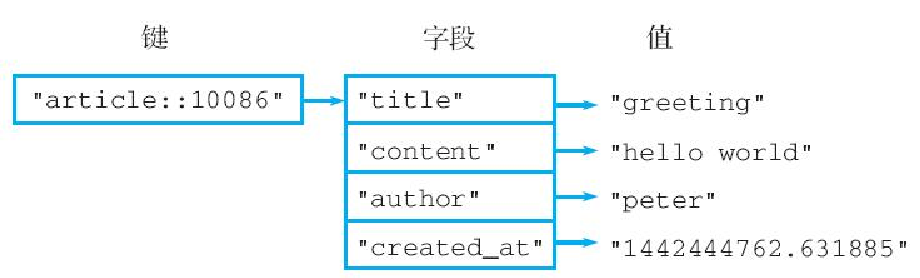
HKEYS、HVALS、HGETALL:获取所有字段、所有值、所有字段和值
Redis 为散列提供了 HKEYS、HVALS 和 HGETALL 这 3 个命令,可以分别用于获取散列包含的所有字段、所有值以及所有字段和值:
HKEYS hash
HVALS hash
HGETALL hash举个例子,对于图 3-19 所示的 article::10086 散列来说,我们可以使用 HKEYS 命令去获取它包含的所有字段:
redis> HKEYS article::10086
1) "title"
2) "content"
3) "author"
4) "created_at"也可以使用 HVALS 命令去获取它包含的所有值:
redis> HVALS article::10086
1) "greeting"
2) "hello world"
3) "peter"
4) "1442744762.631885"还可以使用 HGETALL 命令去获取它包含的所有字段和值:
redis> HGETALL article::10086
1) "title" -- 字段
2) "greeting" -- 字段的值
3) "content"
4) "hello world"
5) "author"
6) "peter"
7) "created_at"
8) "1442744762.631885"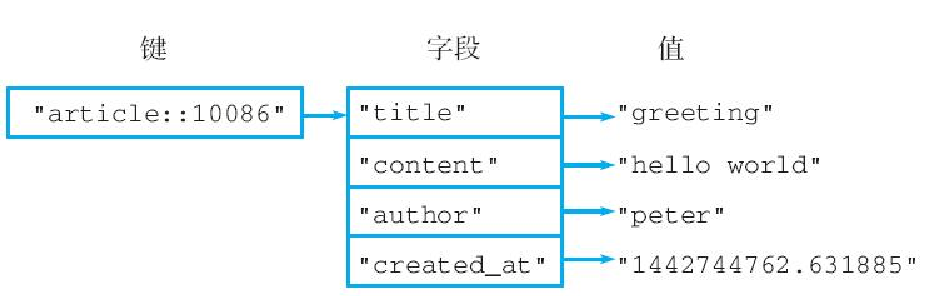
在 HGETALL 命令返回的结果列表当中,每两个连续的元素就代表了散列中的一对字段和值,其中奇数位置上的元素为字段,偶数位置上的元素则为字段的值。
如果用户给定的散列并不存在,那么 HKEYS、HVALS 和 HGETALL 都将返回一个空列表:
redis> HKEYS not-exists-hash
(empty list or set)
redis> HVALS not-exists-hash
(empty list or set)
redis> HGETALL not-exists-hash
(empty list or set)字段在散列中的排列顺序
Redis 散列包含的字段在底层是以无序方式存储的,根据字段插入的顺序不同,包含相同字段的散列在执行 HKEYS 命令、HVALS 命令和 HGETALL 命令时可能会得到不同的结果,因此用户在使用这 3 个命令的时候,不应该对它们返回的元素的排列顺序做任何假设。如果需要,用户可以对这些命令返回的元素进行排序,使它们从无序变为有序。
举个例子,如果我们以不同的设置顺序创建两个完全相同的散列 hash1 和 hash2:
redis> HMSET hash1 field1 value1 field2 value2 field3 value3
OK
redis> HMSET hash2 field3 value3 field2 value2 field1 value1
OK那么 HKEYS 命令将以不同的顺序返回这两个散列的字段:
redis> HKEYS hash1
1) "field1"
2) "field2"
3) "field3"
redis> HKEYS hash2
1) "field3"
2) "field2"
3) "field1"而 HVALS 命令则会以不同的顺序返回这两个散列的字段值:
redis> HVALS hash1
1) "value1"
2) "value2"
3) "value3"
redis> HVALS hash2
1) "value3"
2) "value2"
3) "value1"HGETALL 命令则会以不同的顺序返回这两个散列的字段和值:
redis> HGETALL hash1
1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
redis> HGETALL hash2
1) "field3"
2) "value3"
3) "field2"
4) "value2"
5) "field1"
6) "value1"其它信息
-
复杂度:HKEYS 命令、HVALS 命令和 HGETALL 命令的复杂度都为 O(N),其中 N 为散列包含的字段数量。
-
版本要求:HKEYS 命令、HVALS 命令和 HGETALL 命令都从 Redis 2.0.0 版本开始可用。
示例:存储图数据
在构建地图应用、设计电路图、进行任务调度、分析网络流量等多种任务中,都需要对图(graph)数据结构实施建模,并存储相关的图数据。对于不少数据库来说,想要高效、直观地存储图数据并不是一件容易的事情,但是 Redis 却能够以多种不同的方式表示图数据结构,其中一种方式就是使用散列。
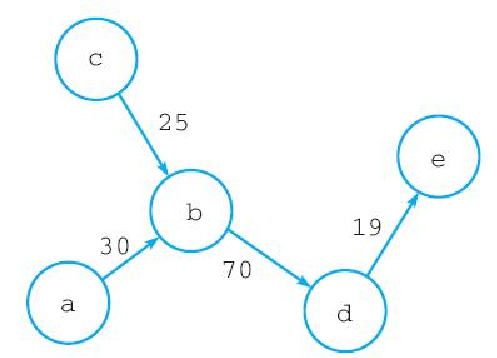
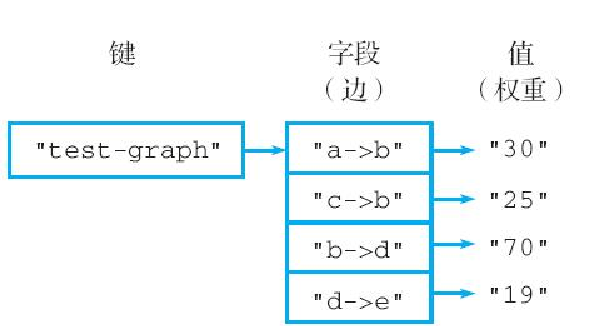
例如,假设我们想要存储图 3-20 所示的带权重有向图,那么可以创建一个图 3-21 所示的散列键,这个散列键会以 start_vertex->end_vertex 的形式将各个顶点之间的边存储到散列的字段中,并将字段的值设置成边的权重。通过这种方法,我们可以将图的相关数据全部存储到散列中,代码清单 3-5 展示了使用这种方法实现的图数据存储程序。
