ZUNIONSTORE、ZINTERSTOTRE:有序集合的并集运算和交集运算
与集合一样,Redis 也为有序集合提供了相应的并集运算命令 ZUNIONSTORE 和交集运算命令 ZINTERSTORE,这两个命令的基本格式如下:
ZUNIONSTORE destination numbers sorted_set [sorted_set ...]
ZINTERSTORE destination numbers sorted_set [sorted_set ...]其中,命令的 numbers 参数用于指定参与计算的有序集合数量,之后的一个或多个 sorted_set 参数则用于指定参与计算的各个有序集合键,计算得出的结果则会存储到 destination 参数指定的键中。
ZUNIONSTORE 命令和 ZINTERSTORE 命令都会返回计算结果包含的成员数量作为返回值。
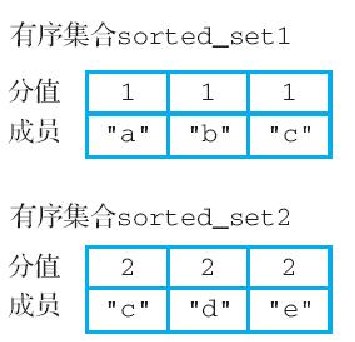
举个例子,对于图6-24所示的两个有序集合 sorted_set1 和 sorted_set2 来说,我们可以通过执行以下命令计算出它们的并集,并将其存储到键 union-result-1 中:
redis> ZUNIONSTORE union-result-1 2 sorted_set1 sorted_set2
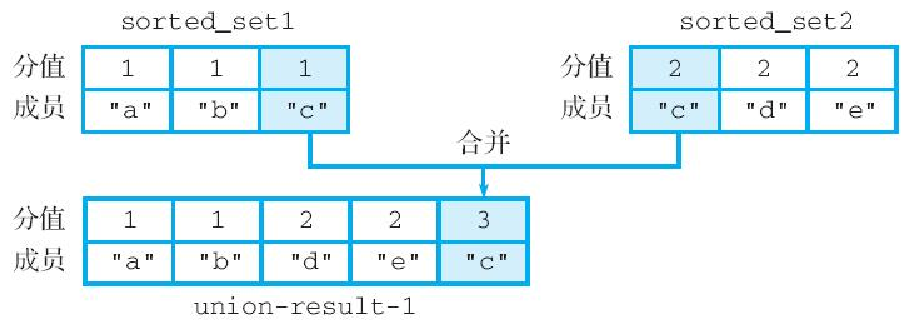
(integer) 5 -- 这个并集包含了5个成员图6-25展示了 union-result-1 有序集合包含的各个成员,其中成员 c 的分值 3 是根据 sorted_set1 和 sorted_set2 这两个有序集合中的成员 c 的分值相加得出的。
除此之外,我们还可以通过执行以下命令计算出 sorted_set1 和 sorted_set2 的交集,并将这个交集存储到键 inter-result-1 中:
redis> ZINTERSTORE inter-result-1 2 sorted_set1 sorted_set2
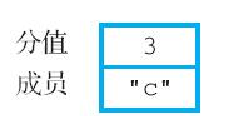
(integer) 1 -- 这个交集只包含了一个成员图6-26展示了 inter-result-1 有序集合包含的各个成员。与计算并集时的情况一样,在计算交集时,交集成员 c 的分值也是根据 sorted_set1 和 sorted_set2 这两个有序集合中成员 c 的分值相加得来的。
指定聚合函数
