RDB持久化
RDB持久化是Redis默认使用的持久化功能,该功能可以创建出一个经 过压缩的二进制文件,其中包含了服务器在各个数据库中存储的键值 对数据等信息。RDB持久化产生的文件都以.rdb后缀结尾,其中rdb代 表Redis DataBase(Redis数据库)。
Redis提供了多种创建RDB文件的方法,用户既可以使用SAVE命令或者 BGSAVE命令手动创建RDB文件,也可以通过设置save配置选项让服务器 在满足指定条件时自动执行BGSAVE命令。本节接下来将分别介绍这3种 RDB文件的创建方法。
SAVE:阻塞服务器并创建RDB文件
用户可以通过执行SAVE命令,要求Redis服务器以同步方式创建出一个 记录了服务器当前所有数据库数据的RDB文件。SAVE命令是一个无参数 命令,它在创建RDB文件成功时将返回OK作为结果:
redis> SAVE
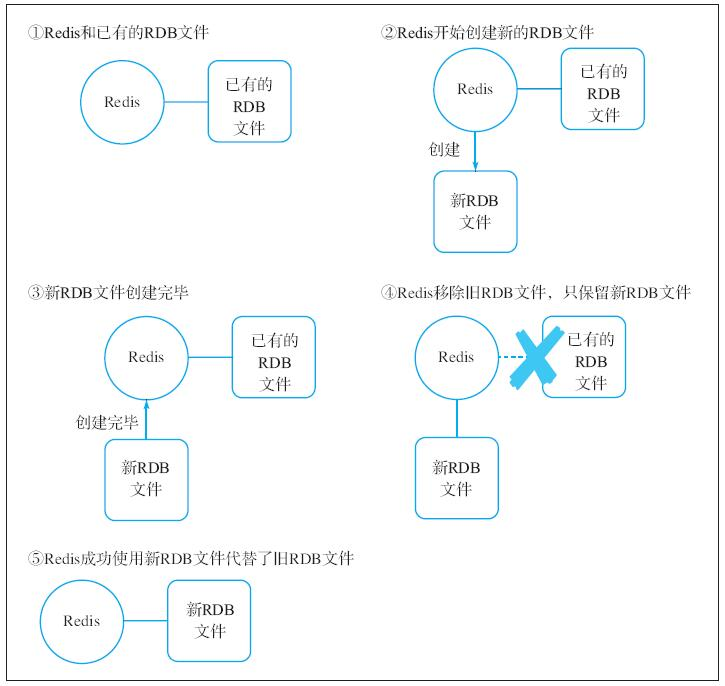
OK接收到SAVE命令的Redis服务器将遍历数据库包含的所有数据库,并将 各个数据库包含的键值对全部记录到RDB文件中。在SAVE命令执行期 间,Redis服务器将阻塞,直到RDB文件创建完毕为止。如果Redis服务 器在执行SAVE命令时已经拥有了相应的RDB文件,那么服务器将使用新 创建的RDB文件代替已有的RDB文件,这个过程如图15-1所示。
其他信息
-
复杂度:O(N),其中N为Redis服务器所有数据库包含的键值对总数量。
-
版本要求:SAVE命令从Redis 1.0.0版本开始可用。
BGSAVE:以非阻塞方式创建RDB文件
因为SAVE命令在执行时会阻塞整个服务器,所以用户在使用该命令创 建RDB文件期间将无法为其他客户端提供服务。为了解决这个问题, Redis提供了SAVE命令的异步版本BGSAVE命令:这个命令与SAVE命令一 样都是无参数命令,它与SAVE命令的不同之处在于,BGSAVE不会直接 使用Redis服务器进程创建RDB文件,而是使用子进程创建RDB文件。
当Redis服务器接收到用户发送的BGSAVE命令时,将执行以下操作:
1)创建一个子进程。 2)子进程执行SAVE命令,创建新的RDB文件。 3)RDB文件创建完毕之后,子进程退出并通知Redis服务器进程(父进 程)新RDB文件已经完成。 4)Redis服务器进程使用新RDB文件替换已有的RDB文件。
图15-2展示了这一执行过程。
因为BGSAVE命令创建RDB文件的操作是由子进程以异步方式执行的,所 以当用户在客户端执行这个命令时,服务器将立即向客户端返回OK, 然后才会在后台开始具体的RDB文件创建操作:
redis> BGSAVE
Background saving started因为BGSAVE命令是以异步方式执行的,所以Redis服务器在BGSAVE命令 执行期间仍然可以继续处理其他客户端发送的命令请求。不过需要注 意的是,虽然BGSAVE命令不会像SAVE命令那样一直阻塞Redis服务器, 但由于执行BGSAVE命令需要创建子进程,所以父进程占用的内存数量 越大,创建子进程这一操作耗费的时间也会越长,因此Redis服务器在 执行BGSAVE命令时,仍然可能会由于创建子进程而被短暂地阻塞。
