之间主要有 4 点区别。
首先,XRANGE 命令和 XREVRANGE 命令接受 ID 区间范围作为输入,而 XREAD 命令接受单个 ID 作为输入,并且前者在每次进行后续迭代时,都需要手动计算下一次迭代的起始 ID,而后者只需要将上一次迭代返回的最后元素的 ID 用作输入即可。两者比较起来,明显是 XREAD 命令更方便。
其次,用户使用 XRANGE 命令和 XREVRANGE 命令,可以按照从头到尾和从尾到头两个方向对流进行迭代,而 XREAD 命令只能从流的开头向结尾进行迭代。
然后,因为 XREAD 命令可以一次接受多个流作为输入,所以它可以同时迭代多个流,而 XRANGE 命令和 XREVRANGE 命令每次只能迭代一个流。
最后,因为 XREAD 命令具备阻塞功能,所以它既可以以同步方式执行,也可以以异步方式执行,而 XRANGE 命令和 XREVRANGE 命令只能以同步方式执行。
表10-1 列举了这 3 个迭代命令各自的特点。

阻塞
通过使用 BLOCK 选项并给定一个毫秒精度的超时时间作为参数,用户能够以可阻塞的方式执行 XREAD 命令:
XREAD [BLOCK ms] [COUNT n] STREAMS stream1 stream2 stream3 ... id1 id2 id3 ...BLOCK 选项的值可以是任何大于等于 0 的数值,给定 0 则表示阻塞直到出现可返回的元素为止。根据用户给定的流是否拥有符合条件的元素,带有 BLOCK 选项的 XREAD 命令的行为也会有所不同。
首先,如果在用户给定的流中,有一个或多个流拥有符合条件、可供读取的元素,那么 XREAD 命令将直接返回这些元素而不会进入阻塞状态。与不带 BLOCK 选项的 XREAD 命令一样,这种情况下的 XREAD 命令会根据用户给定的 COUNT 选项去限制每个流返回元素的数量。
比如在以下代码中,我们就调用 XREAD 命令尝试去读取流 s1、s2 和 bs1:
redis> XREAD BLOCK 10000000 COUNT 2 STREAMS s1 s2 bs1 0 0 0
1) 1) "s1"
2) 1) 1) 1100000000000-0
2) 1) "k1"
2) "v1"
2) 1) 1200000000000-0
2) 1) "k2"
2) "v2"
2) 1) "s2"
2) 1) 1) 1531751993870-0
2) 1) "k1"
2) "v1"
2) 1) 1531751997935-0
2) 1) "k2"
2) "v2"虽然流 bs1 没有可供读取的元素,但是由于流 s1 和 s2 都拥有可供读取的元素,所以命令没有进入阻塞状态,而是直接返回了可供读取的元素,并且元素的数量没有超过 COUNT 选项的限制。
