使用 Requests 和 Beautiful Soup 抓取 Python.org
在本节中,我们将安装 Requests 和 Beautiful Soup 并从 www.python.org 中抓取一些内容。 我们将安装这两个库并对它们进行一些基本的熟悉。 我们将在后续章节中回顾并深入探讨它们。
准备工作
在本节中,我们将从 https://www.python.org/events/pythonevents 中抓取即将到来的 Python 事件。 以下是 Python.org 活动页面的示例(它经常变化,因此您的体验会有所不同):
我们需要确保安装了 Requests 和 Beautiful Soup。 我们可以通过以下方式做到这一点:
pywscb $ pip install requests
Downloading/unpacking requests
Downloading requests-2.18.4-py2.py3-none-any.whl (88kB): 88kB downloaded
Downloading/unpacking certifi>=2017.4.17 (from requests)
Downloading certifi-2018.1.18-py2.py3-none-any.whl (151kB): 151kB
downloaded
Downloading/unpacking idna>=2.5,<2.7 (from requests)
Downloading idna-2.6-py2.py3-none-any.whl (56kB): 56kB downloaded
Downloading/unpacking chardet>=3.0.2,<3.1.0 (from requests)
Downloading chardet-3.0.4-py2.py3-none-any.whl (133kB): 133kB downloaded
Downloading/unpacking urllib3>=1.21.1,<1.23 (from requests)
Downloading urllib3-1.22-py2.py3-none-any.whl (132kB): 132kB downloaded
Installing collected packages: requests, certifi, idna, chardet, urllib3
Successfully installed requests certifi idna chardet urllib3
Cleaning up...
pywscb $ pip install bs4
Downloading/unpacking bs4
Downloading bs4-0.0.1.tar.gz
Running setup.py (path:/Users/michaelheydt/pywscb/env/build/bs4/setup.py)
egg_info for package bs4怎么做
现在让我们来学习抓取几个事件。 对于本教程,我们将从使用交互式 Python 开始。
-
使用 ipython 命令启动它:
$ ipython Python 3.6.1 |Anaconda custom (x86_64)| (default, Mar 22 2017, 19:25:17) Type "copyright", "credits" or "license" for more information. IPython 5.1.0 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: -
接下来我们导入请求
In [1]: import requests -
我们现在使用 requests 对以下 url 发出 GET HTTP 请求:https://www.python.org/events/python-events/ 通过发出 GET 请求:
In [2]: url = 'https://www.python.org/events/python-events/' In [3]: req = requests.get(url) -
下载了页面内容,但它存储在我们的请求对象 req 中。我们可以使用 .text 属性检索内容。 这将打印前 200 个字符。
req.text[:200] Out[4]: '<!doctype html>\n<!--[if lt IE 7]> <html class="no-js ie6 lt-ie7 lt-ie8 lt-ie9"> <![endif]-->\n<!--[if IE 7]> <html class="no-js ie7 lt-ie8 lt-ie9"> <![endif]-->\n<!--[if IE 8]> <h'
现在我们有了页面的原始 HTML。我们现在可以使用 beautiful soup 来解析 HTML 并检索事件数据。
-
首先导入 Beautiful Soup
In [5]: from bs4 import BeautifulSoup -
现在我们创建一个 BeautifulSoup 对象并向其传递 HTML。
In [6]: soup = BeautifulSoup(req.text, 'lxml') -
现在我们告诉 Beautiful Soup 找到最近事件的主 <ul> 标签,然后获取它下面的所有 <li> 标签。
In [7]: events = soup.find('ul', {'class': 'list-recentevents'}).findAll('li') -
最后,我们可以循环遍历每个 <li> 元素,提取事件详细信息,并将每个元素打印到控制台:
In [13]: for event in events:
...: event_details = dict()
...: event_details['name'] = event_details['name'] =
event.find('h3').find("a").text
...: event_details['location'] = event.find('span', {'class',
'event-location'}).text
...: event_details['time'] = event.find('time').text
...: print(event_details)
...:
{'name': 'PyCascades 2018', 'location': 'Granville Island Stage,
1585 Johnston St, Vancouver, BC V6H 3R9, Canada', 'time': '22 Jan.
– 24 Jan. 2018'}
{'name': 'PyCon Cameroon 2018', 'location': 'Limbe, Cameroon',
'time': '24 Jan. – 29 Jan. 2018'}
{'name': 'FOSDEM 2018', 'location': 'ULB Campus du Solbosch, Av. F.
