如何使用 BeautifulSoup 解析网站并导航 DOM
准备工作
我们将使用示例代码的 www 文件夹中包含的一个小型网站。 要继续操作,请从 www 文件夹中启动 Web 服务器。 这可以使用 Python 3 完成,如下所示:
www $ python3 -m http.server 8080
Serving HTTP on 0.0.0.0 port 8080 (http://0.0.0.0:8080/) ...可以在 Chrome 中通过右键单击页面并选择 “检查” 来检查网页的 DOM。 这将打开 Chrome 开发者工具。 打开浏览器页面 http://localhost:8080/planets.html 。 在 Chrome 中,您可以右键单击并选择 “检查” 以打开开发人员工具(其他浏览器也有类似的工具)。
这将打开开发人员工具和检查器。 可以在 “元素” 选项卡中检查 DOM。
下面显示了表中第一行的选择:
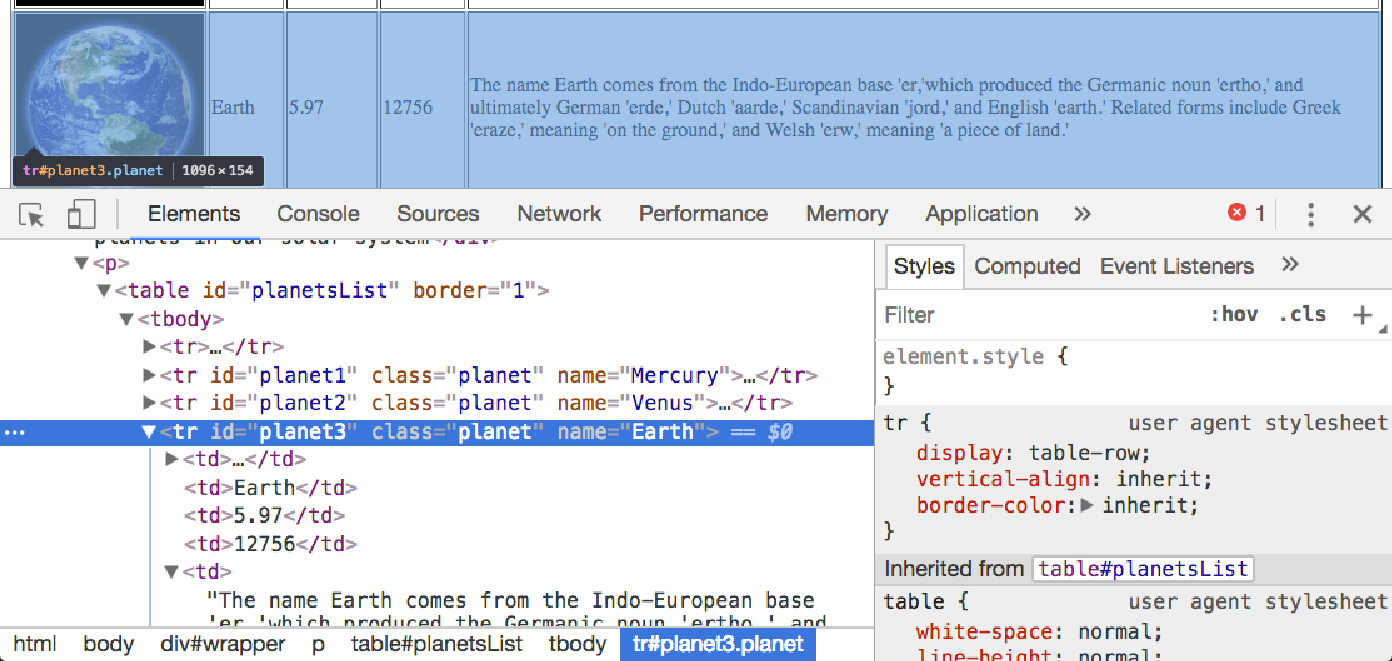
每行行星都位于 <tr> 元素内。 我们将检查该元素及其相邻元素的几个特征,因为它们旨在对常见网页进行建模。
首先,该元素具有三个属性:id、planet、name。 属性在抓取中通常很重要,因为它们通常用于识别和定位 HTML 中嵌入的数据。
其次,<tr> 元素有子元素,在本例中为五个 <td> 元素。 我们经常需要查看特定元素的子元素以查找所需的实际数据。
该元素还有一个父元素 <tbody>。 还有兄弟元素和一组 <tr> 子元素。 从任何行星,我们都可以到达父行星并找到其他行星。 正如我们将看到的,我们可以在各种工具中使用各种构造,例如 Beautiful Soup 中的 find 函数系列,以及 XPath 查询,来轻松导航这些关系。
怎么做
这个秘籍以及本章中的大多数其他秘籍都将以交互方式通过 iPython 呈现。 但每个的所有代码都可以在脚本文件中找到。 此食谱的代码位于 02/01_parsing_html_wtih_bs.py 中。 您可以在脚本文件中键入以下内容,或剪切并粘贴。
现在让我们逐步了解如何使用 Beautiful Soup 解析 HTML。 我们首先使用以下代码将此页面加载到 BeautifulSoup 对象中,该代码创建一个 BeautifulSoup 对象,使用 requests.get 加载页面内容,并将其加载到名为 soup 的变量中。
In [1]: import requests
...: from bs4 import BeautifulSoup
...: html =
requests.get("http://localhost:8080/planets.html").text
...: soup = BeautifulSoup(html, "lxml")
...:soup 对象中的 HTML 可以通过将其转换为字符串来检索(大多数 BeautifulSoup 对象都具有此特性)。 下面显示了文档中 HTML 的前 1000 个字符:
In [2]: str(soup)[:1000]
Out[2]: '<html>\n<head>\n</head>\n<body>\n<div
id="planets">\n<h1>Planetary data</h1>\n<div id="content">Here are some interesting facts about the planets in our solar
system</div>\n<p></p>\n<table border="1" id="planetsTable">\n<tr
id="planetHeader">\n<th>\n</th>\n<th>\r\n Name\r\n </th>\n<th>\r\n
Mass (10^24kg)\r\n </th>\n<th>\r\n Diameter (km)\r\n
</th>\n<th>\r\n How it got its Name\r\n </th>\n<th>\r\n More
Info\r\n </th>\n</tr>\n<tr class="planet" id="planet1"
name="Mercury">\n<td>\n<img
src="img/mercury-150x150.png"/>\n</td>\n<td>\r\n Mercury\r\n
