SDIFF、SDIFFSTORE:对集合执行差集计算
SDIFF 命令可以计算出给定集合之间的差集,并返回差集包含的所有元素:
SDIFF set [set ...]SDIFF 命令会按照用户给定集合的顺序,从左到右依次地对给定的集合执行差集计算。
举个例子,对于以下这 3 个集合来说:
redis> SMEMBERS s1
1) "a"
2) "b"
3) "c"
4) "d"
redis> SMEMBERS s2
1) "c"
2) "d"
3) "e"
4) "f"
redis> SMEMBERS s3
1) "b"
2) "f"
3) "g"如果我们执行以下命令:
redis> SDIFF s1 s2 s3
1) "a"那么 SDIFF 命令首先会对集合 s1 和集合 s2 执行差集计算,得到一个包含元素 "a" 和 "b" 的临时集合,然后使用这个临时集合与集合 s3 执行差集计算。换句话说,这个 SDIFF 命令首先会计算出 s1-s2 的结果,然后再计算 (s1-s2)-s3 的结果。
SDIFFSTORE命令
与 SINTERSTORE 命令和 SUNIONSTORE 命令一样,Redis 也为 SDIFF 命令提供了相应的 SDIFFSTORE 命令,这个命令可以把给定集合之间的差集计算结果存储到指定的键中,并在键已经存在的情况下自动覆盖已有的键:
SDIFFSTORE destination_key set [set ...]SDIFFSTORE 命令会返回被存储的差集元素数量作为返回值。
作为例子,以下代码展示了如何将集合 s1、s2、s3 的差集计算结果存储到集合 diff-result 中:
redis> SDIFFSTORE diff-result s1 s2 s3
(integer) 1 -- 计算出的差集只包含一个元素
redis> SMEMBERS diff-result
1) "a"其它信息
-
复杂度:SDIFF 命令和 SDIFFSTORE 命令的复杂度都是 O(N),其中 N 为所有给定集合包含的元素数量总和。
-
版本要求:SDIFF 命令和 SDIFFSTORE 命令从 Redis 1.0.0 版本开始可用。
执行集合计算的注意事项
因为对集合执行交集、并集、差集等集合计算需要耗费大量的资源,所以用户应该尽量使用 SINTERSTORE 等命令来存储并重用计算结果,而不要每次都重复进行计算。
此外,当集合计算涉及的元素数量非常大时,Redis 服务器在进行计算时可能会被阻塞。这时,我们可以考虑使用 Redis 的复制功能,通过从服务器来执行集合计算任务,从而确保主服务器可以继续处理其他客户端发送的命令请求。
本书第 18 章中将对 Redis 的复制功能进行详细介绍。
示例:共同关注与推荐关注
在前面我们学习了如何使用集合存储社交网站的好友关系,但是除了基本的关注和被关注之外,社交网站通常还会提供一些额外的功能,帮助用户去发现一些自己可能会感兴趣的人。
例如,当我们在微博上访问某个用户的个人页面时,页面上就会展示出我们和这个用户都在关注的人,就像图5-12所示那样。
除了共同关注之外,一些社交网站还会通过算法和数据分析为用户推荐一些他可能感兴趣的人,例如图5-13就展示了 Twitter 是如何向用户推荐他可能会感兴趣的关注对象的。

接下来我们将分别学习如何使用集合实现以上展示的共同关注功能和推荐关注功能。
-
共同关注
要实现共同关注功能,程序需要做的就是计算出两个用户的正在关注集合之间的交集,这一点可以通过前面介绍的 SINTER 命令和 SINTERSTORE 命令来完成,代码清单5-7展示了使用这一原理实现的共同关注程序。
代码清单5-7 共同关注功能的实现:/set/common_following.pydef following_key(user): return user + "::following" class CommonFollowing: def __init__(self, client): self.client = client def calculate(self, user, target): """ 计算并返回当前用户和目标用户共同关注的人。 """ user_following_set = following_key(user) target_following_set = following_key(target) return self.client.sinter(user_following_set, target_following_set) def calculate_and_store(self, user, target, store_key): """ 计算出当前用户和目标用户共同关注的人, 并把结果储存到 store_key 指定的键里面, 最后返回共同关注的人数作为返回值。 """ user_following_set = following_key(user) target_following_set = following_key(target) return self.client.sinterstore(store_key, user_following_set, target_following_set)以下代码展示了共同关注程序的具体用法:
>>> from redis import Redis >>> from relationship import Relationship >>> from common_following import CommonFollowing >>> client = Redis(decode_responses=True) >>> peter = Relationship(client, "peter") >>> jack = Relationship(client, "jack") >>> peter.follow("tom") # peter关注一些用户 >>> peter.follow("david") >>> peter.follow("mary") >>> jack.follow("tom") # jack关注一些用户 >>> jack.follow("david") >>> jack.follow("lily") >>> common_following = CommonFollowing(client) >>> common_following.calculate("peter", "jack") # 计算peter和jack共同关注的用户 set(['tom', 'david']) # 他们都关注了tom和david -
推荐关注
代码清单 5-8 展示了一个推荐关注程序的实现代码,这个程序会从用户的正在关注集合中随机选出指定数量的用户作为种子用户,然后对这些种子用户的正在关注集合执行并集计算,最后从这个并集中随机地选出一些用户作为推荐关注的对象。
def following_key(user):
return user + "::following"
def recommend_follow_key(user):
return user + "::recommend_follow"
class RecommendFollow:
def __init__(self, client, user):
self.client = client
self.user = user
def calculate(self, seed_size):
"""
计算并储存用户的推荐关注数据。
"""
# 1)从用户关注的人中随机选一些人作为种子用户
user_following_set = following_key(self.user)
following_targets = self.client.srandmember(user_following_set, seed_size)
# 2)收集种子用户的正在关注集合键名
target_sets = set()
for target in following_targets:
target_sets.add(following_key(target))
# 3)对所有种子用户的正在关注集合执行并集计算,并储存结果
return self.client.sunionstore(recommend_follow_key(self.user), *target_sets)
def fetch_result(self, number):
"""
从已有的推荐关注数据中随机地获取指定数量的推荐关注用户。
"""
return self.client.srandmember(recommend_follow_key(self.user), number)
def delete_result(self):
"""
删除已计算出的推荐关注数据。
"""