Redis 为 ZUNIONSTORE 命令和 ZINTERSTORE 命令提供了可选的 AGGREGATE 选项,通过这个选项,用户可以决定使用哪个聚合函数来计算结果有序集合成员的分值:
[AGGREGATE SUM|MIN|MAX]
ZINTERSTORE destination numbers sorted_set [sorted_set ...] [AGGREGATE SUM|MIN|MAX]AGGREGATE 选项的值可以是 SUM、MIN 或者 MAX 中的一个,表6-2 展示了这 3 个聚合函数的不同作用。

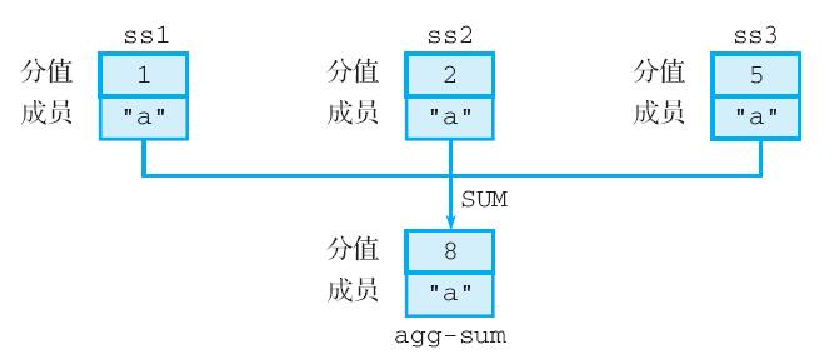
举个例子,对于图6-27 所示的 3 个有序集合 ss1、ss2 和 ss3 来说,使用 SUM 作为聚合函数进行交集计算,将得出一个分值为 8 的成员 a:

redis> ZINTERSTORE agg-sum 3 ss1 ss2 ss3 AGGREGATE SUM
(integer) 1
redis> ZRANGE agg-sum 0 -1 WITHSCORES
1) "a"
2) "8"这个分值是通过将 1、2、5 这 3 个分值相加得出的,如图 6-28 所示。
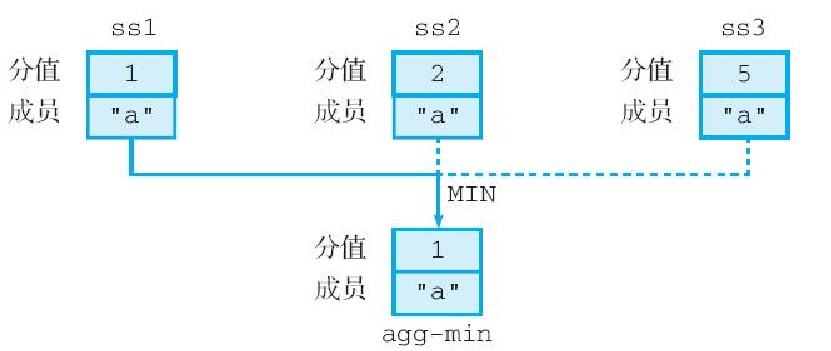
使用 MIN 作为聚合函数进行交集计算,将得出一个分值为 1 的成员 a:
redis> ZINTERSTORE agg-min 3 ss1 ss2 ss3 AGGREGATE MIN
(integer) 1
redis> ZRANGE agg-min 0 -1 WITHSCORES
1) "a"
2) "1"这个分值是通过从 1、2、5 这 3 个分值中选出最小值得出的,如图 6-29 所示。
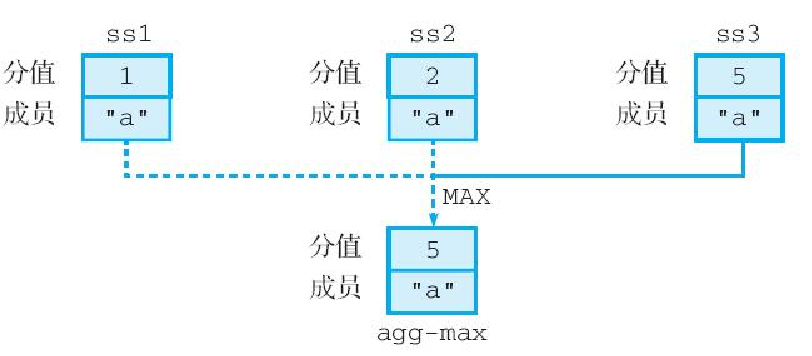
最后,使用 MAX 作为聚合函数进行交集计算,将得出一个分值为 5 的成员 a:
redis> ZINTERSTORE agg-max 3 ss1 ss2 ss3 AGGREGATE MAX
(integer) 1
redis> ZRANGE agg-max 0 -1 WITHSCORES
1) "a"
2) "5"这个分值是通过从 1、2、5 这 3 个分值中选出最大值得出的,如图6-30 所示。
在没有显式地使用 AGGREGATE 选项指定聚合函数的情况下,ZUNIONSTORE 和 ZINTERSTORE
默认使用 SUM 作为聚合函数。换句话说,以下这两条并集计算命令具有相同效果:
ZUNIONSTORE destination numbers sorted_set [sorted_set ...]