</td>\n<td>\r\n 0.330\r\n </td>\n<td>\r\n 4879\r\n </td>\n<td>Named
Mercurius by the Romans because it appears to move so
swiftly.</td>\n<td>\n<a
href="https://en.wikipedia.org/wiki/Mercury_(planet)">Wikipedia</a>
\n</td>\n</tr>\n<tr class="p'我们可以使用 soup 的属性来导航 DOM 中的元素。 soup代表整个文档,我们可以通过链接标签名称来深入了解文档。 以下导航到包含数据的 <table>:
In [3]: str(soup.html.body.div.table)[:200]
Out[3]: '<table border="1" id="planetsTable">\n<tr
id="planetHeader">\n<th>\n</th>\n<th>\r\n Name\r\n </th>\n<th>\r\n Mass
(10^24kg)\r\n </th>\n<th>\r\n '以下代码检索表的第一个子 <tr>:
In [6]: soup.html.body.div.table.tr
Out[6]: <tr id="planetHeader">
<th></th>
<th>Name</th>
<th>Mass (10^24kg)</th>
<th>Diameter (km)</th>
<th>How it got its Name</th>
<th>More Info</th>
</tr>请注意,这种类型的表示法仅检索该类型的第一个子代。 查找更多需要迭代所有子项,我们接下来将这样做,或者使用 find 方法(下一个示例)。
每个节点都有子节点和后代。 后代是给定节点下面的所有节点(比直接子节点更高级别的事件),而子节点是第一级后代的节点。 下面的代码检索表的子项,它实际上是一个 list_iterator 对象:
In [4]: soup.html.body.div.table.children
Out[4]: <list_iterator at 0x10eb11cc0>我们可以使用 for 循环或 Python 生成器检查迭代器中的每个子元素。 下面使用生成器获取 的所有子级,并以列表形式返回其组成 HTML 的前几个字符:
In [5]: [str(c)[:45] for c in soup.html.body.div.table.children]
Out[5]:
['\n',
'<tr id="planetHeader">\n<th>\n</th>\n<th>\r\n ',
'\n',
'<tr class="planet" id="planet1" name="Mercury',
'\n',
'<tr class="planet" id="planet2" name="Venus">',
'\n',
'<tr class="planet" id="planet3" name="Earth">',
'\n',
'<tr class="planet" id="planet4" name="Mars">\n',
'\n',
'<tr class="planet" id="planet5" name="Jupiter',
'\n',
'<tr class="planet" id="planet6" name="Saturn"',
'\n',
'<tr class="planet" id="planet7" name="Uranus"',
'\n',
'<tr class="planet" id="planet8" name="Neptune',
'\n',
'<tr class="planet" id="planet9" name="Pluto">',
'\n']最后但并非最不重要的一点是,可以使用 .parent 属性找到节点的父节点:
In [7]: str(soup.html.body.div.table.tr.parent)[:200]
Out[7]: '<table border="1" id="planetsTable">\n<tr
id="planetHeader">\n<th>\n</th>\n<th>\r\n Name\r\n </th>\n<th>\r\n
Mass (10^24kg)\r\n </th>\n<th>\r\n '