self.client.delete(recommend_follow_key(self.user))以下代码展示了这个推荐关注程序的使用方法:
>>> from redis import Redis
>>> from recommend_follow import RecommendFollow
>>> client = Redis(decode_responses=True)
>>> recommend_follow = RecommendFollow(client, "peter")
>>> recommend_follow.calculate(3) # 随机选择3个正在关注的人作为种子用户
30
>>> recommend_follow.fetch_result(10) # 获取10个推荐关注对象
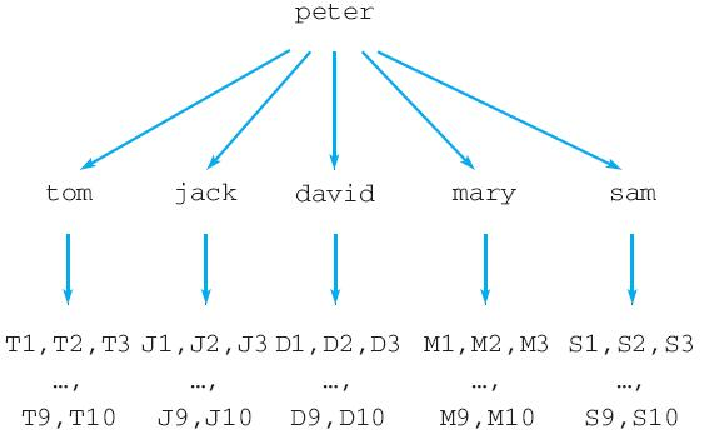
['D6', 'M0', 'S4', 'M1', 'S8', 'M3', 'S3', 'M7', 'M4', 'D7']在执行这段代码之前,用户 peter 关注了 tom、david、jack、mary 和 sam 这 5 个用户,而这 5 个用户又分别关注了如图 5-14 所示的一些用户,从结果来看,推荐程序随机选中了 david、sam 和 mary 作为种子用户,然后又从这 3 个用户的正在关注集合的并集中随机选出了 10 个人作为 peter 的推荐关注对象。
需要注意的是,这里使用的是非常简单的推荐算法,假设用户会对自己正在关注的人的关注对象感兴趣,但实际的情况可能并非如此。为了获得更为精准的推荐效果,实际的社交网站通常会使用更为复杂的推荐算法,有兴趣的读者可以自行查找这方面的资料。
示例:使用反向索引构建商品筛选器
在访问网店或者购物网站的时候,我们经常会看到类似图5-15中显示的商品筛选器,对于不同的筛选条件,这些筛选器会给出不同的选项,用户可以通过选择不同的选项来快速找到自己想要的商品。

比如对于图 5-15 展示的笔记本电脑筛选器来说,如果我们单击图中 “品牌” 一栏的 ThinkPad 图标,那么筛选器将只在页面中展示 ThinkPad 品牌的笔记本电脑。如果我们继续单击 “尺寸” 一栏中的 “13.3英寸” 选项,那么筛选器将只在页面中展示 ThinkPad 品牌 13.3 英寸的笔记本电脑,诸如此类。
实现商品筛选器的方法之一是使用反向索引,这种数据结构可以为每个物品添加多个关键字,然后根据关键字去反向获取相应的物品。举个例子,对于 "X1Carbon" 这台笔记本电脑来说,我们可以为它添加 "ThinkPad"、"14inch"、"Windows" 等关键字,然后通过这些关键字来反向获取 "X1Carbon" 这台笔记本电脑。
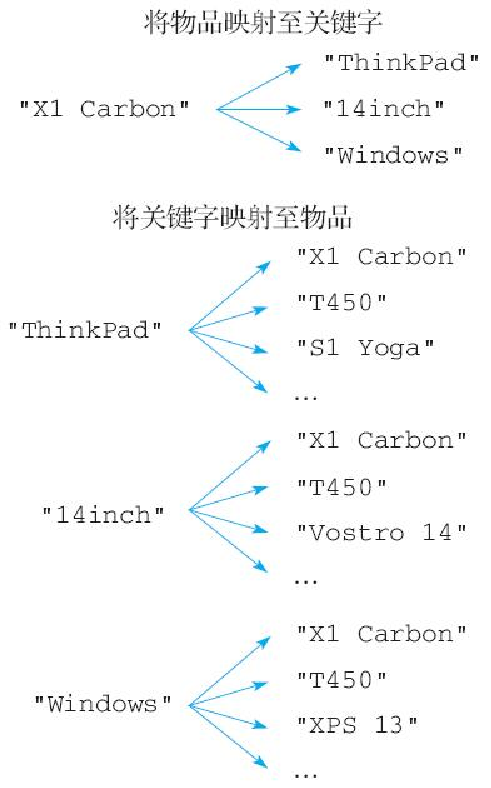
实现反向索引的关键是要在物品和关键字之间构建起双向的映射关系,比如对于刚刚提到的 "X1Carbon" 笔记本电脑来说,反向索引程序需要构建出图5-16所示的两种映射关系:
-
第一种映射关系将 "X1Carbon" 映射至它带有的各个关键字。
-
第二种映射关系将 "ThinkPad"、"14inch"、"Windows" 等多个关键字映射至 "X1Carbon"。
代码清单5-9 展示了一个使用集合实现的反向索引程序,对于用户给定的每一件物品,这个程序都会使用一个集合去存储物品带有的多个关键字,与此同时,对于这件物品的每一个关键字,程序都会使用一个集合去存储关键字与物品之间的映射。因为构建反向索引所需的这两种映射都是一对多映射,所以使用集合来存储这两种映射关系的做法是可行的。
def make_item_key(item):
return "InvertedIndex::" + item + "::keywords"
def make_keyword_key(keyword):
return "InvertedIndex::" + keyword + "::items"
class InvertedIndex:
def __init__(self, client):
self.client = client
def add_index(self, item, *keywords):
"""
为物品添加关键字。
"""
# 将给定关键字添加到物品集合中
item_key = make_item_key(item)
result = self.client.sadd(item_key, *keywords)