其他信息
-
复杂度:O(N),其中N为Redis服务器所有数据库包含的键值对总数量。
-
版本要求:BGSAVE命令从Redis 1.0.0版本开始可用。
通过配置选项自动创建RDB文件
用户除了可以使用SAVE命令和BGSAVE命令手动创建RDB文件之外,还可 以通过设置save选项,让Redis服务器在满足指定条件时自动执行 BGSAVE命令:
save <seconds> <changes>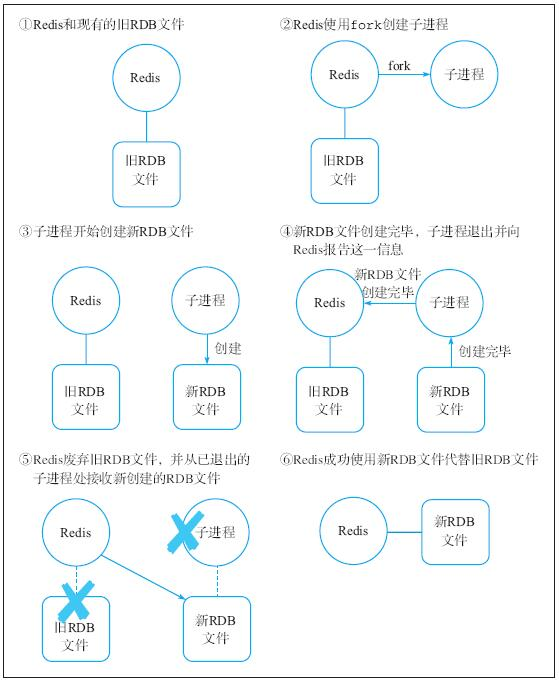
save选项接受seconds和changes两个参数,前者用于指定触发持久化 操作所需的时长,而后者则用于指定触发持久化操作所需的修改次 数。简单来说,如果服务器在seconds秒之内,对其包含的各个数据库 总共执行了至少changes次修改,那么服务器将自动执行一次BGSAVE命 令。
比如,如果我们向服务器提供以下选项:
save 60 10000那么当“服务器在60s秒之内至少执行了10000次修改”这一条件被满足时,服务器就会自动执行一次BGSAVE命令。
-
同时使用多个save选项
Redis允许用户同时向服务器提供多个save选项,当给定选项中的任意一个条件被满足时,服务器就会执行一次BGSAVE。
比如,如果我们向服务器提供以下选项:
save 6000 1
save 600 100
save 60 10000那么当以下任意一个条件被满足时,服务器就会执行一次BGSAVE命 令: ·在6000s(100min)之内,服务器对数据库执行了至少1次修改。 ·在600s(10min)之内,服务器对数据库执行了至少100次修改。 ·在60s(1min)之内,服务器对数据库执行了至少10000次修改。 注意,为了避免由于同时使用多个触发条件而导致服务器过于频繁地 执行BGSAVE命令,Redis服务器在每次成功创建RDB文件之后,负责自 动触发BGSAVE命令的时间计数器以及修改次数计数器都会被清零并重 新开始计数:无论这个RDB文件是由自动触发的BGSAVE命令创建的,还 是由用户执行的SAVE命令或BGSAVE命令创建的,都是如此。
-
默认设置
RDB持久化是Redis默认使用的持久化方式,如果用户在启动Redis服务 器时,既没有显式地关闭RDB持久化功能,也没有启用AOF持久化功 能,那么Redis默认将使用以下save选项进行RDB持久化:
save 60 10000
save 300 100
save 3600 1SAVE命令和BGSAVE命令的选择
因为SAVE命令在创建RDB文件期间会阻塞Redis服务器,所以如果我们 需要在创建RDB文件的同时让Redis服务器继续为其他客户端服务,那 么就只能使用BGSAVE命令来创建RDB文件。
因为SAVE命令无须创建子进程,它不会因为创建子进程而消耗额外的 内存,所以在维护离线的Redis服务器时,使用SAVE命令能够比使用 BGSAVE命令更快地完成创建RDB文件的工作。