def make_edge_name_from_vertexs(start, end):
"""
使用边的起点和终点组建边的名字。
例子:对于 start 为 "a" 、 end 为 "b" 的输入,这个函数将返回 "a->b" 。
"""
return str(start) + "->" + str(end)
def decompose_vertexs_from_edge_name(name):
"""
从边的名字中分解出边的起点和终点。
例子:对于输入 "a->b" ,这个函数将返回结果 ["a", "b"] 。
"""
return name.split("->")
class Graph:
def __init__(self, client, key):
self.client = client
self.key = key
def add_edge(self, start, end, weight):
"""
添加一条从顶点 start 连接至顶点 end 的边,并将边的权重设置为 weight 。
"""
edge = make_edge_name_from_vertexs(start, end)
self.client.hset(self.key, edge, weight)
def remove_edge(self, start, end):
"""
移除从顶点 start 连接至顶点 end 的一条边。
这个方法在成功删除边时返回 True ,
因为边不存在而导致删除失败时返回 False 。
"""
edge = make_edge_name_from_vertexs(start, end)
return self.client.hdel(self.key, edge)
def get_edge_weight(self, start, end):
"""
获取从顶点 start 连接至顶点 end 的边的权重,
如果给定的边不存在,那么返回 None 。
"""
edge = make_edge_name_from_vertexs(start, end)
return self.client.hget(self.key, edge)
def has_edge(self, start, end):
"""
检查顶点 start 和顶点 end 之间是否有边,
是的话返回 True ,否则返回 False 。
"""
edge = make_edge_name_from_vertexs(start, end)
return self.client.hexists(self.key, edge)
def add_multi_edges(self, *tuples):
"""
一次向图中添加多条边。
这个方法接受任意多个格式为 (start, end, weight) 的三元组作为参数。
"""
# redis-py 客户端的 hmset() 方法接受一个字典作为参数
# 格式为 {field1: value1, field2: value2, ...}
# 为了一次对图中的多条边进行设置
# 我们要将待设置的各条边以及它们的权重储存在以下字典
nodes_and_weights = {}
# 遍历输入的每个三元组,从中取出边的起点、终点和权重
for start, end, weight in tuples:
# 根据边的起点和终点,创建出边的名字
edge = make_edge_name_from_vertexs(start, end)
# 使用边的名字作为字段,边的权重作为值,把边及其权重储存到字典里面
nodes_and_weights[edge] = weight
# 根据字典中储存的字段和值,对散列进行设置
self.client.hmset(self.key, nodes_and_weights)
def get_multi_edge_weights(self, *tuples):
"""
一次获取多条边的权重。
这个方法接受任意多个格式为 (start, end) 的二元组作为参数,
然后返回一个列表作为结果,列表中依次储存着每条输入边的权重。
"""
# hmget() 方法接受一个格式为 [field1, field2, ...] 的列表作为参数
# 为了一次获取图中多条边的权重
# 我们需要把所有想要获取权重的边的名字依次放入到以下列表里面
edge_list = []
# 遍历输入的每个二元组,从中获取边的起点和终点
for start, end in tuples:
# 根据边的起点和终点,创建出边的名字
edge = make_edge_name_from_vertexs(start, end)
# 把边的名字放入到列表中
edge_list.append(edge)
# 根据列表中储存的每条边的名字,从散列里面获取它们的权重
return self.client.hmget(self.key, edge_list)
def get_all_edges(self):
"""
以集合形式返回整个图包含的所有边,
集合包含的每个元素都是一个 (start, end) 格式的二元组。
