流水线
在一般情况下,用户每执行一个Redis命令,Redis客户端和Redis服务器就需要执行以下步骤:
-
客户端向服务器发送命令请求。
-
服务器接收命令请求,并执行用户指定的命令调用,然后产生相应的命令执行结果。
-
服务器向客户端返回命令的执行结果。
-
客户端接收命令的执行结果,并向用户进行展示。
与大多数网络程序一样,执行Redis命令所消耗的大部分时间都用在了发送命令请求和接收命令结果上面:Redis服务器处理一个命令请求通常只需要很短的时间,但客户端将命令请求发送给服务器以及服务器向客户端返回命令结果的过程却需要花费不少时间。通常情况下,程序需要执行的Redis命令越多,它需要进行的网络通信操作也会越多,程序的执行速度也会因此而变慢。
为了解决这个问题,我们可以使用Redis提供的流水线特性:这个特性允许客户端把任意多条Redis命令请求打包在一起,然后一次性地将它们全部发送给服务器,而服务器则会在流水线包含的所有命令请求都处理完毕之后,一次性地将它们的执行结果全部返回给客户端。
通过使用流水线特性,我们可以将执行多个命令所需的网络通信次数从原来的N次降低为1次,这可以大幅度地减少程序在网络通信方面耗费的时间,使得程序的执行效率得到显著的提升。
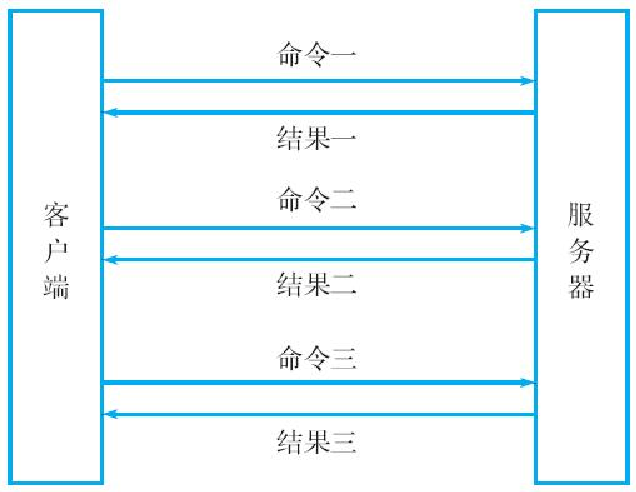
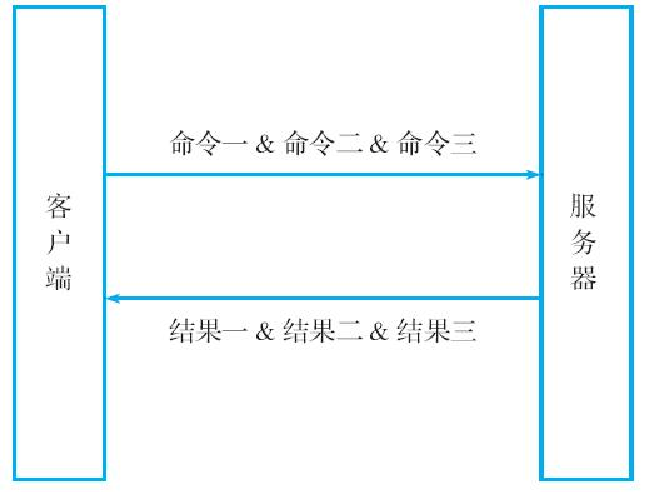
作为例子,图13-1展示了在没有使用流水线的情况下,执行3个Redis命令产生的网络通信示意图,而图13-2则展示了在使用流水线的情况下,执行相同Redis命令产生的网络通信示意图。可以看到,在使用了流水线之后,程序进行网络通信的次数从原来的3次降低到了1次。
虽然Redis服务器提供了流水线特性,但这个特性还需要客户端支持才能使用。幸运的是,包括redis-py在内的绝大部分Redis客户端都提供了对流水线特性的支持,因此Redis用户在绝大部分情况下都能够享受到流水线特性带来的好处。
为了在redis-py客户端中使用流水线特性,我们需要用到 pipeline()方法,调用这个方法会返回一个流水线对象,用户只需要像平时执行Redis命令那样,使用流水线对象调用相应的命令方法,就可以把想要执行的Redis命令放入流水线中。
作为例子,以下代码展示了如何以流水线方式执行SET、INCRBY和SADD 命令:
>>> from redis import Redis
>>> client = Redis(decode_responses=True)
>>> pipe = client.pipeline(transaction=False)
>>> pipe.set("msg", "hello world")
Pipeline<ConnectionPool<Connection<host=localhost,port=6379,db=0>>>
>>> pipe.incrby("pv_counter::12345", 100)
Pipeline<ConnectionPool<Connection<host=localhost,port=6379,db=0>>>
>>> pipe.sadd("fruits", "apple", "banana", "cherry")
Pipeline<ConnectionPool<Connection<host=localhost,port=6379,db=0>>>
>>> pipe.execute()
[True, 100, 3]这段代码先使用pipeline()方法创建了一个流水线对象,并将这个对象存储到了pipe变量中(pipeline()方法中的transaction=False 参数表示不在流水线中使用事务,这个参数的具体意义将在本章后续内容中说明)。在此之后,程序通过流水线对象分别调用了set()方法、incrby()方法和sadd()方法,将这3个方法对应的命令调用放入了流水线队列中。最后,程序调用流水线对象的execute()方法,将队列中的3个命令调用打包发送给服务器,而服务器会在执行完这些命令之后,把各个命令的执行结果依次放入一个列表中,然后将这个列表返回给客户端。
图13-3展示了以上代码在执行期间,redis-py客户端与Redis服务器之间的网络通信情况。

流水线使用注意事项
虽然Redis服务器并不会限制客户端在流水线中包含的命令数量,但是却会为客户端的输入缓冲区设置默认值为1GB的体积上限:当客户端发送的数据量超过这一限制时,Redis服务器将强制关闭该客户端。因此用户在使用流水线特性时,最好不要一下把大量命令或者一些体积非常庞大的命令放到同一个流水线中执行,以免触碰到Redis的这一限制。