RDB文件结构
在了解了如何创建RDB文件之后,接下来了解一下RDB文件的具体结构。
-
总体结构
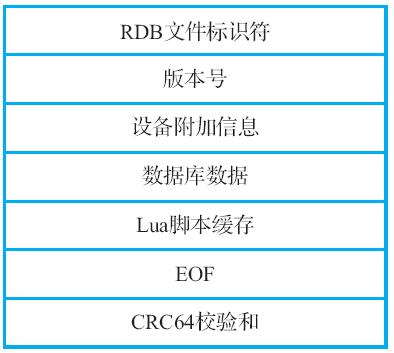 Figure 3. 图15-3 RDB文件的总体结构
Figure 3. 图15-3 RDB文件的总体结构图15-3展示了RDB文件的总体结构,整个文件共分为7个部分。
-
RDB文件标识符 文件最开头的部分为RDB文件标识符,这个标识符的内容为"REDIS"这5 个字符。Redis服务器在尝试载入RDB文件的时候,可以通过这个标识 符快速地判断该文件是否为真正的RDB文件。
-
版本号 跟在RDB文件标识符之后的是RDB文件的版本号,这个版本号是一个字 符串格式的数字,长度为4个字符。目前最新的RDB文件版本为第9版, 因此RDB文件的版本号将为字符串"0009"。不同版本的RDB文件在结构 上都会有一些不同,总的来说,新版RDB文件都会在旧版RDB文件的基 础上添加更多信息,因此RDB文件的版本越新,RDB文件的结构就越复 杂。
关于RDB文件,需要说明的另外一点是新版Redis服务器总是能够向下 兼容旧版Redis服务器生成的RDB文件。比如,生成第9版RDB文件的 Redis 5.0既能够正常读入由Redis 4.0生成的第8版RDB文件,也能够读入由Redis 3.2生成的第7版RDB文件,甚至更旧版本的RDB文件也是 可以的。与此相反,如果Redis服务器生成的是较旧版本的RDB文件, 那么它是无法读入更新版本的RDB文件的。比如,生成第8版RDB文件的 Redis 4.0就不能读入由Redis 5.0生成的第9版RDB文件。
-
设备附加信息 RDB文件的设备附加信息部分记录了生成RDB文件的Redis服务器及其所 在平台的信息,比如服务器的版本号、宿主机器的架构、创建RDB文件 时的时间戳、服务器占用的内存数量等。
-
数据库数据 RDB文件的数据库数据部分记录了Redis服务器存储的0个或任意多个数 据库的数据,当这个部分包含多数个数据库的数据时,各个数据库的 数据将按照数据库号码从小到大进行排列,比如,0号数据库的数据将 排在最前面,紧接着是1号数据库的数据,然后是2号数据库的数据, 以此类推,图15-4展示了这一排列顺序。
-
Lua脚本缓存 如果Redis服务器启用了复制功能,那么服务器将在RDB文件的Lua脚本 缓存部分保存所有已被缓存的Lua脚本。这样一来,从服务器在载入 RDB文件完成数据同步之后,就可以继续执行主服务器发来的EVALSHA 命令了。
-
EOF RDB文件的EOF部分用于标识RDB正文内容的末尾,它的实际值为二进制 值0xFF。当Redis服务器读取到EOF的时候,它知道RDB文件的正文部分 已经全部读取完毕了。
-
CRC64校验和 RDB文件的末尾是一个以无符号64位整数表示的CRC64校验和,比如 5097628732947693614。Redis服务器在读入RDB文件时会通过这个校验 和来快速地检查RDB文件是否有出错或者损坏的情况出现。
-
-
数据库信息结构
