集群管理命令
除了集群管理程序之外,Redis 还提供了一簇以 CLUSTER 开头的集群命令,这些命令可以根据它们的作用分为集群管理命令和槽管理命令,前者管理的是集群及其节点,而后者管理的则是节点的槽分配情况。
需要注意的是,因为 Redis 的集群管理程序 redis-cli --cluster 实际上就是由 CLUSTER 命令实现的,所以这两者之间存在着千丝万缕的关系,某些 redis-cli—cluster 子命令甚至直接与某个 CLUSTER 子命令对应。
我们之所以在了解了 Redis 集群管理程序之后仍然需要了解 CLUSTER 命令,是因为在某些情况下,Redis 提供的集群管理程序可能无法满足我们的需求,这时我们就需要使用 CLUSTER 命令去构建自己的集群管理程序了。
本节接下来的内容将介绍 CLUSTER 命令中集群管理方面的子命令,而 CLUSTER 命令中槽管理方面的子命令则会在 20.7 介绍。
CLUSTER MEET:将节点添加至集群
用户可以通过执行以下命令,将给定的节点添加至当前节点所在的集群中:
CLUSTER MEET ip portCLUSTER MEET 命令在向给定节点发送完握手信息之后将返回 OK。
举个例子,假设我们现在启动了 30001、30002 和 30003 这 3 个节点,并且打算使用这 3 个节点组成一个集群,那么可以首先执行以下命令,将节点 30001 和 30002 放到同一个集群中:
127.0.0.1:30001> CLUSTER MEET 127.0.0.1 30002
OK然后执行以下命令,将节点 30003 也添加到集群中:
127.0.0.1:30001> CLUSTER MEET 127.0.0.1 30003
OK图20-6 展示了 30001、30002 和 30003 这 3 个节点组成集群的整个过程。
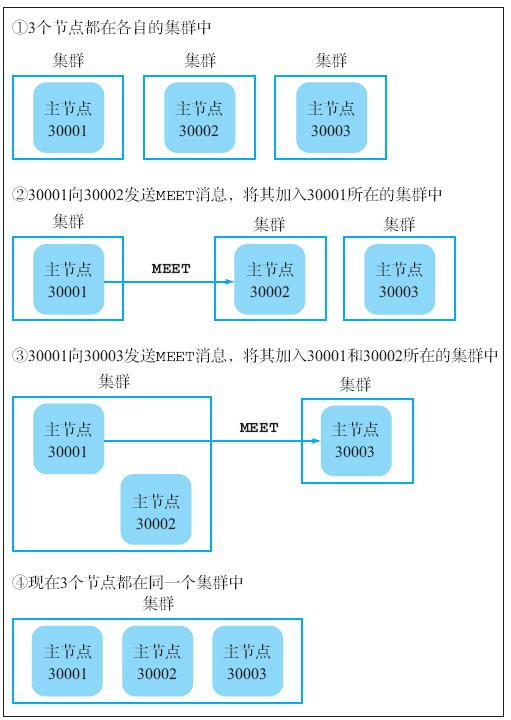
Redis 集群中的节点使用消息(message)进行通信。图20-6 中出现的 MEET 消息由接收到 CLUSTER MEET 命令的节点发送,它会尝试将接收到该消息的节点(以及该节点所在集群的其他节点)加入发送者节点所在的集群中。
-
添加多个节点
当用户执行 CLUSTER MEET 命令,尝试将一个给定的节点添加到当前节点所在的集群时,如果给定节点已经位于一个包含多个节点的集群当中,那么不仅给定节点会被添加到当前节点所在的集群,给定节点原集群内的其他节点也会自动合并到当前集群中。
举个例子,假设现在有两个集群,一个由 30001、30002 和 30003 这 3 个节点组成,而另一个则由 30004、30005 和 30006 这 3 个节点组成。这时,如果我们向 30001 发送以下命令,尝试将 30004 添加到 30001 所在的集群当中:
127.0.0.1:30001> CLUSTER MEET 127.0.0.1 30004 OK那么不仅 30004 会被添加到 30001 所在的集群,30005 和 30006 也同样会被添加到 30001 所在的集群中。图20-7 展示了以上这两个集群合并为一个集群的整个过程。