"""
# hkeys() 方法将返回一个列表,列表中包含多条边的名字
# 例如 ["a->b", "b->c", "c->d"]
edges = self.client.hkeys(self.key)
# 创建一个集合,用于储存二元组格式的边
result = set()
# 遍历每条边的名字
for edge in edges:
# 根据边的名字,分解出边的起点和终点
start, end = decompose_vertexs_from_edge_name(edge)
# 使用起点和终点组成一个二元组,然后把它放入到结果集合里面
result.add((start, end))
return result
def get_all_edges_with_weight(self):
"""
以集合形式返回整个图包含的所有边,以及这些边的权重。
集合包含的每个元素都是一个 (start, end, weight) 格式的三元组。
"""
# hgetall() 方法将返回一个包含边和权重的字典作为结果
# 格式为 {edge1: weight1, edge2: weight2, ...}
edges_and_weights = self.client.hgetall(self.key)
# 创建一个集合,用于储存三元组格式的边和权重
result = set()
# 遍历字典中的每个元素,获取边以及它的权重
for edge, weight in edges_and_weights.items():
# 根据边的名字,分解出边的起点和终点
start, end = decompose_vertexs_from_edge_name(edge)
# 使用起点、终点和权重构建一个三元组,然后把它添加到结果集合里面
result.add((start, end, weight))
return result这个图数据存储程序的核心概念就是把边(edge)的起点和终点组合成一个字段名,并把边的权重(weight)用作字段的值,然后使用 HSET 命令或者 HMSET 命令把它们存储到散列中。比如,如果用户输入的边起点为 "a",终点为 "b",权重为 "30",那么程序将执行命令 HSET hash "a→b" 30,把 "a" 至 "b" 的这条边及其权重 30 存储到散列中。
在此之后,程序就可以使用 HDEL 命令删除图的某条边,使用 HGET 命令或者 HMGET 命令获取边的权重,使用 HEXISTS 命令检查边是否存在,使用 HKEYS 命令和 HGETALL 命令获取图的所有边以及权重。
例如,我们可以通过执行以下代码,构建出前面展示过的带权重有向图3-20:
>>> from redis import Redis
>>> from graph import Graph
>>>
>>> client = Redis(decode_responses=True)
>>> graph = Graph(client, "test-graph")
>>>
>>> graph.add_edge("a", "b", 30) # 添加边
>>> graph.add_edge("c", "b", 25)
>>> graph.add_multi_edges(("b", "d", 70), ("d", "e", 19)) # 添加多条边然后通过执行程序提供的方法获取边的权重,或者检查给定的边是否存在:
>>> graph.get_edge_weight("a", "b") # 获取边a->b的权重
'30'
>>> graph.has_edge("a", "b") # 边a->b存在
True
>>> graph.has_edge("b", "a") # 边b->a不存在
False最后,我们还可以获取图的所有边以及它们的权重:
>>> graph.get_all_edges() # 获取所有边
{('b', 'd'), ('d', 'e'), ('a', 'b'), ('c', 'b')}
>>>
>>> graph.get_all_edges_with_weight() # 获取所有边以及它们的权重
{('c', 'b', '25'), ('a', 'b', '30'), ('d', 'e', '19'), ('b', 'd', '70')}这里展示的图数据存储程序提供了针对边和权重的功能,因为它能够非常方便地向图中添加边和移除边,并且可以快速地检查某条边是否存在,所以适合用来存储节点较多但边较少的稀疏图(sparse graph)。在后续的章节中,我们还会继续看到更多使用 Redis 存储图数据的例子。
示例:使用散列键重新实现文章存储程序
之前我们用散列重写了第 2 章介绍过的计数器程序,但是除了计数器程序之外,还有另一个程序也非常适合使用散列来重写,那就是文章数据存储程序:比起用多个字符串键来存储文章的各项数据,更好的做法是把每篇文章的所有数据都存储到同一个散列中,代码清单3-6展示了这一想法的具体实现。
from time import time
class Article:
def __init__(self, client, article_id):
self.client = client
self.article_id = str(article_id)