除此之外,很多客户端本身也带有隐含的缓冲区大小限制,如果你在使用流水线特性的过程中,发现某些流水线命令没有被执行,或者流水线返回的结果不完整,那么很可能就是你的程序触碰到了客户端内置的缓冲区大小限制。在遇到这种情况时,请缩减流水线命令的数量及其体积,然后再进行尝试。
示例:使用流水线优化随机键创建程序
在第11章中的数据库取样程序示例中,曾经展示过代码清单13-1所示的程序,它可以根据用户给定的数量创建多个类型随机的数据库键。
import random
def create_random_type_keys(client, number):
"""
在数据库中创建指定数量的类型随机键。
"""
for i in range(number):
# 构建键名
key = "key:{0}".format(i)
# 从六个键创建函数中随机选择一个
create_key_func = random.choice([
create_string,
create_hash,
create_list,
create_set,
create_zset,
create_stream
])
# 实际地创建键
create_key_func(client, key)
def create_string(client, key):
client.set(key, "")
def create_hash(client, key):
client.hset(key, "", "")
def create_list(client, key):
client.rpush(key, "")
def create_set(client, key):
client.sadd(key, "")
def create_zset(client, key):
client.zadd(key, {"":0})
def create_stream(client, key):
client.xadd(key, {"":""})通过分析代码可知,这个程序每创建一个键,redis-py客户端就需要与Redis服务器进行一次网络通信:考虑到这个程序执行的都是一些非常简单的命令,每次网络通信只执行一个命令的做法无疑是非常低效的。为了解决这个问题,我们可以使用流水线把程序生成的所有命令都包裹起来,这样的话,创建多个随机键所需要的网络通信次数就会从原来的N次降低为1次。代码清单13-2展示了修改之后的流水线版本随机键创建程序。
import random
def create_random_type_keys(client, number):
"""
在数据库中创建指定数量的类型随机键。
"""
# 创建流水线对象
pipe = client.pipeline(transaction=False)
for i in range(number):
# 构建键名
key = "key:{0}".format(i)
# 从六个键创建函数中随机选择一个
create_key_func = random.choice([
create_string,
create_hash,
create_list,
create_set,
create_zset,
create_stream
])
# 把待执行的 Redis 命令放入流水线队列中
create_key_func(pipe, key)
# 执行流水线包裹的所有命令
pipe.execute()
def create_string(client, key):
client.set(key, "")
def create_hash(client, key):
client.hset(key, "", "")
def create_list(client, key):
client.rpush(key, "")
def create_set(client, key):
client.sadd(key, "")
def create_zset(client, key):
client.zadd(key, {"":0})
def create_stream(client, key):
client.xadd(key, {"":""})即使只在本地网络中进行测试,新版的随机键创建程序也有 5 倍的性能提升。当客户端与服务器处于不同的网络之中,特别是它们之间的连接速度较慢时,流水线版本的性能提升还会更多。