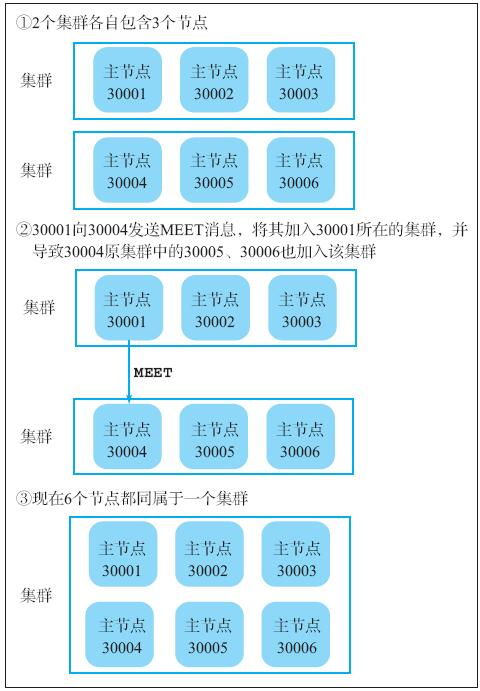 Figure 2. 图20-7 两个集群合并为一个集群的过程
Figure 2. 图20-7 两个集群合并为一个集群的过程 -
其他信息
-
复杂度:O(1)。
-
版本要求:CLUSTER MEET命令从Redis 3.0.0版本开始可用。
-
CLUSTER NODES:查看集群内所有节点的相关信息
用户可以通过执行以下命令,查看集群内所有节点的相关信息:
CLUSTER NODES以下是一个执行该命令的例子:
127.0.0.1:30001> CLUSTER NODES
5f99406c27403564f34f4b5e39410714881ad98e 127.0.0.1:30005@40005 slave 9cd23534bf654a47a2d4d8a4b27
17c495ee31b40 0 1541751161088 5 connected
309871e77eaccc0a4e260cf393547bf51ba11983 127.0.0.1:30002@40002 master - 0 1541751161088 2 connec
ted 5461-10922
db3a54cfe722264bd91caef4d4af9701bf02223f 127.0.0.1:30006@40006 slave 309871e77eaccc0a4e260cf3935
47bf51ba11983 0 1541751161694 6 connected
27493691b04fccc230c7ac4e20836c081a6f33aa 127.0.0.1:30003@40003 master - 0 1541751161088 3 connec
ted 10923-16383
bf0d4857c921750b9d149241255a7ae777b93539 127.0.0.1:30004@40004 slave 27493691b04fccc230c7ac4e208
36c081a6f33aa 0 1541751161694 4 connected
9cd23534bf654a47a2d4d8a4b2717c495ee31b40 127.0.0.1:30001@40001 myself,master - 0 1541751161000 1
connected 0-5460CLUSTER NODES 命令的结果通常由多个行组成,每个行都记录了一个节点的相关信息,行中的各项信息则由空格分隔,表20-1 详细地解释了这些信息项的具体意义。
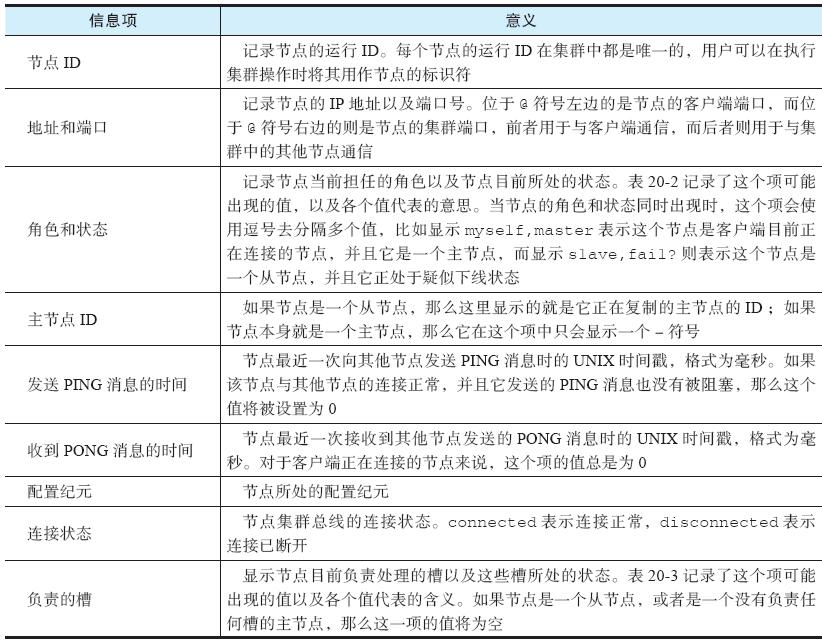
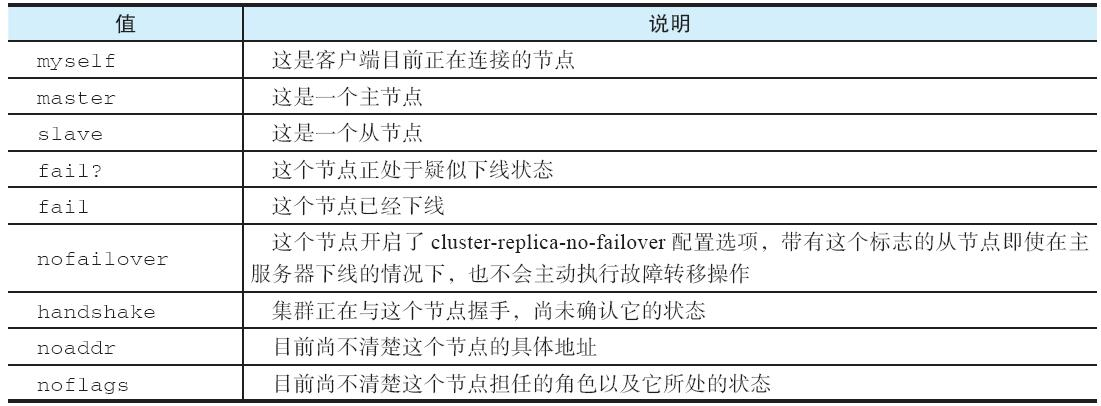

作为例子,对于以下这个输出行:
9cd23534bf654a47a2d4d8a4b2717c495ee31b40 127.0.0.1:30001@40001 myself,master - 0 1541751161000 1
connected 0-5460我们可以从中看出以下信息:
-