如果用户在执行带有 BLOCK 选项的 XREAD 命令时,给定的所有流都不存在可供读取的元素,那么命令将进入阻塞状态。如果在给定的阻塞时长之内有一个可供读取的元素出现,那么 Redis 将把这个元素分发给所有因为该元素而被阻塞的客户端,这种情况下的 XREAD 命令会无视用户给定的 COUNT 选项,只返回一个元素。
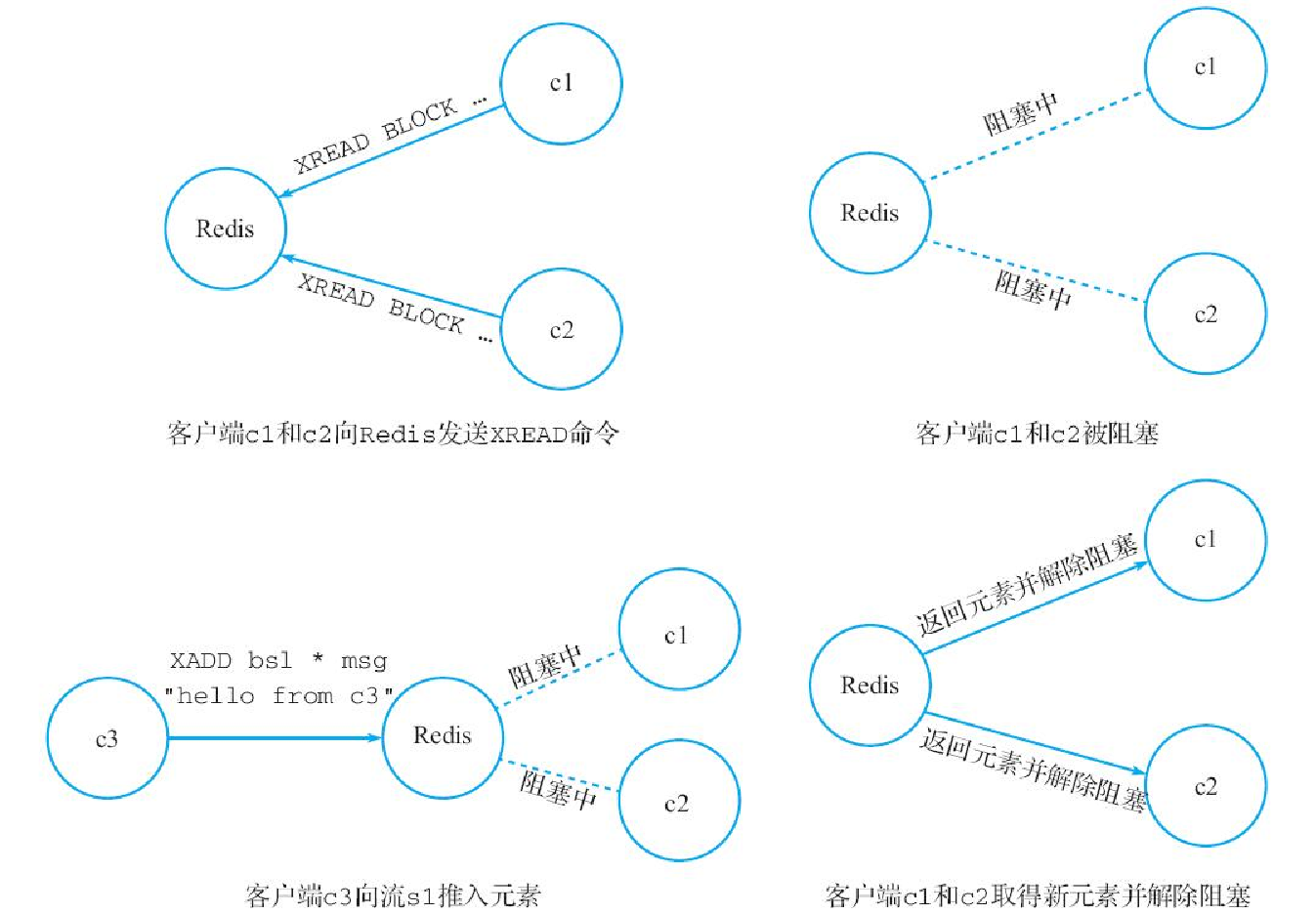
举个例子,假设现在有 c1、c2 两个客户端,它们都因为流 s1 和流 s2 没有可供读取的元素而被阻塞:
c1> XREAD BLOCK 10000000 COUNT 2 STREAMS bs1 bs2 0 0
c2> XREAD BLOCK 10000000 COUNT 2 STREAMS bs1 bs2 0 0如果在这两个客户端被阻塞期间,客户端 c3 向流 s1 推入一个新元素:
c3> XADD bs1 * msg "hello from c3"
1531814693349-0那么 c1 和 c2 的阻塞将被解除,并且它们都会得到以下回复:
1) 1) "bs1" -- 元素的来源流
2) 1) 1) 1531814693349-0 -- 元素的ID
2) 1) "msg" -- 元素的键值对
2) "hello from c3"
(25.99s) -- 客户端被阻塞的时长(redis-cli客户端专属)图10-15展示了这两个客户端从被阻塞到解除阻塞的整个过程。
最后,如果客户端因为 XREAD 命令而被阻塞,并且它未能在指定的超时时限内读取到任何元素,那么客户端将返回一个空值:
redis> XREAD BLOCK 1000 COUNT 2 STREAMS not-exists-stream 0
(nil)
(1.05s)只获取新出现的元素
在以阻塞方式获取流元素的时候,常常会出现这样一种场景,我们需要从当前时刻开始获取流中新出现的元素。换句话说,我们想要 “监听” 指定的流,并在这些流出现新元素时返回这些元素。虽然用户可以通过先使用 XREVRANGE 命令获取流当前的最后一个元素,然后再将该元素的 ID 作为输入,调用启用了阻塞功能的 XREAD 命令来达到 “只获取新出现元素” 的目的,但重复执行这种操作将变得非常麻烦,并且可能引发竞争条件。
为了解决上述问题,Redis 为 XREAD 命令提供了特殊 ID 参数 $ 符号,用户在执行阻塞式的 XREAD 命令时,只要将 $ 符号用作 ID 参数的值,XREAD 命令就会只获取给定流在命令执行之后新出现的元素:
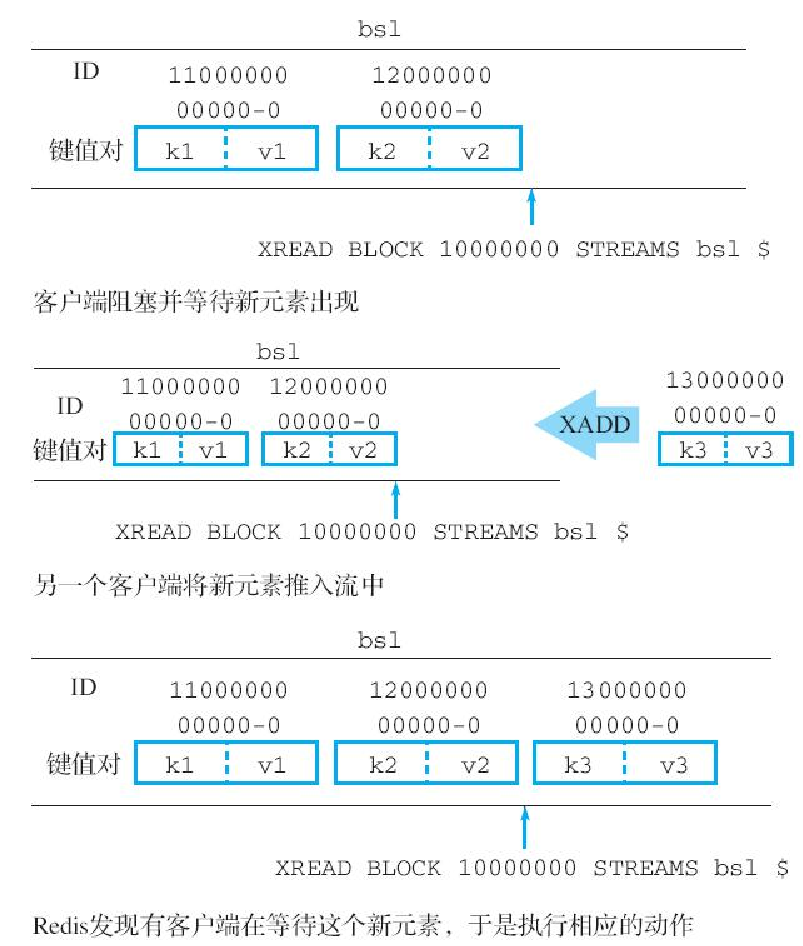
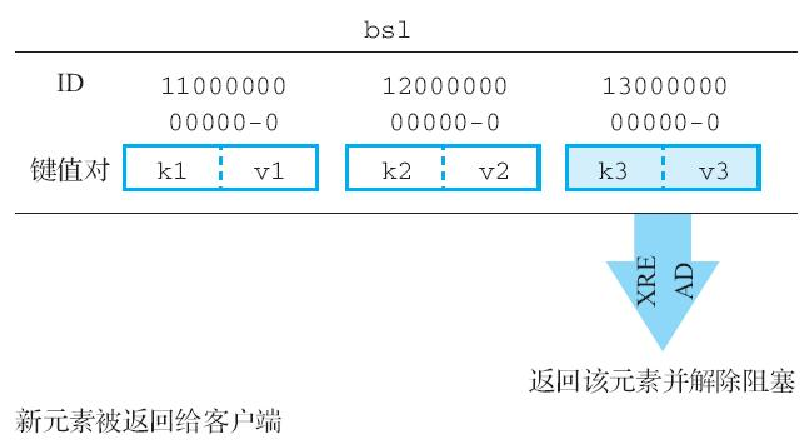
XREAD BLOCK ms STREAMS stream1 stream2 stream3 ... $ $ $ ...举个例子,假设我们现在想要获取流 bs1 接下来将要出现的第一个新元素,那么可以执行以下命令:
redis> XREAD BLOCK 10000000 STREAMS bs1 $执行这个调用的客户端将进入阻塞状态。在此之后,如果在给定的时限内,有另一个客户端向流 s1 推入新元素,那么原客户端的阻塞状态就会被解除,并返回被推入的元素,就像这样:
1) 1) "bs1" -- 元素的来源流
2) 1) 1) 1300000000000-0 -- 元素的ID
2) 1) "k3" -- 元素的键值对
2) "v3"
(2.64s) -- 客户端被阻塞的时长图10-16展示了客户端从被阻塞到获取新元素并解除阻塞的整个过程。
其他信息
-
复杂度:对于用户给定的每个流,获取流元素的复杂度为 O(log(N)M),其中 N 为流包含的元素数量,M 为被获取的元素数量。因此对于用户给定的 I 个流,获取流元素的总复杂度为 O((log(N)+M)*I)。
-
版本要求:XREAD 命令从 Redis 5.0.0 版本开始可用。
示例:消息队列
介绍了 Redis 流的基本功能之后,现在是时候使用这些功能来构建一些实际的应用了。消息队列作为流的典型应用之一,具有非常好的示范性,因此我们将使用 Redis 流的相关功能构建一个消息队列应用,这个消息队列与我们之前使用其他 Redis 数据结构构建的消息队列具有相似的功能。
代码清单10-1展示了一个具有基本功能的消息队列实现:
-
代码最开头的是几个转换函数,它们负责对程序的相关输入输出进行转换和格式化。
-
MessageQueue 类用于实现消息队列,它的添加消息、移除消息以及返回消息数量 3 个方法分别使用了流的 XADD 命令、XDEL 命令和 XLEN 命令。
-
消息队列的两个获取方法 get_message() 和 get_by_range() 分别以两种形式调用了流的 XRANGE 命令。
-
最后,用于迭代消息的 iterate() 方法使用了 XREAD 命令对流进行迭代。
def reconstruct_message_list(message_list):
"""
为了让多条消息能够以更结构化的方式返回给调用者,
将 Redis 返回的多条消息从原来的格式:
[(id1, {k1:v1, k2:v2, ...}), (id2, {k1:v1, k2:v2, ...}), ...]