前面提到过,RDB文件的数据库数据部分包含了任意多个数据库的数 据,其中每个数据库都由图15-5所示的4个部分组成。


首先,第一部分以数字形式记录了数据库的号码,比如0。Redis服务 器在读入RDB文件数据时,会根据这个号码切换至相应的数据库,从而 确保键值对会被载入正确的数据库中。
在之后的两个部分,RDB文件会使用两个数字,分别记录数据库包含的 键值对总数量以及数据库中带有过期时间的键值对数量。Redis服务器 将根据这两个数字,以尽可能优化的方式创建数据库的内部数据结 构。
在最后一个部分,RDB文件将以无序方式记录数据库包含的所有键值 对。具体来说,数据库中的每个键值对都会被划分为最多5个部分,如 图15-6所示。
正如图15-6所示,每个键值对开头的第一部分记录的是可能存在的过 期时间,这是一个毫秒级精度的UNIX时间戳。

之后的LRU信息或者LFU信息分别用于实现可选的LRU算法或者LFU算 法,并且因为Redis只能选择一种键淘汰算法,所以这两项信息将不会 同时出现,最多只会出现其中一种。
至于最后三个部分则分别记录了键值对的类型(比如字符串、列表、 散列等)以及键和值。
载入RDB文件
在介绍完RDB文件的组成结构之后,接下就让我们了解一下Redis服务 器载入RDB文件的具体步骤。
首先,当Redis服务器启动时,它会在工作目录中查找是否有RDB文件 出现,如果有就打开它,然后读取文件的内容并执行以下载入操作:
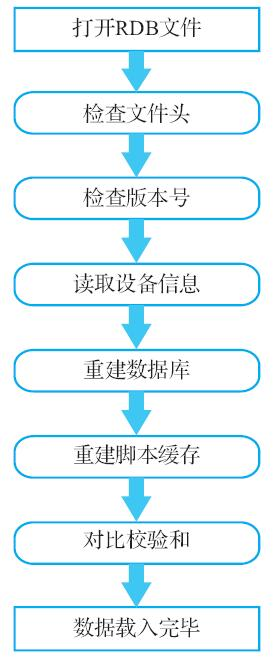
1)检查文件开头的标识符是否为"REDIS",如果是则继续执行后续的 载入操作,不是则抛出错误并终止载入操作。 2)检查文件的RDB版本号,以此来判断当前Redis服务器能否读取这一 版本的RDB文件。 3)根据文件中记录的设备附加信息,执行相应的操作和设置。 4)检查文件的数据库数据部分是否为空,如果不为空就执行以下子操 作: ①根据文件记录的数据库号码,切换至正确的数据库。 ②根据文件记录的键值对总数量以及带有过期时间的键值对数量,设 置数据库底层数据结构。 ③一个接一个地载入文件记录的所有键值对数据,并在数据库中重建 这些键值对。 5)如果服务器启用了复制功能,那么将之前缓存的Lua脚本重新载入 缓存中。 6)遇到EOF标识,确认RDB正文已经全部读取完毕。 7)载入RDB文件末尾记录的CRC64校验和,把它与载入数据期间计算出 的CRC64校验和进行对比,以此来判断被载入的数据是否完好无损。 8)RDB文件载入完毕,服务器开始接受客户端请求。 图15-7展示了这一数据载入流程。
数据丢失
RDB文件记录的是服务器在开始创建文件的那一刻,服务器中包含的所 有键值对数据,这种数据持久化方式通常被称为时间点快照(pointin-time snapshot)。时间点快照持久化的一个特点是,系统在停机 时将丢失最后一次成功实施持久化之后的所有数据。对于一个只使用RDB持久化的Redis服务器来说,服务器停机时丢失的数据量将取决于 最后一次成功执行的RDB持久化操作,以及该操作开始执行的时间。 因为Redis允许使用SAVE和BGSAVE这两种命令来执行RDB持久化操作, 所以接下来将分别分析这两个命令在遭遇故障停机时的表现。