这个节点的运行 ID 为 9cd23534bf654a47a2d4d8a4b2717c495ee31b40。
-
它的 IP 地址为 127.0.0.1,客户端端口号为 30001,集群端口号为 40001。
-
角色和状态部分的 myself 表示它是客户端正在连接的节点,而 master 则表示它是一个主节点。
-
因为这个节点本身就是一个主节点,它没有正在复制的节点,所以它的主节点 ID 部分为
-。 -
节点最近一次发送 PING 消息的时间戳为 0,这表示该节点与其他节点连接正常,并且没有待发送的 PING 消息;该节点最后一次收到 PONG 消息的时间戳为 1541751161000。
-
这个节点所处的配置纪元为 1。
-
connected 表示这个节点的集群总线连接状态正常。
-
0-5460 表示这个节点负责处理槽 0 至槽 5460。
又比如,对于以下这个输出行:
db3a54cfe722264bd91caef4d4af9701bf02223f 127.0.0.1:30006@40006 slave 309871e77eaccc0a4e260cf3935
47bf51ba11983 0 1541751161694 6 connected它包含了以下信息:
-
这个节点的 ID 为 db3a54cfe722264bd91caef4d4af9701bf02223f,它是一个从节点,它的 IP 地址为 127.0.0.1,客户端端口号为 30006,集群端口号为 40006。
-
这个节点正在复制的主节点的运行 ID 为 309871e77eaccc0a4e260cf393547bf51ba11983。
-
这个节点最后一次发送 PING 消息的时间戳为 0,这表示该节点与其他节点的连接正常,并且没有待发送的 PING 消息;而它最后一次接收到 PONG 消息的时间戳为 1541751161694。
-
这个节点所处的配置纪元为 6。
-
connected 表示这个节点的集群总线的连接状态正常。
-
这个节点是一个从节点,它没有被指派任何槽,所以槽信息部分为空。
其他信息
-
复杂度:O(N),其中 N 为集群包含的节点数量。
-
版本要求:CLUSTER NODES 命令从 Redis 3.0.0 版本开始可用。
CLUSTER MYID:查看当前节点的运行ID
当用户想要知道客户端正在连接的节点的运行 ID 时,可以执行以下命令:
CLUSTER MYID因为不少集群命令都需要使用节点的运行 ID 作为参数,所以当我们需要对正在连接的节点执行某个使用运行 ID 作为参数的操作时,就可以使用 CLUSTER MYID 命令快速地获得节点的 ID。
以下是一个 CLUSTER MYID 命令的执行示例:
127.0.0.1:30001> CLUSTER MYID
"9cd23534bf654a47a2d4d8a4b2717c495ee31b40"从命令返回的结果可以知道,客户端正在连接 ID 为 9cd23534bf654a47a2d4d8a4b2717c495ee31b40 的节点。
其他信息
-
复杂度:O(1)。
-