转换成以下格式:
[{id1: {k1:v1, k2:v2, ...}}, {id2: {k1:v1, k2:v2, ...}}, ...]
"""
result = []
for id, kvs in message_list:
result.append({id: kvs})
return result
def get_message_from_nested_list(lst):
"""
从嵌套列表中取出消息本体。
"""
return lst[0][1]
class MessageQueue:
"""
使用 Redis 流实现的消息队列。
"""
def __init__(self, client, stream_key):
self.client = client
self.stream = stream_key
def add_message(self, key_value_pairs):
"""
将给定的键值对存入到消息里面,并返回相应的消息 ID 。
"""
return self.client.xadd(self.stream, key_value_pairs)
def get_message(self, message_id):
"""
根据给定的消息 ID 返回相应的消息,如果消息不存在则返回 None 。
"""
reply = self.client.xrange(self.stream, message_id, message_id)
if len(reply) == 1:
return get_message_from_nested_list(reply)
def remove_message(self, message_id):
"""
根据给定的消息 ID 删除相应的消息,如果消息不存在则忽略该动作。
"""
self.client.xdel(self.stream, message_id)
def len(self):
"""
返回消息队列的长度。
"""
return self.client.xlen(self.stream)
def get_by_range(self, start_id, end_id, max_item=10):
"""
根据给定的 ID 区间范围返回队列中的消息。
"""
reply = self.client.xrange(self.stream, start_id, end_id, max_item)
return reconstruct_message_list(reply)
def iterate(self, start_id=0, max_item=10):
"""
对消息队列进行迭代,返回最多 N 条大于给定 ID 的消息。
"""
reply = self.client.xread({self.stream: start_id}, max_item)
if len(reply) == 0:
return list()
else:
messages = get_message_from_nested_list(reply)
return reconstruct_message_list(messages)对于这个消息队列实现,我们可以通过执行以下代码,创建出它的实例:
>>> from redis import Redis
>>> from message_queue import MessageQueue
>>> client = Redis(decode_responses=True)
>>> mq = MessageQueue(client, "mq")然后通过执行以下代码,向队列中添加 10 条消息:
>>> for i in range(10):
... key = "key{0}".format(i)
... value = "value{0}".format(i)
... msg = {key:value}
... mq.add_message(msg)
...
'1554113926280-0'
'1554113926280-1'
'1554113926281-0'
'1554113926281-1'
'1554113926281-2'
'1554113926281-3'
'1554113926281-4'
'1554113926281-5'
'1554113926281-6'
'1554113926282-0'还可以根据 ID 获取指定的消息,或者使用 get_by_range() 方法同时获取多条消息:
>>> mq.get_message('1554113926280-0')
{'key0': 'value0'}
>>> mq.get_message('1554113926280-1')
{'key1': 'value1'}
>>> mq.get_by_range("-", "+", 3)
[{'1554113926280-0': {'key0': 'value0'}}, {'1554113926280-1': {'key1': 'value1'}},
{'1554113926281-0': {'key2': 'value2'}}]或者使用 iterate() 方法对消息队列进行迭代,等等:
>>> mq.iterate(0, 3)
[{'1554113926280-0': {'key0': 'value0'}}, {'1554113926280-1': {'key1': 'value1'}},
{'1554113926281-0': {'key2': 'value2'}}]
>>> mq.iterate('1554113926281-0', 3)
[{'1554113926281-1': {'key3': 'value3'}}, {'1554113926281-2': {'key4': 'value4'}},
{'1554113926281-3': {'key5': 'value5'}}]