D. Roosevelt 50, 1050 Bruxelles, Belgium', 'time': '03 Feb. – 05
Feb. 2018'}
{'name': 'PyCon Pune 2018', 'location': 'Pune, India', 'time': '08
Feb. – 12 Feb. 2018'}
{'name': 'PyCon Colombia 2018', 'location': 'Medellin, Colombia',
'time': '09 Feb. – 12 Feb. 2018'}
{'name': 'PyTennessee 2018', 'location': 'Nashville, TN, USA',
'time': '10 Feb. – 12 Feb. 2018'}整个示例可在 01/01_events_with_requests.py 脚本文件中找到。以下是它的内容,它汇集了我们刚刚一步步完成的所有内容:
import requests
from bs4 import BeautifulSoup
def get_upcoming_events(url):
req = requests.get(url)
soup = BeautifulSoup(req.text, 'lxml')
events = soup.find('ul', {'class': 'list-recent-events'}).findAll('li')
for event in events:
event_details = dict()
event_details['name'] = event.find('h3').find("a").text
event_details['location'] = event.find('span', {'class', 'event-location'}).text
event_details['time'] = event.find('time').text
print(event_details)
get_upcoming_events('https://www.python.org/events/python-events/')您可以从终端使用以下命令来运行它:
$ python 01_events_with_requests.py
{'name': 'PyCascades 2018', 'location': 'Granville Island Stage, 1585
Johnston St, Vancouver, BC V6H 3R9, Canada', 'time': '22 Jan. – 24 Jan.
2018'}