self.article_hash = "article::" + self.article_id
def is_exists(self):
"""
检查给定 ID 对应的文章是否存在。
"""
# 如果文章散列里面已经设置了标题,那么我们认为这篇文章存在
return self.client.hexists(self.article_hash, "title")
def create(self, title, content, author):
"""
创建一篇新文章,创建成功时返回 True ,
因为文章已经存在而导致创建失败时返回 False 。
"""
# 文章已存在,放弃执行创建操作
if self.is_exists():
return False
# 把所有文章数据都放到字典里面
article_data = {
"title": title,
"content": content,
"author": author,
"create_at": time()
}
# redis-py 的 hmset() 方法接受一个字典作为参数,
# 并根据字典内的键和值对散列的字段和值进行设置。
return self.client.hmset(self.article_hash, article_data)
def get(self):
"""
返回文章的各项信息。
"""
# hgetall() 方法会返回一个包含标题、内容、作者和创建日期的字典
article_data = self.client.hgetall(self.article_hash)
# 把文章 ID 也放到字典里面,以便用户操作
article_data["id"] = self.article_id
return article_data
def update(self, title=None, content=None, author=None):
"""
对文章的各项信息进行更新,
更新成功时返回 True ,失败时返回 False 。
"""
# 如果文章并不存在,那么放弃执行更新操作
if not self.is_exists():
return False
article_data = {}
if title is not None:
article_data["title"] = title
if content is not None:
article_data["content"] = content
if author is not None:
article_data["author"] = author
return self.client.hmset(self.article_hash, article_data)新的文章存储程序除了会用到散列之外,还有两点需要注意:
-
虽然 Redis 为字符串提供了 MSET 命令和 MSETNX 命令,但是并没有为散列提供 HMSET 命令对应的 HMSETNX 命令,所以这个程序在创建一篇新文章之前,需要先通过 is_exists() 方法检查文章是否存在,然后再考虑是否使用 HMSET 命令进行设置。
-
在使用字符串键存储文章数据的时候,为了避免数据库中出现键名冲突,程序必须为每篇文章的每个属性都设置一个独一无二的键,比如使用 article::10086::title 键存储 ID 为 10086 的文章的标题,使用 article::12345::title 键存储 ID 为 12345 的文章的标题,诸如此类。相反,因为新的文章存储程序可以直接将一篇文章的所有相关信息都存储到同一个散列中,所以它可以直接在散列里面使用 title 作为标题的字段,而不必担心出现命名冲突。
以下代码简单地展示了这个文章存储程序的使用方法:
>>> from redis import Redis
>>> from article import Article
>>>
>>> client = Redis(decode_responses=True)
>>> article = Article(client, 10086)
>>>
>>> # 创建文章
>>> article.create("greeting", "hello world", "peter")
>>>
>>> # 获取文章内容
>>> article.get()
{'content': 'hello world', 'id': '10086', 'created_at': '1442744762.631885', 'title': 'greeting'
, 'author': 'peter'}
>>>
>>> # 检查文章是否存在
>>> article.is_exists()
True
>>> # 更新文章内容
>>> article.update(content="good morning!")
>>> article.get()
{'content': 'good morning!', 'id': '10086', 'created_at': '1442744762.631885', 'title': 'greeti
ng', 'author': 'peter'}图 3-22 展示了这段代码创建的散列键。