版本要求:CLUSTER MYID 命令从 Redis 3.0.0 版本开始可用。
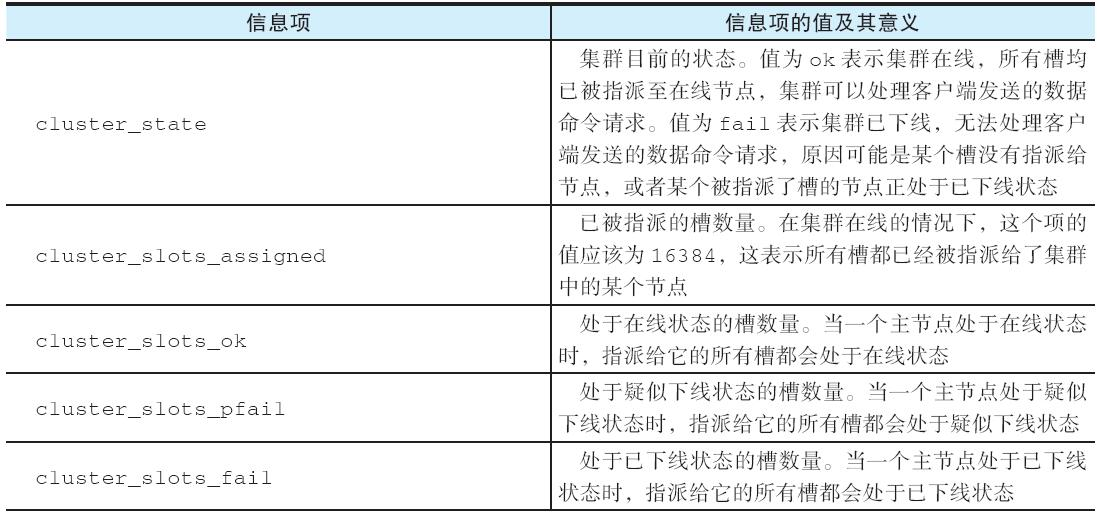
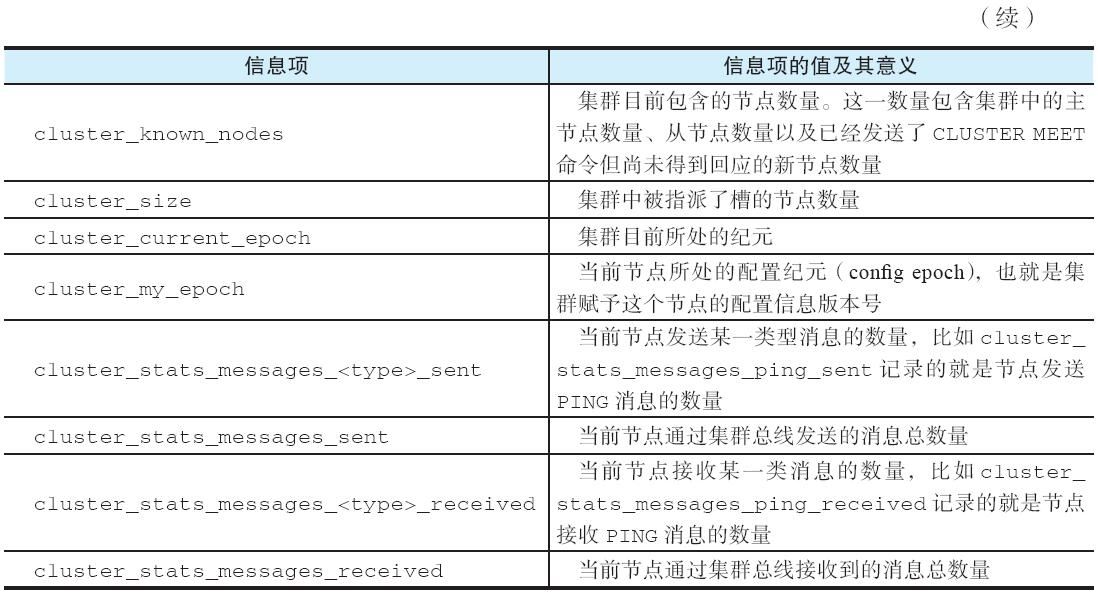
CLUSTER INFO:查看集群信息
用户可以通过执行 CLUSTER INFO 命令,查看与集群以及当前节点有关的状态信息:
CLUSTER INFO以下是一个对节点 30001 执行 CLUSTER INFO 命令的示例:
127.0.0.1:30001> CLUSTER INFO
cluster_state:ok --集群目前处于在线状态
cluster_slots_assigned:16384 --有16384个槽已经被指派
cluster_slots_ok:16384 --有16384个槽处于在线状态
cluster_slots_pfail:0 --没有槽处于疑似下线状态
cluster_slots_fail:0 --没有槽处于已下线状态
cluster_known_nodes:6 --集群包含6个节点
cluster_size:3 --集群中有3个节点被指派了槽
cluster_current_epoch:6 --集群当前所处的纪元为6
cluster_my_epoch:1 --节点当前所处的配置纪元为1
cluster_stats_messages_ping_sent:774301 --节点发送PING消息的数量
cluster_stats_messages_pong_sent:774642 --节点发送PONG消息的数量
cluster_stats_messages_sent:1548943 --节点目前总共发送了1548943条消息
cluster_stats_messages_ping_received:774637 --节点接收PING消息的数量
cluster_stats_messages_pong_received:774301 --节点接收PONG消息的数量
cluster_stats_messages_meet_received:5 --节点接收MEET消息的数量
cluster_stats_messages_received:1548943 --节点目前总共接收了1548943条消息表20-4 详细地说明了 CLUSTER INFO 命令返回的各个信息项的值及其意义。
其他信息
-
复杂度:O(1)。
-
版本要求:CLUSTER INFO 从 Redis 3.0.0 版本开始可用。
CLUSTER FORGET:从集群中移除节点
当用户不再需要集群中的某个节点时,可以通过执行以下命令将其移除:
CLUSTER FORGET node-id这个命令接受节点的运行 ID 作为参数,并在成功执行之后返回 OK 作为结果。
与 CLUSTER MEET 命令引发的节点添加消息不一样,CLUSTER FORGET 命令引发的节点移除消息并不会通过 Gossip 协议传播至集群中的其他节点:当用户向一个节点发送 CLUSTER FORGET 命令,让它去移除集群中的另一个节点时,接收到命令的节点只是暂时屏蔽了用户指定的节点,但这个被屏蔽的节点对于集群中的其他节点仍然是可见的。为此,要让集群真正地移除一个节点,用户必须向集群中的所有节点都发送相同的 CLUSTER FORGET 命令,并且这一动作必须在 60s 之内完成,否则被暂时屏蔽的节点就会因为 Gossip 协议的作用而被重新添加到集群中。