ZUNIONSTORE destination numbers sorted_set [sorted_set ...] AGGREGATE SUM而以下这两条交集计算命令也具有相同效果:
ZINTERSTORE destination numbers sorted_set [sorted_set ...]
ZINTERSTORE destination numbers sorted_set [sorted_set ...] AGGREGATE SUM设置权重
在默认情况下,ZUNIONSTORE 和 ZINTERSTORE 将直接使用给定有序集合的成员分值去计算结果有序集合的成员分值,但是在有需要的情况下,用户也可以通过可选的 WEIGHTS 参数为各个给定有序集合的成员分值设置权重:
ZUNIONSTORE destination numbers sorted_set [sorted_set ...] [WEIGHTS weight [weight ...]]
ZINTERSTORE destination numbers sorted_set [sorted_set ...] [WEIGHTS weight [weight ...]]在使用 WEIGHTS 选项时,用户需要为每个给定的有序集合分别设置一个权重,命令会将这个权重与成员的分值相乘,得出成员的新分值,然后执行聚合计算;与此相反,如果用户在使用 WEIGHTS 选项时,不想改变某个给定有序集合的分值,那么只需要将那个有序集合的权重设置为 1 即可。
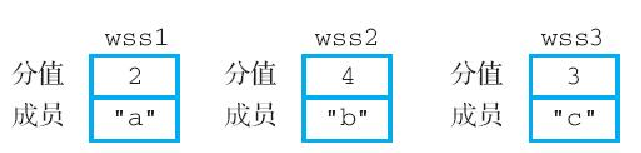
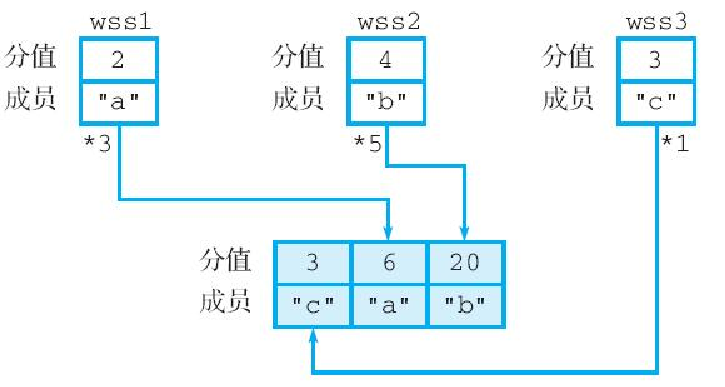
举个例子,如果我们对图6-31 所示的 3 个有序集合执行以下命令:
ZUNIONSTORE weighted-result 3 wss1 wss2 wss3 WEIGHTS 3 5 1那么 wss1 有序集合成员 "a" 的分值 2 将被乘以 3,变为 6;wss2 有序集合成员 "b" 的分值 4 则会被乘以 5,变为 20;wss3 有序集合成员的分值 3 则会保持不变;通过进行并集计算,命令最终将得出图 6-32 所示的结果有序集合 weighted-result。
使用集合作为输入
ZUNIONSTORE 和 ZINTERSTORE 除了可以使用有序集合作为输入之外,还可以使用集合作为输入:在默认情况下,这两个命令将把给定集合看作所有成员的分值都为 1 的有序集合来进行计算。如果有需要,用户也可以使用 WEIGHTS 选项来改变给定集合的分值,比如,如果你希望某个集合所有成员的分值都被看作 10 而不是 1,那么只需要在执行命令时把那个集合的权重设置为 10 即可。

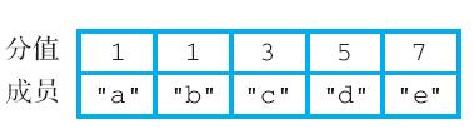
举个例子,对于图6-33 所示的集合和有序集合来说,我们可以执行以下命令,对它们进行并集计算,并将计算结果存储到 mixed 有序集合中:
redis> ZUNIONSTORE mixed 2 alphabets another-alphabets
(integer) 5图6-34展示了 mixed 有序集合示例。
其它信息
-
复杂度:ZUNIONSTORE 命令的复杂度为 O(N*log(N)),其中 N 为所有给定有序集合的成员总数量。ZINTERSTORE 命令的复杂度为 O(N*log(N)*M),其中 N 为所有给定有序集合中,基数最小的那个有序集合的基数,而M则是给定有序集合的数量。
-
版本要求:ZUNIONSTORE 命令和 ZINTERSTORE 命令从 Redis 2.0.0 版本开始可用。
示例:商品推荐
在浏览网上商城的时候,我们常常会看到类似 “购买此商品的顾客也同时购买” 这样的商品推荐功能,如图6-35所示。

从抽象的角度来讲,这些推荐功能实际上都是通过记录用户的访问路径来实现的:如果用户在对一个目标执行了类似浏览或者购买这样的操作之后,也对另一个目标执行了相同的操作,那么程序就会对这次操作的访问路径进行记录和计数,然后程序就可以通过计数结果来知道用户在对指定目标执行了某个操作之后,还会对哪些目标执行相同的操作。
代码清单6-3 展示了一个使用以上原理实现的路径统计程序:
-
每当用户从起点 origin 对终点 destination 进行一次访问,程序都会使用 ZINCRBY 命令对存储着起点 origin 访问记录的有序集合的 destination 成员执行一次分值加 1 操作。
-
在此之后,程序只需要对存储着 origin 访问记录的有序集合执行 ZREVRANGE 命令,就可以知道用户在访问了起点 origin 之后,最经常访问的目的地有哪些。
def make_record_key(origin):
return "forward_to_record::{0}".format(origin)
class Path:
def __init__(self, client):
self.client = client
def forward_to(self, origin, destination):
"""
记录一次从起点 origin 到目的地 destination 的访问。
"""
key = make_record_key(origin)
self.client.zincrby(key, 1, destination)
def pagging_record(self, origin, number, count, with_time=False):
"""
按照每页 count 个目的地计算,
从起点 origin 的访问记录中取出位于第 number 页的访问记录,
其中所有访问记录均按照访问次数从多到小进行排列。
如果可选的 with_time 参数的值为 True ,那么将具体的访问次数也一并返回。
"""
key = make_record_key(origin)
start_index = (number-1)*count
end_index = number*count-1
return self.client.zrevrange(key, start_index, end_index, withscores=with_time, score_cast_func=int) # score_cast_func = int 用于将成员的分值从浮点数转换为整数以下代码展示了如何使用 Path 程序在一个图书网站上实现 “看了这本书的顾客也看了以下这些书” 的功能:
>>> from redis import Redis
>>> from path import Path
>>> client = Redis(decode_responses=True)
>>> see_also = Path(client)
>>> see_also.forward_to("book1", "book2") # 从book1到book2的访问为3次
>>> see_also.forward_to("book1", "book2")
>>> see_also.forward_to("book1", "book2")
>>> see_also.forward_to("book1", "book3") # 从book1到book3的访问为2次
>>> see_also.forward_to("book1", "book3")
>>> see_also.forward_to("book1", "book4") # 从book1到book4和book5的访问各为1次
>>> see_also.forward_to("book1", "book5")
>>> see_also.forward_to("book1", "book6") # 从book1到book6的访问为2次
>>> see_also.forward_to("book1", "book6")
>>> see_also.pagging_record("book1", 1, 5) # 展示顾客在看了book1之后,最常看的其他书
['book2', 'book6', 'book3', 'book5', 'book4']
>>> see_also.pagging_record("book1", 1, 5, with_time=True) # 将查看的次数也列出来
[('book2', 3), ('book6', 2), ('book3', 2), ('book5', 1), ('book4', 1)]