# 遍历每个关键字集合,把给定物品添加到这些集合当中
for keyword in keywords:
keyword_key = make_keyword_key(keyword)
self.client.sadd(keyword_key, item)
# 返回新添加关键字的数量作为结果
return result
def remove_index(self, item, *keywords):
"""
移除物品的关键字。
"""
# 将给定关键字从物品集合中移除
item_key = make_item_key(item)
result = self.client.srem(item_key, *keywords)
# 遍历每个关键字集合,把给定物品从这些集合中移除
for keyword in keywords:
keyword_key = make_keyword_key(keyword)
self.client.srem(keyword_key, item)
# 返回被移除关键字的数量作为结果
return result
def get_keywords(self, item):
"""
获取物品的所有关键字。
"""
return self.client.smembers(make_item_key(item))
def get_items(self, *keywords):
"""
根据给定的关键字获取物品。
"""
# 根据给定的关键字,计算出与之对应的集合键名
keyword_key_list = map(make_keyword_key, keywords)
# 然后对这些储存着各式物品的关键字集合执行并集计算
# 从而查找出带有给定关键字的物品
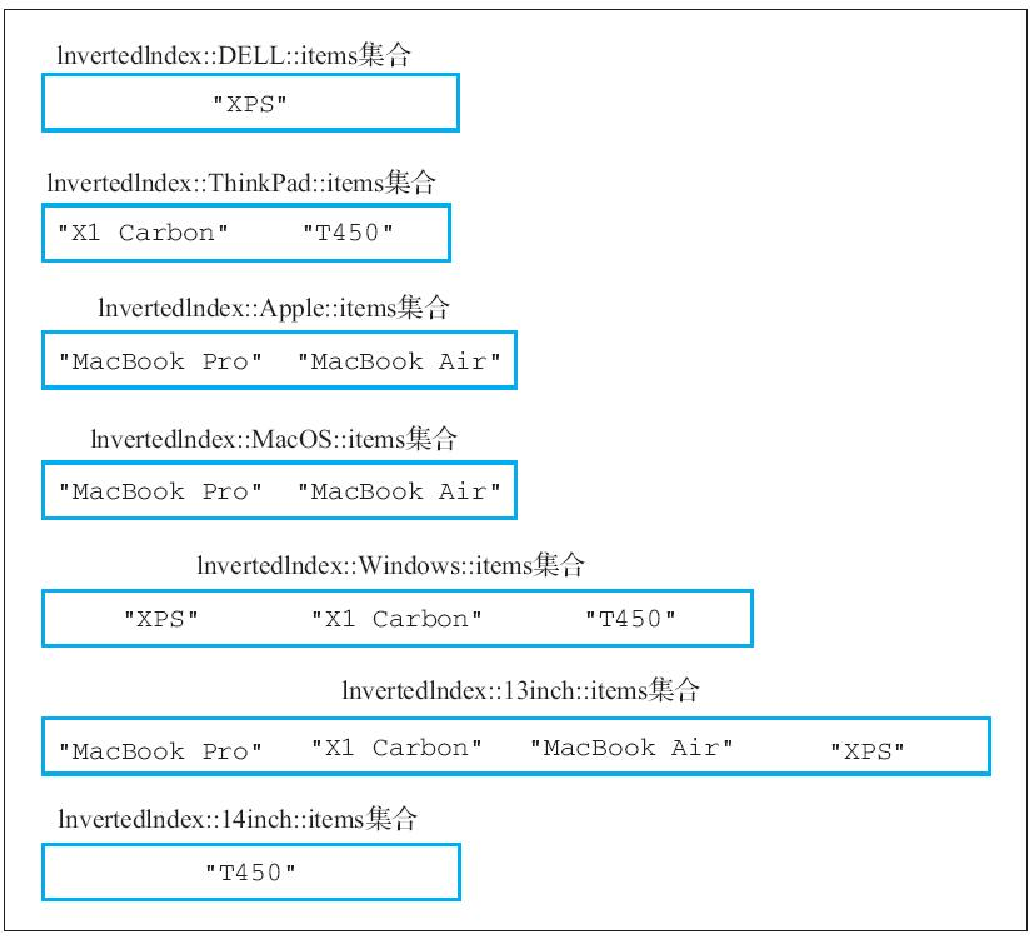
return self.client.sinter(*keyword_key_list)为了测试这个反向索引程序,我们在以下代码中把一些笔记本电脑产品的名称及其关键字添加到了反向索引中:
>>> from redis import Redis
>>> from inverted_index import InvertedIndex
>>> client = Redis(decode_responses=True)
>>> laptops = InvertedIndex(client)
>>> laptops.add_index("MacBook Pro", "Apple", "MacOS", "13inch") # 建立索引
3
>>> laptops.add_index("MacBook Air", "Apple", "MacOS", "13inch")
3
>>> laptops.add_index("X1 Carbon", "ThinkPad", "Windows", "13inch")
3
>>> laptops.add_index("T450", "ThinkPad", "Windows", "14inch")
3
>>> laptops.add_index("XPS", "DELL", "Windows", "13inch")
3在此之后,我们可以通过以下语句找出 "T450" 计算机带有的所有关键字
>>> laptops.get_keywords("T450")
set(['Windows', '14inch', 'ThinkPad'])也可以找出所有屏幕大小为 13 英寸的笔记本电脑:
>>> laptops.get_items("13inch")
set(['MacBook Pro', 'X1 Carbon', 'MacBook Air', 'XPS'])还可以找出所有屏幕大小为 13 英寸并且使用 Windows 系统的笔记本电脑:
>>> laptops.get_items("13inch", "Windows")
set(['XPS', 'X1 Carbon'])或者找出所有屏幕大小为 13 英寸并且使用 Windows 系统的 ThinkPad 品牌笔记本电脑:
>>> laptops.get_items("13inch", "Windows", "ThinkPad")
set(['X1 Carbon'])
图5-17 展示了以上代码在数据库中为物品创建的各个集合,而图5-18 则展示了以上代码在数据库中为关键字创建的各个集合。