举个例子,在一个由 30001~30006 这 6 个节点组成的集群中,如果我们想要移除节点 30005,就需要分别向集群中的其他 5 个节点发送针对节点 30005 的 CLUSTER FORGET 命令,就像这样:
127.0.0.1:30001> CLUSTER FORGET 5f99406c27403564f34f4b5e39410714881ad98e -- 节点30005的运行ID
OK
127.0.0.1:30002> CLUSTER FORGET 5f99406c27403564f34f4b5e39410714881ad98e
OK
127.0.0.1:30003> CLUSTER FORGET 5f99406c27403564f34f4b5e39410714881ad98e
OK
127.0.0.1:30004> CLUSTER FORGET 5f99406c27403564f34f4b5e39410714881ad98e
OK
127.0.0.1:30006> CLUSTER FORGET 5f99406c27403564f34f4b5e39410714881ad98e
OK如果觉得重复发送 5 个 CLUSTER FORGET 命令太麻烦,那么可以使用之前介绍的 Redis 集群管理程序的 call 子命令,一次在整个集群的所有节点中执行 CLUSTER FORGET 命令:
$ redis-cli --
cluster call 127.0.0.1:30001 CLUSTER FORGET 5f99406c27403564f34f4b5e39410714881ad98e
>>> Calling CLUSTER FORGET 5f99406c27403564f34f4b5e39410714881ad98e
127.0.0.1:30001: OK
127.0.0.1:30003: OK
127.0.0.1:30004: OK
127.0.0.1:30002: OK
127.0.0.1:30005: ERR I tried hard but I can't forget myself...
127.0.0.1:30006: OK虽然 30005 因为不能对本身执行 CLUSTER FORGET 而出错了,但这个错误并不会妨碍整个移除操作。
其他信息
-
复杂度:O(1)。
-
版本要求:CLUSTER FORGET 命令从 Redis 3.0.0 版本开始可用。
CLUSTER REPLICATE:将节点变为从节点
CLUSTER REPLICATE 命令接受一个主节点 ID 作为参数,并将执行该命令的节点变成给定主节点的从节点:
CLUSTER REPLICATE master-id用户给定的主节点必须与当前节点位于相同的集群当中。此外,根据当前节点角色的不同,CLUSTER REPLICATE 命令在执行时的情况也会有所不同:
-
如果当前节点是一个主节点,那么它必须是一个没有被指派任何槽的主节点,并且它的数据库中也不能有任何数据,这样它才可以转换成一个从节点。
-
如果当前节点已经是一个从节点,那么它将清空数据库中已有的数据,并开始复制用户给定的节点。
CLUSTER REPLICATE 命令在成功执行时将返回 OK 作为结果。与单机版本的 REPLICAOF 命令一样,CLUSTER REPLICATE 命令引发的复制操作也是异步执行的。
举个例子,通过执行以下命令,我们可以把节点 30005 设置成主节点 30001 的从节点,其中节点 30001 的 ID 为 9cd23534bf654a47a2d4d8a4b2717c495ee31b40:
9cd23534bf654a47a2d4d8a4b2717c495ee31b40:
127.0.0.1:30005> CLUSTER REPLICATE 9cd23534bf654a47a2d4d8a4b2717c495ee31b40
OK只能对主节点进行复制
在使用单机版本的 Redis 时,用户可以让一个从服务器去复制另一个从服务器,以此来构建一系列链式复制的服务器。
与这种做法不同,Redis 集群只允许节点对主节点而不是从节点进行复制,如果用户尝试使用 CLUSTER REPLICATE 命令让一个节点去复制一个从节点,那么命令将返回一个错误:
127.0.0.1:30001> CLUSTER REPLICATE db3a54cfe722264bd91caef4d4af9701bf02223f --向命令传入一个从节点
ID
(error) ERR I can only replicate a master, not a replica.其他信息
-
复杂度:CLUSTER REPLICATE 命令本身的复杂度为 O(1),但它引起的异步复制操作的复杂度为 O(N),其中 N 为主节点数据库包含的键值对总数量。
-
版本要求:CLUSTER REPLICATE 命令从 Redis 3.0.0 版本开始可用。
CLUSTER REPLICAS:查看给定节点的所有从节点
CLUSTER REPLICAS 命令接受一个节点ID作为参数,然后返回该节点属下所有从节点的相关信息:
CLUSTER REPLICAS node-id作为例子,以下代码展示了如何获取节点 30001 属下所有从节点的相关信息:
--首先获取本节点的ID
127.0.0.1:30001> CLUSTER MYID
"9cd23534bf654a47a2d4d8a4b2717c495ee31b40"
--然后再使用这个ID查看该节点属下从节点的信息
127.0.0.1:30001> CLUSTER REPLICAS 9cd23534bf654a47a2d4d8a4b2717c495ee31b40
1) "5f99406c27403564f34f4b5e39410714881ad98e 127.0.0.1:30005@40005 slave 9cd23534bf654a47a2d4d8a