{'name': 'PyCon Cameroon 2018', 'location': 'Limbe, Cameroon', 'time': '24
Jan. – 29 Jan. 2018'}
{'name': 'FOSDEM 2018', 'location': 'ULB Campus du Solbosch, Av. F. D.
Roosevelt 50, 1050 Bruxelles, Belgium', 'time': '03 Feb. – 05 Feb. 2018'}
{'name': 'PyCon Pune 2018', 'location': 'Pune, India', 'time': '08 Feb. – 12
Feb. 2018'}
{'name': 'PyCon Colombia 2018', 'location': 'Medellin, Colombia', 'time':
'09 Feb. – 12 Feb. 2018'}
{'name': 'PyTennessee 2018', 'location': 'Nashville, TN, USA', 'time': '10
Feb. – 12 Feb. 2018'}怎么运行
我们将在下一章中深入探讨 Requests 和 Beautiful Soup 的细节,但现在我们只总结一下其工作原理的几个关键点。 关于 Requests 的以下要点:
-
Requests 用于执行 HTTP 请求。 我们使用它对事件页面的 URL 发出 GET 动词请求。
-
Requests 对象保存请求的结果。 这不仅是页面内容,还包括有关结果的许多其他项目,例如 HTTP 状态代码和标头。
-
请求仅用于获取页面,它不进行解析。 我们使用 Beautiful Soup 来解析 HTML 并查找 HTML 中的内容。
要了解其工作原理,页面内容具有以下 HTML Upcoming Events 部分:
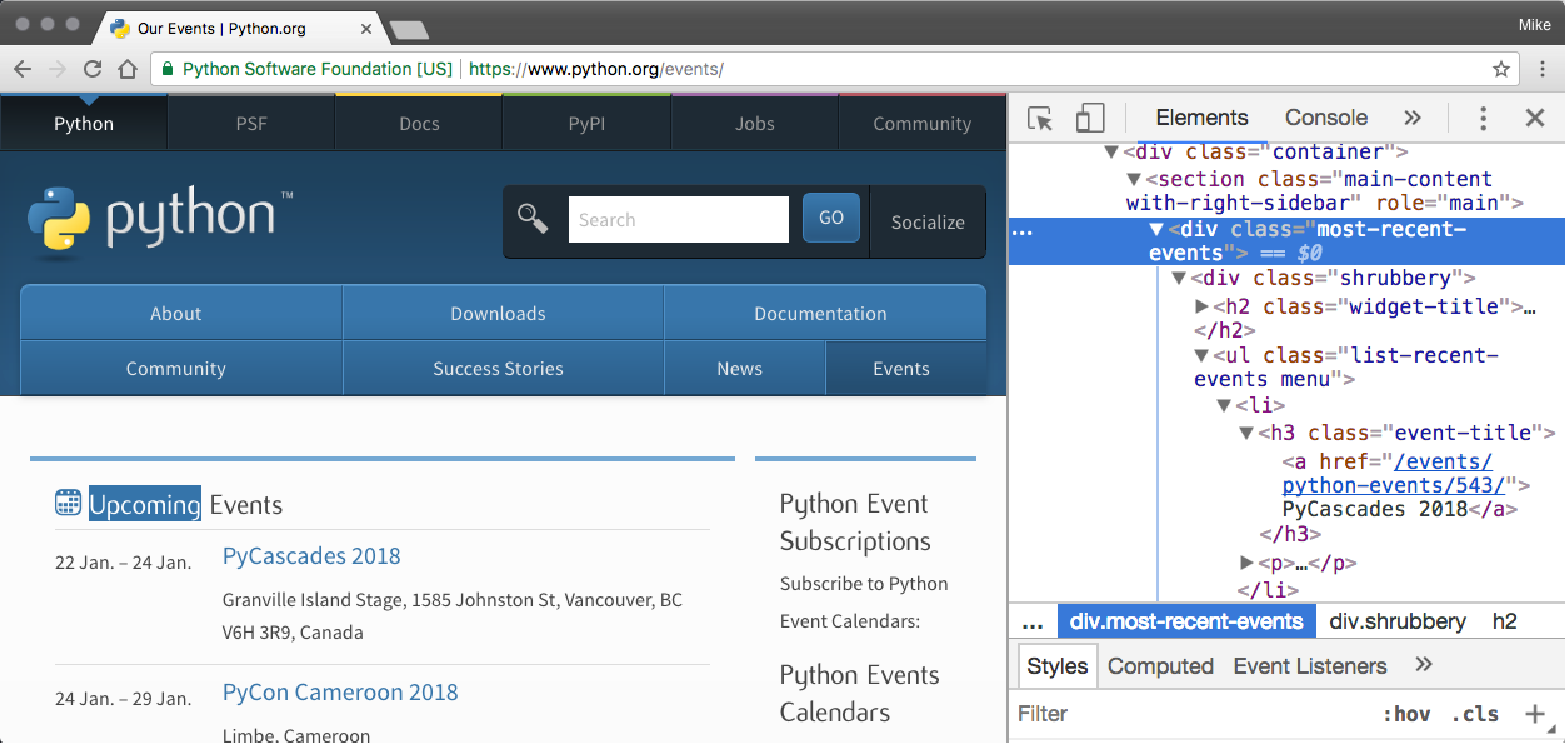
我们使用 Beautiful Soup 功能来处理:
-
查找表示该部分的 <ul> 元素,该元素是通过查找具有一个 class 属性且值为 list-recent-events 的 <ul> 来找到的。
-
从该对象中,我们找到所有 <li> 元素。
每个 <li> 标签代表一个不同的事件。我们迭代每个从子 HTML 标签中找到的事件数据创建字典的内容:
-
该名称是从 <a> 标签中提取的,该标签是 <h3> 标签的子标签
-
位置是 <span> 的文本内容,具有 event-location 类
-
时间是从 <time> 标记的 datetime 属性中提取的。