TYPE:查看键的类型
TYPE 命令允许我们查看给定键的类型:
TYPE key举个例子,如果我们对一个字符串键执行 TYPE 命令,那么命令将告知我们,这个键是一个字符串键:
redis> GET msg
"hello world"
redis> TYPE msg
string又比如,如果我们对一个集合键执行 TYPE 命令,那么命令将告知我们,这个键是一个集合键:
redis> SMEMBERS fruits
1) "banana"
2) "cherry"
3) "apple"
redis> TYPE fruits
set表11-4列出了TYPE命令在面对不同类型的键时返回的各项结果。
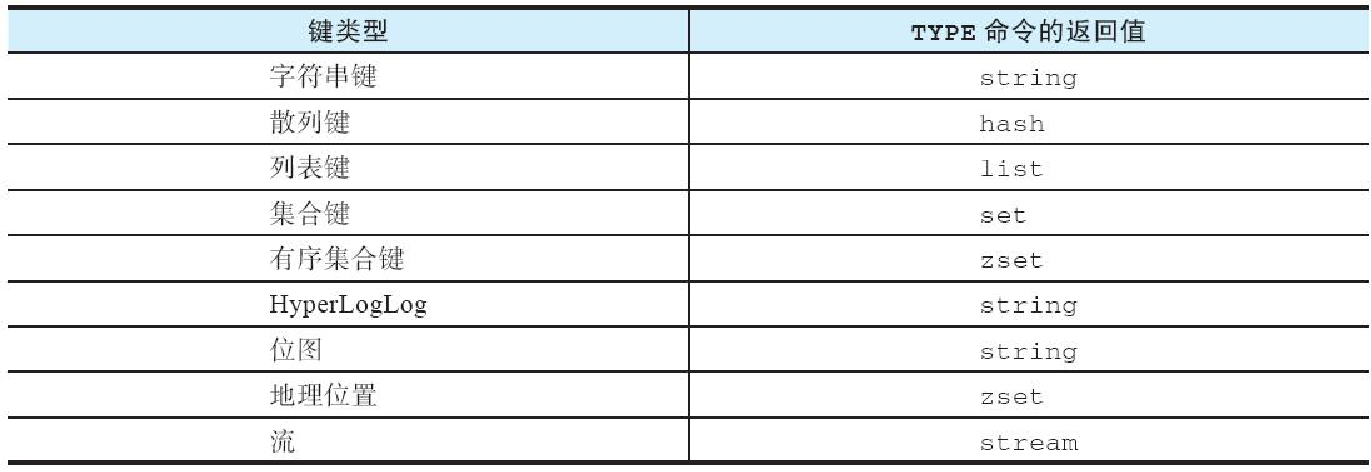
在表11-4中,TYPE 命令对于字符串键、散列键、列表键、集合键和流键的返回结果都非常直观,不过它对于之后几种类型的键的返回结果则需要做进一步解释:
-
因为所有有序集合命令,比如ZADD、ZREM、ZSCORE等,都是以z为前缀命名的,所以有序集合也被称为zset。因此TYPE命令在接收到有序集合键作为输入时,将返回zset作为结果。
-
因为HyperLogLog和位图这两种键在底层都是通过字符串键来实现的,所以TYPE命令对于这两种键将返回string作为结果。
-
与HyperLogLog和位图的情况类似,因为地理位置键使用了有序集合键作为底层实现,所以TYPE命令对于地理位置键将返回zset作为结果。
其他信息
-
复杂度:O(1)。
-
版本要求:TYPE命令从Redis 1.0.0版本开始可用。
示例:数据库取样程序
在使用Redis的过程中,我们可能会想要知道Redis数据库中各种键的类型分布状况,比如,我们可能会想要知道数据库中有多少个字符串键、有多少个列表键、有多少个散列键,以及这些键在数据库键的总数量中占多少个百分比。
代码清单11-2展示了一个能够计算出以上信息的数据库取样程序。DbSampler程序会对数据库进行迭代,使用TYPE命令获取被迭代键的类型并对不同类型的键实施计数,最终在迭代完整个数据库之后,打印出相应的取样结果。
def type_sample_result(type_name, type_counter, db_size):
result = "{0}: {1} keys, {2}% of the total."
return result.format(type_name, type_counter, type_counter*100.0/db_size)
class DbSampler:
def __init__(self, client):
self.client = client
def sample(self):
# 键类型计数器
type_counter = {
"string": 0,
"list": 0,
"hash": 0,
"set": 0,
"zset": 0,
"stream": 0,
}
# 遍历整个数据库
for key in self.client.scan_iter():
# 获取键的类型
type = self.client.type(key)
# 对相应的类型计数器执行加一操作
type_counter[type] += 1
# 获取数据库大小
db_size = self.client.dbsize()
# 打印结果
print("Sampled {0} keys.".format(db_size))
print(type_sample_result("String", type_counter["string"], db_size))
print(type_sample_result("List", type_counter["list"], db_size))
print(type_sample_result("Hash", type_counter["hash"], db_size))
print(type_sample_result("Set", type_counter["set"], db_size))
print(type_sample_result("SortedSet", type_counter["zset"], db_size))
print(type_sample_result("Stream", type_counter["stream"], db_size))以下代码展示了这个数据库取样程序的使用方法:
>>> from redis import Redis
>>> from create_random_type_keys import create_random_type_keys
>>> from db_sampler import DbSampler
>>> client = Redis(decode_responses=True)
>>> create_random_type_keys(client, 1000) # 创建1000个类型随机的键
>>> sampler = DbSampler(client)
>>> sampler.sample()
Sampled 1000 keys.
String: 179 keys, 17.9% of the total.
List: 155 keys, 15.5% of the total.
Hash: 172 keys, 17.2% of the total.
Set: 165 keys, 16.5% of the total.
SortedSet: 161 keys, 16.1% of the total.
Stream: 168 keys, 16.8% of the total.可以看到,取样程序遍历了数据库中的 1000 个键,然后打印出了不同类型键的具体数量以及它们在整个数据库中所占的百分比。
为了演示方便,上面的代码使用了 create_random_type_keys() 函数来创建出指定数量的类型随机键,代码清单11-3展示了这个函数的具体定义。
import random
def create_random_type_keys(client, number):
"""
在数据库中创建指定数量的类型随机键。
"""
for i in range(number):
# 构建键名
key = "key:{0}".format(i)
# 从六个键创建函数中随机选择一个
create_key_func = random.choice([
create_string,
create_hash,
create_list,
create_set,
create_zset,
create_stream
])
# 实际地创建键
create_key_func(client, key)
def create_string(client, key):
client.set(key, "")
def create_hash(client, key):
client.hset(key, "", "")
def create_list(client, key):
client.rpush(key, "")
def create_set(client, key):
client.sadd(key, "")
def create_zset(client, key):
client.zadd(key, {"":0})
def create_stream(client, key):
client.xadd(key, {"":""})