-
SAVE命令的停机情况
因为SAVE命令是一个同步操作,它的开始和结束都位于同一个原子时 间之内,所以如果用户使用SAVE命令进行持久化,那么服务器在停机 时将丢失最后一次成功执行SAVE命令之后产生的所有数据。
以表15-1所示的情况为例,我们需要了解以下两点:
-
因为服务器最后一次成功执行SAVE命令是在T7,所以服务器创建出 的RDB文件将包含键k1至键k4在内的数据,服务器在重启时将使用这个 RDB文件进行数据恢复。
-
因为服务器在T7之后创建了键k5和键k6,并在之后出现停机,所以 当服务器重启时,键k5、k6的数据将丢失,而键k1至键k4的数据将被恢复。
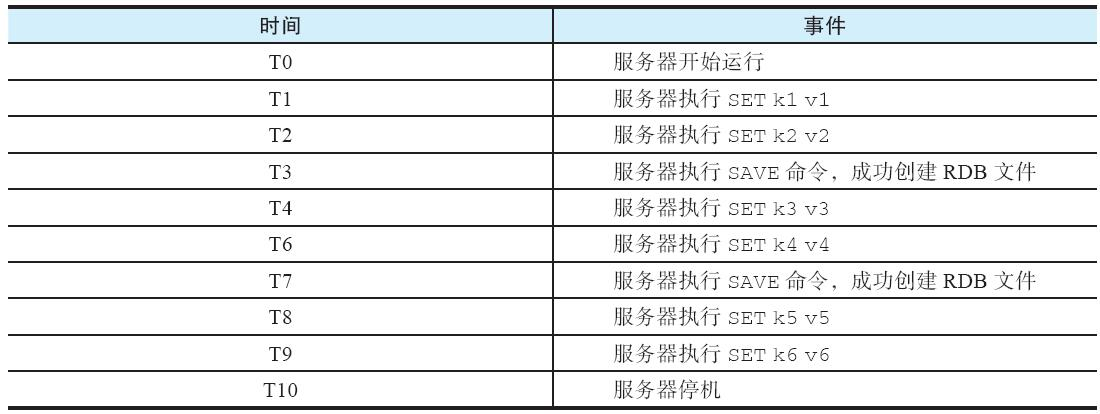 Figure 8. 表15-1 SAVE命令停机示例
Figure 8. 表15-1 SAVE命令停机示例 -
-
BGSAVE命令的停机情况
因为BGSAVE命令是一个异步命令,它的开始和结束并不位于同一个原 子时间之内,所以如果用户使用BGSAVE命令进行持久化,那么服务器 在停机时丢失的数据量将取决于最后一次成功执行的BGSAVE命令的开 始时间。
以表15-2所示的情况为例,我们需要了解以下三点:
-
因为T7创建的新RDB文件尚未完成,所以服务器在停机之后将使用T5 成功创建的RDB文件进行数据恢复。
-
虽然服务器现有的RDB文件是在T5成功创建的,但由于这个文件是在 T3开始创建的,所以它只包含了T3之前的数据,即键k1和键k2的数 据。
-
基于上述原因,当服务器重启时,只有键k1和键k2的数据会被恢 复,而键k3至键k6的数据则会丢失。

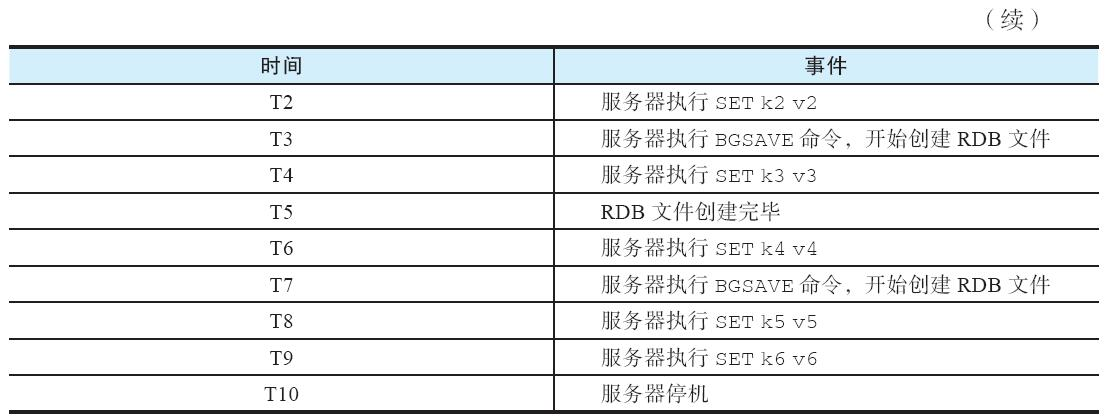 Figure 9. 表15-2 BGSAVE停机示例
Figure 9. 表15-2 BGSAVE停机示例 -
-
RDB持久化的缺陷
总的来说,无论用户使用的是SAVE命令还是BGSAVE命令,停机时服务 器丢失的数据量将取决于创建RDB文件的时间间隔:间隔越长,停机时 丢失的数据也就越多。
然而矛盾之处在于,RDB持久化是一种全量持久化操作,它在创建RDB 文件时需要存储整个服务器包含的所有数据,并因此消耗大量计算资 源和内存资源,所以用户是不太可能通过增大RDB文件的生成频率来保 证数据安全的。
举个例子,虽然从技术上来说,用户可以在每次执行写命令之后都执 行一次SAVE命令,以此来保证数据处于绝对安全的状态,但这样一来 Redis服务器的性能将下降至无法正常使用的水平。相反,用户如果想 要保证服务器的性能处于合理水平,就不能过于频繁地创建RDB文件, 这样一来,也就不可避免地会出现因为停机而丢失大量数据的情况。
从RDB持久化的特征来看,它更像是一种数据备份手段而非一种普通的 数据持久化手段。为了解决RDB持久化在停机时可能会丢失大量数据这 一问题,并提供一种真正符合用户预期的持久化功能,Redis推出了 15.2节将要介绍的AOF持久化模式。