4b2717c495ee31b40 0 1541931897080 1 connected"因为节点 30001 目前只有一个从节点,所以命令只打印了一个节点的信息。CLUSTER REPLICAS 命令输出的节点信息和 CLUSTER NODES 命令输出的节点信息的格式完全相同。根据上述节点信息显示,节点 30001 的从节点的运行 ID 为 5f99406c27403564f34f4b5e39410714881ad98e,它的 IP 地址、客户端端口号和集群端口号分别为 127.0.0.1、30005 和 40005,它所处的配置纪元为 1,诸如此类。
如果给定的节点并不存在于集群当中,或者它是一个从节点,那么命令将返回相应的错误:
--节点不存在
127.0.0.1:30001> CLUSTER REPLICAS not-exists-node-abcdefghijklmnopqrstuvwx
(error) ERR Unknown node not-exists-node-abcdefghijklmnopqrstuvwx
--节点是一个从节点
127.0.0.1:30001> CLUSTER REPLICAS db3a54cfe722264bd91caef4d4af9701bf02223f
(error) ERR The specified node is not a master旧版Redis中的CLUSTER REPLICAS命令
CLUSTER REPLICAS 命令是从 Redis 5.0.0 版本开始启用的,在较旧的 Redis 版本中(不低于 3.0.0版本),同样的工作可以通过执行 CLUSTER SLAVES 命令来完成。因为 CLUSTER SLAVES 在未来可能会被废弃,所以如果你使用的是 Redis 5.0.0 或以上版本,那么你应该使用 CLUSTER REPLICAS 而不是 CLUSTER SLAVES。
其他信息
-
复杂度:O(N),其中 N 为给定节点拥有的从节点数量。
-
版本要求:CLUSTER SLAVES 命令从 Redis 3.0.0 版本开始可用,CLUSTER REPLICAS 命令从 Redis 5.0.0 版本开始可用。
CLUSTER FAILOVER:强制执行故障转移
用户可以通过向从节点发送以下命令,让它发起一次对自身主节点的故障转移操作:
CLUSTER FAILOVER因为接收到该命令的从节点会先将自身的数据库更新至与主节点完全一致,然后再执行后续的故障转移操作,所以这个过程不会丢失任何数据。
作为例子,我们可以对主节点 30001 的从节点 30005 发送 CLUSTER FAILOVER 命令,让后者代替前者成为新的主节点:
--执行CLUSTER FAILOVER命令前的节点配置
--节点30005为30001从节点
127.0.0.1:30005> CLUSTER NODES
...
5f99406c27403564f34f4b5e39410714881ad98e 127.0.0.1:30005@40005 myself,slave 9cd23534bf654a47a2d4
d8a4b2717c495ee31b40 0 1542078342000 5 connected
...
9cd23534bf654a47a2d4d8a4b2717c495ee31b40 127.0.0.1:30001@40001 master - 0 1542078342138 1 connected 0-5460
--执行故障转移操作
127.0.0.1:30005> CLUSTER FAILOVER
OK
--故障转移实施之后的节点配置
--节点30005已经成为了新的主节点,而30001则变成了该节点的从节点
127.0.0.1:30005> CLUSTER NODES
...
5f99406c27403564f34f4b5e39410714881ad98e 127.0.0.1:30005@40005 myself,master - 0 1542078351000 7
connected 0-5460
...
9cd23534bf654a47a2d4d8a4b2717c495ee31b40 127.0.0.1:30001@40001 slave 5f99406c27403564f34f4b5e394
10714881ad98e 0 1542078351095 7 connectedCLUSTER FAILOVER 命令在执行成功时将返回 OK 作为结果。如果用户尝试向主节点发送该命令,那么命令将返回一个错误:
--尝试再次向已经成为主节点的30005发送CLUSTER FAILOVER命令
127.0.0.1:30005> CLUSTER FAILOVER
(error) ERR You should send CLUSTER FAILOVER to a replica-
FORCE选项和TAKEOVER选项
用户可以通过可选的 FORCE 选项和 TAKEOVER 选项来改变 CLUSTER FAILOVER 命令的行为:
CLUSTER FAILOVER [FORCE|TAKEOVER]在给定了 FORCE 选项时,从节点将在不尝试与主节点进行握手的情况下,直接实施故障转移。这种做法可以让用户在主节点已经下线的情况下立即开始故障转移。
需要注意的是,即使用户给定了 FORCE 选项,从节点对主节点的故障转移操作仍然要经过集群中大多数主节点的同意才能够真正执行。但如果用户给定了 TAKEOVER 选项,那么从节点将在不询问集群中其他节点意见的情况下,直接对主节点实施故障转移。
-
其他信息
-
复杂度:O(1)。
-
版本要求:CLUSTER FAILOVER 命令从 Redis 3.0.0 版本开始可用。
-
CLUSTER RESET:重置节点
用户可以通过在节点上执行 CLUSTER RESET 命令来重置该节点,以便在集群中复用该节点:
CLUSTER RESET [SOFT|HARD]这个命令接受 SOFT 和 HARD 两个可选项作为参数,用于指定重置操作的具体行为(软重置和硬重置)。如果用户在执行 CLUSTER RESET 命令的时候没有显式地指定重置方式,那么命令默认将使用 SOFT 选项。
CLUSTER RESET 命令在执行时,将对节点执行以下操作:
-
遗忘该节点已知的其他所有节点。
-
撤销指派给该节点的所有槽,并清空节点内部的槽-节点映射表。
-
如果执行该命令的节点是一个从节点,那么将它转换成一个主节点。
-
如果执行的是硬重置,那么为节点创建一个新的运行 ID。
-
如果执行的是硬重置,那么将节点的纪元和配置纪元都设置为0。
-
通过集群节点配置文件的方式,将新的配置持久化到硬盘上。
需要注意的是,CLUSTER RESET 命令只能在数据库为空的节点上执行,如果节点的数据库非空,那么命令将返回一个错误:
127.0.0.1:30002> CLUSTER RESET
(error) ERR CLUSTER RESET can't be called with master nodes containing keys在正常情况下,CLUSTER RESET 命令在正确执行之后将返回 OK 作为结果:
--清空数据库
127.0.0.1:30002> FLUSHALL
OK
--执行(软)重置
127.0.0.1:30002> CLUSTER RESET
OK
--节点在重置之后将遗忘之前发现过的所有节点
127.0.0.1:30002> CLUSTER NODES
309871e77eaccc0a4e260cf393547bf51ba11983 127.0.0.1:30002@40002 myself,master - 0 1542090339000 2
connected
--执行硬重置
127.0.0.1:30002> CLUSTER RESET HARD
OK
--节点在硬重置之后获得了新的运行ID
127.0.0.1:30002> CLUSTER NODES
b24d4a41c6a9c5633eb93caca15faed75398dd54 127.0.0.1:30002@40002 myself,master - 0 1542090339000 0
connected